
多维度消费人群分析及产品推荐系统①
2020-03-18 07:54刘丽萍黄晓娜潘家辉
计算机系统应用 2020年3期
刘丽萍,黄晓娜,杨 珊,潘家辉
(华南师范大学 软件学院,佛山 528225)
1 引言
随着消费市场规模的进一步扩大,以及移动互联网和智能手机的普及,当前已经出现了信息过载(information overload)的现象,用户将面对更多的产品,购物将变得更加复杂[1].为了让产品的设计开发和消费人群定位更加实效,并帮助用户在信息过载的情况下获取对自己有用的信息,通过智能化技术对商品消费者进行研究和结合推荐系统(recommender system)手段进行产品推荐是应对信息过载和短生命周期产品“短、频、快”发展非常有用的方法[2,3].
消费者研究是所有市场营销活动的中心和出发点,如何深入洞察消费者的基本行为与态度,并将他们的消费行为碎片转换成营销整体策略是消费者研究的精髓和重点所在[4].传统的消费者分析方法如文献资料法、问卷调查法、数理统计法非常耗时[5]、耗力,使得数据调查、收集、分析等工作会消耗大量的人力资源和时间,不但分析成本上升,还会消耗产品热度.同时在人工调查方法中被调查者具有一定的保守性,会导致产品的市场定位偏差.因此我们在收集显性评价数据的同时,结合非接触式技术的使用来收集和利用隐性评价数据,使得产品的满意度调查更加有说服力.
推荐系统是信息过滤的重要手段,智能推荐已成为当前人工智能和大数据领域研究的重点[6].Resnick和Varian 在1997 给出它是帮助用户决定应该购买什么产品,模拟销售员帮助客户完成购买过程的概念[7].当前著名的推荐系统有Amazon 的个性化产品推荐、Netflix 的视频推荐、Pandora 的音乐推荐、Facebook的好友推荐和Google Reader 的个性化阅读等.推荐系统的商业化应用,不仅给企业和运营商带来了利益,也满足了人民日益增长的美好需要[8].
因此,该系统结合了当前最热门的人脸、人眼和语音识别技术,致力发开一款可多维度收集消费人群数据并进行智能产品推荐的系统,帮助企业和生产商快速获得大量产品的消费人群数据、进行产品宣传推荐服务以及进行相应生产模式和营销策略的调整.系统总体业务流程如图1 所示.
系统开启时呈现轮播页状态,中间包含推荐按钮,点击按钮时,将开始人脸属性识别,快速获取客户的人脸属性并存入数据库.然后,使用基于用户人脸属性的推荐模型生成推荐产品,反馈给系统主页面.主页还包含5 个子页面,当客户点击某个推荐产品时,系统将显示该产品的详情页面,该页面提供消费者产品评分版块来获取产品的显性评分数据,同时进行语音和人眼识别来获取客户的隐性评分数据存入数据库.
2 获取消费者人脸特征
人脸识别具有非接触式、友好、方便、速度快[9]的特点,不容易引起人们的反感,易于为用户所接受,当前已得到了广泛的研究与应用[10].
人脸属性识别模块主要包含3 个步骤:用户人脸图像获取、人脸属性分析及人脸属性值提取.
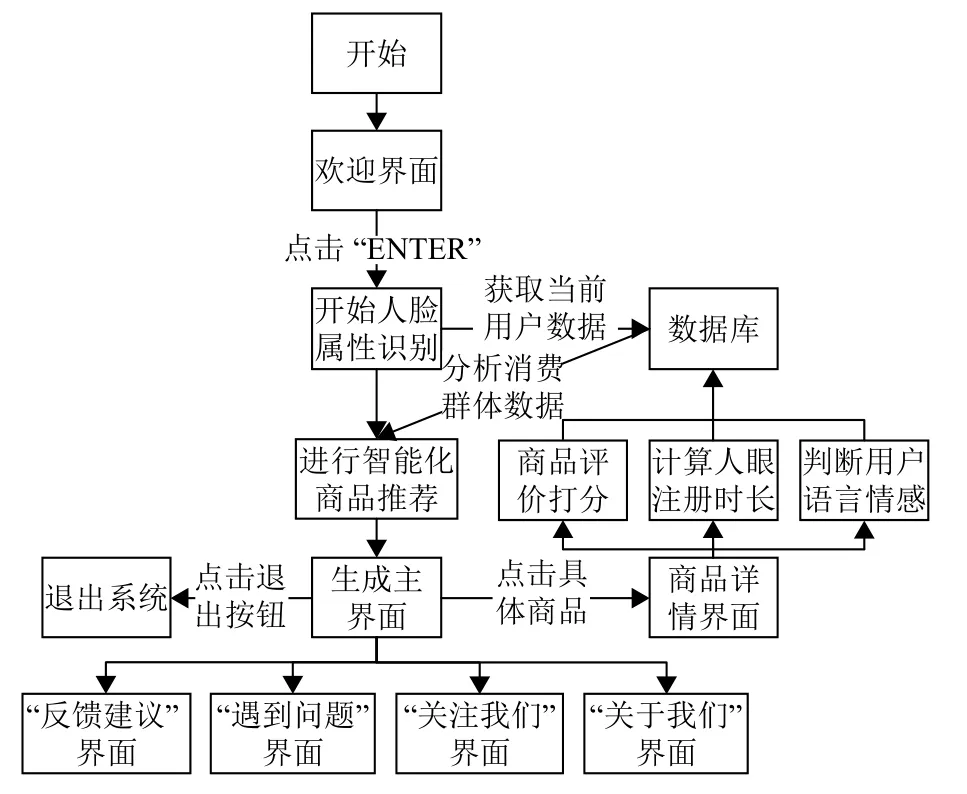
图1 系统总体流程图
2.1 用户人脸图像获取
通过视频采集设备检测人脸,扫描和判断当前图像区域,调用OpenCV 中基于HOG(Histogram of Oriented Gradient)和SVM(Support Vector Machine)算法的分类器获取当前图像区域中面积最大的人脸图像,并默认识别人脸数量为1.为使人脸属性识别结果足够客观,将截取数帧人脸图像并计算属性平均值.
2.2 人脸属性分析
获取人脸识别API 的权限,创建新应用,获取该应用的API Key 和Secret Key,并获取接口调用所需的access token.再将需要被识别的图片转换成BASE64位编码制,对人脸图片进行预处理.预处理阶段包括150 个关键点定位、人脸图像对齐等.预处理结束后将展示人脸属性信息,该信息以result 字典的方式返回.具体人脸属性分析流程图图2 所示.
2.3 人脸属性值提取
本系统并不需要所有的关键点信息,因此需从result 字典中提取出所需的具体属性值,本系统目前提取的属性值有年龄、性别、颜值、佩戴眼镜状态以及种族.
3 跟踪计算人眼停留和注视产品的时长
3.1 Haar 分类器
Haar 分类器就是Haar-like 特征、AdaBoost 算法、积分图运算和分类器级联的综合.因此,对于Haar 分类器,其算法的步骤为:首先使用Haar-like 特征对于输入的原始图像做特征检测,检测完成之后利用积分图对Haar-like 矩形特征数计算进行加速,再利用AdaBoost 算法对分类器进行训练,最后将训练出的强分类器进行级联,提高准确率[11].

图2 人脸属性识别流程图
3.2 记录用户浏览商品页面时间
在用户浏览商品页面时,系统会调用人眼识别模块的方法,在用户打开商品详情页面时进行计时,直到用户离开商品详情页面时停止,以此记录用户停留在某商品详情页面的总时间.其中Python 语音中datetime模块中的datetime.now()函数可用来获取系统当前时间.
3.3 记录用户注视的时间
Yantis S 等[12]提出获取消费者对产品的注视时间,尤其首次注视时长,可获取消费者对产品的感兴趣程度,时间越长,代表着越高的购买意愿和购买行为倾向.
该部分通过使用OpenCV 中的Haar 特征进行人脸检测实现.OpenCV 中支持的目标检测的方法是利用样本的Haar 特征进行的分类器训练,不仅适用于正面人脸检测,而且对于侧面人脸、眼睛、嘴巴、鼻子等都适用[11].利用Haar 特征分类器实现人脸识别,其特点主要表现为检测速度快,性能好[13].
通过使用OpenCV 中已经训练好的XML 格式的分类器进行人脸检测.首先通过人脸分类器获取人脸之后,再进行判断是否能检测到眼睛.在用户停留在商品详情页面的过程中实时检测用户的眼睛存在情况,记录检测到用户眼睛的总帧数,通过时间=帧数/帧率,而一般视频文件的帧率为25 帧/s,因而将帧数进行转化为时间.记录用户注视的时间的流程图如图3 所示.
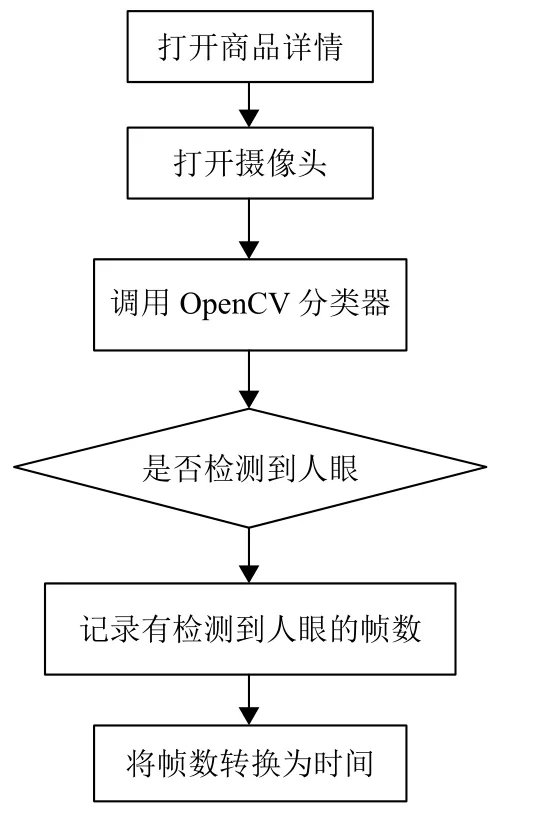
图3 记录用户注视时间流程图
3.4 对人眼识别模块进行量化估分
从心理学的角度讲,兴趣是指个人对客观事物的选择性态度,表现为一个人认识、探索、接近或获得某种客观事物的倾向,它是个性最明显的表现[14].因此,我们将用户对商品的观察时间,以及注视程度作为用户对于某种商品的情感倾向.首先,我们将人眼部分的分数拆分为2 个部分,一个是用户停留页面的时间,另一个是检测到用户眼睛的时间.首先我们初始化score为0 分,在用户停留页面部分的最高分数score为5分,各种情况加分如下:在用户停留页面时间T<12 时score+1;当12<T<=24 时score+2;当24<T<=36 时,score+3;当36<T<=48 时score+4;当T>48 时,score+5.而检测到用户眼睛的时间,即用户注视时间部分的score最高分为5 分,加分情况如下:用户注视时间占页面停留时间的比值为0-0.2 时,score+1;用户注视时间占页面停留时间的比值为0.2-0.4 时,score+2;用户注视时间占页面停留时间的比值为0.4-0.6 时,score+3;用户注视时间占页面停留时间的比值为0.6-0.8 时,score+4;用户注视时间占页面停留时间的比值为0.8-1 时,score+5.
4 获取文本情感极性和评价关键词
语音识别是计算机通过识别把语音信号转变为相应文本的技术,属于多维模式识别和智能计算机接口的范畴[15].语音识别在人机交互技术中具有非常重要的地位,拥有非常广阔的应用领域和市场.随着时代的发展和科技的进步,为了能使机器听懂人的语义和分析人类语言的情感状态,语音识别已经开始向更深入的自然语言处理等研究领域发展[16].语音识别也是获取数据的来源,语音数据的采集以及识别在不考虑背景噪音的情形下,相比其他模态数据均具有一定的便捷性,具有对用户的干扰小等优点[17],能帮助系统获取消费者对产品的评价信息,提高系统的智能性.因此如果能够获取消费者的语音信息,并且使用自然语言分析出语音的情感极性及评价关键词,那么就能有效避免评价数据信息过载的现象.
4.1 音频文件录制存储过程
音频文件录制主要使用Python 的PyAudio 和wave库来读取、写入、生成wav 文件.由于百度语音识别接口严格控制音频文件的大小,因此程序使用线程将录音时长控制在60 s 之内,若超时或用户退出页面则停止对该文件的音频数据输入,具体过程如图4.

图4 音频文件录制存储流程图
4.2 语音识别和自然语言处理
如图5 所示,当程序接收到录音文件时,开始调用百度语音识别接口,对识别的文本进行预处理.如果没有识别到有效的文本数据,则做丢弃处理.如果数据有效则再次调用百度自然语言处理接口对文本数据进行自然语言处理,分析文本的情感倾向和抽取评论观点,将最后量化的结果存入数据库.
4.3 对语音识别模块进行量化估分
百度情感倾向分析返回部分参数如表1,评论观点抽取返回部分参数如表2.我们对情感倾向分析和评论观点抽取返回的参数进行了选取,对其中共同部分sentiment 中返回的分类结果进行统计求平均,获得介于0~2 之间的平均值.我们将该平均值乘以5 量化成0~10 的分数,作为消费者在语音识别模块的分数,该分数越靠近0 分,说明语音中文本的情感更多为负向,当分数越靠近10 分,说明语音中文本的情感更多为正向,当分数在中间时,表示语音中文本的情感正负向大致参半或者中性居多,当音频文件无效并且数据被丢弃时则作为中性处理,予以5 分,此外,对于语音识别模块记录的评价关键词则直接使用评论观点抽取中prop 参数的返回数据.

图5 语音转文自然语言分析流程图

表1 情感倾向分析部分返回参数表

表2 评论观点抽取部分返回参数表
5 推荐模型的设计和实现
根据系统人脸识别功能的特点,系统只获取当前消费者的人脸属性而不存储人脸图片,因此不同的消费者可能拥有相同的人脸属性,我们无法追踪当前消费者曾经对产品的评价数据来进行推荐.然而系统需要在获取人脸属性后对其进行产品推荐服务,因此设计了基于用户人脸属性的推荐模型.从用户属性的角度出发,通过识别到的人脸属性,作为当前用户标识搜索相近年龄段消费人群对产品的评价数据,以产品评分的平均分数高低排序生成产品推荐列表.该推荐模型主要基于用户-产品评价关系的数据来推荐,其结果与数据积累有密切关系,其推荐结果表现了同龄消费者群体对产品的喜好趋势,对于广大消费者具有较好的适用性,且推荐准确率随着数据的增加而提高.
5.1 用户评分
从产品评分中获取显性评分数据,从语音和人眼识别中获取隐性评分数据.对于这些数据,可以用一个三元组表示产品系统.

其中,U={U1,U2,···,Ux}表示用户关系且U1为主键,U1{u1,u2,···,un}表示所有用户的有限集合且|U1|=n,表示产品关系且R1为主键,R1{r1,r2,···,rm}表示所有产品的有限集合且|R2|=m,表示用户对产品的评分关系且{U1,R1}是主键,表示第ui个用户对rj产品的评分分数,分值在1-100 之间,i∈[1,n],如表3 所示n=4,j∈[1,m],m=4.

表3 用户对产品的评分表
5.2 寻找相似人群
假设在U关系中Ua表示年龄、Us表示性别,若当前消费者的性别为s、年龄为a,设相似人群关系为A,那么寻找消费者相似人群的关系代数式为:

5.3 寻找相似人群评价过的产品及其评分分数
假设相似人群评价过的产品及其产品评分关系为B,则寻找B的步骤为:首先自然连接相似人群A关系和用户对产品的评价数据Q关系,后生成一个新关系D,D中包含A、Q所有属性,并在结果中把重复的属性去掉.由于我们只需要寻找产品及其评分分数,为去掉多余的数据,对D关系使用R1和Q1属性投影,此时B关系只有R1和Q1这2 个元组.
5.4 寻找K 个平均分最高的产品作为推荐产品集合
对于关系B,可对R1域所有的产品进行评分求和取平均,选取前K个平均分最高的产品推荐给客户.假设求rm产品平均分,运算式子表达如下:

6 实验和测试
6.1 系统架构和实验环境
基于Windows 系统,我们搭建了系统的开发环境,主要由PyCharm 开发工具、PyQt5 界面开发工具、MySQL 数据库组成,如图6 所示.系统的功能和表现层主要由人脸、人眼和语音识别、基于用户人脸属性的推荐模型和界面设计这5 大模块构成.在第三方资源上,系统使用到了百度API 和OpenCV 开源计算机视觉类库.

图6 系统架构图
实验所用的测试机为联想电脑,型号为拯救者R720-15IKBN,处理器为Intel(R)Core(TM)i5 一7300HQ CPU @ 2.50GHz,所用系统为Win10.
6.2 实验过程
本次实验分为两大模块,分别为功能测试和性能测试.其中功能测试包括3 个部分,第1 部分为测试系统中人脸、人眼和语音识别3 个模块的准确率;第2 部分为测试系统推荐的合理性;第3 个部分为用户使用该系统的满意度调查;性能测试为测试本系统的响应时间.各实验过程如下:
6.2.1 功能测试
(1)在测试人脸识别准确率中,有20 个实验者,其中男性10 人,女性10 人,真实年龄为19~22 岁,测试年龄为22~27 岁,误差范围1~7 岁,该系统的年龄误差为±3 岁,超过范围,将对产品推荐产生影响.实验测试产生的数据如表4 所示.
(2)在测试人眼识别准确率中,实验者的个数为10 个,假设每个用户真实观察商品的时间为30 s,用系统获取用户的实验观察时长,以实验观察时长除于用户真实观察时长来获得相应的比值来衡量系统人眼识别的准确率.测试数据如表5 所示.
(3)在语音识别中,调用百度接口,百度官方技术文档中表示其语音识别的准确率达到90%以上.
(4)测试系统收集数据的可信度测试分为两个部分:首先通过问卷调查收集10 位男实验者和10 位女实验者喜欢的商品数据,年龄在19~24 岁,实验数据如图7,下方为商品的编码,上方柱状图对应显示各商品被喜欢的次数.另外,再通过系统收集另10 位男实验者和10 位女实验者的操作数据,年龄均为19~24 岁,分析训练的结果是否和问卷调查结果相似,表6 为问卷调查中用户最喜爱的前5 个产品,表7 为系统经训练后所得出最受用户喜爱的前5 个产品.

表4 人脸识别测试结果表

表5 人眼识别测试结果表
(5)测试系统的推荐合理性
本测试使用已经经过训练的系统,对20 位未使用过系统的实验者进行推荐产品的满意度调查,实验者年龄均为19~24 岁,实验结果如表8 所示.
6.2.2 性能测试
由于本系统的在用户使用过程中需要收集用户的操作信息,因此在用户使用系统的过程中需要等待系统处理.本次测试主要为测试系统在用户停留不同时长下的用户等待时间,测试情况如图8 所示.

图7 问卷调查数据结果图

表6 用户问卷调查数据分析表

表7 系统后台推荐数据分析表

表8 用户对推荐产品的满意度调查表

图8 系统响应时间测试图
6.3 实验结果
在功能测试实验过程中,人脸识别的准确率为95%(19/20=95.0%),准确率较高,证明其人脸识别是可行的.人眼注视页面时长的准确率为72.96%,而在本系统中,对于眼睛注视页面时长的比值中0.6-0.8 为一个梯度,0.8-1.0 为另一个梯度,则实验中系统得出的结果与实际值相差一个梯度,但是,在实际量化打分中每个梯度的区别比较小,所以,可以得出我们的获取人眼时长的方式是可行的.语音识别的准确率在90%以上,说明系统对语音数据的收集和处理是可行的.在测试系统收集数据的可信度中,系统推荐页面包含问卷中排名前5 的商品个数比为:男:60%,女:80%,平均覆盖率70%,由此我们可以看到,通过系统获取到的数据与使用问卷调查所获取的数据在商品覆盖面上具有一致性,说明本系统所收集的数据是可信的.在测试系统的推荐合理性中,80%的实验者对在经过20 位其他实验者进行训练的系统所推出的前5 个推荐商品表示满意,说明本系统在商品的推荐方面具有合理性.在性能测试实验过程中,系统页面平均响应时间为8.689 s,属于可以接受范围,但靠近用户忍耐极限边界,需要提高系统性能.
7 讨论与结果
本系统基于成熟的人脸识别、人眼识别和语音识别等技术,采用非接触式的方式进行数据采集并使用基于用户人脸属性的推荐模型进行产品推荐.相比于传统的数据收集方法,该系统使用到了更多便捷有效的数据收集技术,在很大程度上节省了时间和人力,且系统在用户交互界面上更加智能化,形式更加新颖有趣,互动性较强,能吸引更多的消费者使用.
本团队对该系统的最新版本进行了充分测试,经调查及测试结果显示,该系统具有准确的人脸属性识别能力、人眼追踪功能以及语音识别功能,实验数据主要受硬件及环境的影响,属性识别在误差范围内的准确度高达95%,人眼注视时长准确率为72.96%,语音识别的准确率为90%以上;数据收集和传统问卷调查的结果有70%的覆盖率;且实验人群中,80%以上的实验对象表示该系统体验感良好,商品推荐符合预期期望.以上实验证明本系统提高了商品推荐的用户体验并解决了消费者数据收集的问题.但本系统仍然存在受使用环境影响、系统性能有待优化等问题.
综上所述,本系统对于人脸、人脸和语音识别等技术进行了有效的实践,在商品推荐的智能化中做出了实质性的探索.
猜你喜欢
保健医苑(2022年1期)2022-08-30
东坡赤壁诗词(2022年3期)2022-05-29
少儿美术·书法版(2021年9期)2021-10-20
奥秘(2021年5期)2021-06-15
动漫界·幼教365(中班)(2021年4期)2021-05-23
电脑爱好者(2020年17期)2020-09-14
优雅(2016年12期)2017-02-28
米娜·女性大世界(2016年8期)2016-08-17
电影故事(2016年5期)2016-06-15
奇闻怪事(2014年5期)2014-05-13
