
面向Android恶意应用静态检测的特征频数差异增强算法*
2020-06-22 12:50李向军魏智翔王科选肖聚鑫
计算机工程与科学 2020年6期
李向军,孔 珂,魏智翔,王科选,肖聚鑫
(1.南昌大学软件学院,江西 南昌 330047;2.南昌大学计算机科学与技术系,江西 南昌 330031)
1 引言
Android已经占据了智能手机操作系统的大量市场份额,据Statcounter统计,2019年8月Android占据了全球移动操作系统市场份额的76.23%[1],至2019年,Google Play应用数量超过250万[2]。恶意软件开发者把大量恶意软件进行伪装上传至Google Play 或第三方市场。2018全年,360互联网安全中心累计监测移动端恶意软件感染量约为1.1亿人次[3]。Android应用程序的安全性检测已成为网络安全领域的热点研究问题之一。
根据Android恶意应用的特征性质,检测方法可分为静态检测、动态检测和动静混合检测[4]。3种检测方法中,静态检测的研究更广泛。静态检测是指通过静态特征进行恶意应用检测,该方法可以在软件未安装之前对应用程序进行识别,提前预防恶意行为的发生。静态特征通过对APK(Android Application Package)反编译后,通过相关文件获取,相比于动态特征的获取,较为方便,不浪费用户系统资源。静态特征的提取通常会获取大量的特征信息,其中大部分为冗余特征,因此特征选择是十分必要的工作。而传统的特征选择算法不完全适用于Android恶意应用检测的静态特征选择,如无法去除非典型特征,偏重恶意典型特征,在非平衡数据上对恶意应用识别准确率不良。
本文主要贡献:在分析卡方校验、信息增益、FrequenSel等特征选择算法不足的基础上,给出了良性特征、恶意特征、良性典型特征、恶意典型特征和非典型特征等定义,提出了一种适用于Android恶意应用静态检测的特征选择算法——特征频数差异增强FDE(Frequency Differential Enhancement)算法。平衡数据集和非平衡数据集上的实验结果表明,FDE算法可有效去除静态特征中的非典型特征,筛选出更有效特征。同时,引入权重损失函数弥补不平衡数据的缺陷,可有效提高恶意应用的识别准确率。
2 研究现状
目前,Android恶意应用检测3类方法中,相比于动态检测、动静混合检测2种方法,静态检测方法的研究和应用更为广泛。
静态检测需要对APK进行反编译,从各类文件中提取信息,如权限、API信息等。Felt等[5]评价了权限机制的可用性,研究得出了恶意应用存在过度敏感权限申请问题。Nix等[6]使用API调用序列对恶意应用进行检测,在深度置信网络上检测准确率达到95.7%。Mclaughlin等[7]使用卷积神经网络CNN(Convolutional Neural Network)从原始操作码序列中学习恶意应用的特征,召回率达到96.29%。Yerima等[8]提取权限信息作为数据特征,开发和分析了基于贝叶斯分类的主动式机器学习方法,展示了高精度的检测能力。Wang等[9]集成了5种分类算法,使用11种类型的静态特征识别良性应用和恶意应用,准确率高达99.39%。Shabtai等[10]使用了APK大小、特征数量等非主流特征。
动态检测需要对应用进行安装,获取系统调用、网络流量等信息。早期研究者缺乏对恶意应用行为模式的认识,把手机能量的消耗作为评判依据[11]。随着对动态信息的研究,研究者获得了更有代表性的动态特征。Martinelli等[12]在CNN上建立了一个基于系统调用的检测应用程序,准确率在85%~95%。Vinod等[13]针对系统调用研究了数种动态特征选择算法。Liang等[14]通过将系统调用序列视为文本来设计端到端恶意软件识别模型,准确率达93.1%,F-1值为86.57%。柯懂湘等[15]使用随机森林算法对行为日志中的恶意行为进行识别与分类,该方法对恶意行为分类的平均准确率达到96.8%。
动静混合检测是指将动态特征和静态特征相结合的检测方法。Fang等[16]对静态检测的结果进行动态检测,在XGBoost算法上达到94.6%的检测精度。Alshahrani等[17]把权限、组件信息、系统调用进行结合,实现了可运行在用户设备上的识别器,准确率达到95%。Xu等[18]将静态信息转换为矢量,动态信息转换为图形特征集,组合构建了混合分类器,准确率达到93.4%。Vinayakumar等[19]使用基于多种网络拓扑的长短期循环神经网络对混合特征进行处理,准确率最高为94.2%。
基于静态特征的Android恶意应用检测方法使用的特征种类众多。DREBIN[20]中使用了硬件组件、请求权限、应用程序组件、过滤意图、限制API调用、使用权限、可疑API调用、网络地址等8种静态特征。Zhang等[21]使用了权限、API、组件、字符串4种特征。Luo等[22]只用了API调用信息。分析可见,多数基于静态特征的应用检测研究中,权限和API是最常用的特征。研究者针对静态特征检测使用的分类算法各有不同,Wang等[23]使用了支持向量机、随机森林、K最近邻3种传统的机器学习算法。Arshad等[24]使用了随机森林算法建立了三级混合恶意软件检测模型。深度学习算法也受到很多研究者青睐[25,26]。分类算法种类繁多,针对不同问题有不同的处理效果。
基于权限和API的静态检测中,Android系统要求应用权限信息必须公开,通过权限使用情况,一定程度上可以判断是否为有恶意行为。权限特征声明在AndroidManifest.xml文件中,可以通过对APK的反编译得到。API特征存在于.smali文件中,攻击者想要实现某一恶意行为,必须使用相应的API,所以API信息在恶意软件静态检测中是非常重要的特征。权限与API信息相比,API信息的数量远远大于权限的数量,因为API不仅限于Google提供的,开发者也可以使用自己编写的API,导致API数量庞大。API数量虽多,但大部分的API信息是无用的,并不具有识别恶意应用的功能。
静态检测提取特征信息后,有研究者使用卡方校验、信息增益等传统方法[27,28]进行特征选择。Zhao等[29]在传统算法的基础上提出FrequenSel算法进行特征选择。面对静态特征选择,这些算法都存在一些不足,如非典型特征排名过高,偏重恶意典型特征,重复选择同一特征。很少有研究者对Android恶意应用检测静态特征选择算法进行研究,多数研究者选择传统的特征选择算法或人工特征选择,部分研究者不进行特征选择。
3 特征频数差异增强算法
传统特征选择算法,如FrequenSel(Fre)[29]、卡方校验Chi(Chi-square test)[30]、信息增益Info(Information divergence)[31]等,应用在Android恶意应用检测领域存在一定的不足。其中,卡方校验和信息增益特征选择算法在特征分值计算过程中会赋予不利于辨别良性和恶意应用的非典型特征高排名。FrequenSel特征选择算法在特征选择过程中注重恶意特征的比例,忽略了特征的原始规律,并且在选择良性特征和恶意特征时会重复选择同一特征。为了弥补以上缺点,本文提出一种新的特征选择算法——特征频数差异增强算法FDE。
FDE算法旨在排除非典型特征,遵循特征的原始规律进行特征选择。算法从特征最本质的角度,即各特征在良性应用与恶意应用中出现的频率角度,进行分析设计。应用数据集上数据的非典型特征和典型特征呈现的特点是:良性典型特征只在良性应用中大量出现,恶意典型特征只在恶意应用中大量出现。非典型特征在良性应用和恶意应用中大量出现,或只少量出现在良性应用或恶意应用中。因此,以特征在良性应用和恶意应用中出现的频数差异数和总样本数量的比值作为评价特征的标准,设计特征评价公式如下所示:
(1)
其中,Nm表示包含特征fi的恶意应用数量,Nb表示包含特征fi的良性应用数量,Tm表示恶意应用的总数量,Tb表示良性应用的总数量。
特征评价公式先计算特征在良性应用与恶意应用中出现次数的差值绝对值,再用差值绝对值除以总样本数。其特点是:(1)可计算得出每个特征的分值,每个特征的分值作为特征选择的依据。(2)可有效对非典型特征进行甄别。根据非典型特征和典型特征的特点分析,通过式(1)的计算,非典型特征的S值较小,典型特征的S值较大,因此可有效去除非典型特征,筛选出更有效的特征。同时,该公式是从特征最原始的规律角度设计,不会干预恶意典型特征所占比例。
为有效筛选特征,给出如下相关定义:
定义1(良性特征) 对于某个特征fi,其在良性应用中和在恶意应用中出现的次数记为二元组counti=(Nb,Nm),若Nb>Nm,则称其为良性特征。
定义2(恶意特征) 对于某个特征fi,其在良性应用中和在恶意应用中出现的次数记为二元组counti=(Nb,Nm),若Nm>Nb,则称其为恶意特征。
定义3(良性典型特征) 若某特征fi为良性特征,即counti=(Nb,Nm),其中Nb>Nm,且满足:
(2)
则称其为良性典型特征。
定义4(恶意典型特征) 若某特征fi为恶意特征,即counti=(Nb,Nm),其中Nm>Nb,且满足:
(3)
则称其为恶意典型特征。
定义5(非典型特征) 若某特征fi满足以下2个条件之一,则称其为非典型特征。
(1)counti=(Nb,Nm),且:
(4)
即该特征在良性应用中出现的次数较少,在恶意应用中出现的次数几乎为0,或其在恶意应用中出现的次数较少,在良性应用中出现的次数几乎为0。
(2)counti=(Nb,Nm),且:
(5)
即该特征在良性应用和恶意应用中都大量出现,但出现的次数差的绝对值很小。
根据上述定义,特征频数差异增强算法FDE的思路为:首先,统计总样本数量以及各特征在良性应用和恶意应用中出现的次数;然后,按照式(1)计算每个特征的S值,并按照定义3~定义5进行特征选择。算法伪代码如下所示:
算法1特征频数差异增强算法FDE
输入:特征集合F,阈值ɑ。
输出:新的特征集合F′。
1.Tm←CountMalware;
2.Tb←CountBenign;
3.Fori←1toF.Size()do
4.Nm←CountInMalware(fi);
5.Nb←CountInBenign(fi);
6.S←|Nb-Nm|/(Tb+Tm);
7.IfS≥αthen
8.F′←fi;
9.endif
10.endfor
第1~2行统计恶意样本和良性样本数量;第3~10行执行循环,统计每个特征在良性应用和恶意应用出现的次数,然后计算每一个特征的S值,根据定义3~定义5选取符合条件的特征。其中不同的阈值ɑ取值会产生不同数量的特征。
由算法描述可见,FDE算法只需统计每个特征出现在良性应用和恶意应用中的数量,计算每个特征的S值,并依据相关定义进行特征选择。相比于FrequenSel、卡方校验、信息增益等算法,FDE算法特征评价简便,特征选择依据更加合理,计算消耗低且时间代价呈线性,运行时间增幅与样本输入规模增幅成固定比例。由算法步骤可知,第1~2行执行次数和问题规模无关,仅执行2次,第3~10行执行次数随问题规模n变化,其执行次数最少为5n,最多为6n。故算法计算复杂度仅和样本数量相关,算法最好情况和最坏情况的时间复杂度均为O(n)。
4 实验结果与分析
本文通过3组实验来验证FDE算法的目标效果和性能。第1组实验展示5个特征使用FDE算法的详细计算过程和结果,验证FDE算法是否可达到有效去除非典型特征的目标。第2组实验是在理想平衡数据集上验证不同特征数量下FDE算法的有效性,以及相比其他特征选择算法的优越性。第3组实验是在非平衡数据集上验证FDE算法选择特征的有效性,以及相比其他特征选择算法的优越性。其中,为解决正负样本不平衡情况下各算法组合对恶意样本识别准确率较低的问题,引入权重损失函数,以降低误报率。
4.1 实验数据集与预处理
在Google Play应用市场下载5 000个良性应用,VirusShare下载5 000个恶意应用,通过Androidguard反编译得到AndroidManifest.xml和.smali文件,提取权限和API调用信息。10 000个应用构成平衡数据集,共提取14 610个特征,按7∶3比例划分训练集和测试集。非平衡数据集中良性与恶意应用比例为5∶1,共提取13 789个特征,按10∶1划分训练集和测试集。原始特征为权限信息和API信息,需将特征信息数字化,样本中如果包含该特征则该栏特征信息为1,否则为0。表1展示了少量权限信息的特征数字化。

Table 1 Examples of individual sample feature digitization 表1 个别样本特征数字化示例
4.2 评价指标
TP(True Positive):将正类预测为正类;
TN(True Negative):将负类预测为负类;
FP(False Positive):将负类预测为正类;
FN(False Negative):将正类预测为负类。
准确率:
(6)
精确率:
(7)
召回率:
(8)
误报率:
(9)
F-1:
(10)
均值:
(11)
方差:
(12)
ROC(Receiver Operating Characteristic)曲线:ROC曲线是以假正率(FPR)和真正率(TPR)为轴的曲线,设定不同的判定正负样本阈值,可以得到不同的TPR和FPR点对。将一系列点对连接成平滑的曲线,则为ROC曲线。TPR和FPR的定义见式(8)和式(9),其中TPR=Recall。
4.3 FDE算法目标效果验证
设计FDE算法的目的是为了去除非典型特征,选择更有效的特征。为验证FDE算法是否达到设计目的,从14 610个特征中选取5个特征进行计算和分析。表2展示了5个特征的特征信息及FDE算法计算结果。
详细计算过程如下所示:
步骤1统计恶意样本和良性样本数量Tm=5000和Tb=5000。
步骤2分别统计5个特征在恶意样本和良性样本中出现的次数Nm和Nb。
步骤3根据式(1)计算5个特征的S值。
步骤4根据特征选择标准,选择S值大于或等于0.1的特征,5个特征中有3个特征的S值大于0.1。
表2中非典型特征Landroid/net/SSLSessi-onCache和Landroid/graphics/Typeface经FDE算法计算,分值较低,与其他典型特征分值差距较大,排名第4位和第5位,不在选取特征范围之内。后续使用卡方校验方法对上述5个特征进行分值计算,结果显示非典型特征Landroid/net/SSLSessionCache分值排名第3位。计算结果表明,FDE算法能达到有效去除非典型特征的目的。
4.4 平衡数据集实验结果与分析
给定平衡数据集,将FDE算法中ɑ设置为不同值,验证不同特征数量时FDE算法的有效性,以及相比其他算法的优越性。ɑ取值分别为0.1,0.15,0.2和0.25,产生的特征数量分别为778,566,398和233。将经过特征选择后的不同数量特征放入SVM、KNN、CNN、Bayes、决策树DT(Decision Tree)5种分类器中进行实验对比,其中,由于CNN的特性,在平衡数据集上有关CNN实验结果皆取500次迭代的平均值作为实验结果。各分类器实验结果如图1所示。
图1a展示了各分类器准确率的变化。由图1a可见,随着特征数量的增加,多数分类器的准确率都呈上升趋势。其中,SVM分类器的效果最优,准确率最高值达98%,CNN分类准确率略低于SVM的,Bayes分类效果最差,准确率最高值仅为93.30%。DT分类准确率呈现上下波动状况,与KNN分类准确率基本接近。
图1b展示了各分类器在778个特征上的ROC曲线(不含CNN算法,原因在于CNN取500次迭代平均值,无法生成其ROC曲线)。ROC曲线能够综合反映一个分类器的好坏,4种分类器ROC曲线中,最靠近左上方的是SVM的曲线,DT和KNN的曲线基本重合,Bayes的曲线最靠近右下方。实验结果表明,5种分类器中最适合FDE特征选择的是SVM分类器,效果最差的是Bayes分类器。

Table 2 Instance data and calculation analysis of FDE algorithm表2 实例数据及FDE计算分析

Figure 1 Experimental results of FDE algorithm’s effectiveness with different features number图1 不同特征数量时FDE算法的有效性实验结果
为比较FDE算法和其他特征选择算法的性能差别,选择卡方校验、信息增益、FrequenSel和FDE算法在SVM、KNN、CNN 3种分类器上进行实验对比,实验结果如图2所示。由于FrequenSel无法自主选择特征数量,经参数调整特征数量最低为930个,将单独把FrequenSel选择的930个特征和卡方校验、信息增益、FDE等选择的778个特征作比较。
图2展示的实验结果中,SVM+Chi表示为SVM算法结合卡方校验特征选择算法所得的实验结果,后续图表中相关表示具有同种含义。由图2a可知,FDE在各特征数量选择上的准确率都优于卡方校验和信息增益特征选择算法的。图2b和图2c所示为召回率和F-1值实验结果,由于对CNN的准确率取500次迭代的平均值,所以无法得出其具体的召回率和F-1值。在召回率上FDE没有表现出绝对优势,卡方校验与SVM的组合拥有最高的召回率,但在KNN分类器上,FDE的召回率基本优于其他2种算法的。在F-1值上,FDE算法与SVM的组合拥有最高值,且各特征数量上的F-1值优于其他特征选择算法的。
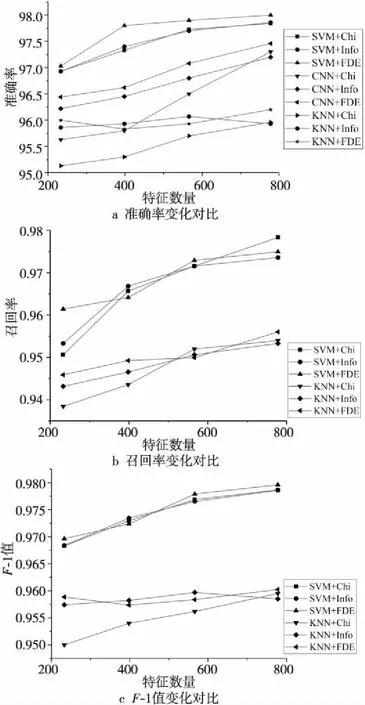
Figure 2 Experimental results of FDE algorithm with other feature selection algorithms图2 FDE算法与其他特征选择算法对比实验结果
表3给出了FDE算法与FrequenSel、卡方校验、信息增益等算法在SVM、CNN、KNN 3种分类器上的比对实验结果。FrequenSel特征选择算法在SVM和CNN上的准确率都是最低的,在KNN上的准确率高于卡方校验和信息增益的,但低于FDE的。在召回率及F-1值上,FrequenSel在KNN上有较好表现,但在SVM上均最差。从3种评价指标的最高数值来看,FDE算法优于FrequenSel算法。
同时,为更详细地比较各特征选择算法对分类的影响,本文从分类概率值角度,验证分析了在SVM分类器上FDE与其他特征选择算法对分类概率值的影响。实验中选取了平衡数据测试集中的1 522个恶意样本和1 478个良性样本,对各特征选择算法在SVM分类器上的分类概率值进行了验证分析。首先,选择表现最优异的SVM分类器,然后统计SVM结合不同特征选择算法的分类概率值,计算出均值和方差。通过均值分析分类概率值的整体大小,通过方差分析分类概率值的离散程度。
表4展示了在SVM分类器上各特征选择算法对分类概率值的影响结果。在良性测试样本上SVM+FDE的分类概率值的均值略低于SVM+Chi的,方差略高于SVM+Chi的。在恶意测试样本上SVM+FDE的均值最高,方差最小。结合召回率说明SVM+FDE倾向于恶意类别的识别,SVM+Chi在良性样本的识别上效果要略好于SVM+FDE。虽然SVM+Chi在良性测试样本上的分类概率值的均值和方差最优,但在恶意测试样本上的分类概率值的均值和方差都是最差的。良性样本和恶意样本的分类概率值汇总计算后得出,SVM+FDE拥有最高的均值和最低的方差,所以SVM+FDE的分类概率值更大、更稳定,FDE对分类的影响效果更好。

Table 3 Experimental results of FDE algorithm,FrequenSel algorithm,Chi-square test algorithm and Information divergence algorithm on SVM,CNN and KNN 表3 FDE与FrequenSel、卡方校验、信息增益等算法在SVM、KNN、CNN 3种分类器上的比对实验结果

Table 4 Average value and variance of classify probability values of FDE and other feature selection algorithms on SVM表4 FDE与其他特征选择算法在SVM上分类概率值的均值和方差
表5中对比了SVM+FDE与其他4位研究者文章中的实验结果。实验结果表明,与FDE结合效果最好的SVM分类器的准确率、F-1值都高于其他4篇文献的方法,但在召回率上略有不足。
小结:(1) 5种分类算法验证实验上的结果表明,FDE算法是有效可行的。(2) 与FrequenSel、卡方校验、信息增益等特征选择算法的对比实验结果说明,SVM+FDE拥有最高的准确率和F-1值,但SVM+Chi的召回率最高。召回率只是单方面地反映对正样本的识别准确度,但准确率和F-1值更能综合反应方法的好坏,且FDE算法对分类概率值的影响较好。这表明FDE算法有效且优于其他算法。(3) FDE算法的不足之处为:对良性样本的识别比其他算法略差,即召回率略低。导致这种情况的原因有2种可能:一是FDE算法设计的目的是去除非典型特征,选择有利于识别恶意应用的特征,从而导致对恶意应用识别效果较好,对良性应用的识别效果较差。二是由于本文只使用了权限和API信息作为特征,仅依据这2种特征可能不能全面地分辨良性应用与恶意应用。
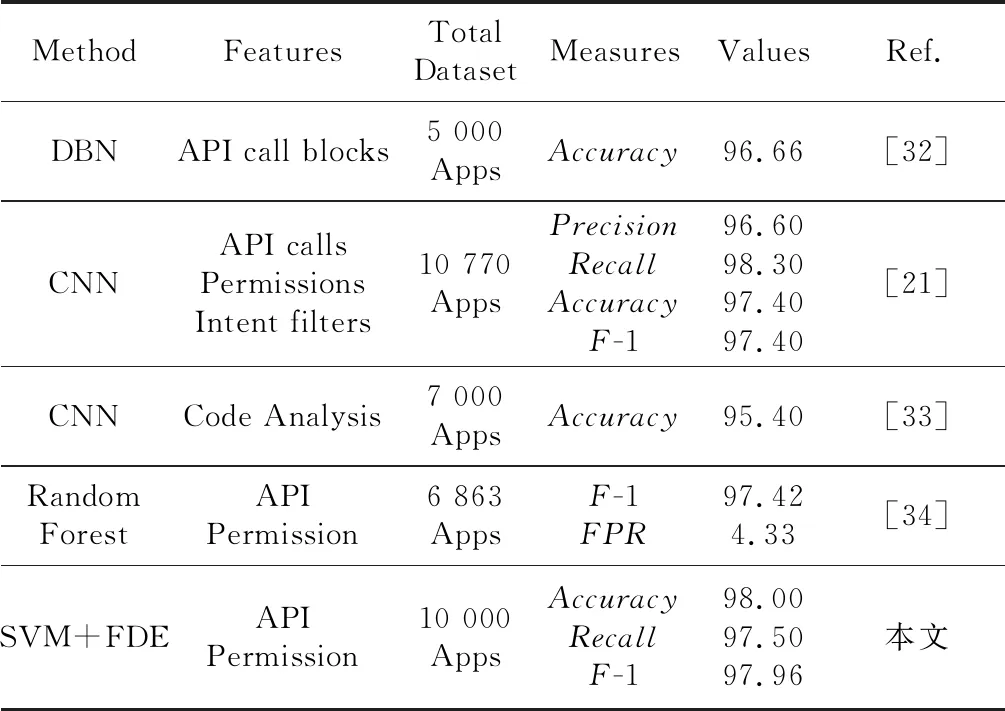
Table 5 Comparison of the method in this paper with other methods表5 本文方法与其他方法比较
4.5 非平衡数据集实验结果与分析
为模仿良性应用数量远超出恶意应用数量的真实应用软件环境,本文在10 000个应用的基础上,删除4 000个恶意应用,形成正负样本比为5∶1的非平衡数据集。重新进行特征提取后获得13 789个特征,使用FDE算法进行特征选择,共选择1 062个特征。与平衡数据集选择的778个特征作比较,其中有709个特征重合,权限类特征重复率为零。实验训练集包含3 850个应用,测试集共2 150个样本。
首先,设计实施了非平衡数据上FDE算法特征选择有效性验证和FDE算法与其他特征选择算法性能比对实验。实验中,卡方校验、信息增益、FrequenSel皆重新进行特征选择,并分别在SVM和CNN分类器上进行实验比较,实验结果如表 6所示,其中所有CNN实验均运行5次,每次迭代150次,每次运行结果取值于最后一次的迭代结果,统计5次运行的结果。
表6中,Accuracy-max为最高准确率,Accur-acy-aver为平均准确率,M-Accuracy为恶意样本识别准确率。实验结果表明,当正负样本比例不平衡时,各特征选择算法效果均有所降低。在CNN实验中,FDE算法的最高准确率和平均准确率最高,最高值为96.56%,平均值为96.35%。且对恶意样本识别效果最好,最高值达到93.85%,平均值达到93.72%。在SVM分类器上,FDE算法的效果略低于信息增益特征选择算法的。同时,对比了各特征选择算法进行特征提取的时间,结果表明,FDE算法的时间远远少于卡方校验和信息增益的,略少于FrequenSel的特征提取时间。以上分析表明,FDE算法在非平衡数据集上同样有效,且相比其他特征选择算法具有一定的优势。
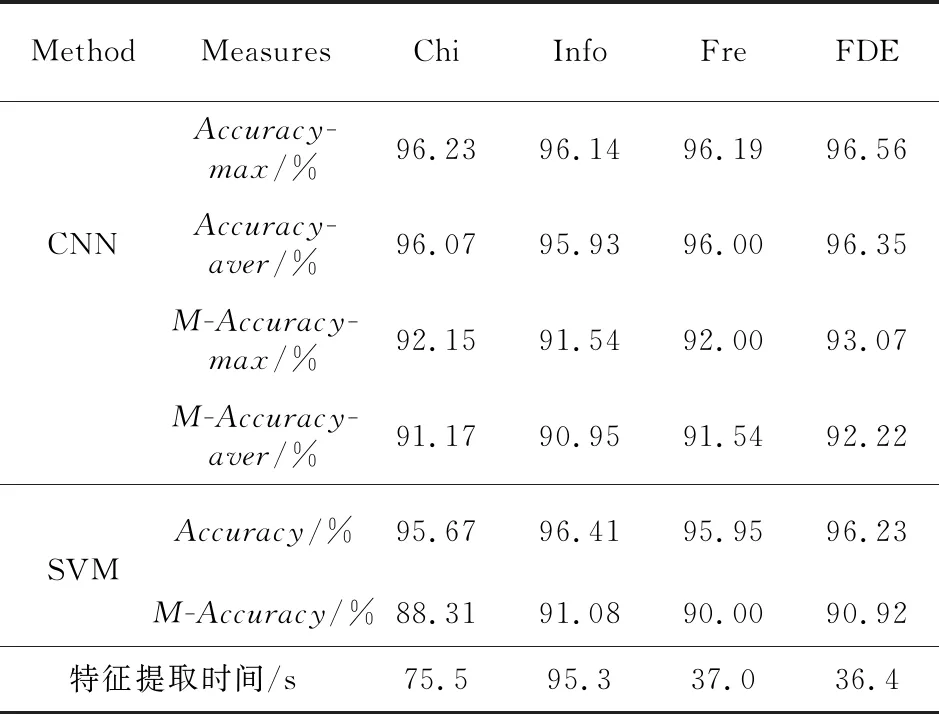
Table 6 Experimental results on unbalanced data sets表6 非平衡数据集上实验结果
其次,注意到由于正负样本的不平衡,使得各算法组合对恶意样本的识别准确率明显低于对良性样本的识别准确率。由于特征良性或恶意判断问题可理解为二分类问题,为解决恶意样本识别准确率低的问题,引入权重损失函数。
以交叉熵函数作为损失函数,计算公式如下所示:

(13)
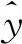
考虑到样本的不平衡性,在损失函数中赋予不同类别不同的权重,改进式(13)得权重损失函数如下所示:
(14)
其中,W0为第1个类别的权重,W1为第2个类别的权重。若W0值较高,W1值较低,第1类中的样本被错分时,权重损失函数值比无权重的损失函数值更大,而第2类中的样本被错分时,对损失值的影响较小。因此,影响网络倾向于学习某些类而降低损失值。对于多分类的问题,同样可以使用这种赋予权重的方式来让网络倾向于某些类。
实验中,采用FDE+CNN组合的方法验证引入权重损失函数的效果。图3展示了FDE+CNN组合方法下各权重误报率和准确率变化情况,其中,良性类别权重为BW,恶意类别权重为MW。误报率可以反映测试集中恶意样本被错分为良性应用的比例。
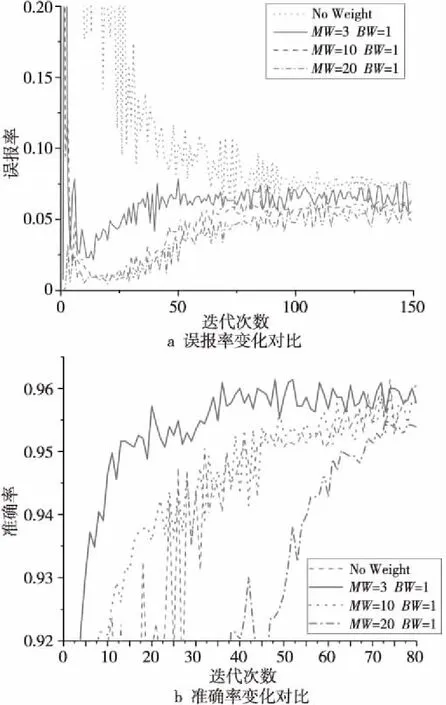
Figure 3 Weight adjustment experimental results of FDE+CNN combination method图3 FDE+CNN组合方法的权重调整实验结果
由图3a和图3b可见,随着迭代次数的增加,误报率呈现先下降后升高的趋势,且随着恶意样本类权重数值的增大,误报率整体呈下降趋势,但准确率呈先上升后下降的趋势。这表明恶意类别权重数值增大可以减少误报率,但权重超过一定数值,会降低整体准确率。
因此,经多次权重参数调整,最终权重取值确定为MW=3,BW=1。此权重下恶意样本识别准确率为94.31%,整体准确率为96.37%。相比于表6中未考虑权重损失函数的实验结果,恶意样本识别准确率得到提高,整体准确率和平均值相近,但对良性样本的识别率有所下降。
该实验结果表明:(1)在非平衡数据集上FDE算法同样有效,且相比于其他特征选择算法,具有整体准确率高、善于识别恶意应用、特征提取时间短等特点。(2)针对非平衡数据中恶意应用识别率较低的问题,引入权重损失函数,赋予恶意应用类别高权重可提高对恶意应用的识别准确率。
5 结束语
本文针对Android恶意应用静态检测提出了一种新的特征选择算法FDE,其目的是为了解决已有特征选择算法在检测中存在的不足,以筛选出更有效的特征,提高检测的准确率。FDE算法从特征最本质的角度筛选有效特征,去除非典型特征,从大量特征中选取少量特征作为分类算法的输入,减少模型训练时间与特征提取时间。理论分析和实验结果表明,FDE算法是有效可行的,且相比于其他特征选择算法具有自身的优势。但是也反映出,FDE算法还存在需要改进完善之处:对非典型特征做的限定略显粗糙,可能会使一些典型特征被限定为非典型特征,且实验中分类器在召回率上的表现略有不足。未来值得进一步探讨的方向有:(1)新特征[35 - 37]或有效特征的组合方法。有研究者发现仅靠权限和API信息2种特征并不能全面地检测恶意应用,可以挖掘更具有代表性的特征进行恶意应用检测。(2)对抗攻击的深度学习检测方法研究。随着深度学习的广泛应用[38],有研究者利用深度学习的脆弱性实现了针对基于深度学习的对抗攻击。(3)基于Android的其他恶意行为检测,如钓鱼网站检测[39]等。
猜你喜欢
云南画报(2021年8期)2021-11-13
北京航空航天大学学报(2021年6期)2021-07-20
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
专用汽车(2015年1期)2015-03-01
航天返回与遥感(2014年5期)2014-07-31
中原工学院学报(2014年4期)2014-04-01
