
基于多Inception 结构的卷积神经网络人脸识别算法①
2020-03-23 06:04蔡坚勇张明伟
计算机系统应用 2020年2期
李 楠, 蔡坚勇,2,3,4, 李 科, 程 玉, 张明伟
1(福建师范大学 光电与信息工程学院, 福州 350007)
2(福建师范大学 医学光电科学与技术教育部重点实验室, 福州 350007)
3(福建师范大学 福建省光子技术重点实验室, 福州 350007)
4(福建师范大学 福建省光电传感应用工程技术研究中心, 福州 350007)
上述方法虽能解决部分非限制性问题, 但在收敛速度上性能较差, 特别是当网络层数太多时, 会出现梯度弥散现象.为了解决这类问题, 本文提出基于多Inception 结构的卷积网络神经算法用于人脸识别, 通过改造传统的SoftmaxLoss 方法, 结合Softmax 和TripletLoss 可以获得更大的类间距离和更小的类内距离.实验证明本文提出的算法在增加网络深度和宽度的同时减少了参数个数, 在训练过程中能有效减少类内间距, 在同等条件下能获取更高的特征提取能力.
1 基于Inception 结构的卷积神经网络
1.1 卷积神经网络
CNN (Convolutional Neural Network)是一个多层次结构的神经网络[6], 通常由输入、特征提取层(多层)以及分类器组成, 每层都有多个二维独立神经元.CNN 网络通过逐层的特征提取来提升特征准确度, 最后将其输入到分类器中对结果进行分类.卷积层是CNN 的特征映射层, 具有局部连接和权值共享的特征.这两种特征降低了模型的复杂度, 并使参数数量大幅减少.下采样(池化)层是CNN 的特征提取层, 它将输入中的连续范围作为池化区域, 并且只对重复的隐藏单元输出特征进行池化, 该操作使CNN 具有平移不变性.实际上每个用来求局部平均和二次提取的卷积层后都紧跟一个下采样层, 这种两次特征提取的结构使CNN 在对输入样本进行识别时具有较高畸变容忍力.网络的最后是分类器, 通常由Softmax 方法实现, 该层将之前提取到的特征进行综合, 使图像特征信息由二维降为一维.分类器层(如Softmax 层)一般位于网络尾端, 对前面逐层变换和映射提取的特征进行回归分类等处理也可作输出层.
1.2 Inception 结构
主流的卷积神经网络在特征提取过程中主要采用加深网络层数来实现, 但是由此引入了过度拟合、梯度弥散和计算复杂度提升的问题.因此, Szegedy 等提出了Inception 结构用于解决该类问题[7].这种结构能够有效地减少网络的参数数量, 同时也能加深加宽网络, 增加网络的特征提取能力.
最初的Inception 是所有卷积核都放到上层的输出来实现, 即1×1, 3×3, 5×5 的卷积和3×3 池融合在一起,因此也造成5×5 的卷积核计算复杂度太高, 特征图厚度过大.随后在Inception 的第一个稳定版本中, Szegedy将Inception 结构进行优化, 在3×3 前, 5×5 前, max pooling 后都分别加上了1×1 的卷积核从而降低特征图厚度的.最后的模型如图1 所示.

图1 Inception V1 结构图
在接下来的Inception V2 中, Google 团队为了进一步减少计算量并提升性能, 加入了BN 层减少Internal Covariate Shift, 将两个5×5 的卷积分解成两个3×3 的卷积进行叠加, 节省了72%左右的开销, 再将3×3 的conv 用1×3 和3×1 的卷积来代替, 在此基础上,Santurkar 等[8]认为n×n 的卷积在理论上都可以由n×1和1×n 的卷积来进行替代, 从而节约CPU 和内存损耗.最终在训练参数较少的情况下提升了分类准确率.Inception V2 如图2 所示.
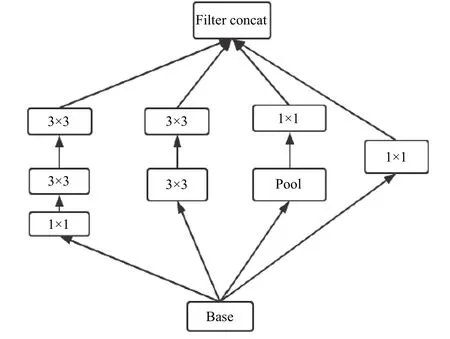
图2 Inception V2 结构图
Inception V3 一个最重要的改进是分解(factorization), 将7×7 分解成两个一维的卷积(1×7, 7×1),3×3 也是一样(1×3, 3×1), 这样的好处, 既可以加速计算(多余的计算能力可以用来加深网络), 又可以将1 个卷积拆成2 个卷积, 使得网络深度进一步增加, 增加了网络的非线性.
1.3 归一化(Batch Normalization, BN)层


其中, 分母为第 i 维数据的标准差, 分子为i 维数据和均值的差.
对照组大鼠存活良好,模型组大鼠进食、活动减少,毛发凌乱甚至脱毛,成功率100%,丁酸钠组由于药物作用,造模成功25例,成功率为83.3%,成功率显著低于模型组(P<0.05)。
2 多结构Inception 算法
2.1 多Inception 结构
本文提出的多Inception 结构特征提取算法的核心思路是将网络层的输入输出尺寸进行修改, 并将滤波器的结构进行调整, 每个Inception 结构都在对应的卷积层特征上提取不同尺度的特征图, 从而对同一目标不同尺寸的特征进行提取, 能有效将卷积特征层更好地结合, 从而在整体上提升人脸特征的精度.本文构建Inception 的核心思路是: ① 使用更小的核来减少网络参数, 例如在第一层将原本7×7 的卷积核减少为两个5×5 和3×3 的卷积核, 从而减少参数.② 利用BN 层降低梯度消失的问题.③ 利用TripletLoss 和Softmax 结合的方法来降低类内距离, 提高类间距离.④ 采用瓶颈性结构, 充分利用深层次提高抽象能力, 同时节约计算.本文提出的多Inception 结构如下:
(1)第1 层为卷积层, 使用5×5 的卷积核(滑动步长2, padding 为3), 在64 通道卷积后进行ReLU 操作经过3×3 的max pooling(步长为2), 输出为((112-3+1)/2)+1=56, 即输出大小为56×56×64, 再进行ReLU 操作.
(2)第2 层继续使用卷积层, 使用3×3 的卷积核(滑动步长为1, padding 为1), 192 通道, 输出大小转化为56×56×192, 卷积后进行归一化操作, 经过3×3 的max pooling(步长为2), 输出为((56-3+1)/2)+1=28, 即输出大小为28×28×192, 再进行ReLU 操作.
(3)第3 层分成4 个部分, 采用不同尺度的卷积核来进行处理, 4 个卷积核分别为: 1) 64 个1×1 的卷积核, 然后进行ReLU 操作, 输出28×28×64, 2) 96 个3×3 的卷积核, 进行ReLU 计算, 再进行128 个3×3 的卷积(padding 为1), 输出28×28×128.3) 16 个5×5 的卷积核, 大小变为28×28×16.4) MaxPool 层, 使用3×3 的核(padding 为1), 然后进行32 个1×1 的卷积,大小变为28×28×32.最后将4 个结果进行连接, 对这4 部分输出结果的第三维进行并联, 即64+128+32+32=256, 最终输出大小变为28×28×256.
(4)第4 层有4 部分, 分别是: ① 128 个1×1 的卷积核, 进行ReLU 操作, 输出28×28×128.② 128 个1×1 的卷积核, 作为3×3 卷积核之前的降维, 进行R e L U 操作, 再进行1 9 2 个3×3 的卷积操作(padding 为1), 输出大小为28×28×192.③ 将32 个1×1 的卷积核作为5×5 卷积核之前的降维, 进行ReLU 操作后, 再进行96 个5×5 的卷积(padding 为1),输出大小变为28×28×96.④ pool 层, 使用3×3 的核(padding 为1)进行64 个1×1 的卷积, 输出大小转换为28×28×64.将4 个结果进行连接, 对这4 部分输出结果的第三维并联.
由于本文提出的结构在每个卷积层都加入Inception, 使网络可以充分考虑每个卷积层的特征维度, 获取不同场景下(即各种非限制条件)的目标特征, 具有更强的鲁棒性, 同时BN 层能进一步优化了参数, 能实现快速收敛.本文提出的多Inception 结构如图3.
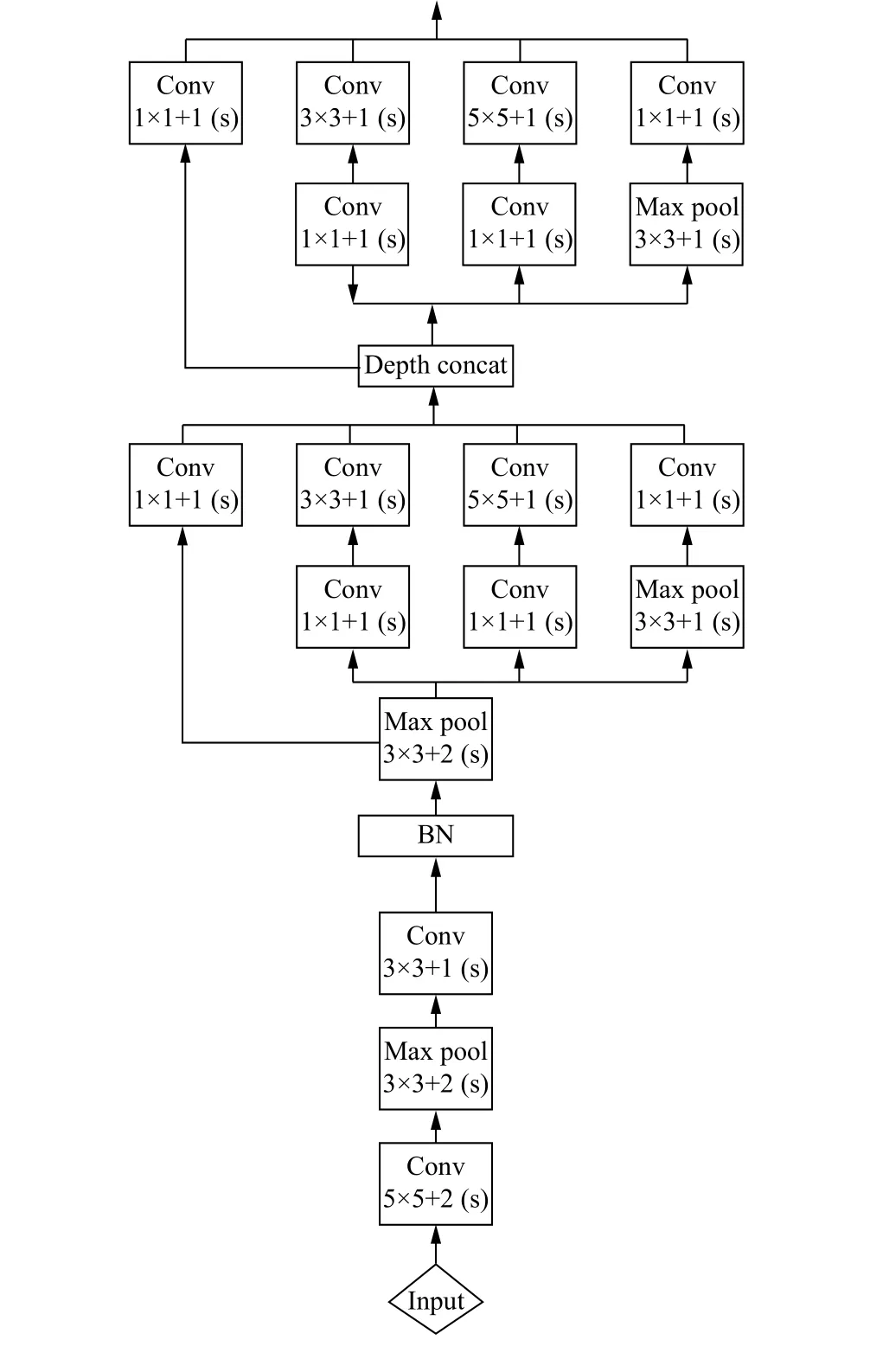
图3 多Inception 结构
2.2 损失函数的度量学习
大部分基于CNN 的特征提取方法都会采用SoftmaxLoss[10]作为训练网络的损失函数, 通过迭代过程中损失函数反馈的损失值来动态优化网络参数, 但是在人脸识别的任务中, 由于人脸表情的复杂性, 环境的多变性, 传统的Softmax 函数只能增大类间距离, 而类内距离无法有效的减少, 因此非限制条件下的人脸识别效率很低.而三元组损失函数TripletLoss 在传统的基于正负样本对的基础上, 引入了Anchor 作为第三个约束条件, 在减低同类样本的同时, 增大非同类样本的类间距离[11].假设为锚样本, 为正样本, 为负样本, 则可以将三元损失函数定义为:

因此综合了SoftmaxLoss 和TripletLoss 的损失函数能有效的优化类间距离和类内距离的分类问题, 同时避免TripletLoss 的收敛缓慢问题.因此本实验采用的损失函数计算方法是将两者进行加权, 具体为:

其中, β 是权重值, 用来平衡两个损失函数.在本文提出的网络中, Softmax 层和TripletLoss 层的使用方式如下:

图4 基于多Inception 结构和融合TripletLoss 和SoftmaxLoss 的特征提取网络
3 实验方案及结果
本实验采用配置为Intel 的I7-8900K 4 核3.7 G 处理器, 32 GB 内存, M40 显卡, Windows10 操作系统的PC 电脑作为运行环境, 使用基于Python 的Google 大数据平台TensorFlow.
3.1 数据样本
本文使用LFW (Labeled Faces in the Wild)[12]人脸数据库, 该数据库是由美国马萨诸塞州立大学提供, 一共13 000 张图片, 每张图片都被标识出对应的人的名字, 其中有1680 人对应不只一张图像, 即大约1680 个人包含两张以上人脸.
3.2 实验流程
首先将训练和测试用的样本进行预处理, 流程如下: (1)用Adaboost 算法[13]面部检测器将样本进行人脸检测和面部关键点定位(双眼, 鼻子, 嘴角, 耳朵).(2)根据Adaboost 算法定位出的6 个关键点位置进行数据剪裁, 得到统一的112×96 的人脸图片.(3)开始训练, 核心训练参数如下: 学习衰减率设置为0.001, 训练批次为50 次, 迭代次数为10 万次.在测试结果的比对中, 将测试的人脸原图特征和水平翻转图提取的特征进行对比, 计算其相似度, 最后标识出人物名字.最后识别效果图如图5.

图5 识别效果图
3.3 测试结果及分析
在LFW 库中选取8000 个人脸, 在非限制条件下对人脸进行检测的过程中, 在采用Softmax 和Triplet结合的损失函数作为训练监督信号的情况下, 能取得98.54%的准确率.在ROC 的对比方面, 如图6 所示,本文将DeepID, DeepFace, 传统Inception 等3 种算法的结果和本文提出算法进行比较.以虚检率为横坐标,检出率为纵坐标, 可以看到, 本文提出的算法在ROC上表现优于其他对比算法.实验对比结果如表1.

图6 ROC 对比图
在最高识别准确率方面传统的基于BP 神经网络的PCA 算法[14]和Fisher[15]判别分析的算法相比, 本文提出的算法具有更高的识别准确率.其次, 与基于分类网络的算法如DeepFace、DeepID 相比, 本文提出的算法的网络个数明显减少, 计算的复杂度大幅度下降.同时, 与基于cosine 距离的Contrastive loss 的算法相比,在保证相同识别率的条件下, 明显减少了人脸关键点.和传统的Inception 的对比中, 本文对卷积核进行了简化, 例如第三层用一个3×3 和1×1 的的卷积核代替了5×5 的卷积核等等, 大量减少了网络参数.

表1 人脸识别对比结果
4 结论
本文提出了基于多Inception 结构的神经网络人脸识别算法, 在进一步分解简化了卷积核之后采用Softmax和TripletLoss 相结合的方式, 实现了加深和加宽网络的能力, 在增强网络性能的同时, 减少网络参数的数量,在LWF 库中进行实验, 实验证明本文提出的算法可以在减少输入参数的情况下提高识别率, 同时降低计算复杂度, 为人脸识别算法的研究提供有益参考.
猜你喜欢
作文中学版(2022年1期)2022-04-14
少儿美术·书法版(2021年9期)2021-10-20
小学生必读(低年级版)(2021年5期)2021-08-14
奥秘(2021年5期)2021-06-15
文萃报·周五版(2021年17期)2021-05-31
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
科技传播(2019年24期)2019-06-15
电子制作(2019年9期)2019-05-30
