
人工智能中数据集的分类、获取与处理
2020-07-18 16:18高宏旭曹大军
科学大众 2020年5期
高宏旭 曹大军
摘 要:文章重点探讨了人工智能中数据集的分类、获取与处理方法。从人工智能的概念、本质与要素出发,深入阐述了数据集对人工智能的重要意义,按照研究领域对数据集进行分类,以图像数据集为例讨论数据集的获取方法,对若干典型图形数据集进行分析、总结,进而阐述数据集处理方法。其中,详细介绍了数据标记方法,以期为即将从事人工智能研究的人员提供方法指引与技术方案。
关键词:人工智能;数据集;分类;处理
人工智能(Artificial Intelligence,AI)是研究、开发能够模拟和扩展人类智能的理论、方法、技术及应用系统的一门全新技术科学[1]。AI的本质是对人类智能的模拟与扩展,赋予机器人类的思考能力。自20世纪50年代开始,AI依次经历了符号处理、字符号法、统计学法、集成方法等发展阶段,已经从单一智能系统模拟进入到混合智能研究阶段。AI的研究领域包括:语音识别、图像识别、自然语言处理、专家系统、仿生设备等,其理论和技术日益成熟,应用范围不断扩大。未来,AI带来的科技产品将会是人类智慧的“容器”。
从技术方案看,AI对给定数据集进行训练,形成研究对象的模型输出。算法、算力、数据是AI的三大要素[2]。(1)算法是核心,是指导数据进行学习训练并形成模型输出的方法,本质是程序化的机器学习方法,可分为监督式学习算法和非监督式学习算法;目前,很多学习算法已经开源,训练其中的关键参数即可获得研究对象的AI学习算法。(2)算力为动力,包含GPU在内的各种高速计算机、服务器等设备,或者某些通用大数据平台,成为AI算力的首选。(3)数据是燃料,其数量和质量直接影响AI算法的最终训练结果。只有有针对性地选择适合相关研究领域的数据,形成有效的训练数据集合,才能达到理想的训练结果。
数据集对人工智能的实现具有重要意义,为人工智能学习算法训练提供数据采集、标注等服务,已经成为近年来人工智能研究的热点之一。本文着重介绍人工智能中数据集的分类、获取与处理方法,为工程应用提供技术指导。
1 数据集的分类与获取
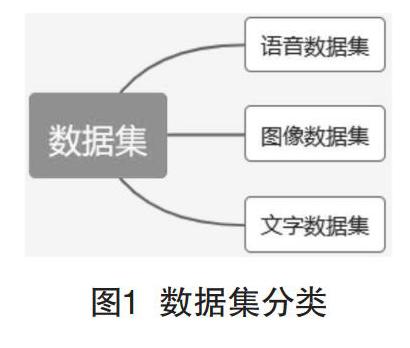
根据研究领域的不同,AI涉及的数据集(见图1)大致可以分为3类:语音数据集、图像数据集、文字数据集[3]。其中,面向智能语音处理领域的数据集合统称为语音数据集,面向图像识别领域的数据集合统称为图像数据集,面向文字识别等领域所选择的为文字数据集。
在实际研究中,对于某类数据集可以依据研究场景进行细化分解。例如,图像数据集可以细分为场景数据集、行人检测数据集、人脸图像数据集、交通工具数据集等[4]。图像数据集可以自行通过传感设备采集相关信息后构建,或者通过网络搜索工具下载后构建,亦可以从已建立的各类数据库获取部分信息后构建且更为便利。下面介绍几种常见的图像数据集。
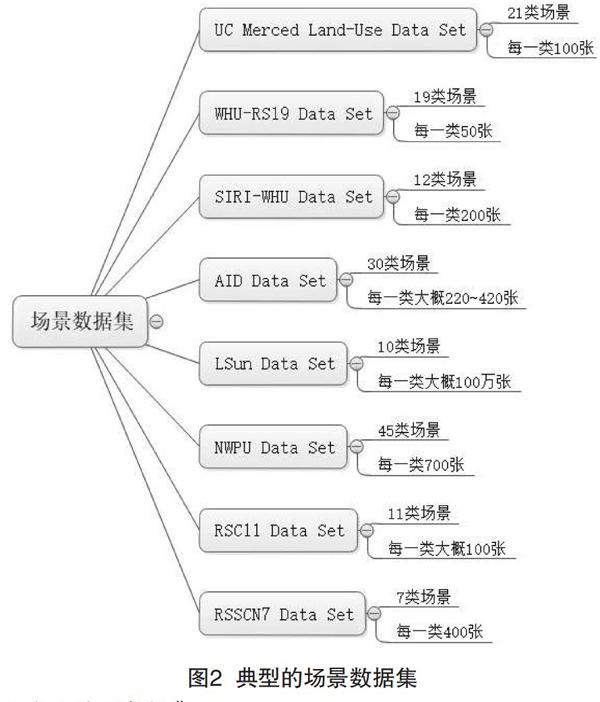
1.1 场景数据集
(1)比较出色的场景数据集是LSUN Dataset,由加州大学伯克利分校于2015年发布,提供10个场景类别和20个类别,共计约100万张标记图像,以闪电式内存映射数据库(Lightning Memory-Mapped Database,LMDB)格式存储,涵盖家居、教室、会议室等多种场景。
(2)比较优秀的场景数据集是UC Merced Land-Use Dataset,由UC Merced计算机视觉实验室于2010年发布。UC Merced Land-Use Dataset包含21类场景,每一类场景含100张图像数据。
此外,WHU-RS19 Dataset提供19类场景的图像数据信息,每一类约含50张图像;SIRI-WHU Dataset包含12类场景,每一类场景含200张图像;RSC11 Dataset包含11类场景,每一类场景含100张图像;AID Dataset包含30类场景,每一类场景包含220~420张图像数据。不同场景数据集提供的图像资源比较如图2所示。
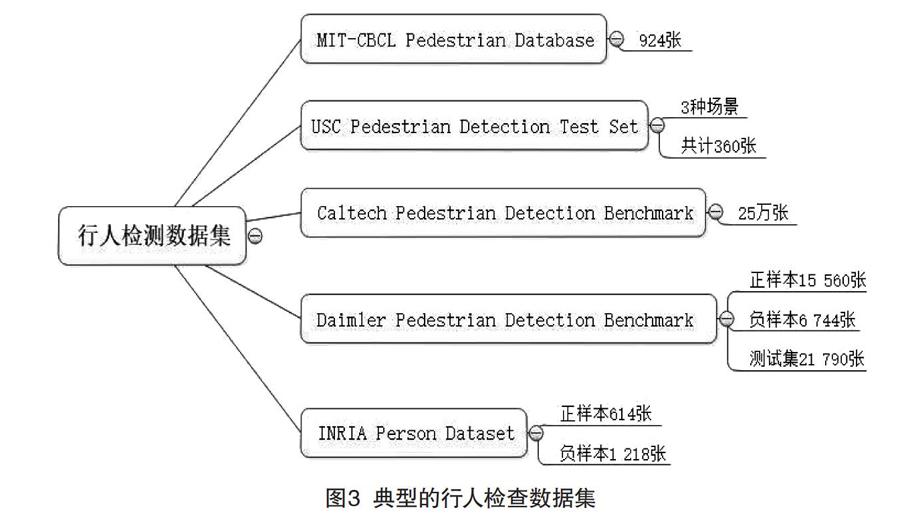
1.2 行人检测数据集
行人检测数据集比较典型的有:加州理工学院(California Institute of Technology)的Caltech行人数据库、麻省理工学院(Massachusetts Institute of Technology)的MIT行人数据库、南加利福尼亚大学(University of Southern California)的USC行人数据库、戴姆勒行人检测标准数据库、INRIA行人数据库[4-5]等,其中包含的行人数据集情况如图3所示。
(1)Caltech行人数据库,是目前规模较大的行人数据库,采用车载摄像头拍摄,以30帧/秒的速度记录了约10 h左右的行人视频,图像分辨率为640×480。其中,对137 min视频约250 000帧图像进行了标注,使用了350 000个矩形框,标注了2 300个行人。
(2)MIT行人数据库:包含924张行人图片,所有拍摄图片只含正面和背面两个视角,每张图片中行人肩到脚的距离约80像素,图片分辨率为64*128;无负样本,未区分训练集和测试集。
(3)USC行人数据库:包含根据拍摄角度和行人重疊与否划分的3组数据集,分别命名为USC-A,USC-B和USC-C。其中,USC-A包含来自网络的205张图片,记录了313个正面或背面视角拍摄的站立行人,行人间相互无遮挡;USC-B包含来自CAVIAR视频库的54张图片,记录了271个多角度行人,行人间存在相互遮挡;USC-C包含来自网络的100张图片,记录了232个多角度行人,行人间相互无遮挡。该数据库采用可扩展标记语言(eXtensible Markup Language,XML)存储图片标注信息。
(4)INRIA行人数据库,是目前应用最广泛的一类静态行人数据库,分为训练集、测试集两部分。其中,训练集包含正样本614张,记录了2 416个站立行人,负样本1 218张;测试集包含正样本288张,记录了1 126个站立行人,负样本453张。图片主要来源于网络,可用OpenCV读取和显示。
1.3 人脸数据集
比较典型的有哥伦比亚大学公众人物脸部数据库、香港中文大学的大型人脸识别数据集、Multi-Task Facial Landmark (MTFL) Dataset,BioID Face Database - FaceDB,Labeled Faces in the Wild Home (LFW) Dataset等[6],如图4所示。其中,MTFL Dataset从互联网上收集了12 995张人脸照片;BioID Face Database-FaceDB包含1 521张人脸灰度照片;LFW Dataset包含超过13 000张多角度人脸图像。3种数据集的基础数据均来源于网络。
为促进人脸识别算法的研究和实用化,美国国防部发起一项人脸识别技术(Face Recognition Technology,FERET)项目,通过采集1 000多位不同年龄志愿者的不同表情、光照、姿态的照片,构建了包含10 000多张面部图像照片的通用人脸数据库,并开发了通用的人脸识别测试标准,以提升人脸识别的精度。
2 数据集的处理方法
AI数据处理又称为AI基础数据服务,包括:数据采集、数据清洗、信息抽取、数据标注。数据采集即获取数据集;数据清洗(Data Cleaning,DC)是指对数据重新审查和校验的过程,包括检查数据一致性、处理无效值和缺失值等[7];信息抽取(Information Extraction,IE)是从数据集中提取有用信息并按照一定结构形成规范化表征的过程,例如变为信息表格;数据标注(Data Annotation,DA)是借助标记工具对数据集中的某些数据进行标记处理的一种行为,包括图像标注、语音标注、文本标注、视频标注等种类,标记的基本形式有标注画框、3D画框、文本转录、图像打点、目标物体轮廓线等。数据标注是影响算法训练的重要环节,成为近年来AI研究的热点之一。目前,对数据集中数据进行标注处理的方法有两种:
(1)通过网络购买标注服务,由第三方平台按要求进行数据标注;
(2)自行采用标注工具对数据集进行处理,打上合适的标签。
目前,比较常用的图形图像标注工具为LabelImg[8]。该工具为Python语言编写,在github相关网站下可以找到该工具https://github.com/tzutalin/labelImg,其产生的注释以PASCAL VOC格式存储的XML文件,被ImageNet数据集采用;LabelImg亦支持YOLO格式存储。
另一种图形图像标注工具Vatic(Video Annotation Tool from Irvine,California)源自MIT的一个研究项目,支持输入视频自动抽取成粒度合适的标注任务,并在流程上支持接入亚马逊的众包平台Mechanical Turk。Vatic具有很多实用特性:第一,简洁的GUI界面,支持多种快捷键操作;第二,基于Opencv的Tracking进行抽样标注,减少工作量。具体使用时,设定要标注的物体名称,比如:人脸、行人、车等,然后指派任务给众包平台。
Yolo_mark工具对图像标注,主要应用于使用YOLO V3或V2的算法。此外,还有微软发布的VOTT图像标注工具等。
3 结语
本文主要讨论了AI的数据集分类、获取及处理方法。随着人工智能的深入发展,算法及算力已不是制约人工智能發展的主要因素,数据集的收集、处理同样重要,为了快速促进训练模型的形成,研究者可以考虑使用开源的数据集或者对数据进行自我采集,并通过图像标注工具,将采集的数据转换为合格的数据集,便于后续工作的进一步开展。
[参考文献]
[1]周芃池.人工智能在生物医疗中的发展应用及前景思考[J].低碳世界,2018(2):320-321.
[2]上海艾瑞市场咨询有限公司.中国人工智能基础数据服务行业白皮书(2019年)[R].上海:上海艾瑞市场咨询有限公司,2019:268-310.
[3]周旺,张晨麟,吴建鑫.一种基于Hartigan-Wong和Lloyd的定性平衡聚类算法[J].山东大学学报(工学版),2016(5):37-44.
[4]屈鉴铭.智能视频监控中的运动目标检测与跟踪技术研究[D].西安:西安电子科技大学,2015.
[5]张金慧.基于多尺度方法的行人检测与跟踪算法研究[D].成都:西南科技大学,2018.
[6]张翠平,苏光大.人脸识别技术综述[J].中国图象图形学报(A辑),2000(11):885-894.
[7]陈畇燚.校园网络行为与流量预测分析研究[D].长沙:湖南大学,2014.
[8]顾广华,韩晰瑛,陈春霞,等.图像场景语义分类研究进展综述[J].系统工程与电子技术,2016(4):936-948.
作者简介:高宏旭(1979— ),吉林兆南人,工程师;研究方向:人工智能,系统架构设计。
猜你喜欢
商界(2019年12期)2019-01-03
IT经理世界(2018年20期)2018-10-24
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
小康(2017年16期)2017-06-07
科学与财富(2016年28期)2016-10-14
南风窗(2016年19期)2016-09-21
少儿科学周刊·少年版(2015年3期)2015-07-07
