
基于用户评论的动态方面注意力电商推荐深度学习模型
2020-03-13 10:55冯兴杰曾云泽
计算机应用与软件 2020年3期
冯兴杰 曾云泽
(中国民航大学计算机科学与技术学院 天津 300300)
0 引 言
在电商网站购物的过程中,商品的评分对用户的购买决策起到了指导作用。特别是对于未曾接触过的商品,用户会更倾向于尝试购买评分高的商品。准确地预测出用户对未接触过的商品的评分,能够指导推荐系统将商品推荐给潜在的客户,是电商公司创收的有效途径。在评分预测任务中,矩阵分解(Matrix Factorization,MF)是最经典的模型[1]。MF仅依赖于用户-物品的评分矩阵,将用户和物品特征映射为在同一隐空间的隐因子向量。然而,评分仅能表示用户对物品的整体满意程度,不能对潜在方面作出合理解释。例如,一间餐馆获得高评分,但是却不能指出究竟是其服务态度好还是菜品美味所导致的。所以,MF不能很好地学习出用户在物品不同方面的潜在偏好。另外,当评分矩阵稀疏(一个用户评分过的物品仅占总物品数量的极少部分)时,MF的评分预测精度将受到严重影响。
为了解决以上问题,研究人员将研究重点转移至评论文本。伴随着评分的评论文本,直观地展示了该用户对物品具体某一方面的评价,能很好地刻画用户偏好和物品特点。很多使用评论文本来进行推荐任务的相关方法被陆续提出。以往经典的工作都是使用主题模型LDA(Latent Dirichlet Allocation)[2]来自动地从评论文本提取出不同方面的信息[3-6]。近年来由于深度学习的强大学习能力,研究人员逐渐使用深度学习技术来取代LDA处理评论文本,学习出更好的用户偏好和物品特点[7-12]。
尽管这些方法都比仅使用评分数据的MF取得了更好的效果,但是它们都忽略了一个重要问题:一个用户对某一方面的关注程度(偏好程度)会随物品的改变而改变。推荐系统领域中的用户隐因子向量,其不同维度分别表示用户对不同方面的喜好程度。现在的相关工作都是假设该向量面对不同物品时是相同的。然而,现实中一个用户对该物品可能只关注这方面的问题,但是对另一个物品又很关心另一方面的问题,即使该两个物品属于同种类的商品。例如,对于一部昂贵的平板电脑,一个用户会同时对除了基础功能外的额外几个方面都有高标准的要求,例如AI摄像功能、具有一定的系统开发支持、超长的待机能力、良好的外放音效等。但是,如果是一部廉价的平板电脑,用户的注意力将从上述几方面转移到对基础功能的要求:接收Wi-Fi信号的质量、屏幕分辨率等。
受到该直观例子的启发,本文提出一种能够准确捕获一个用户对不同物品各方面不同关注程度(偏好程度)的模型DARR(Dynamic Aspect Attentional Rating Regression with Reviews)。在DARR中,采用两个CNN从评论中分别提取用户偏好和物品特征。对于每个用户-物品对,它们从CNN学习到的特征表示将会送入因子分解机来指导最终隐因子的学习。其中,DARR通过一个注意力网络来捕获用户的注意力向量,来表示用户对物品不同方面的关注程度。最后,基于用户和物品注意力交互的隐因子,预测出用户对未知物品的评分。
1 相关工作
到目前为止,结合评论文本进行评分预测任务的相关工作众多,它们主要分为两类:基于主题模型的方法;基于深度学习的方法。
1.1 基于主题模型的方法
在深度学习流行前,对文本数据进行特征提取的热门方法为主题模型LDA。在2013年,基于主题模型的开山之作HFT[3]由McAuley和Leskovec提出。其先从评分矩阵中分解出评分数据的隐因子,然后用LDA提取评论文本的隐主题因子,最终通过矩阵分解[1]来执行评分预测任务。随后很多工作受到他们启发,开始注意到隐藏在评论文本中的隐因子。文献[13]提出的RMR采取类似的思路,其将主题模型与基于评分数据的混合高斯模型相结合,使得评分预测精度进一步提高。但是文献[4]认为LDA只能挖掘词语级别的主题分布,不能准确表达复合主题的分布,因此提出TopicMF模型。TopicMF通过非负矩阵分解得到每条评论的潜在主题,并与用户和商品的潜在因子建立映射关系,最后主题分布反映了用户偏好和商品特性。尽管自2016年起,基于评论文本的评分预测研究开始更倾向于深度学习方法,但是文献[14]仍采取LDA处理评论文本。在该模型中,概率模型用于捕获用户偏好及商品的隐因子,随机游走部分则负责构建全局的潜在关联来预测用户对未评分商品的偏好。
上述的相关工作,大都是通过主题模型来对评论文本挖掘出用户或商品潜在的特征分布,然而基于词袋模型的主题模型不能保留词序信息,忽略了在情感分析中极其重要的局部上下文信息。另外,以深度学习的角度来看,这些方法学习到的都是浅层线性特征,未能充分挖掘出深度的非线性隐因子特征。为了解决该问题,近年来的大部分工作大都是使用卷积神经网络来处理评论文本。
1.2 基于深度学习的方法
由于CNN在自然语言处理取得巨大的成功,Kim等[7]受其启发并提出了ConvMF。在基于评论文本进行评分预测的研究领域内,ConvMF是首次采用卷积神经网络从评论文本产生物品更深层的隐表达的方法。该方法考虑了单词的上下文信息,产生出比主题模型更为合理的物品隐因子向量。然而,ConvMF认为评论文本只能揭示物品的特点,而忽略了评论文本中的用户偏好成分。为了捕获评论中用户的偏好成分,Zheng等[8]提出的DeepCoNN将评论集拆分为用户评论集(每用户的历史评论进行合并处理)、物品评论集(各物品的历史评论进行合并处理)。然后分别使用两个并行的CNN从用户评论集和物品评论集中提取它们的隐因子。拆分评论集并使用CNN的思想随后启发了很多相关研究。Catherine等[9]基于DeepCoNN进行拓展,在双CNN学习的过程中,额外要求模型能预测出待预测评分的评论的隐表达。因此该模型实际是先预测目标评论,然后再基于该评论来预测评分。本文认为该做法无疑会增加模型学习的时间花销,不能很好地满足推荐系统在线更新参数的实时性要求。同样受DeepCoNN所启发的是,Wu等[10]将CNN与双向GRU网络结合,提出DRMF。但是该方法最后的预测评分仍采用基于矩阵分解的内积形式,预测效果仍存在提升空间。Chen等[11]提出NARRE模型,通过注意力机制对每条评论都进行打分,并将注意力得分与用户隐因子结合提高表达质量。但是,Wang等[12]指出以往基于CNN的方法都可能会忽略词频信息,并提出能同时结合主题模型与CNN的WCN,其中主题模型能捕获词频信息来弥补CNN的不足。该方法一定程度上能解决可能丢失词频问题,但是在本文实验中并不是在任何数据集上都有效。
尽管上述的相关研究都能解决不同方面的问题,但是它们都基于一种假设:用户对不同方面的偏好权重不随物品的改变而发生变化。在现实中该假设是不成立的,特别是在面对不同物品千变万化的特点的情况下。因此本文同时结合评论文本和评分矩阵,设计出一种注意力神经网络来捕获用户对不同物品的动态注意力偏好向量。
2 前期准备
2.1 问题定义
给定一个包含N个样本的数据集D,其中每个样本(u,i,rui,wui)表示用户u对物品(也就是商品)i写了一条评论wui及相应的评分rui。本文的目标是预测出用户对未知物品的评分。
2.2 CNN文本处理器
CNN文本处理器的结构如图1所示。在第一层,词映射函数f:M→Rd将评论的每个单词映射为d维向量,然后将给定的评论文本转化为长度固定为T的词嵌入矩阵中(只截取评论文本中的前T个单词,对长度不足的文本则进行填充处理)。

图1 CNN文本处理器结构
词映射层后的是卷积层,其包含m个神经元,每个神经元对应的卷积核K∈Rt×d用于对词向量进行卷积运算提取特征。假设V1:T是文本长度为T的词嵌入矩阵,第j个神经元产生的特征为:
zj=ReLU(V1:T*Kj+bj)
(1)
式中:bj为偏倚项;*表示卷积运算;ReLU是非线性激活函数。
在滑动窗口t的作用下,第j个神经元产生的特征为z1,z2,…,zj(T-t+1)。将该特征进行max-pooling运算,其主要用于捕获拥有最大值的最重要的特征,定义为:
oj=max(z1,z2,…,zj(T-t+1))
(2)
最后卷积层的输出为m个神经元输出的拼接结果,定义为:
O=[o1,o2,…,om]
(3)
通常O会接着送入全连接层,其中包含权重矩阵W∈Rm×n和偏置项g∈Rn,具体公式为:
X=ReLU(WO+g)
(4)
3 模型设计
3.1 DARR的整体结构
DARR从输入阶段到评分预测阶段的整体流程如图2所示。

图2 DARR整体结构
DARR共包括4大部分:
(1) 输入。在输入阶段,DARR将用户评论、物品评论、用户编号、物品编号输入模型。对于用户评论,本文使用CNN处理器进行特征提取得到CNN_U,同理物品评论可以得到CNN_I。对于用户编号,其先进行one-hot编码转化为二进制稀疏向量,然后通过嵌入层映射为稠密的向量表达pu,同理可以得到物品的qi。随后将CNN_U、CNN_I、pu、qi送入下一阶段。
(2) 特征融合。特征融合阶段的目的是将CNN_U、CNN_I、pu、qi进行合理的融合,使得模型对用户和物品能更好地建模。在很多以往的工作中[15-16],不同的融合策略被广泛应用于提高推荐性能,例如:拼接、相加、各元素间相乘。这里为了简单实现,采取相加的策略,其他的融合策略留待未来工作进行探索。对于用户来说,CNN_U和pu是分别来自评论文本和评分矩阵的因子,其属于非同源隐因子。为了进一步充分利用深度学习在非线性空间的建模能力,本文在融合后多添加一个全连接层(内含非线性激活函数ReLU),将非同源隐因子映射到同一隐空间(对于物品同理)。
(3) 注意力交互。设U∈Rk和I∈Rk分别表示用户u和物品i的隐向量(它们从特征融合阶段得到),其中k为隐向量的维度。注意力交互阶段的输出F作为评分预测阶段的输入,设用户-物品对的隐表达为F=[f1,f2,…,fk],其计算过程为:
F=aui⊗(U⊗I)
(5)
式中:⊗表示向量元素间相乘;aui是用户u对物品i的注意力向量。从式(5)可知,F的第k维因子为fk=aui·Uk·Ik,其表示U和I个第k维因子之间的就交互。而且,对于每个用户-物品对,都存在一个注意力权值aui来调整用户和物品第k维交互的重要程度,也就是用户u对物品i的第k方面的关注程度。因此对于每个用户-物品对,aui都是不相同的,其中aui的计算见3.2节。

(6)
式中:b是全局偏置项;wi是一次项的权重;〈vi,vj〉表示向量内积,其用于捕获二阶项交互的权重。
3.2 注意力机制
本节主要介绍一种注意力机制,用于捕获用户u对物品i的第k方面的关注程度aui。由于评论文本直观地表达了用户u的偏好和物品i的特点,因此这里需要用到从评论文本提取得到的特征CNN_U和CNN_I。同时,为了在特征融合阶段得到更好的用户-物品的交互特征F,本文将注意力向量定义为:
(7)

(8)
3.3 模型训练
尽管本文在输入阶段使用到了评论文本,但是模型最终目标是实现评分预测任务。因此其属于回归问题,常用的目标函数为平方损失函数[18-19]:
(9)

4 实 验
4.1 数据集和评估指标
亚马逊评论公开数据集由McAuley等[3]搜集并公布,其包含24个子集,每个对应一种商品类型。本文采用其5-core版本(每个用户和商品最少有5条评论)的3个类别,它们分别为Beauty、Pet_Supplies(PS)、Cell_Phones_and_Accessories(CPA)。本文模型所需的每条评论共有4种特征:用户ID、物品ID、评论内容、该物品所得评分(1到5分)。3个数据集对应的统计信息如表1所示。

表1 数据集信息
由表1可知,尽管每个数据集的用户数和物品数非常丰富,但是用户和物品产生的交互(评分)实际占评分矩阵中的极小部分,也就是所谓的评分数据稀疏问题。另外,3个数据集的平均每商品的被评分数仅为17.864,而平均每条评论包含的单词数为90.652,这表明数据集中存在及其丰富的文本信息,如何有效结合评分数据和评论文本是本文的研究重点。
为了验证本文模型的性能,本文采取在评分预测相关工作中普遍使用的MSE(均方误差)作为评估指标,其值越小代表模型预测得越准确。
(10)

4.2 对比模型
为了评估DARR的评分预测性能,本文选择将目前最经典的评分预测模型作为对比模型,包括:LFM[1],HFT[3],ConvMF[7],DeepCoNN[8]和WCN[12]。
从表2可知,本文实验的对比模型大体可以分为两类:非深度学习模型,深度学习模型。另外最值得一提的是,本文模型DARR认为用户隐因子应该随用户-物品对的不同而发生改变,因此具有其他模型所没有的捕获动态隐因子的能力。

表2 对比模型比较
(1) LFM:最经典的矩阵分解算法,本文实验过程中使用仅包含全局偏倚项的版本,但是该模型仅仅使用评分数据作为输入,评分性能的提高严重受其数据稀疏所影响。本文以LFM作为各种矩阵分解算法的代表。
(2) HFT:为了缓解数据稀疏的影响,该模型首次将评分数据和评论数据共同学习来预测评分。在本文实验中,以HFT作为使用LDA处理评论文本一类模型的代表。
(3) ConvMF:此模型是首次引入CNN处理评论文本来进行评分预测的模型,因此可以将其视为使用深度学习方法基于评论文本进行评分预测的开山之作。
(4) DeepCoNN:该模型开创同时使用两个CNN来分别处理用户评论集、物品评论集的研究思路,目前很多相关研究都是沿用该思路。
(5) WCN:该模型可以看作是对DeepCoNN的直接改进,其在每个CNN通道学习的同时,额外添加一层加入隐主题因子的网络,来提高DeepCoNN可能丢失的词频信息。
4.3 实验方案和模型超参数
本文模型DARR的实现基于Tensorflow,并得益于GPU加速技术的支持,结合CNN作为文本特征提取器的模型才能快速训练收敛。为了实验的公平性,参照对比模型的文献,采取相同的划分策略:随机将实验数据集划分为训练集(80%)、验证集(10%)和测试集(10%)。但是由于本文使用的是亚马逊5-core版本的数据集,其每个用户至少包含5条评论,因此本文将数据集处理为每用户60%条评论放入训练集,并将另外的40%分别平均放入验证集和测试集。在实验中,深度学习模型的卷积核个数都设置为50,卷积核大小为3,词向量维度设置为100。不同的batch size和学习率对深度学习是否收敛到极值点至关重要,本文batch size和学习率的选取范围分别为[128,256,512,1 024]和[0.001,0.002,0.003,0.005,0.01]。每种深度学习模型取得最佳结果的batch size和学习率都不一样,因此本文进行多次实验,将其最优参数组合时对应的结果进行展示。
4.4 性能对比
在3个数据集上进行的对比结果如表3所示。其中*表示对比模型中性能最佳的结果,粗体表示在该数据集上性能最佳的结果。

表3 各种算法在3个数据集上的结果
3个数据集的稀疏度都为99%,仅利用评分数据而忽略了评论数据的LFM受数据稀疏的影响严重,其效果最差。HFT添加评论数据,很好地缓解了评分数据稀疏的影响,但是其使用LDA处理评论文本的方式丢失了上下文信息。
为了解决该问题,ConvMF使用CNN代替LDA取得了一定程度的性能提升,但是ConvMF仅考虑物品评论集而忽略了用户评论集,其结果不如同时考虑用户和物品评论集的DeepCoNN。但是卷积核滑动扫描的方式可能会丢失词频信息,因此WCN将擅长捕获词频信息的LDA融入CNN。但WCN只能在平均每条评论包含的单词数最多的CPA上取得较好的结果,在另外两个评论文本较短的数据集都不如DeepCoNN,因此CNN可能丢失的词频信息并不是极其重要的影响因素。另外,WCN通过额外添加一个LDA的网络会增大模型训练的时间成本,不能很好地满足推荐系统在线实时更新参数的要求。所以,DARR仍只采取CNN作为文本特征提取器,并发现以往的模型都只能学习出用户和物品的静态隐因子,未合理运用注意力机制解决该问题,其推荐性能的提高受到了限制。本文通过一个注意力网络来学习出用户和物品的动态隐因子。实验结果验证了该猜想,考虑了动态隐因子的DARR更符合用户的关注点会随物品变化而改变的现实情境,因此DARR在3个数据集上取得了最佳的结果。
4.5 注意力机制的影响
为了探索本文注意力机制对模型的影响,以下针对注意力部分设置了4种不同的DARR变体:
(1) DARR-1:该变体直接取消注意力机制部分,也就是将用户u和物品i的隐向量U和I拼接为一个向量,然后送入因子分解机进行预测评分。
(2) DARR-2:对注意力计算部分进行修改,仅考虑评分矩阵隐因子来计算注意力权重,也就是将式(7)修改为:
(3) DARR-3:对注意力计算部分进行修改,仅考虑评论数据隐因子来计算注意力权重,也就是将式(7)修改为:
(4) DARR-4:对注意力计算部分进行修改,考虑同时结合评分数据和评论数据的融合特征,也就是将式(7)修改为:
(5) DARR:在变体(4)的基础上,添加评论隐因子,也就是式(7)。
在不同隐因子数目(U和I的维度)的条件下,各变体和DARR的性能表现如图3所示。
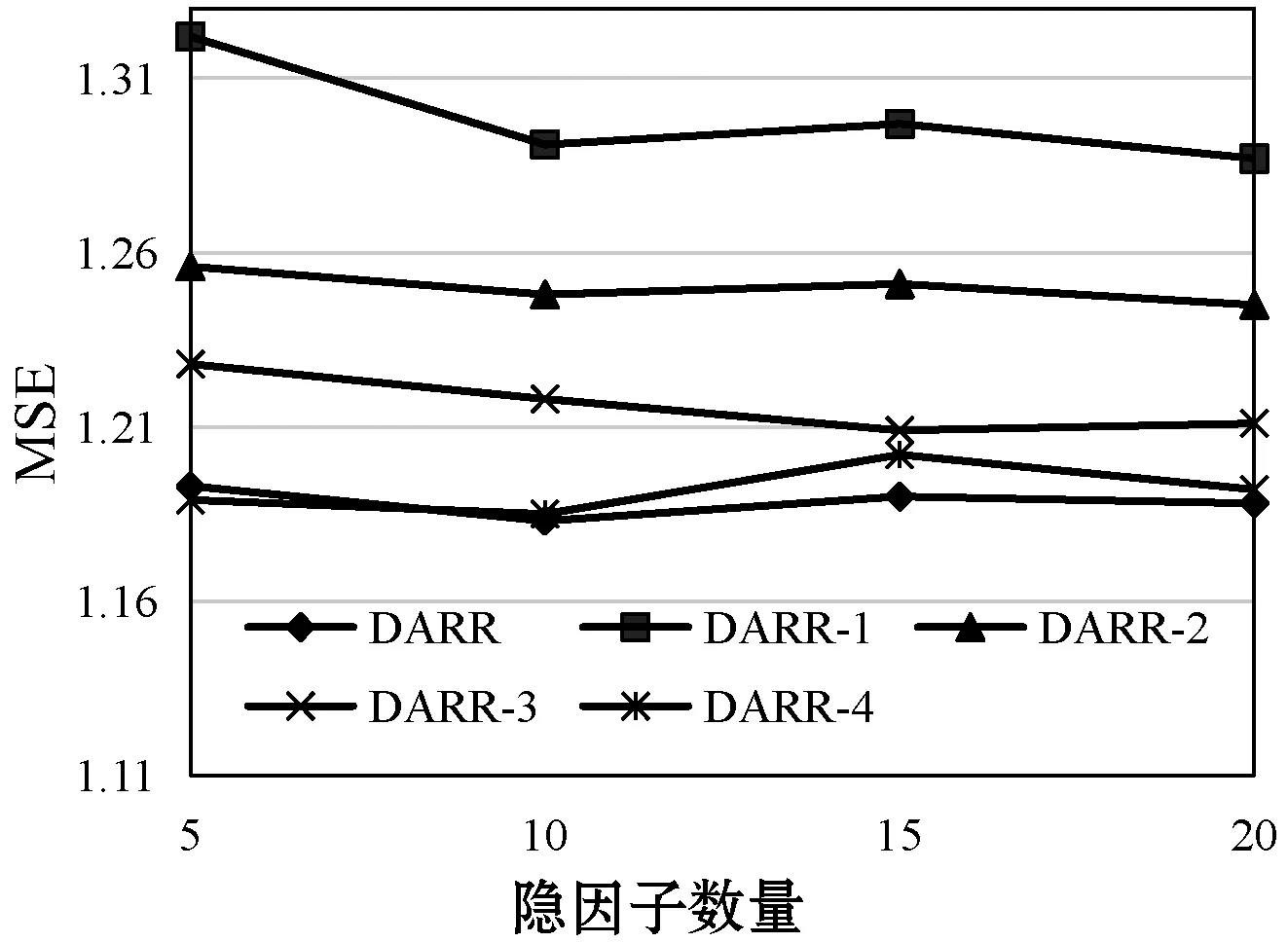
(a) Beauty

(b) PS
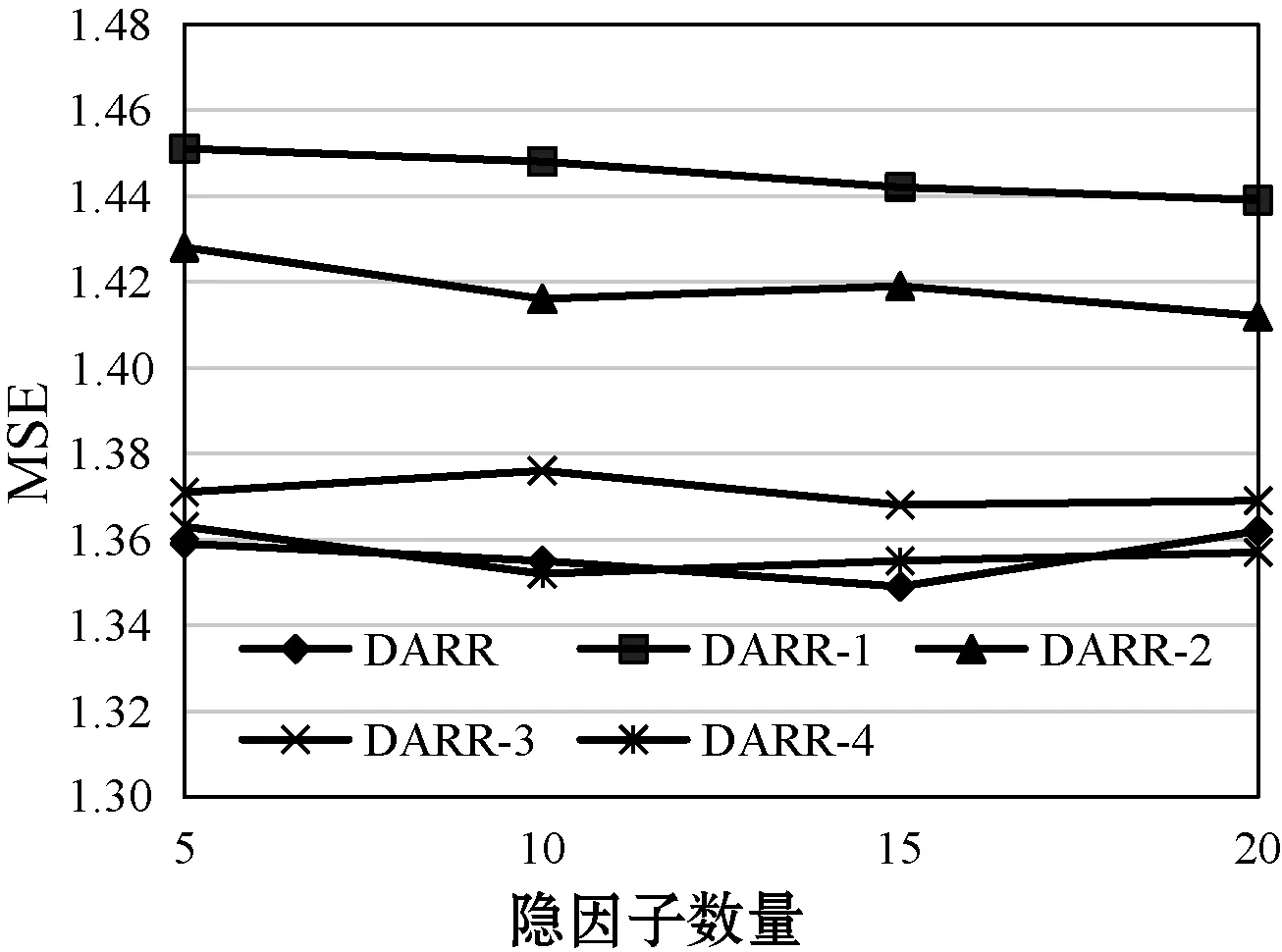
(c) CPA图3 隐因子数量对模型的影响对比
DARR-1直接取消注意力机制,用户和物品的隐向量不随“用户-物品”对的不同而改变,该静态隐因子的策略和以往工作相同(LFM,HFT,ConvMF,DeepCoNN和WCN),不符合现实中用户关注点随物品变化而发生转变的情景,因此其结果最差。DARR-2对注意力的计算进行修改,其仅考虑评分矩阵中隐因子的影响而忽略了评论文本的隐因子。尽管该策略能根据注意力权重得出动态隐因子,取得比DARR-1更好的效果,但是其忽略了能直观表达用户偏好和物品特点的评论数据,未能充分挖掘注意力机制的效力。DARR-3仅考虑评论数据隐因子,由于评论文本中含有丰富的用户偏好信息和物品特点信息,其对建模更有利,其效果相比DARR-2有大幅提升。DARR- 4使用同时结合评分数据和评论数据的融合特征,在DARR-3的基础上性能得到进一步的提高,其与标准版的DARR性能不相上下。但是,由于融合特征是由评分隐因子和评论隐因子结合产生,可能会影响评论文本中用户偏好和物品特征信息,因此标准版的DARR在DARR- 4的基础上再次加入评论隐因子CNN_U和CNN_I。从实验结果来看,大部分情况下DARR会比DARR-4取得更好的结果。该实验有力地验证了DARR的注意力机制能有效捕捉用户-物品对的注意力权重来提高评分预测精度。
5 结 语
以往基于评论进行评分预测的相关工作都假设某用户对任一物品的关注点是相同的。但是现实中用户的关注点会随物品的改变而转变。因此,本文设置一种注意力机制来捕获动态隐因子,使得每用户对每物品的隐因子都不相同。在3个公开数据集上进行对比实验,验证了本文模型的有效性。
未来工作主要在本文模型特征融合阶段设置特定的注意力机制,使得分别来自评分矩阵和评论文本的非同源隐因子进行更有效的融合来提高隐因子的表达质量。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
小天使·二年级语数英综合(2017年3期)2017-04-01
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
小天使·一年级语数英综合(2015年8期)2015-07-06
读者·校园版(2015年13期)2015-07-01
