
基于BERT和TextRank关键词提取的实体链接方法
2020-07-23 13:52朱艳辉梁文桐冀相冰
湖南工业大学学报 2020年4期
詹 飞,朱艳辉,梁文桐,冀相冰
(1.湖南工业大学 计算机学院,湖南 株洲 412007;2.湖南工业大学 智能信息感知及处理技术湖南省重点实验室,湖南 株洲 412007)
1 研究背景
近年来,大规模中文通用知识图谱的发展给国内人工智能领域的发展带来了新的机遇。实体链接作为命名实体识别任务的后续任务,是知识图谱构建和补全过程中的关键一环。实体链接任务的目标是将文本中识别的实体指称和该实体指称在给定知识库中对应的实体相关联,通常可以将实体链接分解为两个串行的子任务:候选实体生成和候选实体排序。候选实体生成阶段为当前实体指称过滤掉知识库中的大部分不相关实体,得到候选实体集。候选实体集中通常包含多于一个候选实体,在候选实体排序阶段对候选实体集中的实体和当前实体指称进行相似度打分并排序,得分最高的实体即为当前实体指称的目标链接实体。实体链接任务的关键挑战即为如何有效利用实体指称和候选实体的相关信息来对二者进行相似度打分。
现有实体链接工作的重点集中在候选实体排序阶段。随着深度学习的发展,深度学习技术被广泛地应用到自然语言处理领域的多项任务中,并取得了很好的效果。针对实体链接任务,He Z.Y.等[1]提出一种基于深度神经网络(deep neural networks,DNN)的方法来进行实体链接,通过深度神经网络自主学习实体和上下文的特征表示,端到端地进行实体链接,避免了人工设计特征,当时在两个公开实体链接数据集上取得了最先进的性能。M.Francis-Landau 等[2]使用卷积神经网络(convolutional neural networks,CNN)来捕获实体指称上下文和目标实体上下文的语义信息,并利用多个粒度的卷积来比较两者之间的语义相似度。T.H.Nguyen 等[3]提出结合循环神经网络和卷积神经网络的联合模型来同时获取实体指称上下文局部特征和全局主题特征,用卷积神经网络获取局部相似性,用循环神经网络获取全局一致性,该模型在多个数据集上被证明是有效的。Liu C.等[4]提出一种新型的注意力机制来获取给定实体指称周围重要的文本,并且结合一种前向-后向算法获取文本主题信息来提高实体链接的准确率。Hu S.Z.等[5]提出具有双重注意力机制的对称Bi-LSTM(bidirectional long short-term memory)模型,该模型能有效利用结构信息和注意力机制更全面地提取实体特征,并结合上下文特征和结构特征作为实体的特征表示。
预训练语言模型出现之前,使用深度学习方法解决自然语言处理问题的研究思路,大多是针对特定的目标任务来设计对应的模型。BERT(bidirectional encoder representations from transformers)出现之前,已经有了一些专家学者对预训练语言模型进行了相关研究工作,如ULMFiT(universal language model fine-tuning)[6]和OpenAI GPT[7]模型,但由于单向语言模型的限制,它们不能对上下文语义信息进行充分利用。J.Devlin 等[8]对现有预训练语言模型[7]进行改进,提出新的预训练语言模型BERT,目前,该模型在许多下游任务上取得了较优效果。本研究将BERT 引入实体链接任务中,将预训练的BERT 语言模型作为实体链接模型的一部分。
关键词能够反映出文本主题信息,强化文本相似度比较的效果。将关键词提取技术加入到实体链接过程中,辅助进行实体指称和候选实体相关信息的相似度比较,能够增强文本相似度度量的准确性,从而优化模型效果。TextRank关键词提取算法将关键词提取问题转化到图模型中进行处理,能够考虑到相邻词的语义关系,提取出的关键词能够更好地反映文本的主题信息。因此,本文将TextRank关键词提取算法融合到实体链接过程中。
基于BERT模型的实体链接方法在NLP(natural language processing)任务上的优秀表现和关键词提取对文本相似度比较的强化效果,本文提出一种基于BERT和TextRank关键词提取的实体链接模型。该模型的特点是将BERT预训练语言模型引入实体链接任务,通过BERT 来获取句子的向量表示,从而进行实体指称和候选实体相关信息的关联度分析。同时,使用TextRank关键词提取技术来获得目标实体描述文本的关键词,作为目标实体综合描述的一部分,输入到BERT中,这能够增强目标实体综合描述的主题信息,从而优化模型的效果。
2 BERT-TextRank模型
本研究提出基于BERT和TextRank关键词提取的深度神经网络模型进行实体链接,模型整体结构如图1所示,主要包括TextRank关键词提取部分、BERT层和输出层。
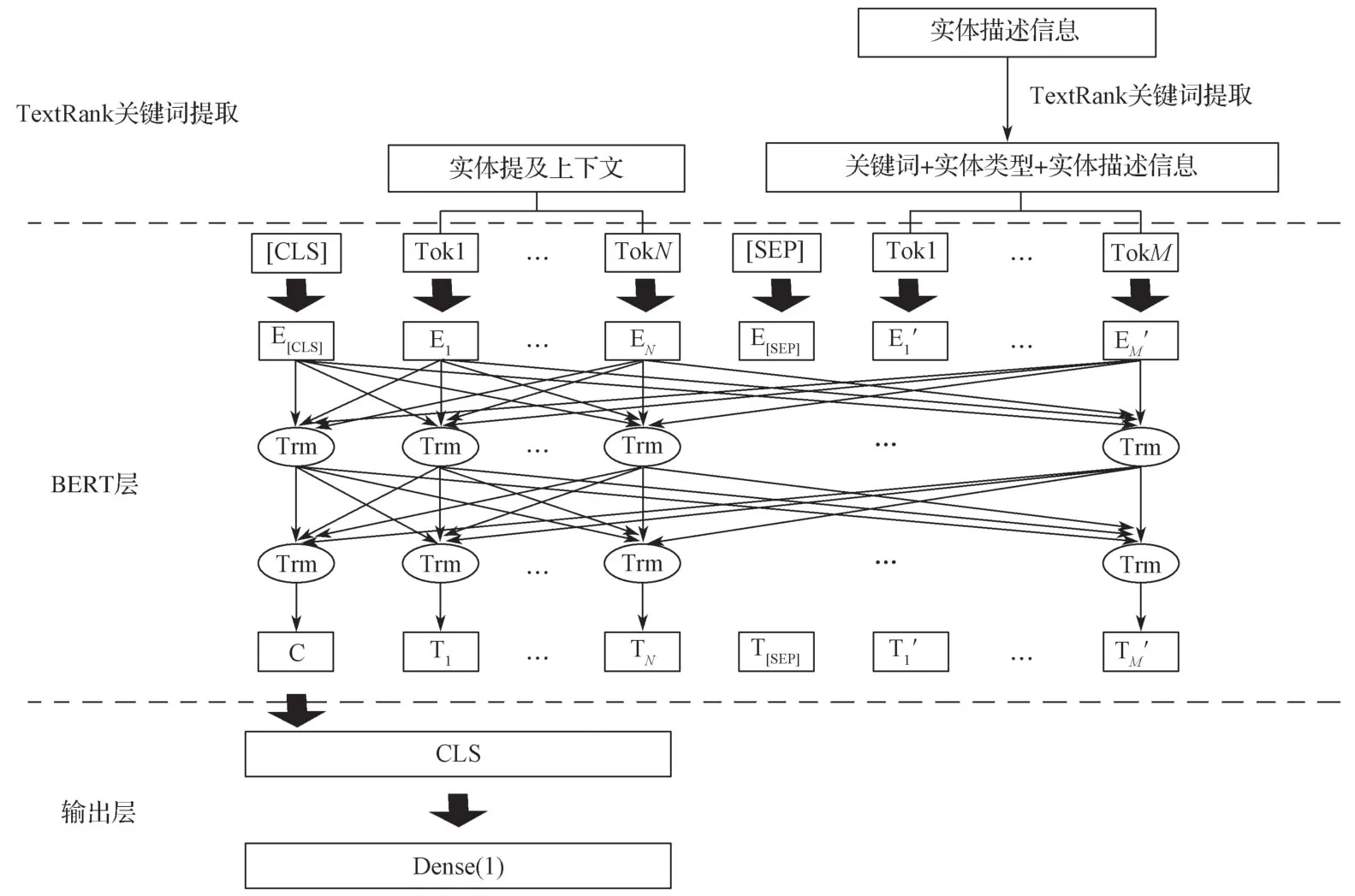
图1 基于BERT和TextRank关键词提取的实体链接网络模型Fig.1 Entity linking model based on BERT and TextRank keyword extraction
将实体指称上下文和候选目标实体的综合描述用[SEP]分隔符隔开作为BERT的输入,实体指称上下文为当前实体指称所在的句子,候选目标实体的综合描述由关键词、实体类型和实体描述信息组成。关键词由实体描述信息通过TextRank关键词提取得到,实体类型和实体描述信息从目标知识库中获取。然后取BERT输出中CLS位置对应的向量作为下一个全连接层的输入,使用sigmoid函数进行激活,把文本语义相似性问题抽象为二分类问题。
2.1 BERT预训练语言模型
BERT模型结构如图2所示。
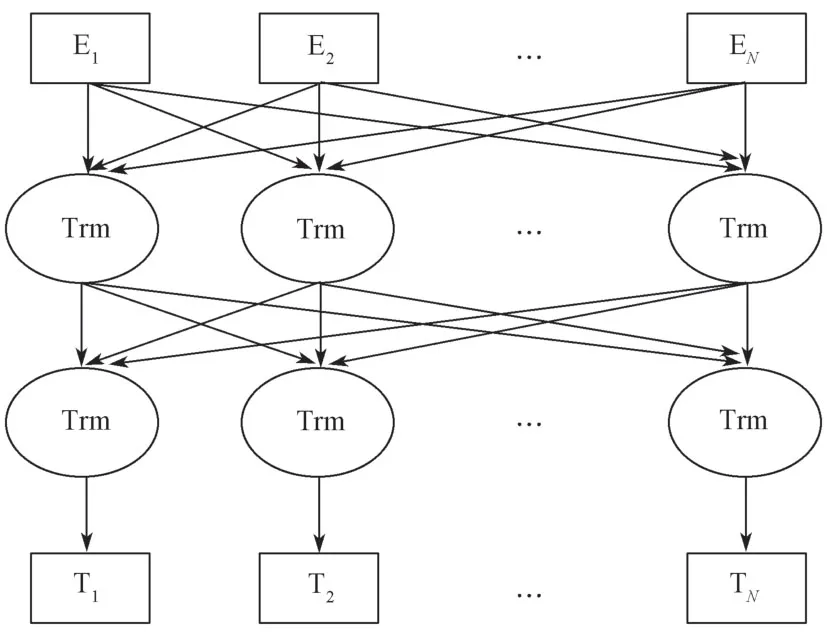
图2 BERT模型结构图Fig.2 BERT model structure illustration
图2所示模型借鉴了A.Vaswani 等[9]提出的“多层双向Transformer 编码器”思想,以双向Transformer的Encoder 作为模型的基本组成单元。
BERT模型虽然和之前的预训练语言模型OpenAI GPT 一样都使用了Transformer,但不同的是OpenAI GPT模型使用的是单向的注意力机制,BERT模型则针对这一不足进行了改进,使用双向Transformer的Encoder 作为基本组成单元,BERT的这种结构能够联合所有层中的左右两个方向的上下文信息进行训练。
BERT模型使用的Transformer 基于多头注意力机制(multi-head attention)。多头注意力机制的结构如图3所示。
由图3的结构形式可知,多头注意力机制可以帮助模型捕获更多层面的语义特征,将各个注意力头单独进行计算,然后将其结果进行拼接,得到最终结果。
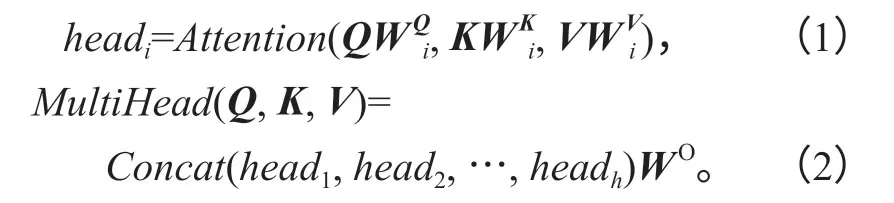
式(1)~(2)中:Q,K,V为输入量;
W为变换参数。
对多头注意力的输入量Q,K,V分别进行线性变换,每次线性变换的参数W取值不同,分别为WiQ,WiK和WiV,线性变换得到的结果输入Scaled Dot-Product Attention中得到headi,重复做h次;然后将h次Scaled Dot-Product Attention 得到的结果head1,head2,…,headh进行拼接,并对拼接的结果进行线性变换,得到多头注意力的最终结果,线性变换的参数为WO。
受Y.Bengio 等[10]研究结论的启发,BERT的训练方式不同于之前的预训练语言模型,而是通过大量未标注的百科文本语料进行训练,得到预训练语言模型,然后根据具体需要,针对特定目标任务对BERT模型进行微调。新的预训练方法也是BERT表现优于之前的预训练语言模型的重要因素,它不再采用传统的单向语言模型来进行预训练,而是提出两个新任务来进行预训练,即通过MLM(masked language model)和“下一句预测”(next sentence prediction)两个新的任务分别捕捉词语和句子级别的特征。
MLM 用来克服之前的预训练语言模型的单向性所具有的局限,对于输入序列中15%的数据,随机地将这些输入序列中的一部分单词用[mask]标记进行遮盖,然后以预测这些被遮盖的单词为目标来对模型进行训练,这样能够同时在左右两个方向上融合上下文信息。通过MLM 任务的训练,模型能够同时对左右两侧的语义特征进行提取,通过联合所有层中的左右两个方向的上下文信息进行训练,得到深度双向Transformer 转换。但是用于遮蔽单词的特殊标记[mask]在实际的NLP 任务中并不存在,用从语料中随机获取的词和预测位置的原词按照一定比例对需要[mask]遮蔽的词进行替换,从而可以保证训练过程和实际任务保持一致。用特殊标记“[mask]”来替换80%的目标单词,用从语料中随机获取的一个词来替换10%的目标单词,剩余10%的目标单词不进行任何操作。
对于“下一句预测”任务捕捉词语和句子级别的特征,是为了让模型能够更好地捕捉句子级别的语义特征。每条训练数据为连续的两个句子M和N,概率为50%的句子N是原文中的正确句子,概率为50%的句子N会被替换为语料中的一条随机语句来作为负样本进行训练,然后再做二分类来判断输入的句子N是正确的还是随机产生的。
2.2 TextRank关键词提取
使用TextRank 算法进行关键词提取的思路是将关键词提取问题转化到图模型中进行处理,这样能够考虑到相邻词的语义关系。使用TextRank 算法提取得到的关键词能够增强句子的主题信息,从而优化文本相似度度量的效果。
TextRank 算法是以PageRank 算法为蓝本,针对自然语言处理的特点进行修改而形成的。使用TextRank 算法进行关键词提取的思路是将关键词提取问题转化到图模型中进行处理,这样能够考虑到相邻词语的语义关系。并根据各个词之间的相互联系判断其对于文本整体重要性的高低,得到各个词的重要性得分,然后根据其得分从高到低进行排序,设定阈值H,重要性得分较高的H个词即可视为提取出来的文本关键词。将文本看成是句子集合T={S1,S2,…,Sn},其中的每个句子Si∈T,又可以看作词的集合Si={N1,N2,…,Nm},构建图模型G=(V,E),其中V=S1∪S2∪…∪Sn,当两个词共同出现在一个句子中时,对应的节点有边,否则无边。词的重要性得分计算方法如下:

式中:In(Ni)是指向节点i的节点集合;
Out(Nj)是节点j指向的节点组成的集合;
d为阻尼系数;根据实际情况对阻尼系数进行赋值,通常取0.85。
在使用TextRank 进行关键词提取时,以词为节点,以共现关系建立节点之间的链接来进行图模型的构建。这里的图模型与PageRank模型不同的是,PageRank 构建的是有向图,而TextRank 构建的图是无向图。首先对图中的每个节点指定任意初始值,然后进行迭代训练直至收敛,这样就能够计算出各节点的最终权重。
3 实验与结果分析
3.1 实验数据
本研究采用CCKS2019(2019 全国知识图谱与语义计算大会)任务二提供的训练语料和知识库[11-12]。训练语料中每条数据包含一条文本和该文本中包含的实体指称,以及各个实体指称在给定知识库中对应的目标实体。知识库中包含每个实体的别名、实体类别和实体描述信息。本研究仅评价数据集中的非“NIL”型实体指称,即在目标知识库中存在链接实体的实体指称。
训练语料由训练集和验证集组成,其中训练集包括9万条短文本标注数据,验证集包括1万条短文本标注数据,数据通过百度众包标注生成。标注数据集主要来自于真实的互联网网页标题数据,这些标题数据来源于用户检索Query 对应的有展现及点击的网页,短文本平均长度为21.73个中文字符,覆盖了不同领域的实体,如人物、电影、电视、小说、软件、组织机构、事件等。
3.2 评价指标
实体链接评价指标选用精确率P、召回率R、F值(F-score),具体说明如下:
给定输入文本集Q,对于Q中每条输入文本q,此输入q中有N个实体指称即,Mq={m1,m2,m3,…},每个实体指称链接到知识库的实体编号为Eq={e1,e2,e3,…},实体链接系统输出的链接结果为Eq′={e1′,e2′,e3′,…},则实体链接的准确率P,召回率R和F值定义如下:

3.3 实验环境
本研究中的软硬件实验环境如下:操作系统为Ubuntu16.04,GPU 显 卡为NVIDIA RTX 2080Ti(11 GB),python版本为3.6,tensorflow版本为1.12.0,内存为16 GB,硬盘容量为1 TB。
3.4 参数设置
本研究所使用的BERT为包含12层的Transformer的BERTBASE,学习率为1e-5,最大序列长度为512,训练batch_size为4。
3.5 实验结果
为了验证本研究中所提出的基于BERT和TextRank关键词提取的实体链接方法的有效性,本研究复现了经典的句子语义建模方法,如TextRNN和TextRNN 方法,用TextRNN[13]和TextRCNN[14]进行实体链接,与本文中的BERT-TextRank模型类似,在这两个模型中都将实体链接中的文本语义相似性问题抽象为二分类问题进行处理。分别将TextRNN和TextRCNN模型与TextRank关键词提取算法相结合,然后进行对比实验。
3.5.1 关键词个数K的取值实验
分 别 使 用TextRNN-TextRank、TextRCNNTextRank和BERT-TextRank 3 组模型进行实体链接实验,TextRNN-TextRank表示将TextRNN模型和TextRank关键词提取算法进行结合,其他两个模型名称含义与其类似。K值表示TextRank 算法提取的关键词个数,以步长为1,在区间[0,6]内对参数K做取值实验,K值为0时表示不进行关键词提取。随着K值的取值变化,上述3个模型的实体链接效果如表1所示。
各模型的TextRank关键词个数K调节实验结果如图4所示。
分析对比图4a、b、c的实验结果表明,结合TextRank关键词提取算法后,3个模型的实体链接效果都有所提高,且本文提出的BERT-TextRank 方法的实验效果优于其他两个模型实验结果。TextRNNTextRank和BERT-TextRank模型在关键词个数K=3时F值达到最大,而TextRCNN-TextRank模型在关键词个数K=5时F值达到最大值。
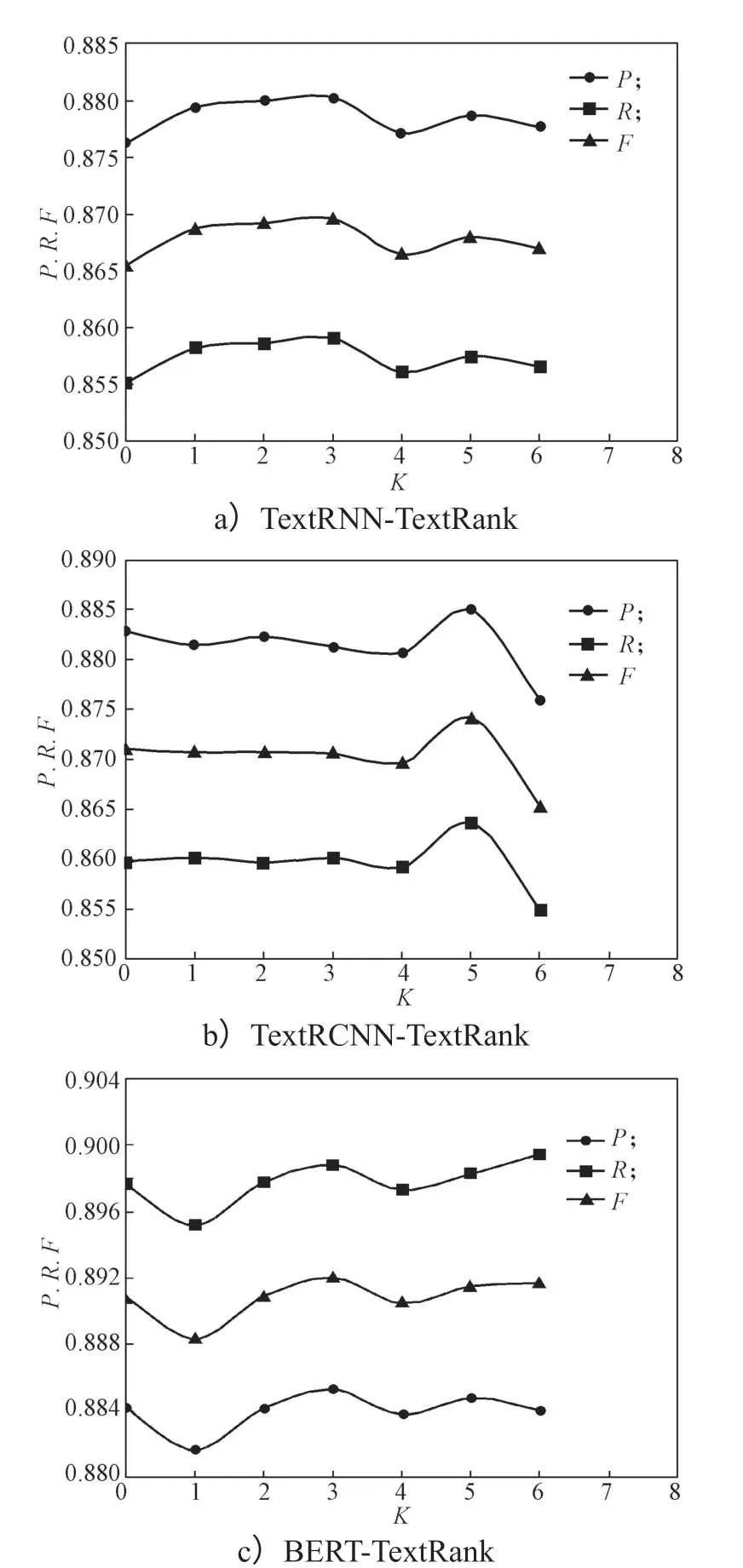
图4 关键词个数K 取值实验结果Fig.4 Experimental results corresponding with values of keyword K
当在F值达到峰值后继续增加关键词个数会导致主题信息比较分散,从而导致F值有所降低。这说明利用TextRank模型提取关键词,从而增强知识库中实体描述文本的主题信息,对于实体链接是有效的,但是不同模型对于关键词个数的敏感性不同,模型F值取得峰值时对应关键词个数K也并不完全相同。因此,接下来关键词个数K分别选取各个模型的最佳值进行对比实验,即K值分别选取3,5,3。
3.5.2 相似度阈值Y取值实验
分析实验结果发现,存在一部分实体指称在目标知识库中对应的候选实体集合不为空,但是候选实体集合中不存在正确的目标实体,即知识库中没有该实体指称对应的实体,导致错误链接。
模型的输出层为全连接层,使用sigmoid函数进行激活,把文本语义相似性问题抽象为二分类问题进行处理。将模型输出值记为y,y即为实体指称链接到当前目标实体的概率,也是实体指称上下文和当前目标实体综合描述信息的相似度得分。设定相似度阈值Y,对其定义如下:

当候选实体上下文与目标实体特征描述的相似度得分y大于阈值Y时,将实体指称链接到当前实体;当y小于阈值Y时,即认为知识库中不存在此实体指称的目标链接实体,将其链接目标标记为“NIL”。
由上述实验确定TextRNN-TextRank模型的参数K=3,TextRCNN-TextRank模型的参数K=5,BERTTextRank模型的参数K=3后,对阈值Y进行取值实验,实验区间设置为[0,0.5],以步长为0.1 进行Y取值实验,其实验结果如表2所示。
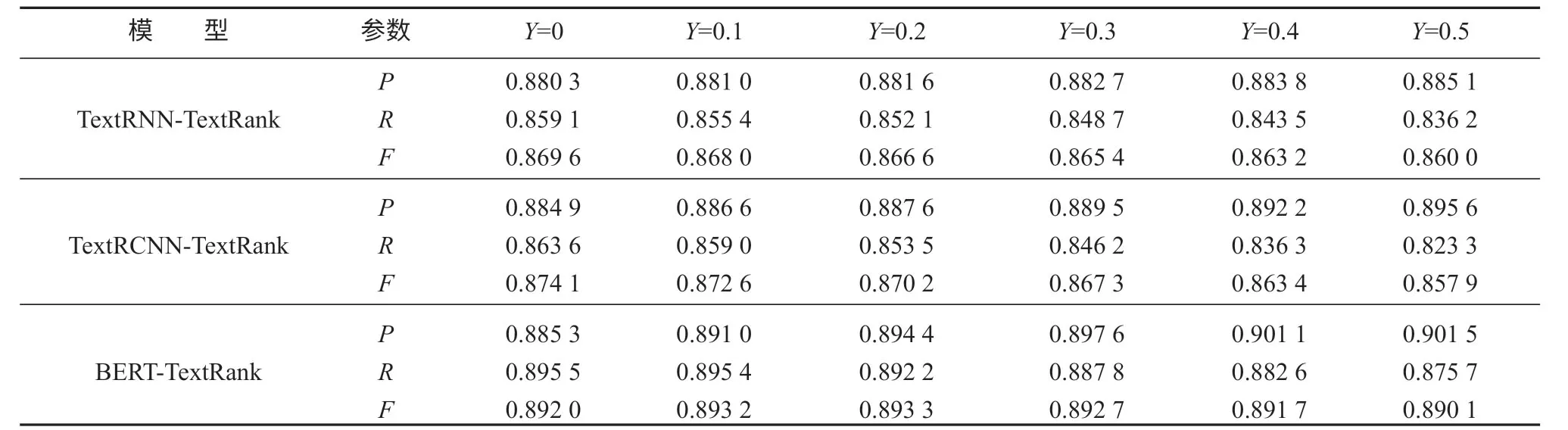
表2 阈值Y 取值实验结果Table2 Threshold Y experiments results
各模型的阈值Y调节实验结果如图5所示。
分析对比图5a、b、c的实验结果表明,3 组模型中的P值均随着Y值的增大呈上升的变化趋势,而R值均随着Y值的增大呈下降的变化趋势,但是TextRNN-TextRank模型和TextRCNN-TextRank模型的P值增加幅度不够大,导致其F值呈单调下降趋势,BERT-TextRank模型的F值随着阈值Y的增大先呈现出上升的变化趋势,在Y取0.2时其F值达到最大值,然后呈下降趋势。证明随着阈值Y的增大,正确链接应为“NIL”的实体指称被更多的识别出来,实体链接准确率提高。但是一部分正确链接为非“NIL”的实体指称因为相似度得分相对较低,在阈值Y增大的过程中被链接为“NIL”,从而导致实体链接召回率逐渐降低。在TextRNN-TextRank模型和TextRCNN-TextRank模型中,P值增大幅度相对较小,而其R值也逐渐减小,从而导致其F值呈单调下降的变化趋势。因此TextRNN-TextRank模型和TextRCNN-TextRank模型的阈值Y应选择0,即不设定阈值,但是对于本研究提出的BERT-TextRank方法,根据实验结果选定阈值Y为0.2,能够提升模型的实体链接效果。


图5 阈值Y 取值实验结果Fig.5 Experimental results of threshold Y
3.5.3 不同模型对比实验
TextRNN、TextRCNN和BERT 三种模型结合关键词提取方法和设定相似度阈值前后对比实验如表3所示。

表3 3个模型结合关键词提取和阈值控制前后的实验结果Table3 Experimental results before and after keyword extraction with three models under threshold control
对比分析表3的实验数据表明,3种模型结合TextRank关键词提取算法和选定相似度阈值Y后的F值均比结合之前有所提升,BERT-TextRank模型相比TextRNN-TextRank模型和TextRCNN-TextRank模型的P、R、F值也有较大提升,有效证明了本研究构建的基于BERT预训练语言表征模型和TextRank关键词提取的实体链接模型相比较于其他模型的有效性。
4 结语
本研究提出了一种基于BERT和TextRank关键词提取的实体链接方法。该方法可以分为TextRank关键词提取和BERT 句子相似度比较两部分。TextRank关键词提取部分用来提取知识库中实体描述文本的关键词来增强文本主题信息,强化文本相似度比较的效果。BERT 句子相似度比较部分将实体指称的上下文和候选实体的特征描述进行相似度比较,候选实体的特征描述由关键词、实体类型和实体描述文本组成,关键词即为TextRank 提取得到的结果。实验结果证明了本文所提方法的有效性,说明加入主题信息对于文本相似性的度量是有效果的。未来计划借鉴Liu Y.等[15]提出的结合词嵌入和主题模型的思想,结合主题模型和BERT模型,将文本主题信息融合到句子向量表示中来进行文本相似性度量和实体链接。
猜你喜欢
北京大学学报(自然科学版)(2022年1期)2022-02-21
建材发展导向(2021年19期)2021-12-06
临床骨科杂志(2020年1期)2020-12-12
中国外汇(2019年18期)2019-11-25
当代陕西(2019年5期)2019-03-21
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
科技视界(2014年27期)2014-08-15
科技视界(2014年25期)2014-04-27
