
ESM:一种增强语义匹配的语句评分模型*
2020-06-22 12:49曹小鹏邵一萌
计算机工程与科学 2020年6期
曹小鹏,邵一萌
(西安邮电大学计算机学院,陕西 西安 710121)
1 引言
语义匹配在自然语言处理任务中具有十分重要的地位,早期的研究表明,无论在语法结构上做何种深入研究,都难以达到理想的效果。后来研究人员发现,一个完整的自然语言处理NLP(Natural Language Processing)任务绕不开语义匹配这个环节[1]。传统的匹配方法没有考虑语义信息,一般从词、句式、语法结构出发,依赖于人工设定的特征和规则,这种硬性的匹配不仅很难达到满意的效果,还需要花费大量人力物力。文本匹配是自然语言处理中的一个基础性问题,而语义匹配是文本匹配研究的重要方向,它可以从根本上解决文本匹配问题。
在搜索引擎中,需要计算用户查询和一个网页正文的语义相关度,这就需要使用短文本语义匹配。在计算的时候,为了避免对短文本直接进行主题映射,采用长文本的主题分布来计算短文本的概率,以此作为用户查询和网页正文之间的相似度。语义匹配可以应用到更复杂的计算当中,如文档中关键词的抽取、个性化小说推荐以及自动阅卷等。
自动阅卷是智能教育的关键技术之一,是语言学和自然语言处理等相关学科交叉的一个研究方向[2]。主观题自动评分ASSR(Automated Scoring Subjective Responses)在语言学与语言测试领域的诊断信息及信度方面具有广泛的应用前景。试卷自动评分在客观题上已经发展得很成熟,但是在主观题的评分上相较于客观题依然差距较大。国外在英文主观题自动评分上起步较早,主观题自动评分的研究与实践早在20世纪80年代就已经开始,目前国外已有多个较为成熟的主观题自动评分系统,如PEG(Project Essay Grade)[3]、IEA(Intelligent Essay Assessor)[4]和e-rater[5]等,并已应用于GRE、TOFEL和GMAT等大型考试[6]。
在汉语主观题的自动评分上,国内有许多学者已经做了很多研究工作,但是由于汉语语言特点以及汉语自然语言处理技术发展还不够成熟,致使汉语主观题的自动评分工作依然进展缓慢。2011年,郭扉扉等[7]在模糊数学的基础上结合动态规划实现了更加精准的主观题自动评分。罗海蛟等[8]使用改进的隐含狄利克雷分布LDA(Latent Dirichlet Allocation)模型进行中文主观题自动评分,结果表明改进的LDA模型在中文主观题自动评分中切实有效。陈珊珊[9]研究了深度学习模型在自动作文评分中的应用,实现了一个作文自动评分系统。陈志鹏等[10]研究了在作文自动评分中进行作文跑题检测的系统。陈贤武等[11]从关键词相似度、语义相似度以及句法相似度3个方面对文本相似度进行研究并提出了自动阅卷的模型。代钰琴[12]研究了改进的句子相似度的主观题评分并应用在自动阅卷系统中。
上述学者对于主观题的评分使用了不同的模型进行计算,在很多方面都取得了不错的效果,但是评分结果的精度并不是非常理想,主要原因在于没有充分考虑将学生答案的语句通顺度的打分包含在计算模型中。为解决这个问题,本文将文本相似度计算模型与语句通顺度打分模型相结合,构建了一个新的语句评分模型。
2 相关模型
2.1 LDA模型
LDA是由Blei等[13]提出的一种新式的语义一致的主题模型,是一个生成概率模型。其基本思想就是认为文档是由潜在的一些主题随机组合而成的,而每个主题又由词组成,即一个文档中可能包含多个主题,一个词也可能同时属于多个主题。LDA是一个3层贝叶斯模型,包含词、文档和主题3层结构。
LDA 假设文档是由多个主题混合产生的,它的训练过程使用吉布斯采样:吉布斯采样 (Gibbs Sampling) 首先选取概率向量的一个维度,将其他维度的变量值设定为当前维度的变量值,通过不断收敛来输出待估计的参数。LDA 对于每个文档的每一个词都有一个主题下标。经过大量的迭代,主题分布和词分布都比较稳定之后,LDA 模型收敛。
LDA的训练过程首先是对语料库进行清洗和预处理,包括移除标点符号、停用词和标准语料库。LDA使用 DT(Document-Term) 矩阵进行训练。
2.2 统计语言模型KenLM
N-gram Models即n元语言模型,常用的N-gram训练工具有SRILM(Stanford Research Institute Language Modeling toolkit)[14]、IRSTLM(IRST Language Modeling toolkit)[15]、BerkeleyLM(Berkeley Language Model)和统计语言模型KenLM(Kneser-Ney Language Model)[16]等。本文以KenLM作为训练工具,它比SRILM和IRSTLM 快,占用更少的内存。基于N-gram所用的平滑技术是Modified Kneser-Ney smoothing[17],它是当前一个标准的、广泛采用的、效果最好的平滑算法。
统计语言模型KenLM的基本步骤如下所示:
(1)进行原始计数。把相同的词合并,然后排序。可以得到1-gram和2-gram的原始计数,n=1的时候被称为unigram,n=2的时候被称为bigram。
(2)调整计数。其公式如下所示:
(1)
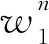
(3)计数。
其基本思想是把经常出现的一些N-gram的概率分一些出来给没有出现的N-gram,这样出现次数较多但不是最多的词的计数就得到了较高的概率值。
(4)做标准化,首先计算N-gram的概率。其公式如下所示:
(2)
(3)
其中,x表示与wn不同的词,tn,k为出现了k次的N-gram的个数。
(5)计算回退权重。
回退权重衡量的是某个词后面能接不同词的能力。最后把bigram 和 unigram 结合起来,计算公式如下所示:
(4)
该过程不断递归,直到n=1停止。在KenLM的计算中,对上述的概率取以10为底的对数。
3 模型设计
为了提高语句评分的准确率,本文模型在计算文本相似度的基础上增加了语句通顺度的计算,选择主题模型进行相似度计算的主要原因是主题模型可以比较高效地解决短文本中存在的上下文依赖性强、关键特征非常稀疏等问题。对一段文本进行评分,除了目标文本与标准文本的相似度对评分的影响较大之外,目标文本的语句通顺度也非常重要,所以本文将通顺度也加入语句评分模型的设计当中。计算通顺度值使用的是经过KenLM训练之后的语言模型,用“统计+平滑”的方法来进行计算。KenLM是一个C++编写的语言模型工具,具有速度快、占用内存少的特点,也提供了Python接口。使用KenLM进行语句通顺度值计算的优点是:节省内存且允许使用多核处理器,这样就极大地节省了训练模型的开销。同时,考虑到人工评分中目标文本的大小对于最终评分也有不可忽略的影响,在模型设计的时候加入了字符比因子。所以,基于语义匹配的多维度语句评分模型在设计的时候,主要考虑文本相似度、语句通顺度以及字符比这3个因素对最终评分的影响。
本文采用预处理好的Wiki语料库,使用KenLM在语料库上训练语言模型(计算各种组合的条件概率)。在Python中加载训练好的KenLM模型,之后使用该模型对目标文本进行打分。每个句子通过语言模型都会得到一个概率,然后对概率值取以10为底的对数得到分数smooth,分数值越高说明该句子的语句越通顺。
KenLM计算语句通顺度的步骤如下所示:
(1)使用KenLM在Wiki语料库上训练语言模型。
(2)对训练得到的文件进行压缩和序列化,以提高后续在Python中加载的速度。
(3)在Python中加载训练好的KenLM模型,使用该模型对目标文本进行打分。
之后使用软件测试语料库训练LDA模型,用训练好的LDA模型对目标文本和标准文本进行对比,得出相似度分数similarity。
LDA基本步骤如下所示:
(1)随机初始化:对当前文档中的每个词w,随机地赋一个主题编号z;
(2)重新扫描当前文档,按照吉布斯采样公式,对每个词w,重新采样它的主题;
(3)重复以上过程直到吉布斯采样过程收敛;
(4)统计文档中的主题分布。
本文提出的增强语义匹配的语句评分模型ESM(a sentence scoring model for Enhancing Semantic Matching)框架如图1所示。

Figure 1 Framework of sentence scoring model to enhance semantic matching图1 增强语义匹配的语句评分模型框架图
增强语义匹配的语句评分模型在进行语句评分时,首先分别使用预处理之后的语料库训练LDA模型和KenLM模型,用训练好的LDA模型对标准文本与目标文本进行相似度计算,得出目标文本与标准文本的相似度得分;再使用训练好的KenLM模型对目标文本进行通顺度计算,得到目标文本的通顺度得分;然后单独计算目标文本与标准文本的比值得出字符比;最后将上述3个数据进行汇总计算得出目标文本的最后得分。将文本相似度、语句通顺度和字符比作为语句评分的影响因子,最终语句评分的计算公式如下所示:
(5)
其中,score是增强语义匹配的语句评分模型的最终成绩,smooth是使用KenLM计算的通顺度得分,similarity是使用LDA模型计算的文本相似度得分,counts是目标文本字符比,counta是标准文本字符比,α是语句通顺度在成绩中所占比重,β是文本相似度在成绩中所占比重,γ是字符比在成绩中所占比重,φ为随机变量。
4 实验与分析
4.1 数据集
为解决传统LDA模型使用通用语料库造成文本稀疏等问题,本文实验选择大量与软件测试相关的书籍资料作为语料库训练LDA模型,选择预处理后的Wiki语料库作为KenLM的训练数据,在计算模型参数的时候,选取了某大学软件测试期末考试的真题和答案作为样本,共233份,题目为:请阐述黑盒测试的概念(共10分)。
4.2 实验分析
本文选择LDA进行文本相似度的计算,该模型在语料库中训练不同主题下文本的主题分布,主题数量对实验结果有很大的影响。困惑度(Perplexity)是评价一个语言模型性能的指标,其计算公式如下所示:
Perplexity({w} |M) =
(6)
其中,M指训练好的模型参数,Nm为文档m的单词数,φk,n为主题n的单词多项式分布向量,θk,m为文档m的主题分布概率向量。w为对真实分布下样本出现概率的估计。
使用某大学软件测试期末考试的233份样本进行LDA不同主题数下困惑度的计算,得到的实验结果如图2所示。

Figure 2 Statistical chart of perplexity under different topic numbers图2 不同主题数下的困惑度统计图
困惑度的值越低表示该语言模型的性能越好,从图2的实验结果可以看出,主题数为20的时候,困惑度最小,因此本文选择的主题数为20。
表1列出了通过KenLM模型计算出的语句通顺度得分、通过LDA模型计算出的文本相似度得分、字符比和人工手动对学生答案的得分值汇总的节选。为方便对实验结果进行分析,对所获得的数据进行统计与筛选。对处理之后的数据分别进行文本相似度与评分、语句通顺度与评分和字符比与评分的趋势分析,其中文本相似度与评分的数据统计如图3所示。
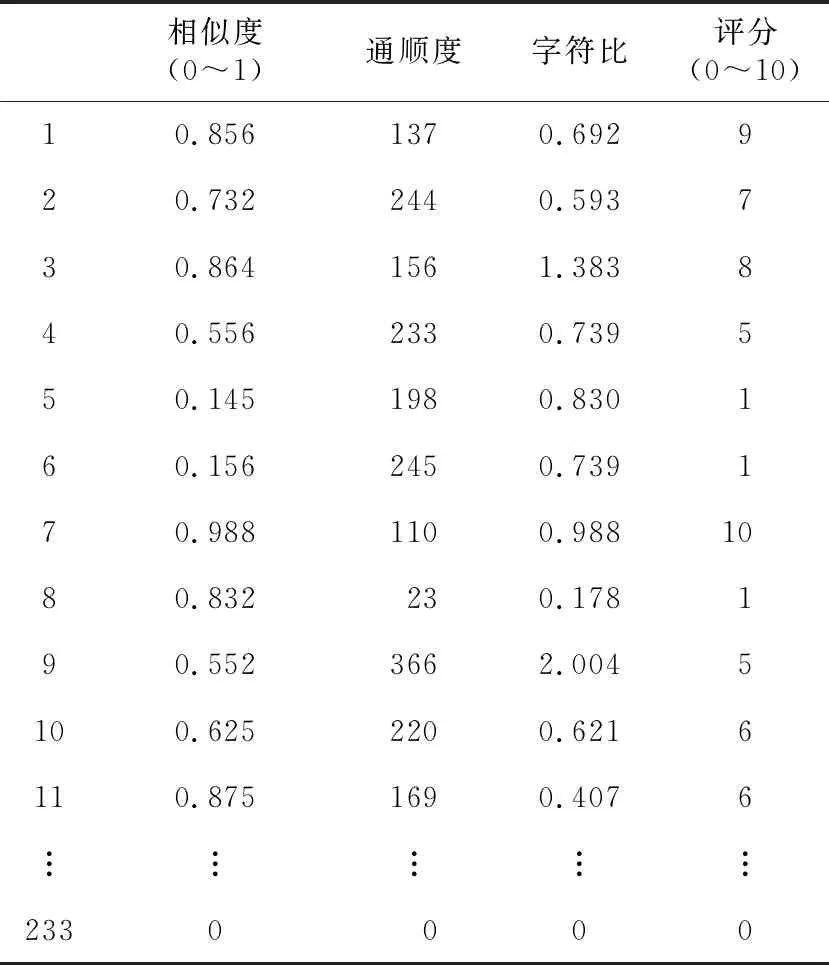
Table 1 Summary of experimental results表1 实验结果汇总表
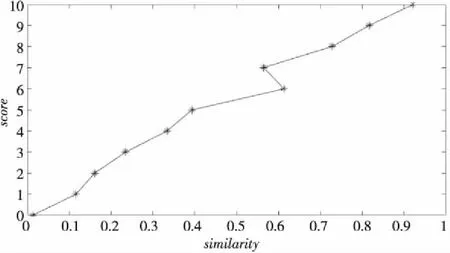
Figure 3 Similarity-score trend chart图3 相似度-评分趋势图
从图3可以看出,随着相似度值得分不断接近于1,语句评分值越来越高,大体呈正比例增加,因此相似度与最终评分大致是成正比例的关系,可选择相似度作为影响评分的因子。
通顺度与评分的数据统计如图4所示。
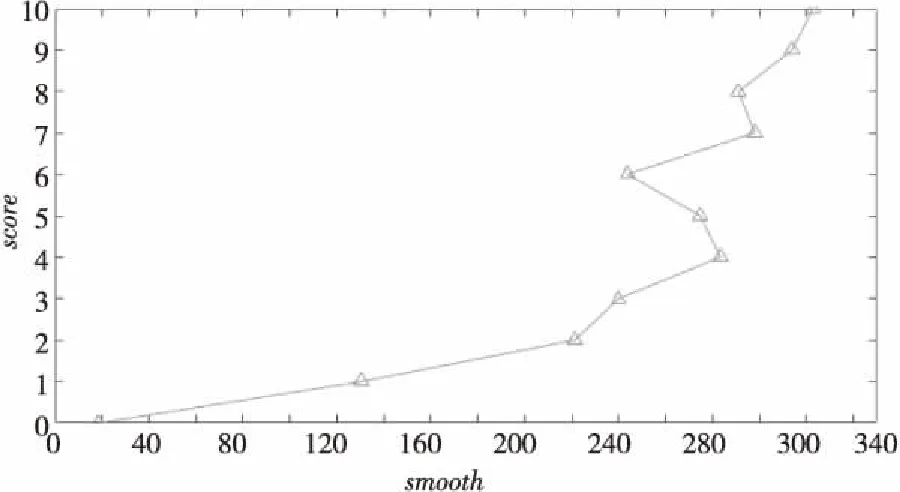
Figure 4 Sentence smooth-score trend chart图4 通顺度-评分趋势图
从图4中可以看出,大体上,随着通顺度的增加,评分也越来越高,整体呈正比例增加,由此可知通顺度与最终评分是成正比例的,可选择通顺度作为影响评分的因子。
字符比与评分的数据统计如图5所示。
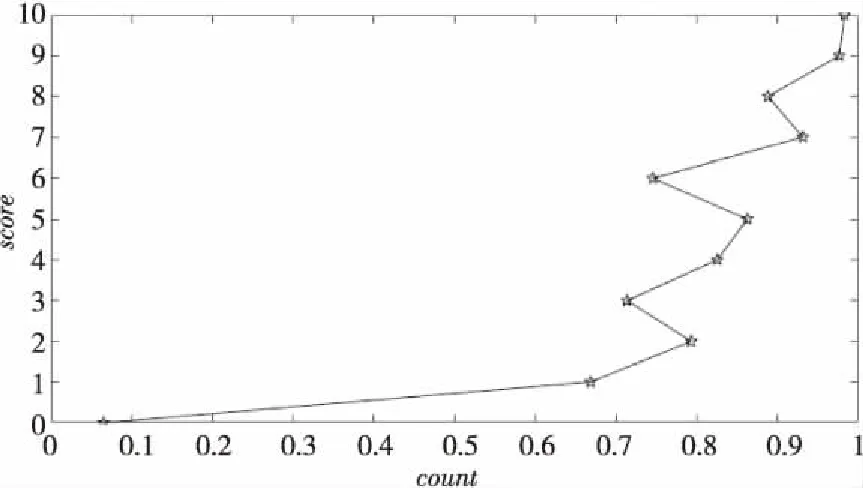
Figure 5 Character ratio-score trend chart图5 字符比-评分趋势图
从图5中可以看出,随着字符比的增加,评分也越来越高,呈正比例增加的趋势,可知字符比与最终评分大致是成正比例的关系,可选择字符比作为影响评分的因子。
综合上文的分析可以得出:文本相似度、语句通顺度和字符比与最终评分结果大致上是正相关的关系,所以选择文本相似度、语句通顺度和字符比这3个因素作为最终评分的影响因子。
4.3 实验结果
使用多元回归分析对实验数据进行分析统计,得出的结果如表2所示。

Table 2 Estimation results of multiple regression analysis表2 多元回归分析估计结果
从表2可得到模型各变量的回归系数估计值、标准误差、t检验值以及P值信息。多元回归中的P值(Pvalue)就是当原假设为真时所得到的样本观察结果出现的概率,用来衡量因素之间有没有显著影响。经过多元回归的计算,模型中的3个影响因子的系数Pvalue均小于0.01,所以置信度达到99%,这就说明针对当前数据集而言该模型为最优回归模型,具有良好的可信度和可行性。
最终得出的多元回归模型如下所示:
score=1.65·esmooth+7.68·similarity+
(7)
从多元回归分析的结果可以看出,对目标文本的最后评分score影响最大的是文本相似度的得分,接下来是语句通顺度,对score影响最小的是字符比。由以上分析可知,基于统计语言模型和LDA模型相结合的技术对目标文本和标准文本进行语句通顺程度打分和相似度打分可以实现评分的客观性和准确性。本文提出的一种增强语义匹配的语句评分模型ESM,从文本相似度、语句通顺度以及字符比3个方面来综合计算在有参照的标准文本下目标文本的评分。
4.4 实验结果对比
国内的大多数学者在计算主观题的评分时多采用的是文本相似度的方法,本文实验结合文本相似度与语句通顺度以及字符比共同作为影响最终评分的因素。为了进行对比,将训练好的模型应用到在线考试平台中,通过在线考试平台进行测试,观察自动评分的结果与人工评分的结果是否一致,采用平均误差作为评价指标。误差值的计算采用以下公式:
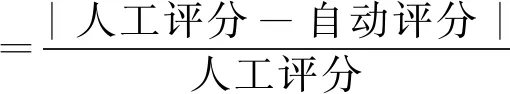
(8)
随机抽取100个学生的答案作为目标文本,对学生作答的100道软件测试的题目分别使用了5种评分方法:人工阅卷、仅使用LDA进行语句相似度的主观题自动评分、采用依存语法的相似度计算的主观题自动评分、使用TF-IDF模型的句子相似度算法的主观题自动评分[18]以及ESM,将上述后4种自动评分方法计算的最终评分的结果与人工阅卷的结果进行对比。实验得出的平均误差数据汇总如图6所示。
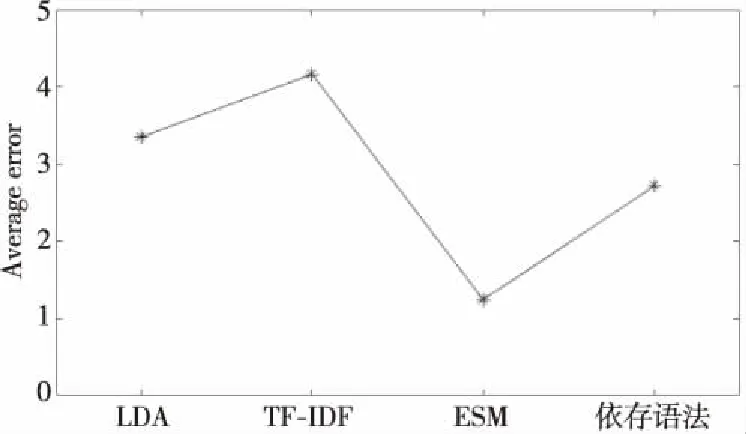
Figure 6 Comparison of experiment results图6 实验结果对比
图6是使用自动评分与手工评分进行误差计算的实验结果对比图,从实验结果可以看出,平均误差最大的是使用TF-IDF进行相似度计算的评分方法,因为TF-IDF是对关键词出现次数的统计,并没有考虑到语义对文本相似度计算的影响,因此效果较差;对比仅使用LDA模型的评分方法,本文模型增加了通顺度和字符比的影响因子,平均误差有所减少;使用基于依存语法的相似度的评分方法充分考虑了语义信息以及句子结构,但是对于长句子分析的准确率不高。本文所采用的增强语义匹配的语句评分模型计算得到的平均误差值明显小于仅使用语句相似度进行主观题自动评分计算的自动评分方法的,这表明本文模型能有效提高主观题自动评分的准确率。对实验结果进行分析可知,将语句通顺度等因素考虑在主观题评分的计算中,可以提高准确率,最后的得分更接近于人工评分。
5 结束语
传统的语句评分模型并没有结合相似度以及语句通顺度等多种要素综合评价,因此效果较差。本文在传统语义匹配使用相似度进行计算的基础上,增加了通顺度因子来解决语句评分的问题,提出一种增强语义匹配的语句评分模型。本文在计算相似度的时候考虑使用LDA主题模型来进行学生答案和标准答案的计算,主要是考虑到可以将学生答案划分为各个不同的学科作为不同的相似度计算主题,进一步提高使用LDA计算主题之间相似度的准确性。由于很难建立完善的语言规则也缺乏相关的语言学知识,考虑到某些类型的词互斥的特性存在,可以使用N-gram来判断语句的通顺程度,使用KenLM作为工具是因为它实现了2种有效的语言模型查询数据结构,减少了时间和内存开销。使用文本相似度结合语句通顺度所计算得到的平均误差值明显小于仅使用语句相似度的自动评分方法的。
但是,在KenLM中使用N-gram方法存在瓶颈,当下深度学习在NLP中的应用十分广泛,未来可以尝试在NLP中应用深度学习,使用循环神经网络或者Google新提出的bert[19]基于句子做特征工程,学习病句特征,最后结合通顺度与相似度等因素进行多粒度与多维度的语句评分。
猜你喜欢
考试与招生(2022年10期)2022-11-17
井冈教育(2022年2期)2022-10-14
中学生数理化·高三版(2022年6期)2022-07-08
甘肃教育(2021年10期)2021-11-02
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
数字通信世界(2019年3期)2019-04-19
读写算·小学低年级(2009年10期)2009-10-27
初中生学习·低(2009年3期)2009-04-14
