
基于降噪自编码器的社会化推荐算法*
2020-06-02 00:19杨丰瑞李前洋罗思烦
计算机工程与科学 2020年5期
杨丰瑞,李前洋,罗思烦
(1.重庆邮电大学通信与信息工程学院,重庆 400065;2.重庆邮电大学通信新技术应用研究中心,重庆 400065;3.重庆重邮信科(集团)股份有限公司,重庆 401121)
1 引言
随着各类媒体和Web服务的快速发展,网络中存储的用户信息迅速增长,信息超载成为一个重要的挑战,如何帮助用户定位自己感兴趣的信息正变得空前重要。传统的推荐系统仅仅挖掘用户项目评级矩阵来提供建议,并不能提供足够准确和可靠的预测。随着在线交互平台的出现,基于社交网络的推荐方法得到了广泛的应用。结合社交信息的推荐算法融入了用户之间的关联及其引发的相互影响,从而使得系统模型的建立更加真实和周全,推荐性能得以进一步提升[1 - 3]。针对用户的偏好往往受其朋友影响的现象[4,5],相关学者提出了许多将社交信任信息集成到推荐系统的方法[6 - 9]。其结果表明,信任关系对于完善用户偏好和提高推荐性能是有效的。
尽管现有研究提出了将信任信息纳入推荐的不同算法,然而这些信任感知算法仍然存在2个关键问题。首先,它们大多采用浅模型直接建模信任关系,没有利用到信任用户的深层偏好信息。其次,现有推荐算法也未对信任用户的影响程度进行有效的衡量。基于此,本文提出了利用深度学习技术有效衡量信任数据影响的算法。主要内容如下所示:
(1)利用2个降噪自编码器来分别学习用户及其信任用户的高阶潜在偏好,并将2个自编码器与加权层融合,提出了SDAE(Social recommendation algorithm based on Denoising Auto-Encoder)算法,用于衡量信任用户偏好对其目标用户的影响。
(2)利用目标用户与其信任用户的评分差进行用户聚类,为不同类的用户分配不同的影响权重,提高推荐质量。
(3)在Epinions数据集上证明了相比于现有社会化推荐算法,本文算法在推荐精度上有所提升。
2 相关工作
近年来,可信推荐算法在提高推荐质量方面显示出了巨大的潜力。特别地,Ma等人[3]提出了SoRec(Social Recommendation using probabilistic matrix factorization)算法,它是基于概率矩阵分解的推荐模型,通过共享用户隐藏特征矩阵的方式整合了用户的评分信息和用户的社交信任信息。为了对推荐过程进行更加直观、准确的模拟,Ma等人[10]进一步提出了RSTE(learning to Recommend with Social Trust Ensemble)算法,它综合考虑了朋友喜好和用户自身喜好,并假定用户最终决定是两者的折衷。Jamali等人[9]利用信任传播机制对用户偏好进行建模,并结合矩阵因子分解进行推荐,提出了SocialMF(a transitivity aware Matrix Factorization model for recommendation in Social networks)模型。Yang等人[7]在观察到用户对信任者和受信人的角色表现出不同偏好的基础上,提出了TrustMF(Matrix Factorization based social collaborative filtering)算法来进一步提高推荐性能。
然而,这些算法都是利用浅层次的信任数据,忽略了用户之间深层的潜在偏好交互。要从这些数据中学习高阶信息,一个很大的挑战是信任关系非常稀疏。针对这一问题,本文提出了一个深度模型来学习稀疏的浅层用户数据,同时考虑信任用户评级信息。该模型将2个独立的降噪自编码器[11]中间层融合到1个共享层中,使模型能够有效地从这些数据的低层表示中提取高阶关联,为推荐提供依据。另外,针对不同用户受信任关系影响程度的不同,本文通过聚类为用户分配个性化权重,以进一步改善推荐质量。
2.1 社交关系
社交网络是一种由多个节点和节点之间关系构成的社会结构[12]。其中,节点表示1个人或者社交网络的1个参与者。社会化推荐算法一般基于这样的假设:社交网络中用户喜好受其信任朋友偏好的影响,并且朋友之间具备类似的偏好。因此存在社交关系的用户在选择或倾向上,往往基于相互信任而表现出一定的相似性[13],在线社交网络数据的日益可用性,让社交网络的潜力得以充分展现。在实际的社交评论网站 Epinions上,用户可以在信任列表中添加自己信任的用户。图 1 是简单的社交信任网络图,箭头表示用户的信任关系,其中双向箭头表示相互信任。在线社交网络提供了一个独立的信息源,可以使用它来提高推荐的质量[14]。

Figure 1 Schematic diagram of social trust relationship图1 社交信任关系示意图
2.2 降噪自编码器
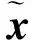

(1)

(2)
(3)
(4)
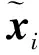
(5)

3 基于降噪自编码器的社会化推荐算法
3.1 SDAE算法
基于社交趋同性的假设,社交网络中存在关联的人互相交流偏好信息,相互影响对方的决策[14,17]。信任用户的影响,一方面体现在对目标用户潜在偏好的改变,用户对1件物品的偏好程度,一部分由自己产生,一部分受信任用户影响,最终的用户决策是两者的综合考量。另一方面体现在信任用户偏好对目标用户偏好的弥补,这种情况下的用户往往直接借鉴其信任用户的选择,实际中稀疏的评分数据并不能完全表示出用户的偏好信息。如图2所示,为了对信任用户的影响机制进行有效模拟,本文使用2个自动编码器分别学习用户及其信任用户的评分数据,得到的用户及其信任用户的低维偏好,通过1个加权隐藏层来平衡隐藏层表示的重要性,有效建模用户偏好的深层交互。本文提出的深度模型能从额外的社交信任信息中充分挖掘目标用户的潜在偏好,进而改善推荐性能。
本节所述的混合模型如图2所示,信任用户评分数据由式(6)给出:
(6)
其中,Su表示用户u的评分向量,Uu表示用户u的信任用户集合,Iu表示用户u的信任用户数,T表示社交信任网络中得出的用户信任值数据,通常为0或1。

Figure 2 Graphical model of SDAE图2 SDAE图模型
通过2个自编码器隐藏层特征的加权融合来为信任用户对目标用户的潜在影响建模,首先使用编码器层将目标用户评级和信任用户评级输入映射到低维空间,该编码层由式(7)和式(8)表示:
(7)
(8)

F为加权隐藏层的输出,用来融合信任用户偏好的间接影响,表示为:
(9)
其中,α是平衡信任用户影响的权重因子,最后通过2个解码器层对原始输入数据进行重构。这2层由式(10)和式(11)表示:
(10)
(11)

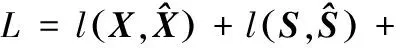
λΩ(WX,WS,W′X,W′S,b,c,b′,c′)
(12)
其中,l(·)为计算重构误差的损失函数,Ω(·)为正则化项,定义为:
(13)
3.2 个性化权值计算
对信任影响机制进行深入探究,不难发现如果一名用户倾向于接受来自好友偏好的影响,其评分相似性也会相对一致。因此,本文从用户与其信任好友的评分一致性作为研究切入点,对用户受其信任用户的影响程度进行衡量。
若2个用户具有较强的评分相似性,那么他们也应具有较小的评分差,本文利用评分差来衡量评分相似性,计算每个用户的聚类特征,最后进行用户聚类及区分。如图3所示,首先计算目标用户与其每个信任用户在各个项目上的评分差,统计所有值为{0,1,2,3,4}的评分差的个数,并将其归一化后作为目标用户的分类特征。这样得出的特征消除了项目之间的差异,能从整体上衡量用户之间的评分差,且维度仅仅为5,计算复杂度较低。最后一步是将用户按照分类特征进行聚类,通过为每个类别中的用户赋予相同权值,得到个性化权值α。具体做法如下所示。
首先初始化特征中心,任意选择m个用户的分类特征向量作为m个类别d1,d2,…,dm的初始特征,以用户与各个初始聚类中心的余弦相似度为依据,为其分配相似度最大的聚类中心所在类别。相似度计算如式(14)所示:
(14)
其中,fi,j表示用户ui的信任特征的第j个分量,dk,j表示类别dk的特征的第j个分量。
下一次迭代时聚类中心dk更新为该类中所有用户特征的均值。
最后以聚类中心所代表的评分差为依据为其代表的类别分配权重。聚类中心代表的评分差为其特征与{0,1,2,3,4}的内积,表示用户在所有项目上的平均评分差值。评分差较大,说明该用户与其他用户的评分相似性较低,则为其代表的类别分配较大的权重α,表示此类用户不易受好友影响;反之,则分配小权重。初始权重为3.1节确定的总体平衡点处的权重α,通过在其周围均匀地取值为每一类用户分配个性化权重。

Figure 3 Schematic diagram for calculating rating difference图3 评分差计算示意图
4 实验分析
4.1 实验数据和评价标准
为了验证本文算法的有效性,在2个开源数据集Epinions(https:∥en.wikipedia.org/wiki/Epinions)和Ciao(https:∥en.wikipedia.org/wiki/Ciao_%28website%29)上进行验证。本文对2个数据集进行了划分,选取了其中对商品评价个数大于1并且至少有10个信任关系的用户,经过过滤之后的数据集信息如表1所示。

Table 1 Statistics of experimental datasets
为了评估本文算法的有效性,从数据集中随机选取80%的数据作为训练集,留下20%作为测试集。本文采用五折交叉验证的方法,取实验结果的平均值作为实验的最终结果。网络采用随机梯度下降法对损失函数进行优化,其网络设置如表2所示。

Table 2 Parameter settings
本文采用常用的2种评测标准平均绝对误差(MAE)和均方根误差(RMSE)来量化算法的性能,其定义如下所示:
(15)
(16)
其中,n表示预测评分项的个数,rij表示用户ui对项目vj的预测值,xij表示用户ui对项目vj的真实的评分。MAE和RMSE值越小,说明算法性能越好,算法的预测值越接近于实际值。本文算法将与SoRec算法、RSTE算法、SocailMF算法、TrustMF算法进行对比实验。
4.2 超参数对实验的影响
本节主要讨论2个参数λ和α对推荐效果的影响,其中λ为防止网络过拟合的正则项系数,α为衡量信任用户影响的因子。在验证某个参数对实验的影响时固定其它参数。
(1)确定参数α。
参数α主要作用是平衡信任用户偏好的影响,如图4所示,实验中设定参数α的值为0,0.1,0.2,0.3,0.4,0.5,0.6,0.7,0.8,1。其中α=0和α=1分别表示网络只根据用户评分和信任数据进行评分预测,2个数据集上效果皆不是最佳。这说明本文混合信任用户评分偏好改善了系统整体的推荐性能。在Ciao和Epinions数据集上,当α=0.4和α=0.5时系统分别达到了一个平衡点,此时算法推荐性能最佳,当α取值过小时信任用户作用过小,由于评分数据稀疏性,导致误差大。当α取值过大时,信任用户偏好所占比重过大,产生了多余的干扰,也会导致误差过大,另外由于Epinions的数据相对更为稀疏,信任用户对推荐的影响更显著,因此最佳点处α较大。
(2)确定参数λ。
参数λ的作用是避免网络过拟合,如图5所示,在实验中λ的取值分别为0.001,0.01,0.02,0.05,0.1,0.2,0.5。由图5可以看出,在2个数据集Epinions和Ciao 上过拟合参数保持在一个数量级,λ取0.1时误差最小,λ大于0.1时网络过拟合,λ小于0.1时网络欠拟合,效果皆不佳。

Figure 4 Effect of parameter α on recommendation accuracy图4 参数α对推荐准确度的影响

Figure 5 Effect of parameter λ on recommendation accuracy图5 参数λ对推荐准确度的影响
4.3 个性化权重的影响
实验将聚类后的类别设置为2,具体的个性化权重的取值如表3所示,为了更全面地比较个性化权重算法的实验效果,本节以上文得出的最佳α为基准点,并在基准点附近设置较大的初始波动范围,后面的情形将2个类的差异逐渐缩小,各取5组实验结果进行对比。具体的算法个性化权重取值如表3所示,α=0.62/0.18表示2类用户的α分别取值为0.62和0.18。

Table 3 α values for SDAE algorithm
图6中所示为通过用户聚类为每一类用户分配不同权重后的实验结果。情形2至情形5中,2个数据集Ciao和Epinions 所对应的RMSE值分别优于α固定取0.4和0.5的情形,说明不同用户受信任用户的影响程度是不同的,采用个性化权重能够改善系统的推荐性能。在情形1下,2个数据集对应的RMSE值比最优固定权重值时的RMSE值更大,分析其原因就是情形1的分配方案均较大地偏离了原有2类用户的实际比重,导致实验结果不佳。

Figure 6 Recommended results for personalized algorithm图6 个性化算法推荐结果
4.4 训练集的划分影响
为了展现在不同比例训练集下算法的推荐效果,本节分别对Ciao和Epinions数据集进行40%~80%训练集划分,实验结果如图7和图8所示。

Figure 7 Comparison results on Ciao dataset图7 Ciao数据集上对比结果

Figure 8 Comparison results on Epinions dataset图8 Epinions数据集上对比结果
观察图7和图8可以发现,随着训练集划分比例的增加,各个算法的推荐效果不断提高,原因是训练集比例的增加减少了数据稀疏的影响。另外,本文算法在各个比例训练集上都表现出良好的推荐效果,这是由于算法建模了信任用户深度的偏好影响机制,从而获得了更好的推荐性能。
4.5 最终对比实验
本节实验比较了SoRec、RSTE、SocialMF、TrustMF算法在Epinions数据集上的推荐效果,为了方便展示,将本文未加个性化权重的算法取名为SDAE,引入个性化权重后的算法取名为SDAE+,均取参数最优时的结果,即在Ciao数据集上SDAE取α=0.4,λ=0.1,SDAE+取α=0.52/0.28。在Epinions数据集上SDAE取α=0.5,λ=0.1,SDAE+取α=0.61/0.39。本节算法的对比实验结果如表4所示。
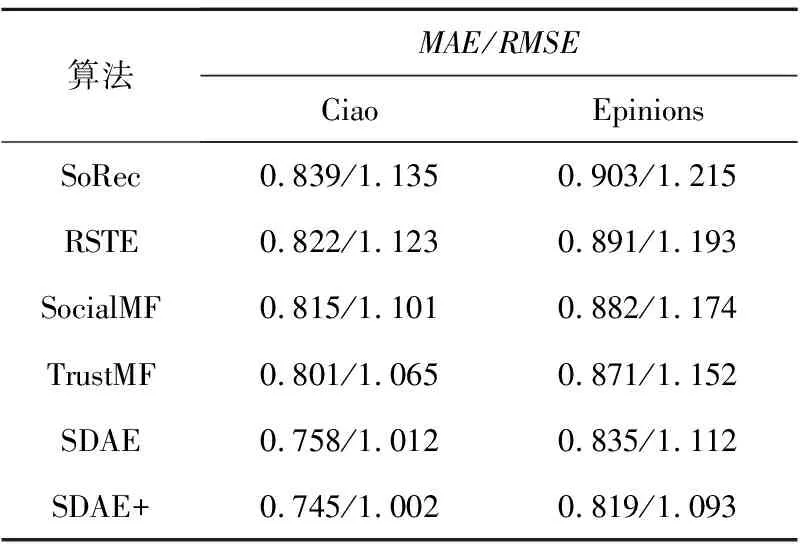
Table 4 Performance comparison of algorithms
从表4中可以看出,与其它算法相比,本文算法在推荐精度上有了明显的提高,在Ciao数据集上SDAE算法相比于其他4种算法,MAE值和RMSE值分别降低了5.3%~9.6%和4.9%~10.8%,SDAE+算法的MAE值和RMSE值分别降低了6.9%~11.2%和5.9%~11.7%。在Epinions数据集上,SDAE的MAE值和RMSE值分别降低了4.1%~7.5%和3.4%~8.4%,SDAE+算法的MAE值和RMSE值分别降低了5.9%~9.3%和5.1%~10%。总体上来看,用户评分数和信任数越稠密,算法效果越好。算法考虑了用户及其信任用户的高阶潜在交互,能够发现浅层线性模型无法挖掘的用户潜在偏好,实验结果充分证明了算法的正确性。另外为每类用户分配不同的信任影响权重,取得了更好的推荐效果,也证明了实际社交网络中的用户受信任用户的影响程度是不同的,可以借此来改善推荐质量。
5 结束语
本文提出了基于降噪自编码器的社会化推荐算法,通过1个共享层将2个降噪自编码器结合起来,从用户及其信任用户数据中学习深层的偏好信息,有效挖掘了社交关系中信任用户的潜在作用。另外,本文通过分析用户的评分相关性进行用户聚类,并引入个性化权重值,实验结果表明,本文算法是有效的。随着数据采集技术的发展,推荐系统已经搜集到丰富的多源信息,设计可扩展性高的社交推荐模型,将更多额外信息有效融入推荐模型中将是下一步研究重点。同时,未来还将考虑到用户兴趣随时间的变化,围绕如何感知、建模这一规律展开研究。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
制造技术与机床(2017年7期)2018-01-19
桃之夭夭B(2017年2期)2017-02-24
西安工程大学学报(2016年6期)2017-01-15
探测与控制学报(2015年4期)2015-12-15
高中生·青春励志(2014年11期)2014-11-25
新课程学习·中(2013年3期)2013-06-14
