
表示学习技术研究进展及其在植物表型中应用分析
2020-06-29 01:17袁培森李润隆任守纲顾兴健徐焕良
农业机械学报 2020年6期
袁培森 李润隆 任守纲 顾兴健 徐焕良
(南京农业大学信息科学技术学院, 南京 210095)
0 引言
表示学习是一种将研究对象的内在信息表示为稠密低维实值向量的方法[1],在学习使用特征的同时,也需要学习如何提取特征[2]。表示学习的研究对象主要是文本[3-4]、图像[5-6]、视频[7-8]等。应用于文本处理的表示学习模型主要有Word2vec[4]和神经网络语言模型[9]。应用于图像处理的表示学习模型有自动编码器[10]、深度哈希[11]等。应用于视频处理的表示学习模型包括卷积神经网络[12]、堆叠自编码器[13]等。
表示学习可以分为监督特征学习和无监督特征学习。监督特征学习主要包括监督字典学习[14]和神经网络[15];无监督特征学习主要包括主成分分析[16]、自动编码器[17]以及概率图模型[18]。在处理海量高维的植物表型数据任务中,表示学习凭借其自动提取特征的能力,表现出高效性[1],获得了研究者的关注。
植物表型是近年来植物学领域研究的热点,其本质是植物基因图谱的时序三维表达及其地域分异特征和代际演进规律[19]。1911年,丹麦遗传学家WILHELM将生物体的表型定义为基因型和环境因素相互影响的结果,其中,基因型是表型得以表达的内因,而环境是各类形态特征得以显现的外部条件[20]。随着透射、波谱、显微等检测技术以及生物信息技术和计算机技术的快速发展,该定义范围被扩展到了生物化学[21]和行为学[22]等领域。总体而言,植物表型不仅可以反映出植物的理化性质、形状及内部结构[23],也可以体现基因在分子尺度上的特征,甚至可以反映出病理性质[24]。
传统的植物表型研究使用人工测量和记录的方式,这种方法采集到的样本数据集小,并且仅能够获取器官[25]、轮廓[26]、高度[27]等外部表征,效率较低,难以对植物的多种性状进行综合分析和研究[28]。
近年来,随着分子育种技术以及植物功能基因组相关研究的不断深入,表型数据也扩展到行为特性以及体内和体表的理化和生化特征[29]。植物表型数据类型包括结构化、非结构化的图像以及文本数据[19],并且具有数据量大[30]、数据多态性[31]以及数据时效性的特点。这对于植物表型的获取以及处理分析技术提出了很高的要求,需要生命科学、计算机科学以及工程学等多学科知识的交叉融合[32]。
在传统植物表型分析研究过程中,研究人员需要通过费时、费力的手工标注方式建立特征,再进行相关学习算法的部署,这表明传统植物表型研究技术无法自动提取数据的特征信息。在这类处理大量复杂或者人为先验理解有限的数据任务时,表示学习表现出其高效性[1]。
在植物表型研究中,表示学习已经在文本、图像、三维点云等植物表型数据的分析研究中获得了广泛运用[33]。本文对表示学习的相关概念及其模型进行简述分析,阐述植物表型概念[22,24]及其处理方法,重点对表示学习在植物表型应用中的优势及问题[34]进行分析,最后对表示学习在植物表型中的应用趋势进行总结与展望。
1 表示学习技术研究进展
1.1 表示学习的概念
表示学习(Representation learning),又称为学习表示,指的是通过学习产生对观测样本有效的表示,使得能够在建立分类器或者其他预测器时提取更有用的信息[35]。表示学习的目标是通过学习把所需的研究对象的内在信息表示为稠密低维实值向量,解决输入数据的底层特征和高层语义信息之间的不一致性和差异性的问题。设输入样本数据为X=(x1,x2,…,xn),通过表示学习能够得到一个低维特征表达X′=(x′1,x′2,…,x′m),m≪n。当该实体和关系处在知识库中时,可以通过计算欧氏距离等方法来获得任意2个对象之间的语义相似度[36]。
表示学习通过解决输入数据中的底层特征与其高层语义信息间产生的差异性问题,为后续的机器学习模型构建提供良好基础。表示学习主要有两个优点。首先它能够从大量复杂且人为先验理解有限的数据中自动提取特征。其次,表示学习的向量维度较低,可以根据对象间的语义信息进行更加充分的提取,从而解决数据稀疏问题[37]。
表示学习与深度学习(Deep learning)具有密切的关系,如图1所示。表示学习属于深度学习算法中提取特征的一部分,通过自动学习获得好的特征表示,从而提高深度学习模型的预测准确率。原始数据进行非线性特征转换的次数被称为深度。深度是表示学习模型的特点,表示学习模型通过具有深度的模型来提取各层特征,从而获得好的表示[35]。
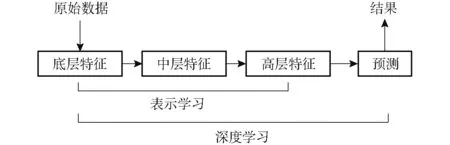
图1 深度学习与表示学习关系Fig.1 Relationship of deep learning and representation learning
深度学习解决的关键问题是贡献度分配问题,从而最终提升预测模型的准确率。如图1,假如把一个表示学习系统看作是一个有向图结构,则深度学习覆盖从输入节点(原始数据)到输出节点(预测结果)所经过的最长过程。
1.2 表示学习模型
表示学习可以分为监督特征学习和无监督特征学习两种类型,如图2所示。常用的监督特征学习模型主要包括监督字典学习(Supervised dictionary learning)[14]和有监督神经网络(Supervised neural network)[15];常用的无监督特征学习模型主要包括主成分分析(Principal component analysis)[16]、自动编码器(Autoencoders)[17]和概率图模型(Probability graph model)[18]。
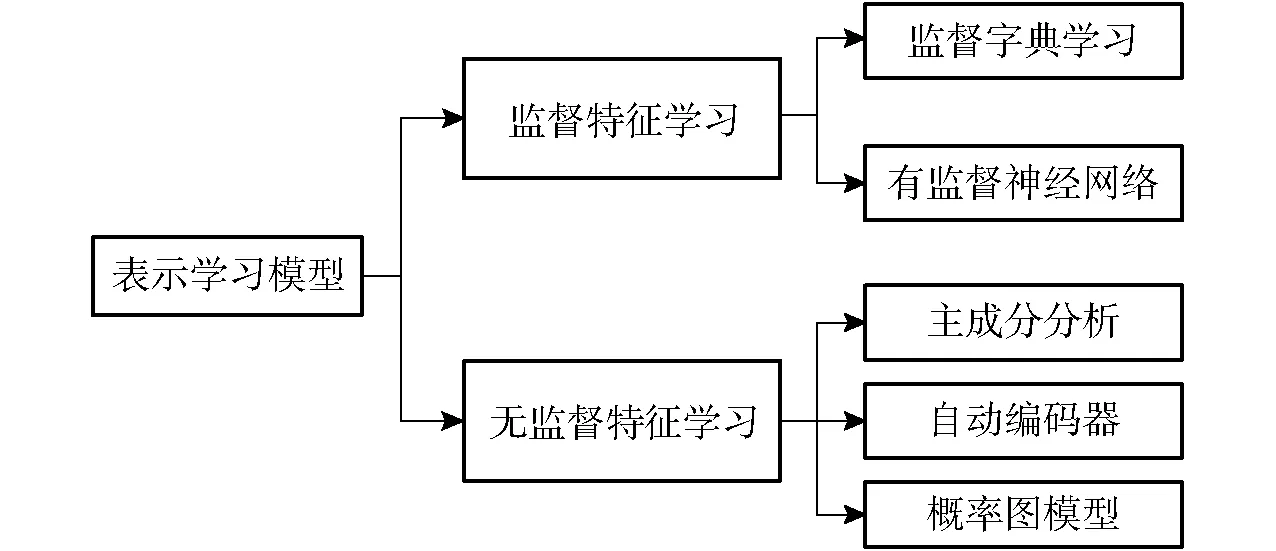
图2 表示学习模型分类Fig.2 Classification of representation learning model
下面对图2中的常用表示学习模型进行介绍,并且对其中一些模型在植物表型应用上的优缺点进行对比分析,结果如表1所示。

表1 常用表示学习模型对比Tab.1 Comparison of common representation learning models
1.2.1监督特征学习
1.2.1.1监督字典学习
字典学习是从输入数据中学习一组代表元素的字典,其中每个数据都可以表示为代表元素的加权和[38]。监督字典学习指将分类信息添加到字典学习中,从而利用输入数据和标签的隐含结构来优化字典。
设数据集为X={X1,X2,…,Xc}∈Tp×n,其中c为类别的数量,T是样本,p是每个样本对应的维数,n是训练的总样本数。训练字典为D={D1,D2,…,Dc}∈Tp×k,p是字典中原子数量,与样本维度一致,k是字典中原子数量。初始化字典Di=Xi,Xi指属于第i个分类的所有训练数据,字典求解算法使用基于表示的稀疏分类算法[14],为
(1)
式中,xts∈Tp为测试数据集,X为用于训练字典的数据集,α为用于计算分类残差的稀疏编码,分类残差计算式为
(2)
δi函数用于根据分类来选择合适的稀疏编码,ri函数根据测试数据xts计算各个分类的残差,测试数据所属的分类即残差最小的分类[38]。
字典学习在植物种类图像识别方面得到了广泛的应用,能够通过基于纹理[46]或者直接处理原始图像的方法[38]建立稀疏表示字典,从而完成植物器官图像分类任务。其优点在于其非线性的结构能够使得表达能力更强,有效对图像、三维点云等数据进行降维表示,且计算速度快[14]。缺点是在分类数目较多的情况下算法效果不好。
1.2.1.2有监督神经网络
有监督神经网络是通过相互关联的节点构成多层网络的有监督学习算法的总称[47]。有监督的神经网络包括深度神经网络[47]、循环神经网络[48]、递归神经网络[49]和卷积神经网络[50]。多层神经网络可以用来进行特征学习,因为它可以获取隐藏层中的输出特征。
图3中的卷积神经网络是一种经典的使用卷积计算并且拥有深度结构的前馈型有监督神经网络。通常由卷积层(Convolution)、池化层(Pooling)、全连接层(Fully-connected)等部分组成[51]。卷积层用来分析上一部分特征中间的局部特征之间隐含的信息,而池化层则是分析并且结合具有相似意义的信息,从而可以在上层的特征图中获得有用的信息[50]。全连接层中,每层的每一个神经元都和上一层的所有神经元连接并且分析所有信息,将信息降到低维,再把信息传输给回归器、分类器等来获得最后结果。
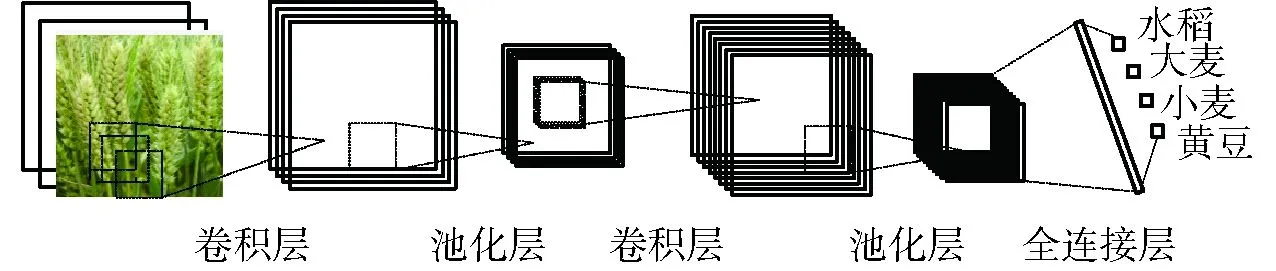
图3 卷积神经网络经典模型[50]Fig.3 Classic model of convolutional neural network
目前,大量CNN的常用深度学习框架包括TensorFlow[50]、PyTorch[52]、Caffe[53]等,这些框架完成了深度学习的底层架构实现,为研究人员提供了方便进行调用的接口,获得了广泛的应用。研究人员通过对有监督神经网络模型的结构和参数进行调整,使得其在植物种类识别[34,54]、病虫害分析[55]、产量预测[56]、形态结构表型数据计算[57]等研究中都得到了广泛应用。卷积神经网络在处理海量高维植物表型数据任务时获得了较高的准确度,但是其需要大规模的数据集进行训练和测试[39]。
1.2.2无监督特征学习
1.2.2.1主成分分析
主成分分析主要用于降维,能够将多个变量化为少数几个互相无关的综合变量[58]。主成分分析的步骤如下:数据预处理;判断要选择的主成分数目;选择主成分;解释结果;计算主成分得分。
主成分分析能降低植物表型数据的维数,是多维数据的一种有效表示方法,并且可以较好地表示植物表型的信息而不丢失重要特征,从而在杂草识别[40]、叶片分类[59]等表型数据分析任务中获得较高的准确率。但是主成分分析有几点局限:主成分分析依赖于原始数据的正交变换;只有在输入数据向量是互相相关的情况下主成分分析才能很好地降维;并且其无法通过调参等方法对结果进行干预[41]。
1.2.2.2自动编码器
自动编码器是一种尽可能将输入信号进行复现的无监督神经网络。自动编码器的目的是基于输入的无标签数据X=(x(1),x(2),…,x(n)),通过训练从而获得降维之后的特征表达H=(h(1),h(2),…,h(m))[10]。自动编码器分为编码器和解码器,自动编码器通过学习hw,b(x)≈x来尝试逼近恒等函数,使得输出结果接近于输入x。
最经典的自动编码器已发展了很多不同的种类,包括稀疏自编码器[43]、栈式自编码器[60]、降噪自编码器[61]。
稀疏自编码器中的稀疏指的是限制编码后隐藏层的神经元个数[43],栈式自编码器指由多层稀疏自动编码器级联从而完成特征提取的神经网络,将前一层自动编码器的输出结果作为后一层自动编码器的输入结果,并且在逐层训练结束后进行微调[60]。降噪自动编码器是在原有的自动编码器的基础上要求自动编码器具有通过学习恢复出原始信号的能力,其泛化能力较强。
降噪自动编码器通过对输入添加随机噪声,再通过编码解码来获得健壮的结构,从而对原来数据加以恢复[61]。自动编码器作为一种无监督的神经网络,能够凭借其对二维图像特征较好的保留能力,对根[42]、种子[62]等测量困难的植物表型数据进行快速提取计算。但是其隐藏层的维度较难选择,确定起来比较困难。
1.2.2.3概率图模型
从概率的角度来看,表示学习可以解释为获取数据集中简单潜在随机变量的一种方法,概率图提供了两类可能的建模方式:有向图和无向图(图4)。概率图模型是综合运用概率论和图论来描述统计关系的应用模型[35]。有向图模型主要包含贝叶斯网络以及隐马尔可夫模型,无向图模型主要包括马尔可夫随机场以及条件随机场[63]。
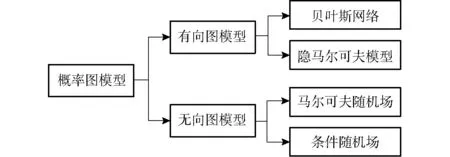
图4 概率图模型Fig.4 Probability graph model
图4中的条件随机场是给定随机变量X条件下的随机变量Y的概率分布无向图[63]。条件随机场对于观测数据没有独立性要求,能够对复杂的上下文关系进行特征的归一化,对图像的纹理特征进行有效提取[44]。条件随机场在农业场景图像上对植物种类进行了有效识别和区分[45],也能够对植物图像数据进行疾病检测分析,获得比有监督卷积神经网络更高的准确度,达到了99.79%[44]。条件随机场的缺点是复杂度高[45]。
1.3 文本处理方法
表示学习可以计算在低维空间中实体之间的关系,从而高效解决数据表示的稀疏问题。表示学习可以发现文本之间的内在关系,发现文本之间的语义层级关系。文本的处理方法可以分成独热码表示(One-hot representation)、连续表示或者词嵌入。本部分对文本的两种表示学习模型:神经网络语言模型[9]和Word2vec模型[4]加以阐述。
1.3.1神经网络语言模型
BENGIO等[9]在训练语言模型的过程中提出了词向量的基本模型:神经网络语言模型(Neural network language model),提出了一个3层神经网络模型,对语言模型和词向量同时建模。神经网络语言模型生成的词向量能够很好地根据特征距离计算词的相似性[64],因此获得了较好的实际运用,能够对植物表型信息进行语义挖掘[65]。
1.3.2Word2vec
MIKOLOV等[4]提出了用于词向量计算的模型Word2vec,该模型能够将每个词映射到一个向量。Word2vec通过CBoW(Continuous bag-of-words)或Skip-Gram模型来建立神经词嵌入。二者的共同点在于对每个单词都设定一个输入向量和一个输出向量,CBoW在给定上下文的情况下预测当前词,Skip-Gram模型在给定当前词的情况下预测上下文。Word2vec可以在百万数量级的词典和上亿的数据集上进行高效训练。同时,该工具得到的词向量可以很好地度量词与词之间的相似性,能够通过对大量水稻文献的训练来获取水稻文本中语义距离最近的短语[66]。
1.4 图像处理方法
图像处理的关键是对于图像的表示,它是进行计算机视觉的目标识别和分类归纳的重要技术[67],通过特征的学习和提取将特征提取为高层特征,除了传统的Gist等特征,近年来也产生了很多基于哈希算法以及深度学习的表示方法。
1.4.1Gist特征
Gist特征是一种场景特征描述,该特征通过模拟人的视觉器官获取图像中的关键上下文信息[68]。图像的Gist特征由多尺度多方向的Gabor滤波器组对图像进行滤波处理之后获得。
一幅尺寸为r×c的灰度图像f(x,y)用尺度为m和方向为n的Gabor滤波器组进行滤波,即先同nc个通道的滤波器进行卷积,其中nc=mn,再进行级联卷积得出图像的Gist特征。
Gist特征可以较好地提取单一场景的特征,从而基于Gist纹理特征对植物叶片进行种类识别[69],但是对于包含多个场景的图像,这种特征的区分性能大幅降低。
1.4.2尺度不变特征变换特征
尺度不变特征变换特征(Scale invariant feature transform,SIFT)在1999年由LOWE[70]提出,具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
SIFT特征主要具有以下优势[71]:图像的局部特征不受旋转、缩放、亮度等变化影响,同时对于视角及仿射变化、噪声的处理也较为稳定;能够对大量特征的数据集完成快速准确的匹配;多量性,即使样本数很少也能够产生大量的SIFT特征。因此,利用SIFT特征提取能够完成自然光下的植物分类任务[72]。
1.4.3基于哈希算法的图像处理技术
哈希指把任意长度的输入通过散列算法来转换成固定长度的输出,即获得散列值。哈希方法主要分为两大类:以局部敏感哈希为代表的传统哈希,以及学习型哈希[11]。
传统哈希算法的代表为局部敏感哈希(Locality sensitive hashing,LSH),其基本思想是使用一组哈希函数把数据散列到多个桶中,使得相近的数据落在同一个哈希桶,越相似的数据分配到同一个桶中的概率越大[73]。局部敏感哈希提供了一种在海量高维数据集中高效查找数据点近似最相邻的方法,从而可以加快大量数据查找的匹配速度。文献[74]采用4 100幅不同花型的菊花图像作为数据集,提出使用多探测局部位置敏感哈希技术对菊花图像数据的哈希数据结构进行构建,在菊花相似性查询方面提高了计算效率。
学习型哈希可以借助深度神经网络的优势,同时学习图像表示和哈希编码,更好地表达图像特征信息,取得比传统哈希算法更好的结果。LI等[75]提出了深度离散监督哈希,是早期将深层神经网络与哈希编码融合的工作之一,它使用两个阶段来学习图像特征表示和哈希编码。XIA等[76]提出了基于深度的哈希检索方法,能够获得具备哈希表征的良好的图像表示。YUAN等[77]提出了一种基于端到端的低维二值嵌入框架的方法,该方法通过深层卷积神经网络学习紧凑的二进制编码(Compact binary codes),提高了高通量菊花花卉图像表型相似性评估的性能和有效性。
1.4.4卷积神经网络
根据图像表示的提取流程来进行分类,卷积神经网络特征提取方法可以分为3类:局部表示聚合[78]、深度卷积特征聚合和多层融合[79]。
局部表示聚合从图像当中提取局部区域信息,输入前馈网络生成部分图像区域的表示。随后使用特定聚合方法来聚合图像数据,形成最后结果,效率相对较高[78]。深度卷积特征聚合将多幅图像局部区域输入到前馈网络来生成局部特征,只进行一次前馈,就可以生成深度卷积特征,并且可以处理任意大小的图像输入。多层融合根据层次性特征进行设计,从而使深度神经网络中不同层面的信息相互补充,获得特征不变性和更好判别能力[79]。
卷积神经网络凭借其优势,完成了植物表型图像数据的识别以及分类任务[34,54]。文献[80]采用6 000幅菊花图像作为数据集,基于端到端的卷积神经网络技术进行特征学习,实现了菊花种类的准确识别,平均识别率达到0.95。
2 表示学习在植物表型中的应用分析
2.1 植物表型数据处理
植物表型数据处理主要包括数据的获取解析以及管理应用。
2.1.1植物表型数据获取与解析
目前,生物传感器、图像处理、物联网及人工智能等技术的飞速发展为新一代表型数据快速获取和处理提供了海量数据集和处理手段[28]。目前,植物表型数据研究者通过构建表型相关基础设施、研发低成本表型获取装置的方式来提高表型数据的通量及分辨率。
植物表型数据获取是指对植物形态特征进行描述的过程,经典的表型数据获取方式通过手工观察和测量,但是这一方式效率低且错误率高。李少昆等[25]使用相机及扫描仪采集作物株型数据,使用人工标记的各器官表型数据来拟合出曲线,同时基于图像处理技术的工作特点,获得了玉米等作物的株高、叶宽等30种表型数据的信息。方伟等[26]对图像数据采集系统得到的植株图像数据进行预处理获得植株轮廓信息,随后标定相机进行特征识别,使用多幅二维图像进行融合获取植株的三维模型。
近年来,研究人员开发了能够自动进行植物表型数据获取的系统。CONSTANTINO等[27]开发了能够对水稻株高以及分蘖数进行自动测量的系统,首先通过HSV颜色以及空间阈值进行预处理,接着使用Canny边缘检测以及Zhang-Suen细化算法来计算高度,最后通过计算ROI区域的像素簇来统计分蘖数。PAPROKI等[81]使用一种新型混合网格分割算法来解决图像分割任务中的植株形态差异以及叶柄被叶片遮挡等问题,基于主茎、叶柄等表型数据计算了主茎高度、叶宽等参数。
2.1.2植物表型数据管理与应用
植物表型数据除了结构化的数值型或字符串型的数据,还包括了大量的图像数据。常见的关系数据库能够实现结构化的数据存储检索等功能,但由于近年来点云、光谱等表型数据的发展,海量的表型数据对于存储的数据结构和存储方式提出了新要求。在存储这些数据时,非结构化植物表型数据管理系统取代了传统二维表结构的存储方式[19]。常用的非结构化植物表型数据管理系统有基于关系数据库系统扩展的非结构化数据管理系统CropSight[82]、基于NoSQL的非结构化数据管理系统SensorDB[39]等。植物表型数据的应用场景包括植物识别、产量预测、病虫害检测以及植物改良育种等。研究人员利用图像数据的灰度[40]、颜色、纹理[41]等特征完成了分类、分割以及识别等任务。
2.2 基于表示学习的植物表型研究
2.2.1植物种类识别
植物种类识别研究对于生态监测任务至关重要,可以有效地检测生物生长情况,保护生物多样性。分析一个地区的生物种类分布情况,对于濒危物种的种群规模进行定期监测,并且分析研究生态环境的变化对于物种分布的影响,这对植物识别的准确性提出了很高的要求。植物种类识别研究不仅是植物学以及生态学的研究重点,而且对于农业生产有指导作用[83]。表示学习运用卷积神经网络[54]、概率神经网络[84]、稀疏表示字典[38]等模型完成了多达上万种的植物图像分类与识别任务(表2),在测试数据库和公开植物数据库中都获得了较高的准确率。但由于这一类细粒度图像任务处理时间较长,仍然需要在实时性方面加以改进,以构建适用于多种实际农业环境且具有鲁棒性的植物分类系统。
2.2.2病虫害检测分析
植物病虫害自动识别技术可以及时发现作物病害,帮助经验不足的研究人员以及农民完成植物病害的识别和检验。但是自动识别技术面临的主要困难如下:首先,图像背景复杂,图像可能受到其他物体的干扰,比如秸秆、昆虫等。其次,患病部位和健康部位的特征区分不够明显,难以获取显著性差异的特征[91]。同时,同一疾病在不同的阶段也具有不同的特征,对于特征获取技术提出了更高的要求。

表2 植物识别系统Tab.2 Plant recognition systems
近年来,基于表示学习的方法已在植物病理学中得到了广泛使用。
MOHANTY等[55]采用PlantVillage数据库中14个作物品种以及26种病虫害图像数据作为训练集,使用经典网络模型AlexNet和GoogleNet[92]对植物叶片图像进行“作物-病虫害”类别的分析。BRAHIMI等[93]同样使用AlexNet和GoogleNet[92], 实现了对包含9种疾病的番茄叶片图像数据集的分类。
除此之外,AMARA等[94]使用LeNet[92]模型在真实的田地等较为复杂条件(如复杂照明、杂乱背景、不同图像采集器、大小和方位等)下,实现了对于叶斑病、条纹病的两种香蕉病害以及健康状态的分类任务。
与经典的机器学习方法相比,采用表示学习方法来识别植物病虫害可以大幅度提升结果的准确率,TOO等[95]采用PlantVillage中的14种植物和38类病虫害作为数据集,使用VGG-16[96]、Inception V4[96]、DenseNets-121和ResNet-50[97]等多种经典网络进行了小幅度的微调和测试。实验结果显示,随着迭代轮数的不断提高,DenseNets的精度也较高,达到了99.75%,并且没有发生过拟合的状况。LI等[98]采集了包含3种水稻病虫害的5 320幅图像以及5段视频作为数据集,使用Fast-RCNN作为框架,使用图像来对相对模糊的视频进行训练,从而使得训练得到的模型能够准确检测视频中的病虫害类别。
除了直接使用经典网络模型,研究人员也改进了经典网络或尝试构建浅层网络来处理这类任务。LIU等[99]使用包含苹果病叶的13 689幅图像作为数据集,使用了微调的AlexNet和GoogleNet网络模型进行训练,该模型前端由AlexNet的前5个卷积层改造而成,卷积核较小,解决了病斑面积相对较小的问题。相比经典的AlexNet,该网络参数较少,收敛速度很快,准确率较高。在对感病叶片图像分类取得较好效果的基础上,还有一些研究解决了病斑定位和感染程度判断的问题。FUENTES等[100]使用韩国农场番茄植物中几种病虫害的图像作为数据集,提出了一种用于识别番茄病虫害种类和定位感染部位的系统,将VGG[96]和ResNet[97]相结合,解决了图像环境复杂导致的图像特征提取困难问题,可以解决复杂的任务,例如判断感染的状态以及定位感染的位置。
WANG等[5]采用苹果黑腹病不同感染程度的图像作为数据集,提出了使用VGG-16[96]来针对苹果黑腹病感染程度进行分类的模型。RAMCHARAN等[101]使用薯叶片表面病虫害症状图像和视频作为数据集,训练MobileNet-SSD物体检测模型用于识别木薯叶片表面病虫害症状。PICON等[102]采用3种欧洲地方性小麦疾病的图像作为训练集,使用深度残差网络ResNet-50[97]实现了自然条件下的多种病虫害的自动识别。
研究人员对于VGG-16[96]、ResNet-50[97]、AlexNet和GoogleNet[92]等多种神经网络进行微调以及改进,数据集也从公开的病虫害数据集扩展到了真实场景和复杂条件下采集的多种分辨率植物图像[100],完成的任务也不仅包括病虫害图像分类与检测等,也包含了感染程度判断及感染部位定位等更加困难的任务,但是植物病虫害方面的公开数据集较少,深度学习模型仍然需要更大规模的相关数据集进行训练。
2.2.3产量预测
产量预测对于育种者十分重要,对于作物产量和品质的准确预测和分析能够增进对作物的研究和认识,表示学习不仅能够应用于番茄[103]、小麦[104]、玉米[105]、大豆[106]、水果[107]的产量预测(表3),而且能够根据遥感图像进行数据分析,从而对全县乃至全州[106]的作物产量进行预测。
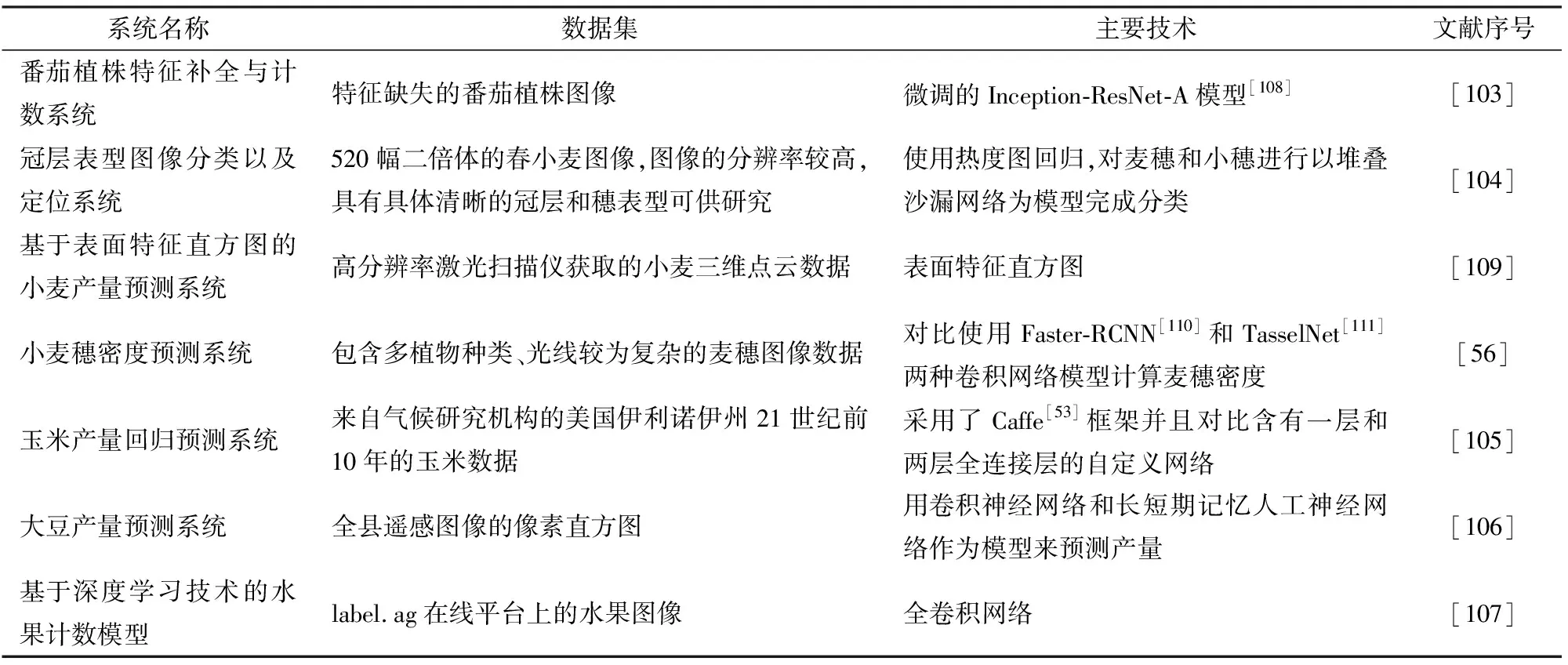
表3 产量预测方法Tab.3 Yield prediction methods
综上,研究者使用堆叠沙漏网络以及表面特征直方图等模型来提取图像特征,使用Faster-RCNN等网络模型对作物的产量预测方法进行研究,通过对比不同的训练集以及测试集来调整模型以及进行准确度的测试,在单植株图像层面上完成了小麦穗和小穗的定位和计数任务,在多植株层面上完成了对于县级乃至国家级的玉米以及大豆产量的预测任务。但是由于公开数据集的缺乏,对于水稻等的重要粮食作物产量预测研究较少。
2.2.4基因研究
表示学习,包括深度学习模型等技术已经被广泛应用到了生物医学领域,而对植物基因的认识是农业研究的重要组成部分,基因研究的突破有利于增强植物的抗病性,提高植物产量。安高乐[112]采用GENCODE以及LNCipedia中的lncRNA以及编码蛋白的转录本为数据集,使用双向动态循环神经网络模型完成了lncRNA的识别任务,研究者将一维的碱基序列转化为二维的向量来作为双向动态循环神经网络的输入,在测试集中获得了98%的正确率。
MONTESINOS-LóPEZ等[113]分析了多特征深度学习模型(Multi-trait deep learning)在提高预测基因组选择的作用。结果显示,与贝叶斯多特征和多环境模型相比,MTDL模型对于在预测基因组需要较少的计算资源,并且能够同时预测基因组的多个响应变量。卷积神经网络能够有效地表示基因序列的内部原理以及特征,并且这种表示学习模型可以应用到真实的植物基因序列[114]。但表示学习和植物基因的交叉研究刚开始,还需要基因组学领域的相关突破。
2.2.5形态结构表型数据计算
植物的形态结构表型数据的获取计算是植物表型研究的重要部分,随着表示学习的研究深入,研究者从植物的组织、器官、植株以及群体等不同尺度,利用表示学习完成形态结构参数测量、二维图像特征获取以及三维模型构建等任务,减少了人工测量形态结构表型数据的工作量。
MALAMBO等[57]采集了由无人机获取的288株玉米以及460株高粱的三维点云数据,使用运动中恢复结构算法来获取田地间作物的精确高度。吴文华[115]选取了3种油菜品种在苗期和抽薹期的叶片图像作为数据集,使用基于点分布模型的主动形状模型算法对破损的油菜花叶片进行复原以及叶片面积计算,在破损面积占总面积的1%~10%之间时,算法求得的油菜叶片重叠度为0.923。
俞双恩等[116]采用Logistic方程和DMOR模型,对于不同灌排模式和施氮水平下水稻株高和茎蘖的动态变化过程进行模型定量分析,获得的模拟值和实测值标准化均方根误差均小于10%,验证该模型能够分析不同环境下的水稻株高和茎蘖的植物表型数据。
黄成龙等[117]首先使用直通滤波、超体聚类以及条件欧氏距离算法对40株棉花幼苗点云数据进行叶片的识别分割,随后通过对分割后的叶片点云完成了三角面片化、随机采样一致性和Lab颜色分割的一系列处理,获取的叶片面积和周长的平均绝对误差为2.59%和2.85%,准确快速地获取了叶片面积周长、黄叶占比等参数。
王琦[118]使用高光谱成像获得的732幅秋葵植株图像作为数据集,采用基于策略搜索的注意力机制的级联式实例分割算法完成秋葵植株的快速分割,随后根据植株干质量与分割像素数的散点图,得到像素数和干质量的相关系数达到0.774,从而表明利用语义分割技术可以实现秋葵冠层面积数据的快速估测。
张慧春等[119]使用运动中恢复结构算法将光学相机采集的二维图像转化为三维点云数据,设计了一种基于彩色标版坐标系标准化方法来提取点云特征,生成用于测量植物形态结构的标准化坐标系,对叶片宽度、长度、主茎长度等数据进行了计算,相比人工测量效率高且速度快。
BAWEJA等[120]提出了StalkNet模型,该模型使用Faster R-CNN进行植物秸秆计数。StalkNet将物体检测结果输入到全连接网络,输出结果为植物秸秆的像素宽度,随后通过立体视觉匹配算法能够将像素宽度转换成植物秸秆的实际茎宽,茎数和宽度计算方法如图5所示。使用OpenCV将三维图像经过输入训练从而生成视差图。该模型能够准确将采集检测到的对象区域以及密集语义进行分割,该方法比人工测量速度快30倍。
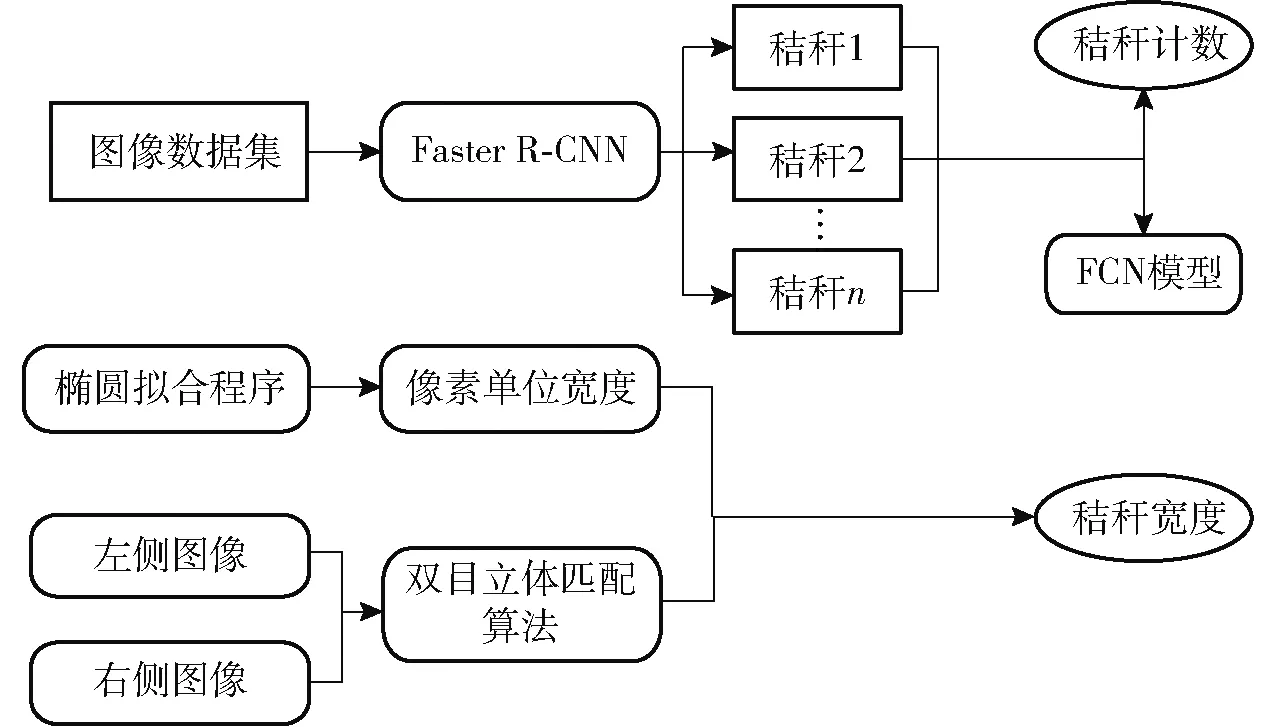
图5 茎数和宽度计算方法Fig.5 Calculation method of stem number and width
除了对数据集中的植物表型数据进行特征提取,YASRAB等[121]使用改进的编码器-解码器神经网络模型,在3 630幅小麦幼苗图像、277幅拟南芥图像、120幅油菜图像数据集上分别计算了根的长度、弯曲度等参数,获得了高准确度。
表示学习相关模型为植物表型数据分析提供了框架,使用要素组合来提取高层特征,从而基于二维图像、三维点云等数据通过主动形状模型算法对破损植株进行复原和修补,完成叶长叶宽、面积周长、倾角、卷曲度等形态表型数据的计算,减少了测量表型数据的工作量。但同时由于单种植物的表型数据量较少,形态结构表型数据计算的准确率仍有提高的空间。
3 总结与展望
表示学习技术在植物表型研究领域得到了成功应用,从底层特征的提取到特征的训练和输出,以深度神经网络、稀疏表示字典为代表的表示学习模型相比传统植物表型研究方法拥有更优的性能,能够完成植株分割、分类、计数等表型数据的分析任务。表示学习在植物表型应用中的发展方向为:
(1)开发能够适用于分析不同种植物表型数据的表示学习模型,实现高整合度、高通用性的目标。近年来,分析植物表型数据的表示学习模型要求训练集和测试集均来自于同一特征空间,而大部分的表型分析系统只能针对某种植物的某一表型性状进行分析和研究,测试不同种植物表型数据时都需要重新训练模型,对于数据集的要求很高。开发分析不同种植物表型数据的表示学习模型可以更好地满足快速和高通量的研究需求,从而增强表示学习模型在植物研究领域中的应用。
(2)提高表示学习模型的实时性及准确度,以增强其实用性。表示学习模型的特征提取和训练流程需要较长的时间,在实时性方面难以满足实际农业环境下的运用需求。此外,研究者使用的测试集和训练集大多来自公开数据集,其实用性需要在实际环境中进行验证。
(3)表示学习在植物表型中的研究和应用需要跨学科的团队共同合作,多模态的表示学习将对多源表型数据构建统一的数据表示,为学科的交叉数据分析研究提供统一的数据视图。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
中国现代医生(2022年21期)2022-08-22
大数据(2021年6期)2021-11-22
锻压装备与制造技术(2021年5期)2021-11-13
电脑爱好者(2021年8期)2021-04-21
科学技术创新(2021年5期)2021-03-17
天津医科大学学报(2021年1期)2021-01-26
医药前沿(2020年20期)2020-11-10
电脑爱好者(2020年20期)2020-10-22
——编码器
演艺科技(2020年7期)2020-08-13
