
基于像素注意力的双通道立体匹配网络*
2020-06-02 00:19桑海伟熊伟程
计算机工程与科学 2020年5期
桑海伟,徐 孩,熊伟程,左 羽,赵 勇,
(1.贵州师范学院数学与大数据学院,贵州 贵阳 550018;2.北京大学深圳研究生院信息工程学院,广东 深圳 518055;3.贵州大学计算机科学与技术学院,贵州 贵阳 550025)
1 引言
立体匹配是指从立体彩色图像对中计算对应点偏差,获取稠密视差图的过程,在自动驾驶[1]、三维重建[2]、机器人导航[3]等领域有着广泛的应用。Scharstein等[4]将立体匹配算法进行归纳总结,并分为4个步骤:匹配值计算、匹配值累积、视差选择与优化以及视差精确化。传统的立体匹配算法可分为局部[5 - 7]、全局[8]和半全局[9]3种类型,其中全局立体匹配算法准确性最高,代表性全局立体匹配算法有图割[10]、信念传播[11]等。传统算法将立体匹配问题分解成若干个子问题,存在求解子问题最优并不代表全局最优的问题。另外,传统算法需要手工设计特征描述算子和代价聚合策略。
卷积神经网络具有强大的特征表示能力,能够直接从视觉图像中有效地学习和理解高级语义,在目标识别[12]、目标检测[13]、语义分割[14]等计算机视觉领域取得较大突破[15]。立体匹配算法也受到越来越多的关注,Žbontar等[16]利用CNN来预测左图与右图的匹配程度,并使用CNN来计算立体匹配值。Luo等[17]采用平滑目标分布来学习所有视差值的概率分布,隐含地捕获不同视差之间的相关性。上述方法仅用神经网络替代立体匹配中的一部分步骤,Mayer等[18]首次提出完全采用神经网络实现端到端的立体匹配、编解码结构和跳跃连接恢复特征细节。跳跃连接是将低层的特征图连接到高层特征图,从而保留图像细节。但是,低层特征图包含一些无用甚至对最终匹配效果造成负面影响的信息,因而有必要进行特征选择,过滤掉低层特征中的无用信息和负面信息。

Figure 1 PASNet structure图1 PASNet结构
2 基于像素注意力的立体匹配网络
深度学习中注意力机制与人类选择性视觉注意力机制类似,让网络可以选择某些特征,抑制一些无用或负面的特征。引入注意力机制可以让其自适应地选择有用的特征,抑制那些无用的或者负面的特征。本文引入像素级注意力机制,用于筛选像素粒度的特征,提出了基于像素注意力的立体匹配模型PASNet(Pixel Attention Siamese neural Network)。该模型由2部分组成:双通道注意力沙漏型纹理特征提取子网络和注意力U型上下文代价聚合子网络,具体结构如图1所示。
2.1 PASNet网络结构
给定2幅立体图像,即左彩色图IL和右彩色图IR,网络的目的是输出对应的视差图DG。先通过CNN对立体图像对进行初步的特征提取,CNN包含6个卷积层(Conv),并将图像降采样到原来图像尺寸的1/4大小,减少参数,提升运算速度。利用不同步长(stride)和大小的卷积(Conv)和反卷积(Decnv)操作,引入像素注意力进一步提取特征,实现双通道注意力沙漏型网络,输出高层语义特征图FL和FR。接着,匹配代价(Cost Volume)则是通过对应层,将左特征图FL和右特征图FR级联,获得代价矩阵C。随后,基于不同步长(stride)卷积、高层次引导和跳跃连接等方式实现注意力U型网络(Attention U-Net),其主要目的是进行代价调整,重新调整像素间的匹配关系,调整后的代价矩阵为C′。最后,通过视差回归层计算并输出的视差图DG。
2.2 双通道注意力沙漏型网络
Brandao等[20]将研究目标聚焦于立体匹配的特征提取上,研究表明,标准的卷积神经网络结构可以用来提升特征提取的质量。对于立体匹配任务而言,特征提取的目的是提取像素之间的对应关系。文献[20]通过池化操作和反卷积操作来增大感受野,但是池化操作会丢失大量细节信息,作者使用跳跃连接可以弥补一定的细节损失。本文采用设定卷积步长的方式来对特征图降采样,尽可能减少细节特征的丢失。
注意力可以解释为重要性权重的向量,在文本处理领域为了预测一个元素,例如句子中的单词,使用注意力向量来估计它与其他元素的相关程度,并将其值的总和作为目标的近似值。在图像处理领域,将当前目标隐藏状态与所有先前的源状态一起使用,以导出注意力权重,用于给先前序列中的信息分配不同的注意力大小[21]。SE-net[19]利用全局池化获得通道注意力向量,对各层输出的特征图进行通道选择。不同通道的特征是不同的滤波器输出的,对于像素级预测的任务来说,理论上应该考虑像素级的特征。像素级的特征包含像素粒度的信息,因此有必要对像素粒度信息进行精确筛选。
双通道注意力沙漏型子网络基于文献[20],将其中的池化层,用步长(stride)为2、卷积核大小为3×3的卷积层替代。PASNet结构如图1所示,包括1个主分支和2个辅分支。主分支先通过2组卷积模块,将输入图像尺寸降采样到当前的1/4,再经过3个核大小为3×3的卷积层,得到引导特征图的输出。引导特征图具有较大感受野和高层语义信息的特点。再通过2个步长为2的转置卷积,将图像恢复到原来大小。2个辅分支用于像素注意力机制的引入,第1个辅分支的输入为低层特征图,目的是补充丰富的细节信息;第2个辅分支的输入为引导特征图,通过像素注意力跳跃模块PAS(Pixel Attention Skip),输出具有像素注意力作用的特征。
PAS模块的2个输入分别为高层特征图和低层特征图,具体结构如图2所示。

Figure 2 PAS structure图2 PAS结构
高层特征图经过卷积层、批量归一化层BN(Batch Normalization)和非线性层ReLU之后,进行Sigmoid变换,如式(1)所示:
(1)
其中,x表示输入特征。Sigmoid的物理意义在于输出1个决定每个特征权重的概率图。概率图与经过了1个卷积层后的低层特征图相乘,再与输入的低层特征图相加,即可得到在像素注意力下的低层特征图。
2.3 级联对应
MC-CNN[15]通过级联左彩色图和右彩色图的特征图,使深度神经网络自动学习代价估计。借鉴文献[22]的思想,本文使用注意力U型子网络,在最大视差范围内,通过级联对应像素的左特征图和右特征图,得到一个四维的代价矩阵。设左、右彩色图分别为IL和IR,大小为W×H,最大视差为D,经过特征提取子网络后特征图的尺寸是(H,W,c),其中c为通道数,2个特征向量经过级联操作后的尺寸为(H,W,2c),则最终获得的代价矩阵尺寸为(D+1,H,W,2c)。
2.4 注意力U型子网络
注意力U型子网络通过像素注意力机制和跳跃连接,提高了立体匹配纹理特征提取的精度。为了同时在视差维度和空间维度进行代价调整,本文基于三维卷积设计一个U型网络,如图1所示,U型子网络结构有3个层级,分别对应原图大小的1/8,1/16,1/32 3种不同尺度的图像,每一个尺度都基于上一层的输出,通过3层三维卷积组合得到。三维卷积组合包括1个核大小为3×3×3、步长为2的三维卷积和2个核大小为3×3×3、步长为1的三维卷积。上采样过程均通过1个核大小为3×3×3、步长为2的三维转置卷积实现。
为了在四维的特征图上同样使用像素注意力,本文设计了三维像素注意力跳跃连接模块SDPAS(Simplified 3D Pixel Attention Skip),具体结构如图3所示。SDPAS的2个输入分别为高层特征图和低层特征图。高层特征图经过三维卷积层、三维量归一化BN和非线性层ReLU之后,进行Sigmoid变换,输出1个概率图,自动优化每个特征层中像素的权重。概率图与使用卷积层后的低层特征图相乘,获得在像素注意力下的低层特征图。网络模型使用SDPAS模块得到所有尺度,将该模块的输出与来自上一层的反卷积结果级联到一起,从而完成像素级注意力特征的引入与融合。

Figure 3 SDPAS structure图3 SDPAS结构
注意力U型子网络的所有尺度都会输出1个视差图,由于每层的视差图尺度不一样,本文通过三线性插值,将得到的视差图上采样到与原图大小一致。由于这个网络有3个输出,因而对应地有3个损失,分别是Loss1、Loss2、Loss3。在训练阶段,视差匹配最终损失由3个损失加权求和得到。在测试阶段,左右图最终视差图是图1中最上面一层的输出,如图1所示。
2.5 视差回归

(2)
其中,D为最大视差,表示对应点可能出现在右图中的位置的最大偏移量。
2.6 损失函数
本文利用具有标准视差图的数据集KITTI,通过随机初始化的方式训练整个网络。由于KITTI数据集的标准视差图是稀疏的,因此需要在有标签的像素集合内平均所有像素的损失。本文提出的网络有3个视差输出,采用绝对值误差训练整个网络:
(3)
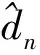
3 实验与分析
3.1 实验条件及评价指标
为了测试本文网络的效果,本文在KITTI2015立体视觉数据集上进行评估。KITTI2015数据集是从汽车视角采集的真实图像数据,包含200对训练立体图像对和对应的稀疏视差图,以及200对测试图像对,其中测试图像对不包含对应的视差图。图像宽为1 240像素,高为376像素。本文取80%的训练图像作为训练集,20%的图像作为验证集。网络基于PyTorch实现,采用Adam优化方法,其中β1取0.9,β2取0.999。训练时对整个数据集进行颜色归一化预处理,图像尺寸随机裁剪成256×512大小,最大视差数D取192。训练阶段网络采用相同的学习率,前200次迭代过程中,学习率设为0.001,后续迭代过程中,学习率降为0.000 1。网络训练的最大迭代数为1 000,在一块NVIDIA 1080Ti GPU上训练耗时约36 h。
所有实验使用像素误差(Pixel Error)作为评价指标。像素误差是预测视差值与标准视差值的误差,超过某个阈值的像素所占的百分比。本文将阈值分别设为2,3,5,分别对应2px-error,3px-error,5px-error。
3.2 实验结果
3.2.1 网络结构实验对比分析
为了验证本文提出的网络结构的有效性,本文设置4种不同的结构进行消融实验,在KITTI验证集上进行对比。实验结果如表1所示,表中‘All’表示在计算错误率时考虑所有的像素,‘Non-Occ’表示在计算错误率时仅考虑非遮挡区域的像素。特征提取阶段和代价聚合阶段分别采用双通道注意力沙漏型子网络和注意力U型子网络。实验结果如表1所示,代价聚合阶段采用注意力U型子网络,3px-error降低了4.2%,说明了U型网络用于代价聚合可以提高立体匹配的精度。在特征提取阶段,引入像素注意力机制,错误率进一步降低,证明了注意力机制的引入,能在像素粒度进行特征筛选,最终提升立体匹配的效果。
3.2.2 网络对比分析
本文与MC-CNN-acrt[16]、Content-CNN[17]、Siamese-CNN[20]、DDR[23]4种网络进行比较,训练集与验证集的比例均为4∶1。其中,MC-CNN网络是没有进行视差后处理的实验结果。本文网络以及Content-CNN和Siamese-CNN都没有进行视差后处理。实验结果如表2所示,与其他网络相比,本文网络的3px-error、5px-error错误率最低,2px-error错误率低于前3种网络。DRR是在MC-CNN的基础上进行视差后处理的网络。本文的网络在3px-error和5px-error错误率上,低于加了后处理的结果。

Table 1 Comparison of different structures on KITTI validation set

Table 2 Performance comparison on KITTI validation set

Figure 4 Results on test set图4 测试集效果图
对KITTI2015中的200对立体图像对进行视差图计算,并将结果提交至KITTI评估网站,结果如表3所示,表中“D1-bg”“D1-fg”“D1-all”分别表示背景、前景、所有区域的像素,即“D1-bg”表示计算错误率时只考虑背景部分的像素。PSANet的3px-error是3.97%,优于大部分网络。
图4是利用本文提出的PSANet生成的视差图样例。从图4中可以看出,PASNet能够生成平滑的视差图,尤其是路面区域具有重复纹理,属于比较常见的病态区域,是立体匹配中的难点之一,但PASNet的像素误差很低。图4中第1行图像存在反光路面,几乎没有明显的纹理特性能够辅助寻找对应匹配点,属于病态区域中的反射表面问题,但是本文的网络得到了较好的视差图。第4行图像中,中间的草丛由于存在重复纹理的病态区域情况,误匹配率较高,误差较大,本文提出的网络在重复纹理下具有较低的误差。本文提出的网络在上述几种病态区域得到了精确的测试结果,一方面验证了本文提出的网络具有鲁棒性,另一方面验证了本文提出的网络能更好地描述匹配点之间的相关性,能有效改善立体匹配精度,特别是在病态区域,能够得到精度较高的视差图。

Table 3 Performance on KITTI test set
4 结束语
本文提出的基于像素注意力的双通道立体匹配卷积神经网络PASNet,将注意力机制引入到特征提取与代价聚合步骤中。首先,通过双通道注意力沙漏型子网络对输入图像进行特征提取,实验验证了注意力机制可以提取有效特征并抑制无效特征;其次,根据特征提取得到的特征图,通过关联层得到代价矩阵,获取初步视差图;最后,利用注意力U型子网络对代价矩阵进行代价聚合,实验表明该子网络可以优化输出结果,最终输出高精度的视差图。在KITTI立体视觉数据集上的实验结果表明,所提出的网络能更好地描述匹配点之间的相关性,有效地解决病态区域精度较低等问题,提高立体匹配精度。PAS和SDPAS模块还可以应用到其它利用像素级预测的网络模型中,以提高匹配精度。
猜你喜欢
小型微型计算机系统(2022年1期)2022-01-21
集成技术(2020年6期)2020-11-30
电子制作(2019年15期)2019-08-27
电子制作(2018年19期)2018-11-14
天津大学学报(自然科学与工程技术版)(2018年6期)2018-05-30
自动化学报(2017年11期)2017-04-04
现代计算机(2016年3期)2016-09-23
电脑知识与技术(2016年15期)2016-07-04
浙江大学学报(工学版)(2016年11期)2016-06-05
应用科技(2015年5期)2015-12-09
