
基于纹理特征和随机森林的恶意代码分类研究
2020-05-30 03:32刘宇强范志鹏
湖北工业大学学报 2020年2期
刘宇强, 李 军, 范志鹏
(湖北工业大学计算机学院, 湖北 武汉 430068)
恶意代码检测技术主要分为两类[1-2]:静态的、基于代码程序结构、控制流特征的技术和动态的、基于行为特征的技术。这些技术包括建立签名数据库。主要的限制是,这些技术无法检测到一个新的恶意软件,直到它的签名被更新。动态技术在执行过程中会分析恶意软件样本。检测恶意软件是否类似报告样本的行为。然而,与静态技术相比,动态技术更为精确,因为在恶意软件执行过程中更难掩盖其行为。但风险是检测和识别过程可能已经对用户的工作造成了伤害。
近年来,许多研究人员使用机器学习[3](Machine Learning,ML)技术动态处理不断变化的恶意软件检测行为。机器学习技术将一个标记的数据集作为训练数据集,并开发一个区分恶意软件和良性样本行为的模型。训练后的模型能够对测试样本进行分类。ML技术可以通过大量的标记训练数据中学习并提高预测精度。
为了确定恶意代码功能属性并对其进行分类,研究人员探索了许多对恶意代码检测和识别的方法[4-5],但面对大量使用混淆技术的恶意代码来说,传统的分析方法都存在一定的局限性[6]。为了克服加壳加密技术的影响,将恶意代码进行神经网络训练已成为了恶意代码分类检测的主流趋势。分类过程主要步骤:1)预处理,将恶意代码二进制文件进行数据预处理,构建成为符合分类器的输入模型;2)特征选择,不同的分类器有着不同的特征选择方法,依次选择特征集中影响最大的几个特征项的特征值作为特征子集,从而构建新的特征集;3)分类器训练与分类运算[7]。恶意软件分类的关键是分类模型的选择和训练阶段定义模型的参数。模型确定后,可以用于新数据的分类。这里选择随机森林模型作为分类器,因为它能够有效地处理大型和不平衡的数据集。此外,它可以处理大量的特征,而不会过度拟合。同时,考虑到恶意程序的长度、原理、以及各种技术的应用导致其代码千差万别,直接导致其代码信息很难识别,笔者提出了恶意代码的图像纹理信息作为特征数据,将其二进制信息理解为图像,设计了单字节、双字节和三字节图像纹理,达到提取特征的目的。
1 相关理论
1.1 灰度纹理图像特征
灰度共生矩阵GLCM(Gray Level Co-Occurrence Matrixes)是研究图像像素的空间相关特性的常用方法。利用灰度纹理特征来表示大规模的图像纹理数据集可以以最小的资源占比来归纳所有的图像,Gotlied等[8]在研究共生矩阵中研究出的一种归纳特征提取的方法,该方法后被证实对于细微纹理归纳时有良好的效果。Kancherla等[9]提出用灰度纹理特征来对恶意代码进行分类检测并取得了95%的准确率,在此之后研究人员逐步开始利用灰度图像来进行恶意代码研究。
通常,GLCM是像素距离和角度的矩阵函数,它不仅能反映亮度的分布特征,还能描述给定图像的纹理特征。可以为整个图像计算GLCM,也可以为像素值周围的小窗口计算GLCM。虽然给定的图像灰度为256,但在计算灰度共生矩阵导出的纹理特征时,图像的灰度远小于256。主要是由于矩阵维数较大,窗口尺寸较小,灰度共生矩阵不能很好地表示纹理,同时计算量大大增加。因此在计算灰度共生矩阵之前,需要对图像进行直方图化处理,以降低图像的灰度值,图像的灰度为8或16。给定图像灰度共生矩阵的构造公式如下:
(1)
式(1)是对图像上保持一定距离的像素点g1,g2之间的灰度情况进行统计,根据图像中两个不同像素之间的距离为d,方位关系度数为θ的两个像素点构建联合概率分布p(g1,g2|d,θ)。将距离d的值设置为1,θ设置为0°、45°、90°和135°
(2)
R={N(N-1)θ=0°,90°(N-1)2θ=45°,135°
通常以三个角度的联合统计数据,就能够归纳出原始图像的所有特征,通过选择其中影响最大的几个特征作为特征值,可以在关键信息丢失率最低的情况下进行降维处理,GLCM算法能够找出其相关性过大的部分进行分割,除了保存关键信息外,也能够很好地剔除掉干扰混淆的部分。
根据上述过程,当角度分别为0°、45°、90°和135°时,可以计算出四个GLCM。计算结果反映了图像的纹理特征,如角二阶矩、熵、逆微分矩、惯性矩和相关性。
例如熵是对图像信息的度量。从熵的值可以看出图像纹理的不均匀程度或复杂程度,且CLCM散射元素越多,图像熵的值越大。二维数组数字差异变化越大,表现出的图像越复杂,具体公式为:
(3)
其中k为灰度图像尺寸大小,通过对图像当中任意像素点g1,g2构造出的灰度共生矩阵进行统计,计算出4个方向上的熵值,将所有方向结果上的值进行求和,可以还原出原始灰度图像的特征图像。
1.2 随机森林RF(Fandom Forest)分类器
随机森林算法是一种能够对大量数据进行准确分类的新型分类技术[10]。它既可以用于故障的分类,也可以用于故障的回归类型。基于树的学习算法是机器学习和数据科学中应用最广泛的学习方法之一。
由于随机森林分类器建立了多个决策树,并根据这些树的投票结果对最终结果进行评估,从而消除了单决策树方法中存在的过度拟合问题。合并树的过程称为集成方法,从每棵树中对向量进行分类,并将其视为类的投票,然后选择投票最多的分类器作为向量。它是以分治方法为基础的集成模型分类器。一组个体的弱学习者可以通过这个过程共同形成一个强学习者。
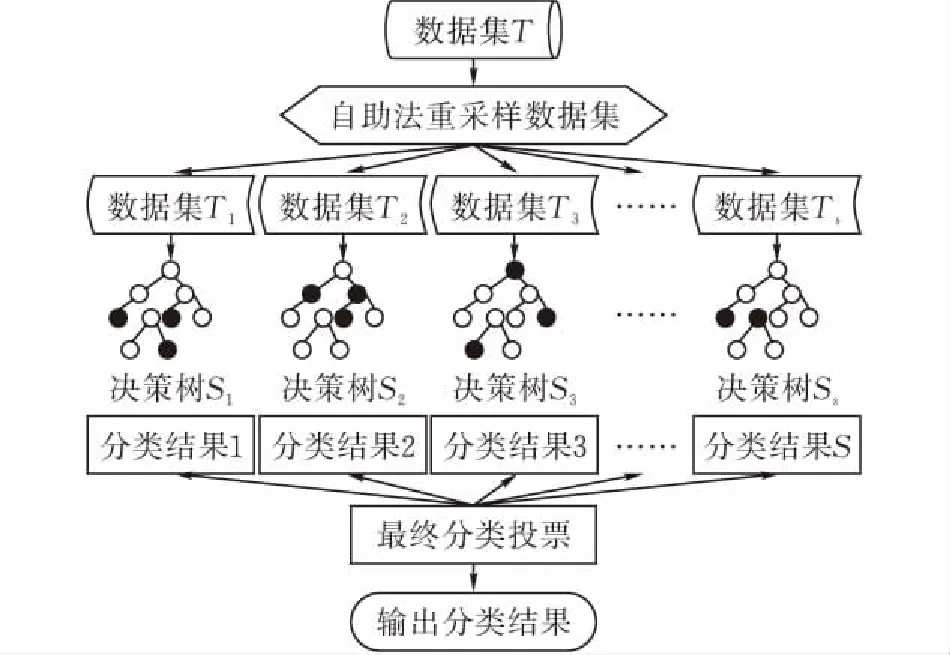
图 1 随机森林整体模型
假设数据集T具有M个特征,n个数据。T表示为X1,Y1;X2,Y2;…;Xn,Yn。其中Xi={Ai1,Ai2,…,AiM}为M个特征值创建的第i个向量,Yi为对应向量的输出类。通过自助法重采样技术将原始数据集T有放回的重复抽取n个样本,形成新的训练集样本Ti,新的训练集样本大小与原始训练集样本大小相同,这一步骤重复S次形成S个数据集:T1,T2,…,TS,通常随机森林分类器使用输入数据的2/3作为训练集,1/3作为测试集,这一类数据称为包外数据。对于一组在数据集Ti上被选择的向量Xi,Yi,在进行重构数据集时,可以被重新用来创造新的数据集Tj,由于随机采样是通过替换完成的,任何向量Xi,Yi都可以被不同的数据集Ti选择多次,并且存在一些从未被任何Ti选择的向量,这种情况被称为bagging,它基于引导聚合产生[11]。对于每个数据集Ti都会形成一个决策树Si,通过决策树对输出向量Vi进行分类,最后统计V1,V2,…,Vs的输出结果,取最大的分类结果来决定Vi的类别。
1.3 K-MEANS聚类分类方法
K-means聚类是一种基于相似性将数据对象分为K个簇的分块聚类方法[12]。在算法中,必须指定集群的数量K。最初选择K个质心。每个数据对象都被分配给包含其最近质心的簇。初始质心的选择是随机的。用欧几里德距离、余弦相似性来衡量与质心和数据对象的接近程度。初始分组完成后,计算每个簇的新质心以及每个数据点到每个中心的距离。根据距离重新分配数据点。如果该点与簇的所有成员之间的距离之和不能再最小化,则将簇中的点视为质心。K-means聚类的主要目的是最小化聚类成员与其质心之间的距离之和。
假设数据集X1,X2,…,Xn中,每一个样本Xi均为d维实向量,k-means方法就是将这n个样本划分到k个集合当中,其中k≤n,同时满足划分后的聚类平方和最小为Ks,具体公式为:
(4)
其中ui为数据集X1,X2,…,Xn中所有点的平均值。
2 改进的灰度纹理图像特征
恶意软件中的单个操作码与普通代码并无太大差异,而较长的操作码具有预测现象发生的能力。每个恶意软件文件的二进制代码长度不一,经过文本可视化后[3],可以看到恶意软件代码可以理解为由众多的1字节16进制数构成的1维向量,数据集中最长的长度为405 248×16B,最短向量的长度为8950×16B。若直接理解为图像,显然图像大小不一,带来后续训练和检测的困难,因此,需要提取每个恶意软件图像的纹理特征,并形成统一大小的特征纹理图像。考虑到代码的顺序性,只采用了水平方向的步长,而不考虑其他方向。
首先选择步长1、2、3建立灰度共生矩阵。原因如下:在操作系统以及汇编指令手册的分析中可以知道,计算机代码中大部分由1字节、2字节、3字节指令构成,如分类1:没有操作数的指令,指令长度为1字节 ;分类2:操作数只涉及寄存器的指令,长度为2字节;分类3:操作数涉及内存地址的指令,长度为3字节等。因此,在灰度共生矩阵中采用了1字节、2字节和3字节的灰度共生矩阵。首先分别以1字节、2字节、3字节为单位切割恶意软件代码行向量并做统计。通常的灰度共生矩阵考虑的是距离为d的2字节同时出现的统计,在大多数文献中[13-14]均为2字节矩阵。对于1字节,行列坐标为0-255,统计每个字节中对应的数值出现个数。对于2字节灰度矩阵,则行代表第一字节,列代表第二字节,如:EB 3C代表EB行,3C列的值加1,直至循环遍历整个恶意软件代码。其中,1字节和2字节矩阵均可形成256×256的标准输入矩阵,1字节灰度共生矩阵为主对角对称矩阵。以样本文件di5lC6uMRX8hJ3BQtIVf.bytes为例,通过图像可视化得到三个纹理图像(图2)。

图 2 样本文件不同字节纹理图像
3 实验和仿真
3.1 数据集
本文采用的数据集为微软2015年恶意代码分类大赛中使用的数据集,BIG2015数据集包含9个恶意家族的21 741个样本,其中10 868个样本为带标签的训练集,其他为不带标签的测试集。训练集中,每一个样本名为一个20字符的哈希ID,以及对应的一个整数值作为家族标签,分别为Ramnit、Lollipop、Kelihos ver3、Vundo、Simda、Tracur、Kelihos、ver1、Obfuscator.ACY和Gatak。对于每个类别,对恶意代码图像分别做1字节,2字节和3字节纹理提取。
3.2 RF实验结果
在这项工作中,根据第2部分生成的灰度共生矩阵生成方法,对每个恶意代码文件重新构成了3个256×256的共生矩阵CSV文件。并根据随机森林分类算法,将样本与百分比分割(80%)使用。其余20%样本向量用作测试数据集。
T={(X1,Y1),(X2,Y2),…,(Xn,Yn)}
在随机森林分类器训练过程中,首先从10棵决策树开始进行训练,通过图3可以看出,随着决策树的增加,分类准确率逐步提升,但超过30棵后,准确率在96%左右变化,不再增加。准确率随着深度增加而逐步提高,但超过10棵后增加不明显。通过图4可以得出,随机森林算法还可以评估所有变量的重要性,无需顾虑变量的多元共线性问题。现实情况下,一个数据集中往往有成百上千个特征,如何在其中选择对结果影响最大的那几个特征,以此来缩减建立模型时的特征数目可以提高算法的效率。这样的方法其实很多,比如主成分分析,lasso等等。可以通过计算每个特征在随机森林中的每颗树上做了多大的贡献,然后取平均值,最后比较特征之间的贡献大小。该方法通常采用基尼指数来评价奉献率。变量重要性评分(variable importance measures)用VIM来表示,将基尼指数用Gini来表示,在分类问题中,假设有k个类,样本点属于第k类的概率为Pk,则概率分布的Gini指数的定义为:

图 3 树的数目对正确率影响
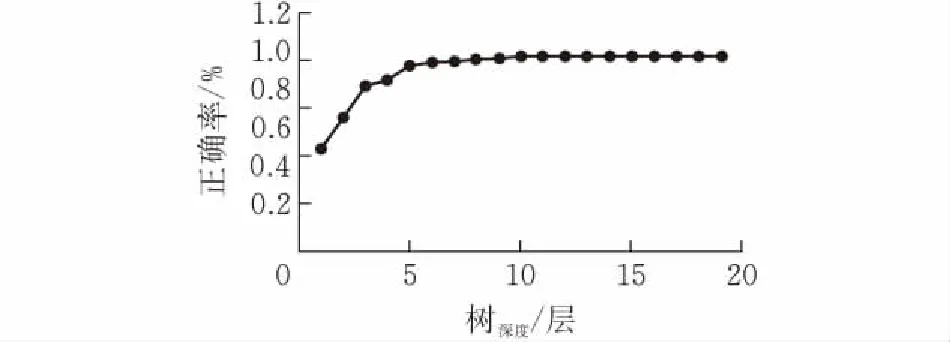
图 4 树的深度对正确率影响
(5)
基于图像纹理的双字节特征相对重要性见表1。基尼系数越大,说明该变量对代码特征的分类重要性越高,经过实验,本方案得出的基于代码特征的指标重要性排序为”0000” >”BC66” >”474E” >”4E49” >”69C3”>…”0001”。由表1可知,取前600个参数就可以达到96%的累计重要性比率,因此可以进一步简化模型,分类代码时,无须每次计算全部的256×256个矩阵参数,而只需要计算列表中
600个参数,即可达到近似的效果。经过实验,表格1中GLCM-RF简化版,可以达到91%。

表1 各列重要性排序表
3.3 KNN聚类结果
为了检验基于恶意代码图像纹理特征提取的效果,继续采用KNN分类方法来验证该特征提取方式的有效性。并将随机森林中得到的重要性特征排序进行聚类可视化排序。由图5可知,各个类别在这些重要的特征上表现出了较强的聚类现象。

图 5 前2列特征聚类情况分析
由于按GLCM聚类的维数较多,达到65 536维,为了更好地的显示结果,采用了TSNE可视化方法。TSNE是一种非线性降维算法,非常适用于高维数据降维到2维或者3维,图6为采用默认的T分布后9类别映射到二维后的结果。每种不同的演示代表了不同的种类,可以看出,红色和绿色的种类聚类特征明显,其他类则较为分散。
为了比较采用GLCM后对分类算法带来的影响,直接提取恶意代码文件的前64K字节作为数据集,用同样的分类方法来进行比较,通过分析统计数据可以看出,采用了图像纹理特征提取后的分类方法均比以前有了显著的提高,其中,GLCM-RF随机森林方法准确率达到了96.36%,较未采用图像特征提取的RF方法提高了约10%,对于传统的KNN方法也有了较大的提高,分类效果明显。

图 6 恶意软件分为9类并采用TSNE后的聚类显示
表2 基于GLCM的RF与传统KNN方法比较
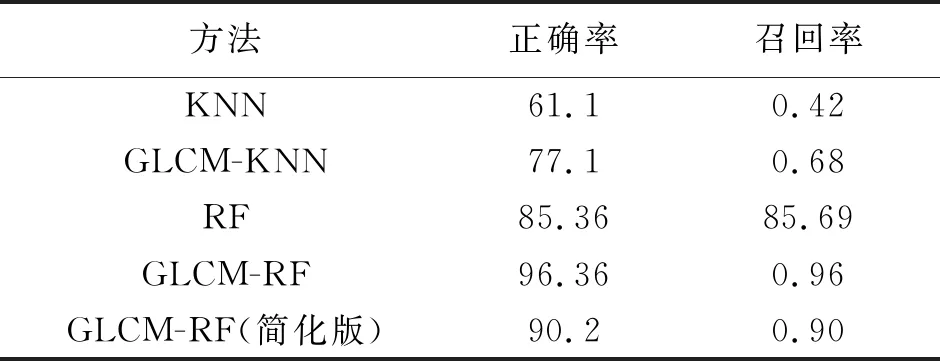
方法正确率召回率KNN61.10.42GLCM-KNN77.10.68RF85.3685.69GLCM-RF96.360.96GLCM-RF(简化版)90.20.90
4 总结
本研究提出一种基于恶意代码图像纹理的随机森林分类方法,这种方法的优点是能够快速高效的识别恶意代码。并通过随机森林分析的特征重要性排序,可以简化图像特征维数,加快分类识别时间。研究结果表明,图像纹理提取简化了代码维数,提高了识别准确率。
猜你喜欢
北京航空航天大学学报(2022年6期)2022-07-02
销售与市场(营销版)(2021年10期)2021-11-21
天津医科大学学报(2021年1期)2021-01-26
软件(2020年3期)2020-04-20
中国信息技术教育(2020年2期)2020-02-02
销售与市场(营销版)(2019年6期)2019-06-21
摄影之友(影像视觉)(2018年12期)2019-01-28
计算机应用与软件(2018年10期)2018-10-24
Coco薇(2017年8期)2017-08-03
Coco薇(2015年5期)2016-03-29
