
一种基于listwise的在线学习书目排序检索算法*
2020-05-04 06:54周华健杨浩运殷海兵
计算机工程与科学 2020年4期
李 茜,周华健,杨浩运,殷海兵
(杭州电子科技大学图书馆,浙江 杭州 310018)
1 引言
伴随着信息网络社会来临,图书馆管理与服务也处于变革与发展时期。由于信息网络化使图书馆逐步从传统手工服务走向计算机网络化服务,因此越来越多的图书馆文献信息加入到互联网[1]。一方面将人类智慧的沉淀与结晶转化为人类可共享的资源,另一方面亦可将网上无序的资源转化为可供利用、借鉴的有序资源。就目前我国图书馆事业发展的状况看,能够将网上资源重新整序、组合和再利用的图书馆不多,而多数图书馆仅停留在本馆资源的利用上[2]。例如,利用计算机对文献进行著录、标引形成系统的书目数据库,读者通过局域网或因特网从不同的检索途径查找所需要的文献信息。以书目数据库的检索途径为例,目前有几种读者可利用的检索方式,如:文献题名、责任者、出版社、分类号、主题词等,却无法根据既具有实用价值又被广大用户常常利用的关键字,检索到所需求的文献信息,这无疑给用户利用文献信息资源带来了不便,也背离了“读者至上”的办馆原则[3,4]。因此,如何利用查询关键字对搜索引擎召回的候选记录进行有效排序是图书馆书目检索的核心问题,是图书馆关键字高效查询的关键所在[5,6]。
随着机器学习技术快速发展,通过机器学习算法来获取精准的排序模型已经得到广泛的应用。迄今为止,常用学习排序算法主要分为3种[7]:pointwise、pairwise和listwise。pointwise算法利用机器学习预测当前查询关键字单个候选记录的排序值,简单地将排序问题归结为线性分类或回归问题[8,9];pairwise算法将候选记录作为一个训练实例,并且将排序问题归结为从候选记录实例集合中学习分类或回归模型的任务[10]。然而,pointwise和pairwise算法都不能够在训练过程中直接通过最小化损失值获得精准的排序模型。因此,学术界提出了listwise算法解决这一问题,它将候选记录的排序列表作为训练实例,并且通过最小化在预测列表和真实列表上定义的损失函数来优化排序模型[11]。
虽然学术界对3种学习排序算法进行了广泛研究,但它们都面临相似的挑战。在训练过程中,上述3种排序算法都不能利用在线获得的数据更新排序模型。因此,随着书目检索数据量越来越多,训练过程中算法有效性差的问题越来越明显。为了解决该问题,学术界提出了将在线学习算法应用到学习排序算法中。在线学习是一种有效的机器学习算法,在训练排序模型时,每一次迭代过程中随机选取一个训练数据用作训练,且仅被应用一次,通过最小化整个预测序列的累计错误,使排序模型性能最优。迄今为止,在线学习只应用到了pairwise算法中,一定程度提高了算法的有效性。
由于pairwise算法在整体排序性能表现上不如listwise算法[12],为了进一步提高算法性能,本文基于listwise算法提出一种在线学习排序算法,记为online-listwise算法。在训练过程中,该算法将整个候选记录的排序列表作为训练实例,利用在线获得的数据更新排序模型。本文的主要贡献在于:首先,将在线学习与学习排序算法相结合,然后通过理论推导得出online-listwise算法的损失值是1-MAP(Mean Average Precision)的上限值,从而可通过最小化损失值使MAP最优。为了在训练排序模型时,能够实现尽快收敛,通过理论推导得出基于online-listwise算法的自适应学习率。因此,可根据图书馆的书目数据库,利用online-listwise算法在极短时间内训练出性能优越的排序模型,用于书目检索系统中,根据读者输入的关键字输出相关候选记录的有序排序列表。
2 相关工作
2.1 listwise
Listwise算法能获得良好的排序性能,在信息检索领域引起广泛的研究。listwise算法将整个候选记录的排序列表作为训练实例,并且最小化在预测列表和真实列表上定义的损失函数来优化排序模型。listwise算法的损失函数是基于Luce模型[7]定义的,如式(1)所示:
(1)
其中,N是当前查询关键字的候选记录总数,φ是变换函数,φ(s)=e(s),s是由评分函数f输出的相关度分数得分,π表示根据候选记录真实相关度分数从大到小排序对应索引序号的列表,sπ(u)表示在有序列表π中第u个索引序号处的预测分数。对于每个查询样本(特征值为x),根据式(1)会得出基于候选记录有序列表真值的损失函数,如式(2)所示:
L(f:x,π)=-logP(π|φ(f(ω,x)))
(2)
其中,ω是权重系数矩阵,f为评分函数,s=f(ω,x)=ωTx。已有结论表明,(1-MAP)可以通过基于listwise学习排序算法定义的损失函数来限定[11]。
2.2 在线学习
在线学习算法是一种高效且可扩展的机器学习算法[13],近年来被广泛应用于文档和视频等信息检索应用中。通常,在线学习排序算法在应用训练实例时,训练实例按照顺序到达神经网络,并且仅被应用1次。在每一次的迭代过程中,通过测量预测值和真实值之间的损失是否小于容错率,来判定模型权重系数是否需要更新。通常,在线学习算法的目标是最小化整个预测序列中的累积错误。
最近,文献[7]将在线学习算法与pairwise学习排序算法相结合提出online-pairwise算法。该算法首先通过理论推导得出其损失值是(1-MAP)的上限值,然后利用在线获得的数据,使用随机梯度下降算法最小化损失函数,从而使性能评价指标MAP最优,获得精准的排序模型。这样,就可以在保证pairwise算法性能优势前提下,提高算法的有效性。
到目前为止,在线学习算法仅应用于pairwise学习排序算法,但该算法相比较于listwise算法存在一定的性能差距。因此,本文提出了online-listwise算法,通过该算法可以在保证listwise算法性能前提下,在训练过程中实现在线更新排序模型并提高算法有效性。
3 在线学习书目排序检索算法
由于listwise算法在检索方面出色的性能优势,在书目检索应用中常采用listwise算法训练排序模型。但是,随着书目检索数据量越来越多,利用listwise算法训练排序模型的时间复杂度越来越高。在线学习排序是一种有效且可扩展的机器学习算法,将在线学习与listwise算法结合,可以在保证listwise算法训练排序模型性能优势前提下,减少训练过程时间消耗。
3.1 online-listwise算法
(1)online-listwise算法。
首先基于listwise算法将查询关键字对应的候选记录排序列表作为训练实例;然后利用在线学习排序算法的训练过程,每一次迭代过程中随机选取一个训练数据用作训练,并且仅被应用1次;最后通过最小化损失值获取精准的排序模型。
如何确保online-listwise算法的性能,是本文需要解决的关键问题。在listwise算法中,排序数据的特征值用x=[x1,x2, …,xN]∈Rd×N表示,N是候选记录总数; 第n个候选记录的特征值xn是一个d×1维矩阵;这些数据的相关度分数(标签值)是y=[l1,l2,…,lN],其中ln表示xn的标签值。将y中元素按从大到小进行排序,得到调整顺序后版本y′,取y′中各个元素在y中对应序号构成有序列表πy。比如:x=[x1,x2,x3,x4,x5],其标签值为y=[34,32,33,31,35], 标签值未排序索引值是{1,2,3,4,5}; 在标签值排序后有序列表πy中存储索引值{5,1,3,2,4}。有序列表πy随机获取索引序号α=πy(i)和β=πy(j)满足:如果xα≥xβ,则lα≥lβ。已有的结论表明,listwise算法的损失函数定义[7]如式(3)所示:
(3)
其中τ(·)表示损失函数,πy(i)表示在列表πy中第i个位置索引序号,f(xπy(i))=ωTxπy(i)是从数据特征到预测值的映射函数关系。在本文中,f(ω,x)=ωTx,是一个线性函数关系。所以,在下文的推导中,用τ(ω;x,y)替代τ(f;x,y)。
MAP是信息检索中常用的评价指标,表示平均正确率,即多个查询输入(query)对应平均精确度AP(Average Precision)的均值,可表达如下:
(4)
其中,q是query序号,进行了Q次查询。对于某次检索而言,平均精确度AP可表达为:
(5)
其中,假设有V个检索结果,v为检索结果队列中的排序位置,Pc(v)为前v次检索结果的准确率,rel(v) 表示位置v的文档是否与查询输入query相关,相关为1,不相关为0。
已有的结论表明式(3)中的损失函数是(1-MAP(f;x,y))的上限值[14],如式(6)所示:
1-MAP(ωT;x,y)≤
(6)
其中,ml是标签值等于l的标签数量。K是标签值列表y中的最大值。xt和yt是第t次在线迭代过程中接收到的训练数据,T表示迭代次数。ω是神经网络里的权重系数矩阵,ωt和ωT分别表示第t和T次迭代权重系数矩阵,ω*表示最优权重矩阵。当数据中给定的标签值K>2时,那么在计算MAP时,需要给定1个固定常数k*,若候选记录的标签值大于k*,则认为是相关,反之,则认为不相关。 为了得出online-listwise算法的损失值是(1-MAP)的上限值,本文首先采用在线梯度下降算法进行网络参数更新,如式(7)所示:
ωt+1=ωt-ηt▽τ(ωt;xt,yt)
(7)
其中,ηt是在第t次迭代过程中的学习率,xt和yt是第t次在线迭代过程中接收到的训练数据,并且 ▽τ(ωt;xt,yt)的定义如式(8)所示:
▽τ(ωt;xt,yt)=
(8)
经过推导,关于MAP可以得到如下结论:
(9)
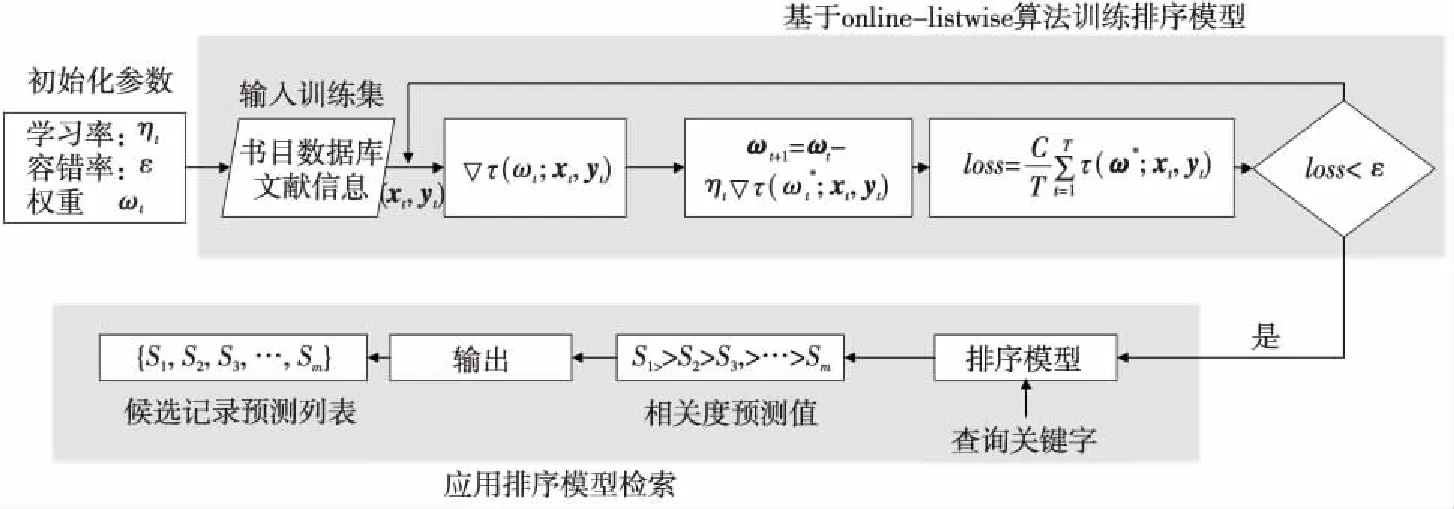
Figure 1 Process of online learning bibliographic sorting retrieval algorithm图1 在线学习书目排序检索算法的流程
参考文献[7]中定理3可得出以下不等式:
(10)
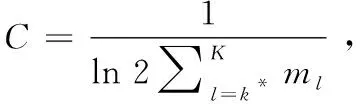
(11)
所以,当T→∞时,式(11)便会近似于式(12):
(12)
通过上述理论推导可以得出,online-listwise算法的损失函数是(1-MAP)的上限值,即式(6),因此在训练过程中可通过最小化损失函数使MAP达到最佳,从而实现高效检索。
(2) 最小化损失函数。
传统的学习排序算法,是在获得一批训练数据后,利用随机梯度下降算法更新网络参数,其中学习率是保持不变的[12]。由于在线学习排序算法是即时处理在线获得的数据,更新排序模型,与传统的学习排序算法的训练过程完全不一样,所以为了解决将基于传统学习排序算法的学习率直接应用到在线学习排序算法中,导致排序模型精准度低和收敛过慢的问题,本文根据实验统计结果得出基于online-listwise算法的自适应学习率ηt,如式(13)所示:
(13)
其中,‖xi-xj‖≤D,D是不同特征值X之间最大差值,t是迭代的次数,G是符合G-Lipschitz连续的收敛参数。参数D和G需满足如式(14)所示的不等式:
|f(xi)-f(xj)|≤G×D,G≥0
(14)
因此,通过使用自适应学习率和式(7)更新网络参数,使排序模型结果更加精准和更快收敛。Online-listwise算法实现流程如算法1所示。
算法1 online-listwise算法
输入:训练集数据{(x1,y1),(x2,y2)…,(xT,yT)},学习率ηt,容错率ε。
输出:排序模型ωT。
初始化权重系数ωt;
fori=1 toTdo
输入(xt,yt)到神经网络并且计算▽τ(ωt;xt,yt);
更新权重系数:ωt+1=ωt-ηt▽τ(ωt;xt,yt);
利用式(12)计算训练集的损失函数值loss;
ifloss<εthen
break;
end if
end for
3.2 应用online-listwise算法
在应用online-listwise算法训练排序模型时,一方面,根据上述理论推导,可直接通过最小化式(11)所示的损失函数,使排序性能MAP最优,从而保证排序模型的性能;另一方面,为减少训练排序模型的时间,训练数据按顺序到达神经网络且仅被应用1次,而且将式(12)所示学习率应用到训练过程中,使排序模型能够尽快收敛。
这样可以根据图书馆内书目数据库,基于online-listwise算法思想训练排序模型,最后将训练好的排序模型应用到关键字检索系统中,从而可利用排序模型根据查询关键字输出相关候选记录的相关度预测值,并根据预测值输出相关候选记录的有序列表S1,S2,…,Sm,以实现图书馆的高效检索功能。在线学习书目排序检索算法的流程如图1所示。
4 实验结果
4.1 测试数据集-LETOR3.0
众所周知,LETOR3.0是一个基准数据集,在信息检索领域典型的学习排序算法,例如pairewise、pointwise和listwise算法都在该数据集上进行了排序性能测试[12]。LETOR3.0中的文档数据库列表如表1所示。

Table 1 List of document databases in LETOR3.0表1 LETOR3.0中的文档数据库列表
由于学者们在LETOR3.0上测试了许多学习排序算法并给出了相应的结果,本文采用LETOR3.0作为测试数据集,以方便比较不同算法的排序性能。
4.2 性能测试结果
本文通过相同的交叉验证方案对不同的算法进行排序性能测试。为了评估检索性能,采用书目检索领域中广泛使用的性能评价指标MAP和NDCG。一方面,在线学习排序算法仅与pairwise算法相结合,因此,本文选取了pairwise类典型算法RankSVM和online-pairwise类典型算法OGDR作比较。另一方面,由于online-listwise算法采用了自适应学习率使排序模型的结果更加精准和更快收敛,因此本文将基于Adam算法进行学习率更新的online-listwise算法和采用自适应学习率的online-listwise算法进行了比较。本文最后测试了listwise、online-listwise、RankSVM、Adam和OGDR算法的排序性能。首先测试了上述几种算法在标准数据集上的性能评价指标MAP,结果如表2所示。根据表2可以得出以下结论:
(1) online-pairwise算法与pairwise算法相比,MAP平均下降了0.015。
(2) 与listwise算法相比,online-listwise算法在6个数据集上平均下降了0.026。但是,online-listwise算法往往比Adam算法性能表现更好。
(3) 在数据集NP04、HP03、HP04和OH上,online-listwise算法与RankSVM算法相比,MAP平均增加了0.015。在其他数据集上,online-listwise算法与RankSVM算法相比,MAP平均下降了0.015,造成这种现象的原因是listwise算法与RankSVM算法相比性能较差。
(4) 在数据集NP04、HP03、HP04和OH上,online-listwise算法与online-pairwise算法相比,MAP平均增加了0.020。在其他数据集上,online-listwise算法的性能不如online-pairwise算法的,造成这种现象的原因同样是listwise算法与RankSVM算法相比性能较差。

Table 2 MAP of each algorithm表2 各算法的MAP
为了进一步评估算法训练排序模型效率,还统计了listwise算法和online-listwise算法训练排序模型的累计CPU时间消耗,如图2所示。从图2可以清楚地看到,与listwise算法相比,online-listwise算法显著提高了训练排序模型的效率。
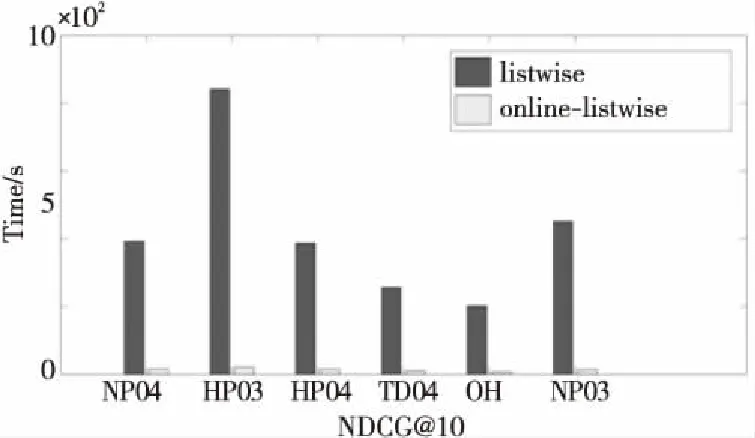
Figure 2 Cumulative time consumption on CPU图2 CPU累计时间消耗
5 结束语
本文提出了一种基于listwise在线学习的排序算法,旨在保证listwise算法性能前提下,降低排序模型训练复杂度。在具有数百万甚至数十亿次的书目大规模查询应用中,首先说明listwise算法面临有效性的挑战,然后探索利用在线学习算法来应对该挑战。本文从理论上证明了通过最小化online-listwise损失值,可以获得最佳排序性能MAP。另外,使用随机梯度下降算法最小化online-listwise损失函数的过程中,将固定学习率转换为自适应学习率,以便快速实现收敛。最后,在LETOR数据集上的测试结果表明:本文算法具有较好的检索准确率和速度,不仅可应用于海量书目高效检索,还可应用于其它信息检索任务。
猜你喜欢
都市人(2022年3期)2022-04-27
中学生数理化·七年级数学人教版(2022年11期)2022-02-14
小学生学习指导(中年级)(2021年4期)2021-04-27
课堂内外(初中版)(2020年5期)2020-06-19
科普童话·学霸日记(2020年1期)2020-05-08
小天使·一年级语数英综合(2019年2期)2019-01-10
中学生数理化·中考版(2015年10期)2015-09-10
中国民间疗法(2012年1期)2012-07-27
小说月刊(2012年3期)2012-05-08
全国新书目(2009年1期)2009-04-13
