
一种基于加权Jaccard距离的决策树集成选择方法
2020-05-25 08:21王立宏
烟台大学学报(自然科学与工程版) 2020年2期
于 凯,王立宏
(烟台大学计算机与控制工程学院,山东 烟台 264005)
在数据挖掘和机器学习中,决策树是常用的分类方法.它利用现有数据构建具有较强泛化能力的预测模型,对未知的对象进行预测分析[1].决策树学习算法是不稳定的,因为训练数据集的微小变化都可能导致决策树形态上的很大差异[2-3].对决策树的研究一方面在于如何度量决策树的稳定性或多样性[2-5],另一方面在于如何给出稳定的预测结果[6-9].现有文献中定义了2种类型的多样性:结构多样性和语义多样性.例如,RCJac[3]和TMD[4]是结构多样性度量,而kappa[5]是语义多样性度量.结构类似的决策树可能会给出类似的分类结果(语义),而反之则不一定成立.多分类器集成(Ensemble)是机器学习中的研究热点,决策树的集成可以整合各个决策树,给未知对象一个可信的预测结果.研究表明,为了获得较好的泛化能力,决策树集成的准确性、多样性和间隔等都是关键因素[10].决策树的准确性可以用训练误差来度量,而多样性需要深入的研究.目前多样性的研究主要集中在以下3个方面:(1)各决策树的生成过程,如Bagging[6]、随机森林[7-8]、Adaboost[9]、权重优化[10]等;(2)各决策树在验证数据集上的预测结果差异,如kappa[5];(3)各决策树的形态差异,如RCJac[3]和TMD[4].周志华等基于树匹配多样性来度量决策树的结构多样性,同时考虑结构和语义多样性,以选择预测能力强的集成[4].本文提出的加权Jaccard距离WJD(weighted Jaccard distance)从决策树的形态和在验证集合上的预测类别两方面来度量决策树的多样性,是决策树之间语义和结构的综合多样性度量.考虑到不同的决策树对验证集合产生的划分不同,而每个划分块都带有类别标签,因此通过加权比较有相同标签的划分块组成的子划分之间的Jaccard距离就可以度量决策树之间的差异.在UCI数据集上的对比实验表明,WJD是一种有效的多样性度量方法,基于WJD的决策树集成选择能够提高集成的分类精度.
1 加权Jaccard距离
1.1 基本概率分配之间的Jaccard距离
Jaccard指数是一种经典的相似性度量.2个有限集A和B之间的Jaccard指数JI计算如下:
(1)
设数据集D={x1,x2,…,xN},其幂集为2D,其中N=|D|.Jaccard指数矩阵J是一个(2N-1)×(2N-1)矩阵,A行B列对应的元素为JI(A,B),其中A和B是非空集合,A⊆D,B⊆D.已有文献证明J是正定的[11].


(2)

设m1和m2是数据集D上的2个BPA,m1和m2之间的Jaccard距离定义如下[12]:
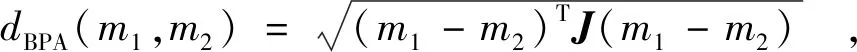
(3)
其中,J是Jaccard矩阵.
1.2 决策树之间的加权Jaccard距离
本文定义了一种新的加权Jaccard距离WJD来比较决策树,WJD是决策树之间的语义和结构的综合多样性度量,它涉及到决策树叶子的标签和叶子上实例的分布.在对WJD进行性能分析后,我们还用它选择多样化的决策树,并对决策树的集成进行实验分析.
设数据集D如上定义,标签集为C={c1,c2,…,ck},T1和T2是2棵决策树.如果用T1来测试数据集D,D中的每个实例都会落到一个相应的叶节点中.这样一个叶节点就对应一些实例的集合,各叶子形成D的一个划分P1={P1,1,P1,2,…,P1,M},与P1相对应的标签为L1=
对决策树T1和T2的比较可以通过比较(P1,L1)和(P2,L2)来完成.需要注意的是,必须是同一标签的子划分进行比较.因为在分类时,不同标签的子划分给出不同的预测,它们之间的相似性计算没有意义.
例如,D={1,2,…,12}有2个带标签的划分:
(P1,L1)=({{1,2,3},{4,5,6},{7,8,9,10},
{11,12}},
(P2,L2)=({{1,2,4,5},{3,6,11,12},{7,8,
9,10}},
此时P1中的{{1,2,3},{7,8,9,10}}与P2中的{{1,2,4,5},{7,8,9,10}}进行比较,P1中的{{4,5,6},{11,12}}与P2中的{{3,6,11,12}}进行比较.显然,这是不同集合的划分之间的比较.常用的划分比较方法如ARI[13]和Jaccard指数[14]都不适用.因此,本文定义了一种新的加权Jaccard距离来比较(P1,L1)和(P2,L2).
定义1 加权Jaccard距离(WJD)
(4)
其中:γc是加权系数,m1,c和m2,c分别是P1和P2标签为c的dBPA的约束项.
加权系数γc定义如下:
(5)
其中:P1,i是P1的第i个划分块,P2,j是P2的第j个划分块.
对于上例,可以得出:
m1,c1是P1中标签为c1的约束BPA,m1,c1的非零项如下:
m1,c1({1,2,3})=3/12=0.250,
m1,c1({7,8,9,10})=4/12=0.333.
类似地,m2,c1的非零项如下:
m2,c1({1,2,4,5})=4/12=0.333,
m2,c1({7,8,9,10})=4/12=0.333.
在2个子划分中{7,8,9,10}相同,m函数相减后{7,8,9,10}的函数值为0,因此,
dBPA(m1,c1,m2,c1)=
同理,m1,c2和m2,c2如下:
m1,c2({4,5,6})=3/12=0.250,
m1,c2({11,12})=2/12=0.167,
m2,c2({3,6,11,12})=4/12=0.333.
于是可得dBPA(m1,c2,m2,c2)=0.343.
最后加权Jaccard距离为:JW(P1,P2,L1,L2)=0.625×0.327+0.375×0.343=0.333.
WJD与文献[3]中的RCJac是不同的.如果不考虑划分的标签,或认为每个划分块标记为相同的标签,则WJD与RCJac是相等的.在分类问题中WJD更有意义,它涉及到划分块的标签并比较有相同标签的划分块组成的子划分.另外,WJD与加权的Jaccard系数[15]从定义上看也是完全不同的.
1.3 加权Jaccard距离的性质
定理1 如果P1中标签为c的子划分与P2中相同标签的子划分相等,那么dBPA(m1,c,m2,c)=0,反之亦然.
证明已知矩阵J是正定的,则dBPA(m1,c,m2,c)=0当且仅当m1,c=m2,c(见公式(3)),根据公式(2)对m的定义可知,P1中标签为c的子划分与P2中标签为c的子划分相等.

其中,
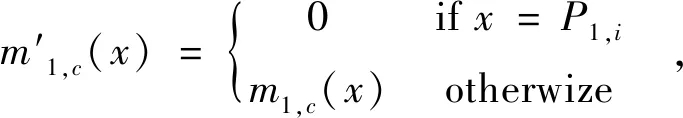
(6)
(7)

推论设S1,c和S2,c分别表示P1和P2中标签为c的子划分.如果S1,c∩S2,c={P1,i1,P1,i2,…,P1,ik},那么
其中
证明与定理2的证明类似.
从定理2及其推论可知,S1,c与S2,c之间相同的部分越多,它们之间的dBPA就越小.
定理3 如果P1和P2是数据集D的2个划分,L1和L2是对应的标签集合,那么JW(P1,P2,L1,L2)=0当且仅当P1=P2,L1=L2.
证明因为dBPA(m1,c,m2,c)≥0且γc>0,所以JW(P1,P2,L1,L2)=0当且仅当对每个标签c,dBPA(m1,c,m2,c)=0.根据定理1,dBPA(m1,c,m2,c)=0当且仅当P1中标签为c的子划分与P2中相同标签的子划分相等.所以,JW(P1,P2,L1,L2)=0当且仅当P1=P2,L1=L2.
定理3说明2个带标签的划分之间的WJD是正定的,并且WJD的值越大,2个划分之间的差异越大.因此,我们能够通过比较WJD来比较决策树的差异,进而挑选差异较大的成员构成决策树的集成.
2 决策树的集成选择
研究表明,一个精确的、多样性的子集成可能会比整个集成有更高的预测精度,因此选择性集成或者集成的剪枝成为了研究热点[16-17].本文以提出的WJD为决策树之间的距离,采用层次聚类算法选择部分决策树,形成一个集成子集.
2.1 决策树的生成
给定数据集D,本文使用10折交叉验证的方法进行实验测试.
首先,将数据集D随机分成大小相等的10份,每次选用其中1份作为测试集De,剩余部分作为训练集和验证集Dt,D=De∪Dt.
然后,用数据集Dt生成决策树,并用生成的决策树对Dt进行预测以获得Dt的划分.在实验中使用了2种决策树生成方式:Bagging[6]和AdaBoost[9].在使用Bagging时,对数据集Dt进行放回式抽样(Bootstrap),训练得到决策树模型.重复这个过程100次,得到含有100棵树的决策树池.在使用AdaBoost时,先将训练样本进行初始化,使每个样本的权重相等,训练得到一棵决策树,然后更新样本权重,增大分类错误的样本的权重,减小分类正确的样本的权重,最后得到有100棵树的决策树池.决策树池的大小设定为100棵树是参照文献[18-19]的做法.
最后,对于数据集D的剩余9份分别使用上述过程,得到10个含有100棵树的决策树池.
关于训练集、验证集和测试集的设计问题,通常的做法是将整个数据集随机划分成3个彼此不相交的部分,各部分占的比例是60∶20∶20[20]或者1∶1∶1[4]等.但是当数据集较小时,这样的划分会导致训练数据集过小,训练得到的模型拟合不足.还可以将训练集全部用来作为验证集,这样能充分利用训练数据,但是容易导致模型对训练数据的过拟合[21].
在实验中,训练集是Dt的子集.由于对数据集Dt进行放回式抽样,Bagging中实际训练决策树模型的数据大约占Dt的63%[6].WJD是计算同一个数据集的2个不同划分P1和P2之间的距离,如果直接将Dt的剩余部分(约占37%)定义为验证集,那么每次抽样都会使其发生变化,不能满足对WJD的定义要求,因此验证集取Dt.Adaboost也是放回式抽样,验证集也取Dt.
2.2 决策树的多样性选择
在集成中决策树的准确性和多样性都是必不可少的,因此在用Bagging方法得到的10个决策树池中,从每个决策树池中选择50棵对Dt预测精度最高的树,然后构建成一个新的决策树池.本文使用单链接的层次聚集聚类的方法选择决策树[22],2棵树之间的距离定义为它们的WJD.得到K个簇后,每个簇中选取与簇中其他树平均距离最小的树来代表这个簇.最后,将得到的K棵树组成集成,过程如图1所示.在这里,K的数值表示的是对新的决策树池(由选择的50棵精度较高的树构成)剪枝后子集成的大小,K<50.
在用AdaBoost算法得到的决策树池中,决策树是通过迭代的方式生成的,与Bagging算法的生成方式不同,因此我们并没有从池中的100棵决策树中挑选出50棵树出来,而是直接对池中的100棵树进行聚类,得到K个簇,然后从每个簇中选取一个与该簇中其他树平均距离最小的树构成集成.此处,K的数值表示对AdaBoost算法得到的决策树池剪枝后得到的子集成大小.
3 实验与结果分析
3.1 数据集
使用UCI上的6个数据集进行实验测试.表1是对所使用的UCI数据集的一些特征描述.

表1 实验数据集描述Tab.1 Description of datasets
3.2 实验方案
对比算法包括MDM[18,23]及2种多样性度量技术kappa[5]和RCJac[3].MDM是通过启发式方法从候选池中逐个选择分类器来构建有序子集成的;kappa是基于语义多样性度量的,只考虑了样本的标签;RCJac是基于结构多样性度量的,只考虑了叶节点上的实例分布,并未使用叶节点的标签;而WJD是语义和结构的多样性度量,它涉及到决策树叶子的标签和叶子上实例的分布.
为了保证对这些技术进行公平的实验比较,本文采用相同的实验方案,使用相同的决策树池,使用相同的数据集进行验证和测试.给定数据集D,用10折交叉验证的方式生成决策树池,使用了Bagging和AdaBoost 2种算法构建集成,如2.1节所述.与常用的静态分类器选择方法相同,我们先在验证集上找到精度最高的子集成,然后用得到的子集成来预测未知样本.
文献[18]提出在Bagging集成中,20%~40%的分类器就能构成一个较高精度的子集成.在本文实验中对更大的范围(10%~60%)进行了测试,以找到一个精度最高的子集成,然后对未知样本进行测试.在AdaBoost算法得到的决策树池中,对10%~80%的范围进行了实验,测试能否对其进行剪枝,期望得到一个精度更高的子集成.
使用基于聚类的方法构建子集成,子集成的大小是聚类的簇个数(见2.2节),也是MDM中用于构建子集成的决策树的数量.根据文献[18]和[23],将MDM的参数p设置为0.075.对Bagging算法生成的子集成,使用多数投票方法来对测试样本进行预测;对AdaBoost算法生成的子集成,使用相应的加权投票方法对测试样本进行预测.
多数投票及加权投票都是用于分类器的静态选择方法,本文还测试了一种动态集成方法LCA(local class accuracy)[24].LCA先让分类器对待测样本做出预测,然后找出待测样本在验证集中的k近邻内被预测为与待测样本相同类别的样本,并计算出分类器对这些样本的分类准确率,最后选择准确率最高的那一个分类器.竞争域RoC(region of competence)定义为测试样本的k近邻,其中k值范围是3~10,测试数据集中使用性能最佳的k值.我们没有考虑k值小于3的情况,因为通常会出现所有的候选树对k近邻内样本预测正确率为零的情况.根据文献[24],将k的最大值设置为10.
3.3 结果分析
表2给出了各算法在采用Bagging生成的决策树池上使用Majority Voting的平均预测精度,MVall是选出的50棵精度最高的决策树的Majority Voting结果.从W/T/L(Wins,Ties and Losses)指标可以看出,WJD表现要比kappa(语义多样性)和RCJac(结构多样性)好,与MDM具有相似的性能.WJD在3个数据集上表现优于MVall.
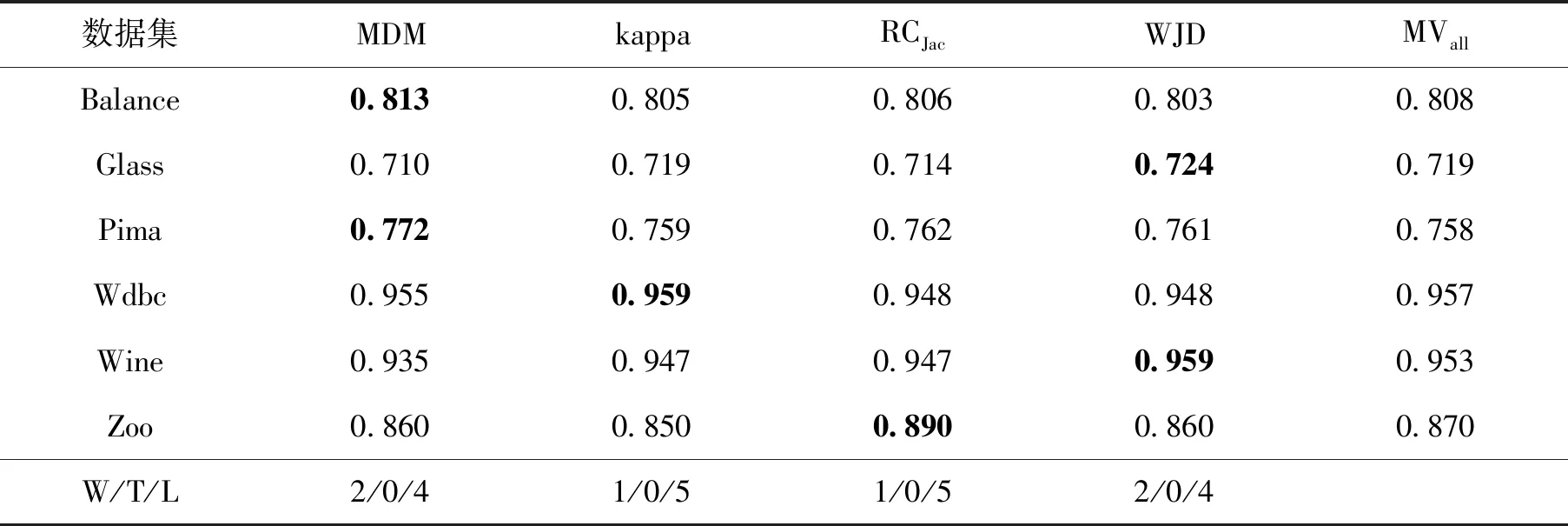
表2 对Bagging生成的决策树池使用多数投票预测精度,并根据(W/T/L)进行性能比较Tab.2 Prediction accuracy using Majority Voting for Bagging and performance comparison in terms of (W/T/L)
表3给出了各算法在采用Bagging生成的决策树池上使用LCA的平均预测精度,可以看出WJD的表现是最好的.WJD在5个数据集上表现优于MVall.
表4给出了各算法在采用AdaBoost生成的决策树池上使用加权投票方式的平均预测精度,WVall是决策树池中的100棵树的加权投票结果.可以看出,WJD的表现要优于MDM和kappa,与RCJac的性能相似.WJD在4个数据集上表现比WVall要好,在1个数据集上表现相当.
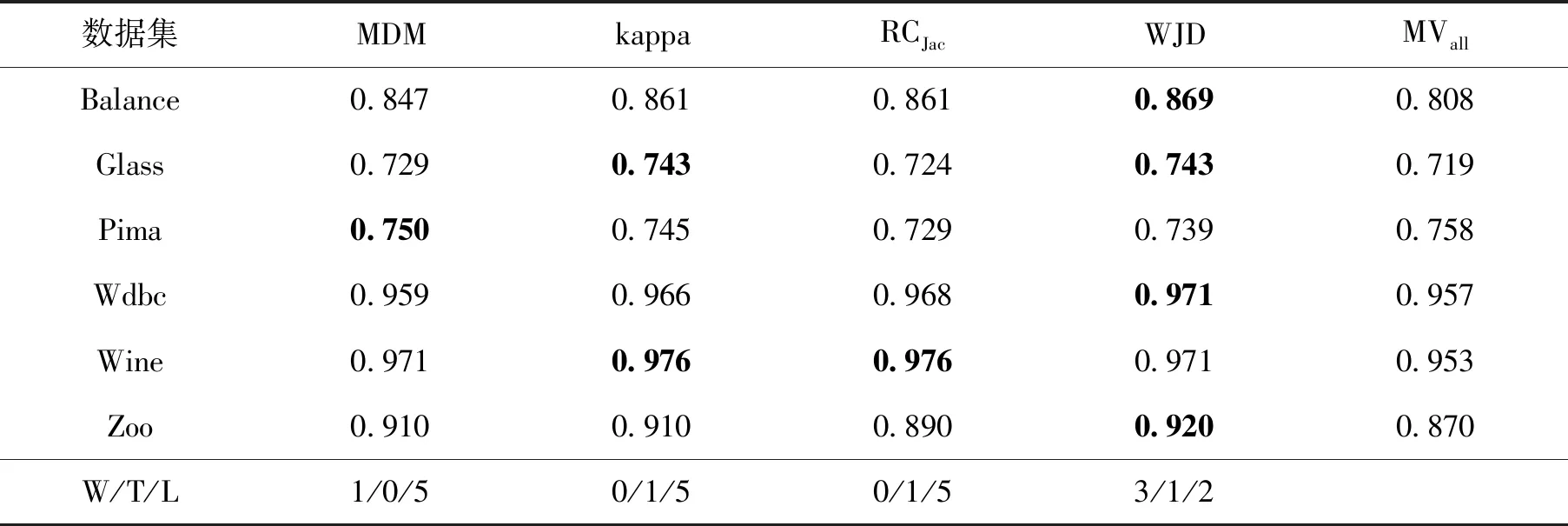
表3 在Bagging算法生成的决策树池中,使用LCA预测精度,并根据(W/T/L)进行性能比较Tab.3 Prediction accuracy using LCA for Bagging and performance comparison in terms of (W/T/L)
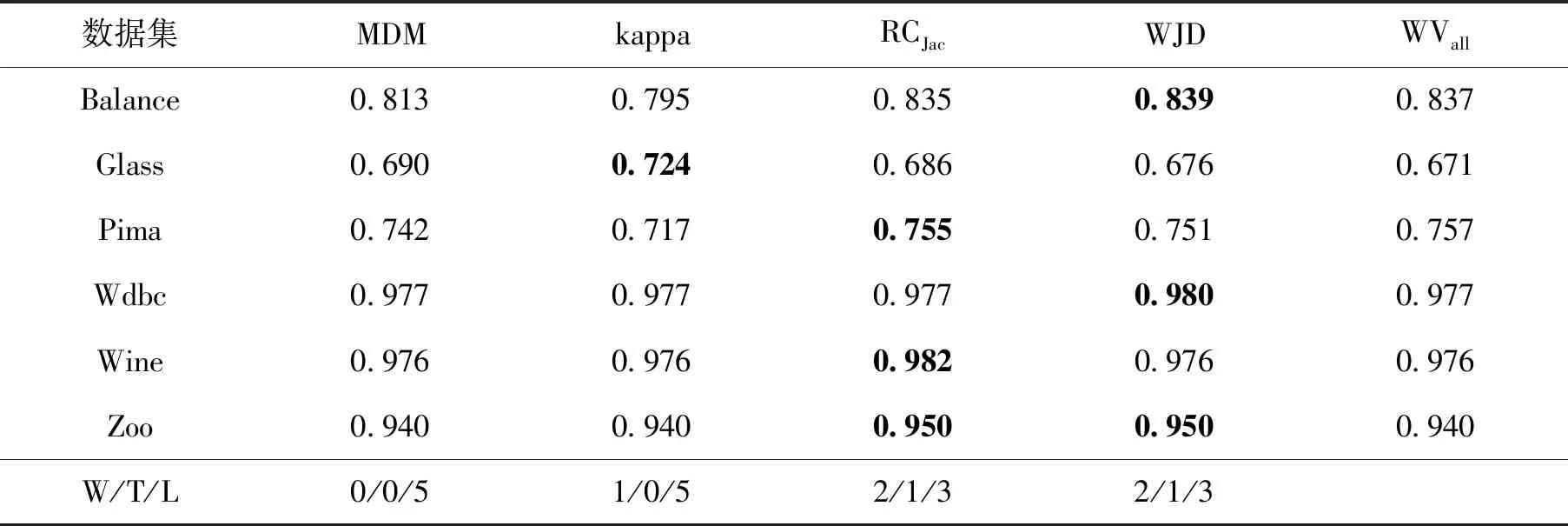
表4 在AdaBoost算法生成的决策树池中,使用加权投票预测精度,并根据(W/T/L)进行性能比较Tab.4 Prediction accuracy using Weighed Voting for AdaBoost and performance comparison in terms of (W/T/L)
表5给出了在用AdaBoost算法生成的决策树池上使用LCA的平均正确率.可以看出,WJD的表现明显优于其他3种方法,在4个数据集上表现优于WVall,在1个数据集上与WVall相当.
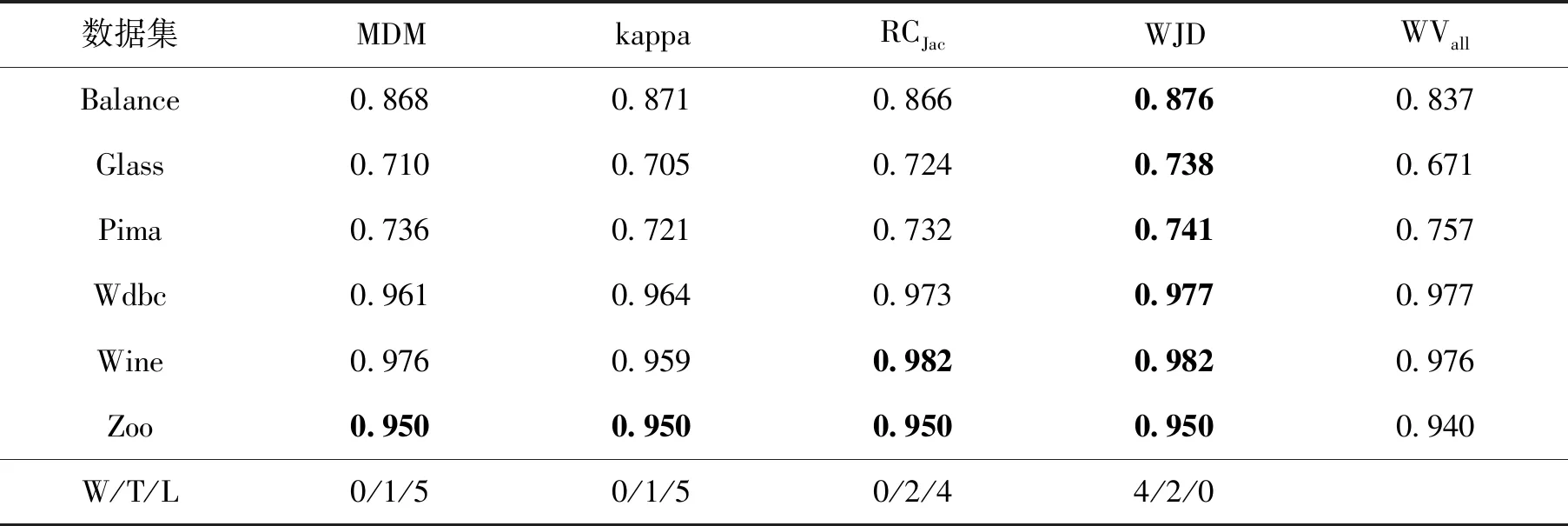
表5 对AdaBoost生成的决策树池使用LCA预测精度,并根据(W/T/L)进行性能比较Tab.5 Prediction accuracy using LCA for AdaBoost and performance comparison in terms of (W/T/L)
从表2—5中可以看出,本文提出的WJD比其他3种方法有更好的表现.kappa是语义多样性度量,RCJac是结构多样性度量.实验表明,本文提出的语义和结构多样性度量方法WJD能够更好地对测试数据进行预测.从实验中可以看出,使用合适的相似性度量方法,基于聚类的剪枝算法会比有序剪枝算法MDM有更好的表现.此外,与所有树的预测结果相比较,本文方法对Bagging和AdaBoost的剪枝是有效的,可以得到精度较高的子集成.
4 结 论
在决策树集成系统中,多样性是重要的特征.本文中提出的加权Jaccard距离是基于决策树中带标签划分的多样性度量.我们分析了WJD的性质,总结了3个定理并予以证明.接下来的实验中,采用MDM算法及2种多样性度量方法kappa和RCJac与WJD进行实验对比.实验结果表明,本文提出的WJD对测试数据的预测精度更高.
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
五邑大学学报(自然科学版)(2019年3期)2019-09-06
江西教育B(2019年2期)2019-04-12
电子制作(2018年16期)2018-09-26
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
中国学术期刊文摘(2016年1期)2016-02-13
智能系统学报(2015年4期)2015-12-27
郑州大学学报(医学版)(2015年1期)2015-02-27
