
中文网络评论的隐式产品特征提取方法研究
2020-05-21 13:31陈可嘉骆佳艺
福州大学学报(哲学社会科学版) 2020年1期
陈可嘉 骆佳艺
(福州大学经济与管理学院, 福建福州 350108)
一、引言
在移动互联网时代,随着大量电商平台的出现,网络购物已经成为一种新的消费方式。消费者通过电商平台不仅能够快速购买商品,还能方便快捷地发表商品评论和反馈用户体验。[1]在线评论可以作为用户反馈信息,为企业提供了更加快捷有效地了解用户需求、把握市场趋势的渠道。但是面对大数据环境下产生的大量产品评论,企业无法及时准确地获取在线评论中用户想要反馈的信息和意见。因此,利用评论挖掘技术对产品评论进行挖掘和应用成为文本挖掘领域中的一个热门研究话题。
评论挖掘是指通过自动分析某种产品评论的文本内容,发现消费者对该产品或产品某一特征的褒贬态度和意见。[2]现有的评论挖掘研究主要包含4个子任务:特征抽取、观点识别、情感极性判断和结果的汇总。[3]其中,产品特征抽取是评论挖掘的重要部分。
产品特征提取是指利用计算机从大量的产品在线评论中自动获取消费者所关注的产品特征。在线评论中的产品特征可以分为显式产品特征和隐式产品特征两种。例如评论“手机电池很耐用,但有点贵”中,“电池”这个特征以文字的形式直接出现,属于显式产品特征;并且由“贵”一词可以推断评论中还描述了产品“价格”特征,因此在该评论中,“价格”属于隐式产品特征。
由于隐式产品特征的提取较为复杂和困难,现阶段大多数关于产品特征提取的研究主要集中在显式产品特征的提取。根据实验数据表明,大部分产品评论中都包含隐式产品特征。考虑隐式产品特征的评论挖掘可以增加产品特征的总体提取效果,从而发现更多人们所关注的产品信息。因此本文认为,进行隐式产品特征提取的研究是非常有必要的。
目前,学者们针对产品特征的提取进行了大量研究。李实等基于关联规则提出一种简单有效的特征提取方法,选择评论中出现频次较高的名词作为产品特征词,并采用Apriori算法对特征词进行剪枝处理。[4]Jin等则直接从利弊型评论中提取出名词和名词短语,去除停止词及低频词后,利用WordNet词典进行同义词聚类,以此集合作为产品特征列表。[5]郭崇慧和张倚天在已有特征剪枝研究的基础上,通过扩充用户词典来提升候选特征的准确性,以及引入同义词表对候选特征有效地剪枝。[6]另一类特征提取工作主要基于LDA((Latent Dirichlet Allocation,隐含狄利克雷分布)主题模型的文本降维及主题聚类作用,通过提取主题词来发现特征词,例如:彭云等针对LDA主题模型用于产品特征抽取中存在的问题,提出将语义约束和主题模型相结合的特征提取方法,相比传统的方法和其他改进方法,此方法在保证召回率的同时,对准确率也有一定程度的提高。[7]
可以发现,目前大部分产品特征提取相关研究主要关注显式产品特征的提取,忽略了隐式产品特征的提取。隐式产品特征的提取目的是使得在分析评论阶段可以获取更多用户关注的产品特征信息,增加产品特征提取的召回率。由此可见忽略隐式产品特征提取的意见挖掘是不明智的,但由于隐式产品特征的特殊性,导致其成为了提取产品特征的一个难点。
在已有的关于中文评论中隐式产品特征提取的研究方法中,以基于共现和关联规则的方法、基于主题建模的方法和监督式机器学习方法为代表。
Zhen等提出用两阶段关联规则方法来识别隐式产品特征,第一阶段为语料库每个评论中的意见词构建一个共现矩阵,然后从共现矩阵中挖掘“意见词-显示产品特征”形式的关联规则;第二阶段对挖掘出的规则进行聚类,形成更健壮的规则;最后将最终形成的关联规则应用到评论句中,提取隐含的产品特征。[8]Wang等首先基于词分割、词性标注和特征聚类提取候选特征指标,然后计算候选特征指标与特征词的共现度,每个指标和对应的特征词构成一个规则,选择五个不同规则集中的最佳规则作为基本规则;最后提出了三种方法从低共现特征指标和非指标词中挖掘可能的合理规则。上述基于共现和关联规则的方法的不足之处在于过于依赖训练集,选择不当会严重影响结果;且该方法只能识别特殊意见词,对于通用意见词,该方法的效果并不理想。[9]
Sun等基于标准LDA模型,通过添加一个意见级别构建了一种联合主题意见模型(JTO,joint topic-opinion model)用于提取隐式产品特征,将与隐式特征相关的意见词分为两类,即特殊意见词和一般意见词;并计算了两种概率分布,一种是主题的意见分布,另一种是主题和意见的上下文分布;最后,利用这些值进行基于意见词的隐式特征提取。[10]上述基于主题建模的方法适用于大规模的产品评论数据,但不足之处在于仅考虑了词性为形容词的意见词。
Xu等首先将must-link和cannot-link这两种约束作为模型的先验知识融入显式主题模型提取显式特征,产生隐式特征句的训练数据,接着通过支持向量机模型对显式特征进行训练用于对隐式特征句分类。[11]上述监督式机器学习的方法优势在于能够处理大规模的产品评论数据,但是缺点在于实验过程需要大量的人工标注。
还有一些国外学者研究了英文网络评论中的隐式产品特征的提取。[12][13]但中文网络评论相较于英文网络评论,普遍存在句子简短的特点。根据张林等的研究,针对手机的中文评论文本平均只有17个字,70%的评论都不超过30个字。[14]因此,本文针对中文网络评论的特点,提出一种基于GT-PLSA模型的隐式产品特征提取方法。首先,基于PLSA(Probabilistic Latent Semantic Analysis,概率潜在语义分析)模型建立GT-PLSA(Given Topic PLSA,给定主题的PLSA)模型;其次,估计GT-PLSA模型参数值;最后通过模型参数值推断评论句所包含的隐式特征。
与现有研究隐式特征提取的方法不同的是,本文使用统计建模和非监督式机器学习的方法来处理此类问题。本文通过引入产品特征主题和背景主题,在PLSA模型基础上建立GT-PLSA模型对隐式产品特征进行提取。背景主题的引入处理了评论中大量存在的与特征无关的词语的问题。GT-PLSA模型参数的估计采用极大似然估计方法,并利用EM算法(Expectation Maximization algorithm,期望最大化算法)求解和自动优化,实验过程无需进行大量的人工标注。
二、基于GT-PLSA模型的隐式产品特征提取
PLSA模型是由Hofmann提出的针对文本建模的模型,是在主题建模领域发展成熟、使用广泛的一种经典的统计学方法。PLSA模型在评论挖掘的主要任务是挖掘评论中所蕴含的主题,例如,对于数码产品评论,主题可能是“外观”“价格”“电池容量”等。但是,研究表明,将传统的PLSA模型直接用于提取评论主题的效果并不令人满意。这主要是因为传统的PLSA模型适用于长篇产品评论的主题提取,且得到的主题一般是产品整体层面的。但中文产品评论句子简短,且往往围绕产品的某些特征展开,如“手机外观很好看,性价比高”,这说明相比对产品的整体评价,用户往往更关心产品特征。因此,本文在PLSA模型的基础上,引入产品特征主题和背景主题,建立给定主题的PLSA(GT-PLSA)模型,用于中文网络评论中的隐式产品特征提取。
(一) PLSA模型
PLSA模型是一种生成模型,该模型假设一篇文档由多个主题混合组成,而每个主题都是词汇上的概率分布,文档中的每个词都是由某个主题生成的。[15]图1表示了PLSA模型中文档、主题和词语三者之间的关系。

图1 PLSA模型示意
其中:d表示文档,z表示隐含主题,w表示词,图中被涂色的d、w代表可观测变量,未被涂色的z代表未知的隐变量,方框代表变量重复,内部方框表示的是一篇文档中总共M个单词,外部方框表示的是文档集共N篇文档。P(di)(i=1,…,N)表示选到文档di的概率,P(zk|di)(k=1,…,K,K为主题个数)表示隐含主题变量zk在文档di上的条件概率分布,P(wj|zk)(j=1,…,M)表示词wj在隐含主题变量zk上的条件概率分布。
整个文档的生成过程如下:(1)按照一定概率P(di)选择一篇文档di;(2)选定文档后,从主题分布中按照一定概率P(zk|di)选择一个隐含主题zk;(3)选定主题后,从词分布P(wj|zk)中按照一定概率选择一个词wj。
对于一个可观察变量(di,wj),即第i文档中的第j个词,其生成过程可用公式(1)表示:
P(di,wj)=P(di)P(wj|di)=

(1)
由上式可知,该模型的参数是P(wj|zk)和P(zk|di),可以通过构建极大化似然函数,利用EM算法求解得到。根据P(zk|di),得到文档di的主题分布θi=[P(z1|di),P(z2|di),…,P(zk|di),…,P(zK|di)]T,θi表示文档di在所有主题下的概率,从而发现文档中隐含的主题,达到文档主题提取的目的。
(二)基于GT-PLSA模型的隐式产品特征提取方法
基于GT-PLSA模型的隐式产品特征提取方法流程如图2所示。

图2 基于GT-PLSA模型的隐式产品特征提取方法流程
1. 数据预处理
数据预处理包括四个主要步骤:
(1)分句。一篇评论通常由若干个评论句组成,通常涉及多个产品特征。为了使产品特征提取效果更加精确,需对长篇评论进行分句处理。
(2)数据清洗。由于在线评论自由性较强,存在很多垃圾评论、重复评论、无用评论和与产品特征无关的评论,这些都会对特征提取结果造成影响。为确保提取结果的客观可靠性,需要进行人工数据清理。
(3)分词。本文提出的隐式产品特征提取方法建立在对评论数据集中词的处理上,因此需要将得到的全部评论分词。
(4)获取特征集合。通过产品参数说明书以及人工标注的方法整理得到产品特征集合和对应的特征词列表。
2. GT-PLSA模型建立
GT-PLSA模型如图3所示,图中的符号说明见表1。

图3 GT-PLSA模型示意

表1 GT-PLSA 模型符号说明
由图3可知,GT-PLSA模型在PLSA模型的基础上加入了给定的主题,包括特征主题zk(k=1,…,K)和背景主题zB。特征主题zk指的是数据预处理阶段获得的特征fk(k=1,…,K)对应的主题;背景主题zB指的是评论句中存在的一些与产品特征无关的背景词的主题,例如对于手机产品评论,“手机”“感觉”“效果”等词与描述的产品特征无关,可视为背景词。
基于GT-PLSA模型的评论句生成过程如下:
(1)对于句子sn中的词语wm,由参数λB决定wm由背景主题zB或特征主题zk生成的概率。
(2)如果(1)步选择背景主题zB,则以概率P(wm|zB)从背景主题中选择一个词。

根据上述过程,在评论句sn中观察到词wm的概率为:
3.模型参数估计
从公式(2)可知,该模型中有四组参数,分别为:P(wm|zB)、P(wm|zk)、λB、πn,k。
(1)P(wm|zB)
P(wm|zB)的计算公式见公式(3)。

(3)
其中:c(sn,wm)表示词wm出现在sn的次数。可知,在评论句中出现频率越高的词,则可视为背景词的概率越高,P(wm|zB)值越大。
(2)P(wm|zk)
在产品特征集和对应的特征词已知的前提下,利用带有特征词的评论数据,根据公式(4)、公式(5)可计算P(wm|zk)的值。

(4)
TFIDF(fk,wm)=log{1+c(fk,wm)}×

(5)
其中:c(fk,wm)表示特征fk和词wm同时出现在一个评论句的次数,c(wm)表示词wm至少出现一次的评论句的数量,TFIDF(fk,wm)表示特征fk和词wm的TF-IDF权值。可知,词wm与特征fk关联性越强,P(wm|zk)值越大。
(3)λB
λB的值反映了生成评论句的词中可视为背景词的比例,取值范围在0~1之间。
(4)πn,k
参数πn,k的估计参考PLSA模型的参数估计方法,通过构建生成评论集R的极大似然函数,如公式(6)所示。

(6)
其中:参数Λ={πn,k|1≤n≤N,1≤k≤K},估计公式如公式(7)所示,即能使极大似然函数值达到最大的参数值,可利用EM算法求得。[16]

(7)
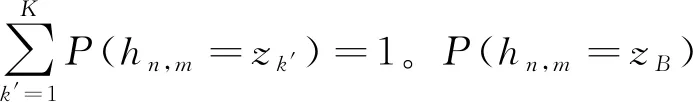
E步:

(8)
M步:

4. 特征提取
算法收敛后,得到特征主题选择参数πn,k的估计值,即句子sn由某个特征主题zk生成的比例。因此可以根据这个比例,推断句子中包含的隐式产品特征。
对于句子sn,则可以推断其对应的参数πn,k中值大于阈值θ的πn,k*所对应的特征zk*为句子sn所描述的隐式产品特征,即给定一个句子,通过查看每个特征主题对该句子生成的贡献,当特征贡献值大于某个阈值θ时推断该特征为该句子描述的隐式产品特征。
三、实验
(一)数据获取和预处理
本文利用爬虫软件从京东商城抓取了苹果iphoneX手机的评论302篇,作为本文实验的数据来源。根据数据预处理步骤,具体操作如下:
首先,以“、。;!?….;!?…~”以及空格等作为分句符号,利用python中的re正则表达式模块对抓取到的评论进行精细化的分句,将302篇评论分句为2158句单句短评论。
其次,从得到的单句短评论中人工清理掉垃圾评论、重复评论和与产品特征无关的评论。网络评论比较随意,因此需要清理例如“11111111”等一些由数字和标点符号等构成的垃圾评论;另外,为保证实验结果客观可靠,还需要将重复两次或者两次以上的评论句删除。同时,由于本文主要面向产品开发,故只考虑产品本身特征,不考虑网店服务质量、快递服务质量等与产品开发无关信息,因此需要剔除与产品特征无关的评论。经过清洗后的单句短评论数量为1163句。
再次,利用python中的jieba中文分词模块对清理后的评论句进行分词。
最后,根据苹果iphoneX的产品参数说明书,以及人工对1163句评论中的产品特征词进行识别,经过整理得到苹果iphoneX手机产品特征及其对应的特征词列表,如表2所示。

表2 苹果iphoneX手机产品特征及其对应的特征词
续表2

产品特征产品特征词信号信号网络网络内存内存、空间、存储量、存储容量、储存量音质音质、音效、声音、听筒、扬声器,音量性能性能、响应速度、运行速度、操作速度、反应速度
(二)GT-PLSA模型参数估计
经过预处理的实验数据集通过公式(3)-(10)估计P(wm|zB)、P(wm|zk)、λB和πn,k4组参数值。
1.P(wm|zB)和P(wm|zk)
表3中列出P(wm|zB)和P(wm|zk)(以价格、外观、尺寸三个特征为例)的参数值从大到小排序前5所对应的词。从表3中可以直观地看到,词“手机”“感觉”“效果”“特别”等与特征无关的词以及“高”等通用的评价词对应的P(wm|zB)参数值较高,说明这些词在所有评论句中出现频率较高,即可视为背景词的概率较高;词“价格”“性价比”“高”“贵”等词对应的“价格”特征主题P(wm|zk)参数值较大,说明这些词在描述“价格”特征的评论句中出现频率较高,即这些词与“价格”特征关联性较高。

表3 模型参数值从大到小排序前5所对应的词
2.λB
对参数λB设置不同值进行多次实验,最终发现λB取0.6时,实验效果最佳。因此在实验中,设置参数λB=0.6。
3.πn,k
P(wm|zB)、P(wm|zk)和λB参数值确定后,根据公式(8)-(10),利用EM算法可以得到参数πn,k的估计值。部分参数值如表4所示,其中仅列出πn,k参数值从大到小排序前3个参数值所对应的特征。

表4 πn,k参数估计值及隐式产品特征提取示例
(三)实验结果与分析
1. 特征提取结果
得到参数πn,k的估计值后,对阈值θ设置不同的值进行多次实验,得到准确率(Precision)、召回率(Recall)和F1值(F1 measure)这3个指标变化如图4所示。从图4可以看出,随着阈值的增大,准确率随之增加,而召回率逐渐降低。当阈值取0.4的时候取得最高的F1值,隐式特征提取效果的综合性能达到最优,此时隐式特征提取的准确率达到78.15%,召回率达到75%,F1值达到76.54%。部分评论句隐式产品特征提取结果如表4所示。

图4 不同阈值对GT-PLSA模型提取效果的影响
另外,通过实验结果可知,该方法在提取显式特征时能达到92.46%的准确率,总体特征提取准确率达86.31%。综上所述,本文提出的方法在隐式特征提取上具有一定的准确性和有效性,同时也可以用于提取显式特征,从而提高产品特征的总体提取效果。
2. 对比分析
通过采用准确率、召回率和综合效果指标F1值这三个评价指标,比较分析使用传统PLSA、JTO(Joint Topic-Opinion Model,主题-意见词联合模型)和本文方法进行隐式产品特征提取的效果,结果如图5所示。其中,PLSA、JTO和GT-PLSA分别代表传统PLSA、JTO和本文方法的结果。

图5 不同方法的隐式产品特征提取效果比较
实验结果表明:在本文实验数据集下,本文方法在准确率、召回率、F1值方面都明显优于其他两种方法。由图5可见,本文方法的隐式产品特征提取效果比传统的PLSA有显著提升,说明加入特征主题对PLSA主题建模有很大的帮助;本文方法的提取效果比JTO有一定的提升,说明从句子层面而不是仅从意见词层面来进行隐式产品特征推断更为准确。
四、结语
针对中文网络评论句子简短的特性,本文提出一种基于GT-PLSA模型的隐式产品特征提取方法。本文在PLSA模型的基础上,创新性地引入产品特征主题和背景主题,建立GT-PLSA模型对隐式产品特征进行提取。通过对手机评论数据的仿真实验,结果表明本文提出的方法能够实现有效的隐式产品特征提取,并且能达到较高的准确率,有效地提高产品特征的总体提取效果。本文通过将特征提取问题转化为统计学问题,避免了实验前期进行大量的人工标注,且背景主题的引入处理了评论中大量存在的与特征无关的词语的问题。
但是,本文仍存在一定局限,主要是本文使用的实验数据集覆盖面有限,目前只选取了苹果iPhoneX的评论数据进行实验,需要在未来的研究中进一步扩大评论数据覆盖面,针对更多类型的产品评论数据进行实验。
注释:
[1] 周立欣、林 杰:《基于NodeRank算法的产品特征提取研究》,《数据分析与知识发现》 2018年第4期。
[2] 李 杰、李 欢:《基于深度学习的短文本评论产品特征提取及情感分类研究》,《情报理论与实践》2018年第2期。
[3] 郗亚辉:《产品评论特征及观点抽取研究》,《情报学报》2014年第3期。
[4] 李 实、叶 强、李一军,等:《中文网络客户评论的产品特征挖掘方法研究》,《管理科学学报》2009年第2期。
[5] Jin J., Liu Y.,Ji P., et al.,“Understanding big consumer opinion data for market-driven product design”,InternationalJournalofProductionresearch, vol.54,no.10(2016),pp.3019-3041.
[6] 郭崇慧、张倚天:《一种基于网络评论的商品特征挖掘方法》,《情报学报》2016年第1期。
[7] 彭 云、万常选、江腾蛟,等:《基于语义约束LDA的商品特征和情感词提取》,《软件学报》2017年第3期。
[8] Zhen H., Chang K., Kim J.,Implicitfeatureidentificationviaco-occurrenceassociationrulemining. International Conference on Intelligent Text Processing and Computational Linguistics, 2011,pp.393-404.
[9] Wang W., Xu H., Wan W., “Implicit feature identification via hybrid association rule mining”,ExpertSystemswithApplications, vol.40,no.9(2013),pp.3518-3531.
[10] Sun L., Chen J., Li J., et al.,Jointtopic-opinionmodelforimplicitfeatureextracting. International Conference on Intelligent Systems and Knowledge Engineering, 2015,pp.208-213.
[11] Xu H., Zhang F., Wang W., “Implicit feature identification in chinese reviews using explicit topic mining model”,Knowledge-BasedSystems, vol.76(2015),pp.166-175.
[12] Yadollahi A., Hahraki A.G., Zaiane O.R., “Current state of text sentiment analysis from opinion to emotion mining”,ACMComputingSurveys, vol.50,no.2(2017),pp.1-33.
[13] Lazhar F.,“Implicit feature identification for opinion mining”,InternationalJournalofBusinessInformationSystems, vol.30,no.1(2019),pp.13-30.
[14] 张 林、钱冠群、樊卫国,等:《轻型评论的情感分析研究》,《软件学报》2014年第12期。
[15] HofmannT.,Probabilisticlatentsemanticindexing. The 22nd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, 1999,pp.50-57.
[16] Dempster A.P., Laird N.M., Rubin D.B., “Maximum likelihood from incomplete data via the EM algorithm”,JournalofRoyalStatisticalSocietyB(Methodological), vol.39,no.1(1977),pp.1-38.
猜你喜欢
计算机技术与发展(2022年8期)2022-08-23
数理化解题研究·高中版(2021年11期)2021-12-16
计算机系统应用(2021年9期)2021-10-11
初中生学习指导·提升版(2021年3期)2021-09-10
现代信息科技(2020年18期)2020-02-22
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年15期)2019-08-27
电子制作(2019年15期)2019-08-27
雷达学报(2018年5期)2018-12-05
电机与控制学报(2018年2期)2018-05-14

- 福州大学学报(哲学社会科学版)的其它文章
- 乳制品冷链物流配送中心选址及配送路径优化
- 创业型人才与创新型人才心理特质对照研究