
基于LSTM与XGBOOST混合模型的孕妇产后出血预测①
2020-03-18 07:55周彤彤袁贞明胡文胜
计算机系统应用 2020年3期
周彤彤,俞 凯,袁贞明,卢 莎,胡文胜
1(杭州师范大学 信息科学与工程学院,杭州 311121)
2(移动健康管理教育部工程研究中心,杭州 311121)
3(杭州市妇产科医院,杭州 310008)
引言
联合国千年发展目标中,第五个议题是关于改善孕产妇的健康问题.报告显示,过去25 年期间,孕产妇死亡率仍高达约十万分之四十五[1],孕妇产后大出血是造成全球孕妇死亡的重要因素之一,在我国居首位.研究显示,在经济发达的国家和地区,产妇产后出血的概率会显著提升.随着经济与社会的发展,孕产妇健康问题成为人们关心的热点问题.据调研,某东部医院一年中39.09%的孕妇有产后出血的情况,4.13%的产妇出现产后大出血情况.产后出血一旦发生,预后严重,若持续时间较长、休克较重,即便获救,仍有可能发生严重并发后遗症,因此产后出血的防治工作意义重大[2].
然而,现有医学手段难以直接对孕妇产后大出血进行精准的预测.目前,医学上无法准确判定产后大出血的成因,临床上医生只能根据某些症状如胎盘前置、妊高症等经验判断产妇大出血的可能性.随着医疗信息化的发展,孕产妇的基本生理特征、历次孕检信息都被记录在电子病历中,这为医生全面掌握孕妇身体状况,预判产后出血风险提供了便利.然而,由于产后出血相关因素众多且联系复杂,即使是经验丰富的医生,面对这些体量巨大、类型异构、内部关联复杂的临床大数据,都难以全面客观地进行分析[3],对缺乏经验的年轻医生更是一个巨大的挑战.随着机器学习、深度学习的发展,借助计算机手段挖掘电子病历数据之间的隐藏关系[4],建立疾病风险预测模型,为复杂的疾病诊断提供支持,成为近年来计算机与医学领域研究的热点.本文尝试利用医院电子病历中孕妇基本数据以及历次孕检数据结合机器学习方法,实现对孕妇产后大出血的预测.
目前,医学上常利用传统机器学习或深度神经网络构建疾病预测模型.深度模型对于时间序列数据有良好的处理能力,然而深度模型难以解释,医学上对于模型的可解释性有较高的要求,传统树模型具有良好的可解释性[5],通过回溯树的结构能够探究出决策形成的原因,为医生诊断提供参考.
孕检的电子病历数据中包含产后大出血相关的特征,孕检数据中孕周的变化间是有关联的时间序列数据.传统树模型难以挖掘时间序列中隐含的信息,LSTM(长短期记忆网络)模型[6]是一种时间递归神经网络,适合处理和预测时间序列中间隔和延迟相对较长的重要事件.XGBoost 模型是一种优秀的集成树模型,具有高效,灵活,鲁棒的特点.为结合两者优点,本文利用LSTM 和XGBoost 构建产后大出血混合预测模型.
1 数据集处理
模型用到的孕妇数据分为孕妇基础信息和孕检信息两部分,孕妇基础信息包含孕妇自身基本信息,如孕妇的身高、体重、年龄、过往孕史、家庭遗传病史等.孕检信息分为首次孕检和历次孕检,首次孕检信息存储孕妇进行第一次孕检的结果,历次孕检包含孕妇在孕期内每次孕检的结果,主要包含胎儿的生长情况、孕妇的体征指标,如血压、血糖、腹围等.
1.1 数据预处理
数据预处理是提高数据质量,避免数据缺失、错误对模型性能影响的重要步骤.本文中,数据预处理主要分3 部分:缺失值处理、归一化处理以及孕检数据的标准化.
孕检数据中存在各孕妇孕检项目不同或未记录检查结果的情况,需进行缺失值处理.根据实际情况,孕检结果中未记录数据为该项目正常值,另外孕检结果的众数或平均值也为该项目的正常值.因此,在实验中缺失的离散值、连续值分别采用其他孕妇同一孕检项目的众数与平均值填充.
通过数据预处理的数据中存在不同的孕检项目具有不同的单位和量纲的情况,实验通过归一化处理得到统一量纲的数据,消除不同的量纲对于模型带来的影响[7].归一化采用式(1)所示的计算方法,其中x表示当前特征值,xmax、xmin表示当前特征值的最大值和最小值.为标准化后的特征值,标准化后的数据范围为[-1,1].

在训练数据集中,孕妇孕检次数范围为1 至84,为方便模型处理,需要对孕检数据进行标准化.标准化依据医学上对孕期的划分以及模型适合的数据格式进行处理.在医学上将孕期划分为孕前期、孕中期、孕后期3 个阶段[8],通常情况下孕妇的孕检频率依次增加,同时孕检结果的重要性也认为是依次增加.孕妇通常在孕早期内孕检次数较少,故本文将孕早期即孕周1 至孕周12 内的孕检记录为一次;孕中期即孕13 周至孕28 周数量相对也较少,分为3 次,即[13-18]周,[19-23]周,[24-28]周;孕后期即孕29 周至孕40 周孕检次数较多,每两周作为一个周期.由于存在晚产的情况,40 周以后还会出现孕检信息,本文将41 周之后作为一个新的孕检周期.将同一孕检周期内的多次孕检结果的均值作为本次孕检周期内的孕检结果值,若孕妇在某周期内无孕检数据,则将该周期的孕检结果值均置为空值.孕检数据的标准化如表1 所示.
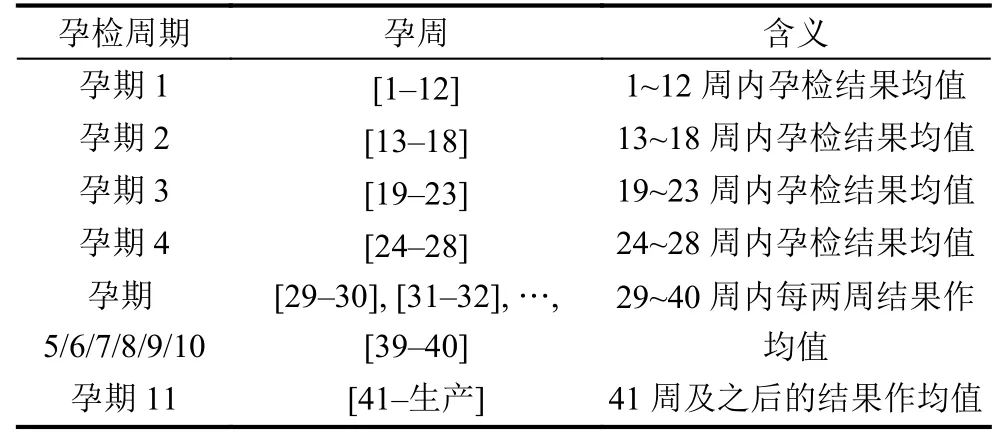
表1 历次孕检数据划分
1.2 特征构建
电子病历数据中不同的检查项目反映了孕妇不同层面的情况.其中,年龄、血型、孕次、病史等孕妇的基本信息,不受本次怀孕的影响,反映出孕妇自身身体的基本素质,因此将孕妇基础信息构建为孕妇基础特征群;而首次孕检时记录的孕妇怀孕初始时的血压、体重、高危因素等,反映出孕初期的基本情况,可以据此评估孕妇在孕程初期的基本状态,因此将首次孕检的数据构建为首次孕检特征群;历次孕检结果记录了整个孕期的动态发展过程,且具有时序的特点,将其构建为历次孕检特征群.而为了增加实验中模型对时序数据变化关系的学习能力,本文将历次孕检的变化记录提取为新的特征群,称为历次孕检结果变化特征群.通过数据预处理及特征构建,本文共构建了如表2 所示的4 个特征群.其中,历次孕检结果变化特征群记录处理后的不同孕检周期的结果变化值,实验中孕期分为11 段,因此孕检结果变化共有10 次记录,若孕妇在该孕检周期内无孕检结果则将该差值置为空值,若下一孕检周期有记录则下一周期差值为与最近的前次孕检周期结果的差值,例如某孕妇仅进行两次孕检,在孕期1 内进行一次孕检,孕期10 进行一次孕检,则该孕妇仅有第9 次孕检结果变化有记录,其余置为空值.

表2 实验特征说明
2 构建基于LSTM 和XGBoost 的混合模型
孕妇产后出血受到多方面因素的影响,实验数据同时包含时序数据和非时序数据两部分,如上一章所介绍,电子病历中记录的数据包括:孕妇的身高、血型、孕次等基础信息,为非时序数据;孕妇历次孕检的数据,如体重、血糖、腹围等,此为时序数据.模型需要具有处理时序数据之间的变化关系,同时,在医疗应用中模型应具有良好的可解释性,从而帮助医生根据经验对预测结果进行判断,另外,方便医生了解疾病的影响因素.LSTM 模型在时间序列数据预测具有良好的效果,而XGBoost 模型作为传统的集成模型在拥有良好性能的同时具有较强的可解释性,在实际的疾病预测应用中,两者都存在各自的缺陷,LSTM 模型作为深度模型在拥有较好性能但难以对模型的结果做出解释,而XGBoost 作为传统集成模型无法提取时序数据中的时序信息.本文利用LSTM 模型提取数据中的时序信息结合XGBoost 模型实现在模型拥有良好性能的同时对结果具有一定的可解释性.混合模型能够为医生的诊断提供参考意见,获取高危风险因素,方便针对性的对某些特征进行检查.
混合模型的构建分成两个部分.首先,构建LSTM模型数据集,利用LSTM 模型对数据中的时序特征进行处理,得到预测结果;然后,利用LSTM 模型结果构建新的特征,结合原有数据集组成新的数据集训练XGBoost 模型,并利用训练后的模型得到最终结果.LSTM 模型作为深度学习模型和集成模型的XGBoost在结构上有较大的差异,因此,混合模型能够较好地降低模型过拟合的风险.构建混合模型的流程如图1 所示.

图1 模型流程图
2.1 LSTM 模型
长短期记忆网络(Long Short Term Memory),简称LSTM,是循环神经网络(RNN)[9]的优秀改进,属于反馈神经网络.相对于传统RNN 网络,LSTM 能够改善“梯度消失”的问题[10],同时,LSTM 在学习长期依赖的[11]问题上有更加优秀的表现.LSTM 模型的结构如图2所示.
LSTM 在RNN 结构的基础上增加每层结构的控制门,控制门分3 类:Forget Gate(遗忘门)、Input Gate(输入门)、Output Gate(输出门)[12].通过控制门的开关判断网络的状态在该层的输出是否达到设定的阈值,从而选择是否将其加入本层的计算中.

图2 LSTM 结构
遗忘门在LSTM 中控制神经元以一定的概率丢弃信息,根据上一序列隐藏状态h(t-1)及本次序列的输入,利用激活函数得到门的输出ft,如式(2)所示:

其中,σ为激活函数,Wf为隐藏层到门的权重,Uf为输入层到门的权重,bf为偏执向量.
输入门负责处理输入信息,输入门利用Sigmoid和tanh 两个激活函数的输出的乘积更新神经元的信息,如式(3)、式(4)所示:

更新神经元的信息来自两个部分,一是Ct-1与遗忘门的乘积,二是it和at的乘积,如式(5)所示:

在更新神经元后通过输出门控制得到t时刻神经元的输出ht,如式(6)所示:

2.2 XGBoost 模型
XGBoost 是2014 年被提出的分布式梯度提升算法(Boosting)工具库,其具有高效、灵活、鲁棒的特点,相对于其他Boosting 方法[13],XGBoost 增加正则化项,能够防止模型过拟合.XGBoost 目标函数如式(7)所示:
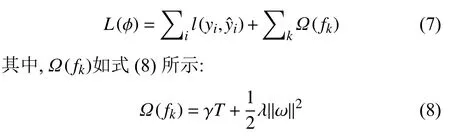
包含正则化项,为模型的输出,yi为真实标签,fk为表示第k个基分类器,T表示叶子数,ω表示叶子节点的权重,γ为惩罚项.
利用泰勒公式[14]将式(7)展开得到式(9):

式中,gi与hi以及 Ω(ft)表达公式分别如式(10)~式(12)如下:
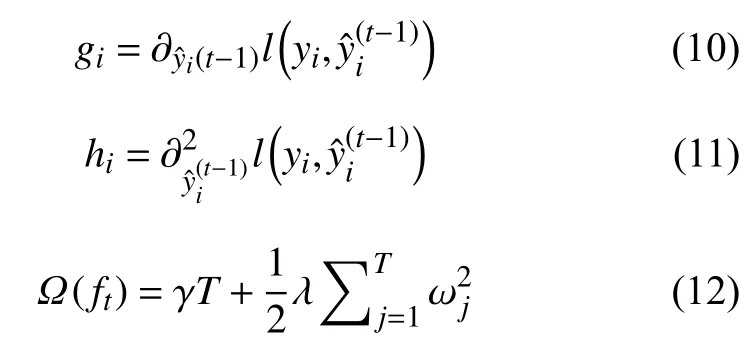
将式(10)~式(12)代入式(9)得到叶子节点权重公式如式(13)所示:

式中,Gj、Hj分别表示一阶梯度和二阶梯度在叶子节点i的值.将式(13)带入式(9)得到目标函数的最优解如式(14)所示:

3 实验与分析
3.1 实验过程
本文在我国东部某医院2018 年间产科所接诊的所有孕产妇的电子病历中,选取了包含产后出血记录的14 409 条样本构建数据集.根据医学标准将胎儿娩出后24 小时内产妇出血量超过500 ml 的样本作为产后大出血的正样本.其中正样本701 条,负样本13 708条.随机抽取70%的正样本和70%的负样本组成训练集,剩余30%的正样本和30%的负样本组成测试集.在实验中采用10 折交叉验证的方式寻找模型最优参数.
将LSTM 模型应用于产后大出血的预测,神经元节点和网络层数直接影响最终效果[15].实验中采用输入数据特征维度作为输入层的神经元数量;输出层对应一个神经元表示是否会发生产后大出血.LSTM 隐藏层[16]的节点数通常利用式(15)确定.

其中,N为隐藏节点数量,m、n为输入、输出节点数,a为区间[1,10]内的常数.实验中输入节点个数为59 个,输出节点个数为1 个,根据式(11)得到隐藏节点数量为8~18 个.实验中通过利用同一数据集选择不同隐藏层节点的方法最终选择隐藏层节点数为15 个.
将LSTM 模型得到的结果作为新的特征加入构建新的数据集,并利用该数据集训练XGBoost 模型.
3.2 评价指标选取
本文目标为分类,选取ROC 曲线[17]及曲线下面积AUC 作为模型性能的评价标准.ROC 曲线的横坐标为假阳性率,表示被划分为正类的结果中负实例占所有负实例的比例;纵坐标为真阳性率,表示被划分为正类的结果中正实例占所有正实例的比例.根据选取的不同划分正负类的阈值,形成ROC 曲线.AUC 是一个概率值,计算方法是ROC 曲线下的面积,取值范围为区间[0.1,1],AUC 值越大表明该模型的分类性能越好.
3.3 结果分析
XGBoost 模型在迭代650 轮时取得最优效果,AUC 值为0.70,ROC 曲线如图3 所示.

图3 预测产后出血的ROC 曲线
从图3 中可知,基于LSTM 和XGBoost 的混合模型在利用孕妇数据和孕检数据对产后大出血进行预测能够在40%的假阳率下准确预测出77%的大出血数据,能够为产前准备工作提供参考意见.同时,即使在本文中被误判为会发生产后大出血的孕妇,相对于其他孕妇,依然面临更高的产后大出血风险.因此,针对这些孕妇进行相关准备对进一步降低生产风险仍有重要意义.
XGBoost 模型给出的重要特征如图4 所示.通过输出特征重要程度,可以判断哪些因素对产后大出血有更显著的影响,从而辅助医生分析孕妇的生产情况,是否要提前做好产后大出血的相关准备工作.LSTM 模型构建的新特征是最终模型结果中最重要的特征,可见LSTM 和XGBoost 的混合模型对于提高预测的准确率是有效的.模型给出的重要特征如图4 所示,其中胎盘相关因素、血压相关因素、年龄等在医学实践中都是经验丰富的医生预判孕妇产后大出血的重要依据,与医学先验知识相符.另外体重、贫血、肝功能、肾功能、畸形、流产次数等因素对产后出血的也有不可忽略的影响.由于因素较多且不够直观,即使是经验丰富的医生也难以直接从冗长的病历中直接得出结论,对缺乏经验的医生而言难度更高,准确性也更难把握.因此,医生可以结合本模型的预测结果,提前采取治疗措施或分娩备血方案,降低产后大出血的发生概率.

图4 特征重要性
表3 为各模型在同一测试集上的性能和运行时间,测试集包含4000 条数据.
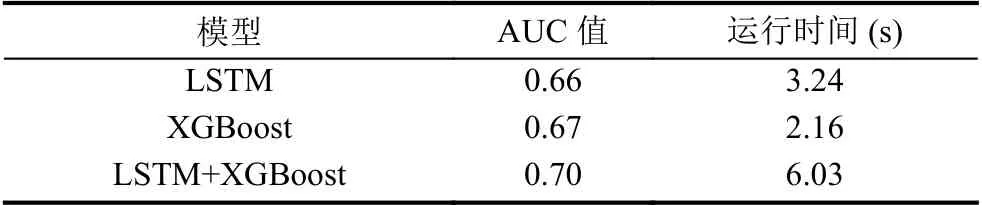
表3 各模型AUC 值及运行时间
结合图4 和表3 可看出LSTM 模型构造的特征能够较大幅度提高模型的效果,而混合模型在三者中效果最好,同时运行时间也最长.而LSTM 模型在运行时间最长的前提下,单模型预测效果却最差,可能的原因是数据中正负样本偏差较大.
4 总结
LSTM 与XGBoost 混合模型在构建数据集时应结合不同模型的特点.LSTM 模型对时间序列信息有较强的处理能力,在数据集中将每次孕检数据的时间进行周期化处理,强化时间特征;针对XGBoost 模型无法提取时间信息,需要提取孕检结果的变化,帮助模型获取隐藏的时序信息.本文中,电子病历数据包含着孕妇孕期内的多类信息,不同类型的信息有不同的特点,为适应不同模型对数据的要求,需要对数据做出不同的处理,如孕妇多次孕检结果反映了孕期内孕妇身体状况和胎儿生长的动态变化,属于时间序列数据,LSTM模型对时间序列信息有较强的处理能力,在数据集中将每次孕检数据的时间进行周期化处理,强化时间特征;针对XGBoost 模型无法提取时间信息,需要提取孕检结果的变化,帮助模型获取隐藏的时序信息.将LSTM 模型对时间序列的处理能力和XGBoost 模型的可解释性结合,对孕妇产后大出血作出预测.实验结果表明,利用LSTM 模型处理时间序列数据并将预测结果作为新特征训练XGBoost 模型相对于原有单模型能够有效提高模型的性能,因此利用混合模型对孕妇产后大出血进行预测是可行的.XGBoost 给出的重要特征能够帮助医生筛选高危患者,通过提前备血等方式降低大出血可能带来的风险.本文采用混合模型在性能提升的同时模型的运行时间长于单模型,如何降低模型的运行时间,满足大数据条件下的预测是后期工作的重点.
猜你喜欢
导航定位学报(2022年5期)2022-10-13
小猕猴智力画刊(2022年3期)2022-03-28
农业工程学报(2022年1期)2022-03-25
现代临床医学(2021年4期)2021-07-31
意林·作文素材(2021年23期)2021-01-22
特别健康·下半月(2020年2期)2020-03-13
Coco薇(2017年5期)2017-06-05
Coco薇(2015年1期)2015-08-13
母子健康(2015年1期)2015-02-28
中国民族民间医药·下半月(2011年4期)2011-09-27
