
基于YARN资源调度器的MapReduce作业数调节方法①
2020-03-18 07:55廉华,刘瑜
计算机系统应用 2020年3期
廉 华,刘 瑜
(浙江理工大学 机械与自动控制学院,杭州 310018)
Apache Hadoop 是Apache 软件基金会的顶级开源项目之一,它在分布式计算与存储上具有先天的优势.随着大数据时代的到来,Hadoop 成为了大数据的标签之一,在很多领域都得到了广泛的应用[1].当前Hadoop 已然发展为拥有MapReduce(MR)、HDFS、YARN、Pig、Hive、Hbase 等系统的较为完整的大数据生态圈[2].YARN(Yet Another Resource Negotiator)资源管理系统是Hadoop 生态圈中的核心,很多计算框架都迁移到YARN 上,借助YARN 获得了更好的资源调度、资源隔离、可扩展性以及容灾容错的特性,比如MR on YARN,Strom on YARN,Spark on YARN 等[3].但是,YARN 有上百个参数供用户配置,而且大多数参数间有着密切联系.对于生产集群来说,手动调节任何参数都需要用户对集群管理机制有深入的理解以及集群性能长期的观察,并且调节参数后还需用户花费很多时间来判断集群性能是否达到预期的效果[4].对于开发者来说在面对上百个参数的情况下很难实现YARN的最佳性能,而YARN 性能对于MR 作业有很大影响[5].因此,设计一种自动调节YARN 配置参数的方法不仅有助于减少用户在参数调节上所花费的时间,同时适当的参数配置还可以减少作业的执行时间,提高作业的吞吐量.近年来,研究人员开发了很多种算法来提高Hadoop 集群的性能.Bei ZD 等[6]提出了RFHOC 模型,利用随机森林方法为map 和reduce 阶段构建性能模型集合,在这些模型的基础上使用遗传算法自动调整Hadoop 配置参数.Chen CO 等[7]利用基于树的回归方法对集群的最优参数进行选取.这类利用机器学习构建性能模型来寻找最优参数的方法需要一个费事的模型训练阶段.同时,若作业的类型发生改变或出现集群中节点增加或减少等变化时,使用这类方法就需要重新训练模型.Zhang B 等[8]发现作业在运行过程中会出现under-allocation 和over-allocation 两种情况会降低集群性能.Under-allocation 表示MR 作业数被设置的过少,导致集群的资源利用率过低.Over-allocation 表示MR 作业过多,大部分资源分配给了AppMaster,导致分配给Container 计算任务的资源不足,甚至会出现AppMaster 只占用资源却不进行任何计算的情况,导致集群性能下降.为克服以上两种情况,张博等人提出一种闭环反馈控制方法,以内存使用状况作为输入,以最小化资源竞争和最大化资源利用率为目标来调整MR 作业数,但对内存的使用状况考虑不够细腻,会出现无法跳出over-allocation 状态的情况,例如当集群中计算任务占用总内存的比率小于T2 时集群处于over-allocation 状态,此时向集群提交大量M R 作业后,又会将集群认定为u n d e rallocation 状态,导致控制量不发生变化,这时集群实际上处于MR 作业数被设置的过少,集群的资源利用率过低的over-allocation 状态.本文提出了一种对YARN 容量调度器和公平调度器参数调节的闭环反馈控制方法,该方法采用二分法原则,逐次缩小被控参数的调节步长,具有调节速度快,控制精度高的优点.相比于文献8 本文将公平调度器参数也纳入调节范围,同时修改了集群状态的判定条件防止无法跳出overallocation 状态.本文方法有效解决了MR 作业运行过程中AppMaster 的under-allocation 与overallocation 的问题,相比于现有的参数自整定方法具有如下优点:1)当集群中有节点增加减少或更换集群时,无需花费任何时间调整方法模型;2)不必事先对YARN 框架或被提交的MR 作业进行修改.
1 相关知识
1.1 YARN 体系架构
YARN 主要依赖于3 个组件ResourceManager、NodeManager 和AppMaster 来实现所有的功能[9].组件ResourceManager 是集群的资源管理器,整个集群只有一个,负责集群整个资源的统一管理和调度分配,包含两个部分:可插拔的资源调度器和ApplicationManager,用于管理集群资源和作业.组件NodeManager位于集群中每个计算节点上,负责监控节点的本地可用资源,故障报告以及管理节点上的作业,它将节点上的资源信息上报给ResourceManager.组件AppMaster 是每个作业的主进程,用于管理作业的生命周期.一个作业由一个AppMaster 及多个Container 组成,其中Container 是节点上的一组资源的组合,例如(1 GB,1 core),用于运行作业中的计算任务.当客户端有作业提交时,ResourceManager 会启动一个AppMaster,之后再由AppMaster 根据当前需要的资源向Application-Manager 请求一定量的Container.ApplicationManager基于调度策略,尽可能最优的为AppMaster 分配Container 的资源,然后将资源请求的应答发给AppMaster[10].上述作业提交流程如图1 所示.

图1 作业提交流程
1.2 YARN 的资源调度器
YARN 中自带的可插拔资源调度器有先入先出调度器(FIFO scheduler)、容量调度器(capacity scheduler)和公平调度器(fair scheduler)[11].其中先入先出调度器以“先来先服务”的原则,按照作业提交的先后时间进行调度,无需任何配置.但这种调度策略不考虑作业的优先级,只适合低负载集群,当使用大型共享集群时,大的作业可能会独占集群资源,导致其他应用阻塞.在大型共享集群中更适合容量调度器或公平调度器,这两个调度器都允许大作业和小作业同时运行并都获得一定的系统资源[12].因此本文利用这两种调度器调节MR 作业数.在容量调度器中可设定参数yarn.scheduler.capacity.maximum-am-resource-percent(AMRP),来调节集群中可分配于AppMaster 的资源量,这个参数影响着集群中MapReduce 作业数.在公平调度器中可设定参数maxAMShare,调节MapReduce 作业数,它限制了AppMastter 可占用队列资源的比例.
2 MapReduce 作业数控制方法
本文提出的MR 作业数控制方法是基于容量资源调度器和公平资源调度其实现的,是一种闭环反馈控制,控制系统的方框图如图2 所示.ysp为用户所设定的域值T1、T2、T3,将监控器得到的内存使用情况与设定值ysp相比较,以此调节控制量A,防止Hadoop 集群中MR 作业出现under-allocation 和over-allocation 两种状态,并使被控变量Hadoop 集群中MR 作业数保持在最佳值.阈值T1、T3 与集群中所有运行作业的内存使用率相比较,阈值T2 与集群中所有计算任务的内存使用率相比较.
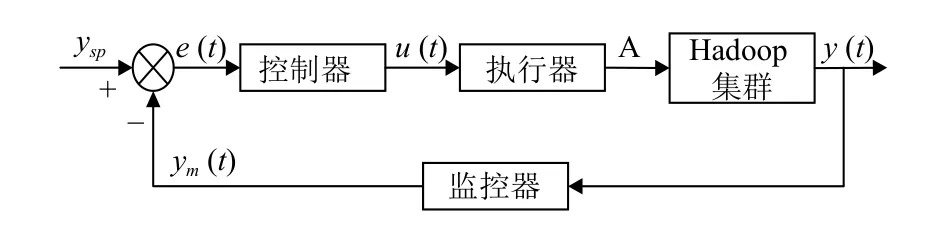
图2 闭环反馈控制系统的方框图
本文提出的闭环反馈控制方法主要分为3 个模块:监控器、控制器和执行器:
(1)监控器:在集群主节点中运行,负责周期性监控集群资源使用情况和MR 作业运行情况,并将监控到的数据传输至控制器中.YARN ResourceManager 有一个Web 端口,用这个端口可以查看YARN 监控页面,使用户可以方便地了解集群的运行情况和作业的运行情况.监控器得到的数据是由Python 脚本爬取YARN 监控页面获得,而未使用YARN 自带的用户命令编写shell 脚本.原因是由YARN 自带的用户命令获取数据相较于使用Python 爬取较慢,且受集群运行状况影响较大.监控器具体获得的指标有:队列中等待提交的作业数、队列中正在运行的作业数、集群中所有运行作业占用内存、集群中所有从节点总内存.
(2)控制器:负责根据从监控器接收到的数据对资源调度器的参数进行周期性地修改.本文调度器参数控制算法以集群内存使用情况和队列中的作业状态作为判断条件,对集群是否处于over-allocation 或underallocation 状态做出判断,若集群处于上述两种状态则采用二分法原则逐次调节被控参数直至集群从这两种状态中跳出.参数控制算法的流程描述如算法1.

?
算法1 中P、R、M_used、M_total的值由监控器传入,M_AMs、M_tasks由如下公式获得:
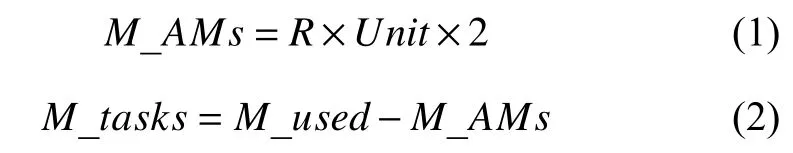
其中,Unit为每个Container 的内存大小.detect()通过读取YARN 配置文件检测调度器类型,随后读取相应调度器配置文件得到变量A的值.A_min和A_max是调度器参数AMRP 或maxAMShare 允许达到的最小值和最大值.
当M_used/M_total<T1且集群中等待提交的作业在增加时(第11 行),可认为没有足够的内存分配给AppMaster,集群中并行的MR 作业数量较少,导致出现MR 作业占用内存小于设定阈值T1的情况.此时集群处于under-allocation 状态,需增加A的值,提升MR 作业数,充分利用集群的资源.
集群处于over-allocation 状态可分为如下3 种情况:
① 队列中无等待作业且队列中正在运行的作业数比上一时刻少,即P=0 且R(t)<R(t-1),表示集群中并MR 作业数较低或正在降低,这种状态判断为overallocation.此时可减少分配到AppMaster 的资源,使计算任务可使用的资源增多,以此来减少MR 作业总体完成时间.
②T3 <M_used/M_total<T1且M_tasks/M_total<T2(第13 行),当集群中提交的任务较少时很容易满足M_used/M_total<T1和M_tasks/M_total<T2条 件 设置阈值T3表示当被使用的内存足够多时才会判断集群是否为over-allocation 状态.若集群处于overallocation 状态,则需减小A的值,使集群跳出此状态.
③M_used/M_total>T1且M_tasks/M_total<T2(第17 行),表示MR 作业占用内存大于设定阈值T1,但MR 作业中的计算任务占用内存小于设定阈值T2.这种情况下集群MR 作业数过高,集群中计算任务得不到足够的资源,此时需要减小A的值,降低MR 作业数,使计算任务获得更多的资源.
算法1 中调节变量A的方法increase_A()和decrease_A()分别如算法2 和算法3 所示.当增加或减小变量A时,将确定 α /2n是否大于用户设置的step,若大于则以 α/2n作为此次调节的步长,若小于则以step作为此次调节的步长.
(3)执行器:负责将修改对应调度器配置文件的AMRP 或maxAMShare 参数,命令 Hadoop 集群重新加载调度器配置.

?
3 实验分析
3.1 实验环境
为了验证MR 作业数控制方法的效果,选取了5 台普通PC 机来搭建测试集群.其中一台作为主节点,包含1 个NameNode 角色和1 个ResourceManager 角色.其余4 台作为从节点,每台节点包含1 个DataNode角色和1 个NodeManager 角色.本文选取Grep,Terasort,Wordcount 这3 种常见的MR 作业用于测试,其中Terasort 为IO 密集型作业,Grep 为计算密集型作业,Wordcount 作业在Map 阶段为计算密集型,Reduce 阶段为IO 密集型,如表1 所示.

表1 实验作业类型
3.2 实验结果
本实验分别在将YARN 集群资源调度器配置为容量调度器和公平调度器的情况下进行测试,将四组作业提交到集群中(第一组30 个Grep 作业、第二组30 个Terasort 作业、第三组30 个Wordcount 作业、第四组每种类型作业各10 个),对比在集群使用默认配置、最优配置和本文方法后作业的完成时间.实验中AMRP 和maxAMShare 的最优值由穷举法得到,穷举范围为{0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,0.9,1},一组作业完成时间越短可认为参数AMRP 或maxAMShare越优.图3 中在使用容量调度器的情况下,每组作业完成时间最短时,AMRP 分别为0.6,0.5,0.3,0.5.图4 中在使用公平调度器的情况下,每组作业完成时间最短时maxAMShare 分别0.8,0.9,0.6,0.8.实验中T1、T2、T3、step、A_ min、A_ max的值分别为1.0,0.5,0.8,0.05,0.05,0.95.
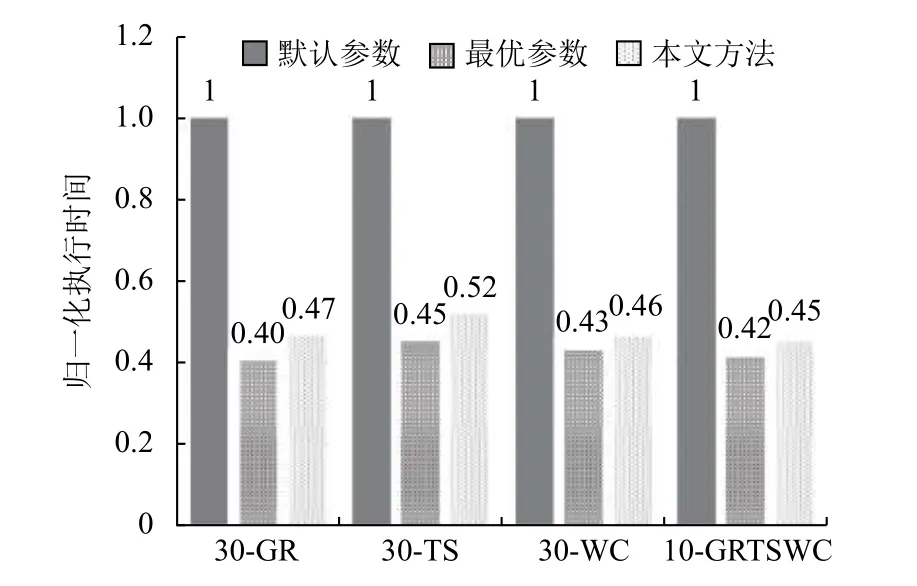
图3 使用容量调度器时作业完成时间对比

图4 使用公平调度器时作业完成时间对比
从图3、图4 中可以看出使用本文提出的方法调节MR 作业数相比于默认的配置,MR 作业整体完成时间会明显的减少,在使用容量调度器和公平调度器的情况下平均减少了53%和14%.同时在参数最优的情况下,与使用本文提出的方法在作业完成时间上相差较小.两者与默认配置相比,作业完成时间最多有7%的差异.由于对于不同的作业组合,都需要做多组实验才能确定最优的参数,所以在实际使用集群时要达到明确的最优参数并不现实,因此本文提出的方法与最优参数下的作业完成时间相比略有差异可以接受.
4 结论与展望
本文在现有调度器的基础上提出了一种闭环反馈控制方法对MR 作业数进行动态调节.通过实验证明本文提出的方法能够在省去人工调节参数的情况下有效的降低MR 作业完成时间,提升了集群的性能.下一步的工作是研究集群虚拟核使用率与集群CPU 使用率的关系,将节点虚拟核数也纳入调节的范畴.
猜你喜欢
农业工程学报(2022年11期)2022-08-22
北京航空航天大学学报(2021年4期)2021-11-24
商情(2020年31期)2020-07-23
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
知识就是力量(2017年2期)2017-01-21
电脑爱好者(2015年21期)2015-09-10
现代电子技术(2009年14期)2009-09-05
电脑爱好者(2009年13期)2009-07-07
新媒体研究(2009年10期)2009-07-02
