
基于行业实用系数的台区线损率标杆值计算方法
2020-07-27 07:37吴科成曲毅陈义森欧阳森
广东电力 2020年7期
吴科成,曲毅,陈义森,欧阳森
(1.广东电网有限责任公司,广东 广州 510600;2.华南理工大学 电力学院,广东 广州 510641)
在规划上,台区的线损受供电半径、线路线径、线路类型与参数的影响较大;在运行上,则受负荷率的影响较大[1]。随着电网企业管理理念由“粗放型”转向“精细型”,再由“精细型”转向“精益型”,电网企业对线损管理提出了更高要求[2],而台区线损率作为衡量电网经济效益的重要指标,是精益化管理的核心内容之一。
目前关于线损的研究集中在降损指标设立[2]、线损率计算[3-7]、台区评估选优[8-9]等方面。文献[2]通过六西格玛模式和戴明环从规划、运行、管理和技术4个维度建立线损管理评价体系。文献[3-4]分别采用改进的BP神经网络模型和随机森林算法对经过聚类后的台区线损率进行预测。文献[5]提出基于极限线损率指标的配电网降损优化方法。文献[6]以馈线运维管理水平、设备构架条件和概率分布为约束条件对中压配电网线损率标杆值进行测算。文献[7]分析了分布式电源在不同容量和不同接入位置对区域配电网合理线损率标杆值计算的影响。文献[8]采用一种混合聚类的方法生成电网的典型运行方式集对网损进行整体性评估。文献[9]从现状供电能力、负荷增长潜力、源荷调节能力3个方面量化台区改造紧迫度。实用系数刻画了区域行业负荷变化的时空特性,其值等于年最大有功负荷与变压器容量的比。现阶段实用系数常用于业扩报装时指导供电企业进行配电变压器(以下简称“配变”)容量选取及中长期负荷预测[10-11],尚未有研究将其纳入台区线损分析工作中。
上述研究对线损率标杆值进行了卓有成效的分析,但存在以下2个方面的不足:①台区分类未能充分挖掘多源系统数据,标杆值设定过程中主观性较强,过分依赖经验;②忽略了负荷随投入年限的变化,尚未考虑到不同行业的发展特性对于区域台区线损率标杆值设定的影响。
对此,提出一种基于行业实用系数特性的台区线损率标杆值计算方法。首先建立涵盖规划、运行、管理3个维度的台区线损影响因子体系;然后采用优化聚类初始中心的模糊C均值(fuzzy C-means,FCM)算法对台区进行分类;最后分析与台区(含用户)投运年限、负荷率密切相关的实用系数,构建基于实用系数特性的台区线损合理标杆值计算模型。本文拟针对与台区线损关联较大的实用系数进行比较系统的分析。
1 台区线损影响因子体系建立
研究台区线损影响因子可从计算台区线损的理论模型出发,传统配电网计算方法如均方根电流法、改进电量法、形状系数法等都属于等值电阻法的范畴,然而等值电阻法存在一些假设条件,尚未考虑到台区实际运行时存在的一些情况[12];故本节从等值电阻法理论模型及模型简化因素2个方面考虑,建立台区线损影响因子体系。
1.1 等值电阻法模型
等值电阻法[13]根据热损耗等量原理将结构复杂的低压台区多段电阻等效为变压器出口的一个等值的线路电阻,使得线路首段流过等值电阻产生的损耗与线路各支路电流流过相应支路电阻产生的损耗总和相同。该台区变压器型号为S9,其额定容量50 kVA,由于实际拓扑较复杂,故截取部分拓扑如图1所示。图1中Req为低压线路等值电阻,R1—R5为部分传输线路的电阻,50*BLV-25表示长度为50 m、截面积为25 mm2的铝芯聚氯乙烯导线,以此可计算R1。
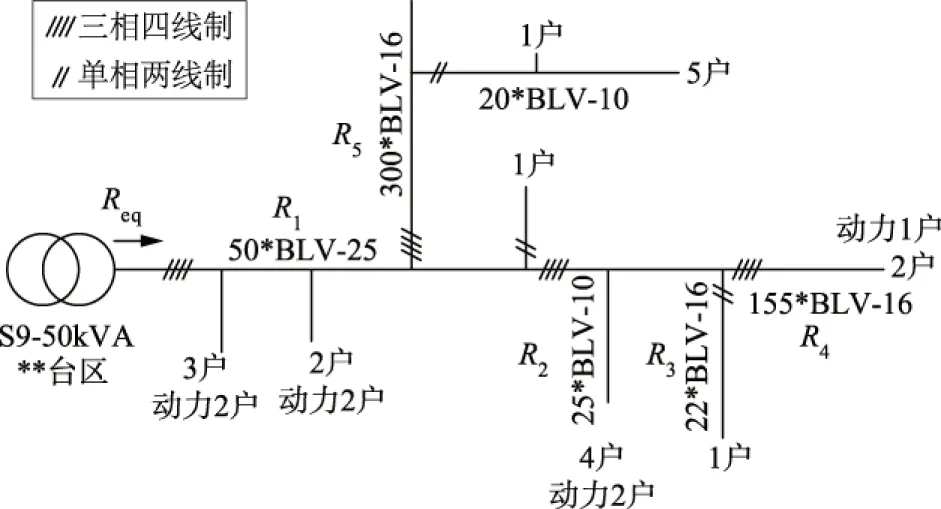
图1 等值电阻法示意图Fig.1 Schematic diagram of equivalent resistance method
理论线损ΔWL的等值电阻模型为
(1)
式中:N为配电变压器低压线路出口的结构系数;K为负荷形状系数,也称波形系数;Iav为低压线路首端平均负荷电流;ts为台区供电时间。由此可见,台区线损计算理论模型中,涉及到的参数主要为电网规划参数及设备运行参数。
下面对理论模型中的参数进行分析。
a)结构系数。低压台区主要的供电模式为TN-C及TN-C-S,对应的供电方式主要有单相两线制、三相三线制及三相四线制,主要应用场景分别为居民用户、动力负荷及低压网络主干线支路。三相不平衡运行时,2种供电模式的回路电流均会在零线上产生可观的损耗,故不同的供电方式下结构系数N的取值不同,单相两线制N=2,三相三线制N=3,三相四线制N=3.4。结构系数的差异直接影响台区线损的大小。
b)负荷形状系数。影响负荷形状系数的因素主要为负荷的实际利用时间及波动情况,常用24 h峰荷电流、谷荷电流及腰荷电流形成和实际负荷曲线近似一致的阶梯状负荷曲线图,模拟得到居民用户、商业用户、动力用户的负荷形状系数。此外,线路负荷形状系数又与线路首端有功电量或平均负荷电流成线性关系。
c)线路首端平均负荷电流
(2)
式中:W为有功供电量;Uav为三相平均电压;cosφ为配电变压器二次侧总表处的平均功率因数;t为对应平均值的运行时间。当有功电量未知时,可用无功电量及功率因数代替,无功电量的大小又受到配电线路无功补偿容量的限制,台区线损与这些运行参数均相关。
d)低压线路等值电阻
(3)
式中:Nj为第j条线路的结构系数;Wb,j为第j个计算线路的低压电能表抄见电量之和;n为一个台区的计算线路数量;Rj为第j段的电阻;Wa,i为第i个380 V/220 V用户电能表的实抄电量;p为用户电能表数量。实际计算时,Rj常简化为单位长度电阻rj与该段长度Lj的乘积。电阻值与导体材料、温度、线路截面积均有关。
1.2 模型简化因素
台区实际运行时,并不像等值电阻法中假设的无电压降、负荷形状系数和功率因数保持一致等理想情况。此外,设备运行工况,数据监测是否准确可信等企业管理参数也是影响台区线损的重要因素。
a)三相不平衡度。低压配电网负荷主要分为动力负荷(三相)及照明负荷(单相),低压台区三相不平衡运行是常态,因而其接线方式大多为三相四线制,负荷不平衡时存在中性线损耗[14-15]。三相负荷平衡及不平衡时的理论损耗分别为:
(4)
(5)
式中:ΔWL,ph和ΔWL,uph分别为负荷平衡时和不平衡时的理论损耗;IA、IB、IC为三相电流;Ipj为三相电流平均值,即Ipj=(IA+IB+IC)/3;IN为中性线电流;R、RN分别为相电阻及中性线电阻。
定义相电流不平衡度
βx=(Ix-Ipj)/Ipj.
(6)
式中:Ix为相电流,x{A,B,C}。工程应用中取βx的最大值βx,max作为三相不平衡度值。
由式(6)可得:
Ix=(1+βx)Ipj;
(7)
βA+βB+βC=0.
(8)
由于中性线电流IN=IA+IB+IC,假定A相为参考相位,并将式(7)代入,得
(9)
从而有
(10)
假定三相四线制线路的相电阻和中性线电阻相等,即R=RN,将式(7)、(8)、(10)代入式(5)可得
(11)
则三相负荷不平衡时线损增加率
(12)
由式(8)知βC=-βA-βB,将此式与式(4)、(11)一同代入式(12),可得
(13)
由此可见,当三相电流不平衡时,由于中性线电阻的存在,将产生额外的损耗。若A、B、C三相电流分别为14 A、6 A、10 A,则由式(6)知其相电流不平衡度分别为0.4、-0.4、0,代入式(13)得到δ=0.267,即三相负荷电流处于该不平衡状态时,比三相电流均为10 A的平衡状态要增加26.7%的损耗。
b)设备运行工况。相比于输配电设备,低压台区的线路、开关、变压器等均处于恶劣的环境(灰尘、温湿度变化、污垢等),随着使用年限的增加,其绝缘性能、氧化程度均有改变,导致线损增加。
c)数据来源可信度。计量装置的准确度、灵敏度时刻影响着电量、线损计算的准确性;台区户变关系的准确性对调度和线损计算也存在影响;用户窃电造成线损统计数据不准确,影响供电企业对不同配电网区域线损的判断。此外,供售电不同期、统计口径不一致均会造成数据真实性降低。
1.3 台区线损影响因子体系
基于上述理论模型中的参数及模型简化因素,本文将台区线损影响因子分为规划、运行及管理3个维度。

表1 台区线损影响因子体系Tab.1 Influence factor system of line loss in the region
2 FCM算法原理
2.1 经典FCM算法
FCM算法是一种基于划分的模糊聚类算法,该算法通过隶属度确定数据的分类。设有台区样本集合为X={x1,x2,…,xn},样本数为n,将其分为c类,其聚类中心集合为C={c1,c2,…,cc},并使给定的目标函数J趋于最小。
(14)
式中:uij为样本xj属于i类的隶属度;m为模糊系数。
FCM算法步骤如下:
步骤1:给定预设参数,包括迭代停止阈值ε、分类数目c、模糊系数m、最大迭代次数T、隶属度矩阵U。
步骤2:检查隶属度是否满足归一化条件。
(15)
步骤3:更新聚类中心C以及隶属度矩阵U。
(16)
(17)
式中dij=‖xj-ci‖,dkj=‖xj-ck‖,‖·‖符号表示欧式距离。
步骤4:若目标函数J(U,C)<ε或已经达到最大迭代次数T,则算法停止,输出结果;否则返回步骤3。
FCM算法通过反复修改聚类中心和隶属度,使得目标函数达到预设的阈值,因此也称为动态聚类。然而FCM算法迭代过程中,由于目标函数极值点的不确定性,在许多情况下以计算机随机获取的初始聚类中心往往偏离极值点,抑或盲目地集中在某些极值点周围而漏掉了其余极值点,导致算法收敛效果不佳。如何使得预设初始聚类中心靠近最终聚类中心,对算法的收敛速度和准确性有很大影响。
2.2 聚类中心优化
FCM算法利用欧氏距离计算最小化目标函数,对于不具有特殊规律的台区数据集,簇划分结果与基于密度的聚类算法有相似之处,其获取的各分类簇中心附近局部密度较大,而簇与簇间的边界点或远离某个簇中心点的局部密度相对较小,最终迭代停止后的聚类簇会呈现局部密度小的样本点包围着局部密度大的样本点这一特点;因此,找出聚类样本中局部密度较大的样本点,将其作为初始聚类中心,可达到优化算法迭代的目的。在此需要引入基于密度的聚类(density-based spatial clustering of applications with noise,DBSCAN)算法。
定义1:领域半径E。DBSCAN算法将聚类视为被低密度区域分隔的高密度区域,它通过给定邻域半径描述样本集的紧密程度。样本的密度被定义为与样本集中其他样本的距离在给定领域半径内的个数,个数越多则表明该样本的密度越高。当其他样本点距该样本点的距离大于E时,可认为对该样本点局部密度的贡献为0。领域半径的确定问题参考文献[16]的方法自适应选取。
定义2:引索密度集
F(xh)={xj∈X,h≠j|0<‖xh-xj‖E}.
(18)
式(18)表示样本xh与其余样本xj的欧式距离落在领域半径内的集合,将高引索密度集合对应样本作为聚类中心,并依次删除已加入聚类中心点集的邻域样本,则可根据算法预设的聚类簇数目c,找出样本密度最大的集合。
引入DBSCAN算法的聚类中心优化步骤如下:
步骤1:输入样本数据集X,初始化聚类中心点集C为零集合。
步骤2:利用算法自适应选取样本集合的邻域半径E,依据式(18)计算引索密度集,设置数组存储样本xi中满足条件的引索密度集数据标签。
步骤3:统计所有数组中存储标签的个数,将当前标签个数最多的、名为array的数组对应的引索样本xarray作为初始聚类中心加入点集C中。
步骤4:判断聚类中心点集C中样本个数是否等于预设聚类数c。若等于c,结束步骤,输出点集C;若小于c,则进行步骤5。
步骤5:将数组array中引索标签对应的样本删除,剩余样本数据集定义为X′,引索密度集为R′(xi),然后重复步骤3。
2.3 聚类评价指标
对台区样本进行FCM聚类分析前,需预先设定聚类数c,对于未知分类的台区数据集,需采用内部有效性指标。Xie-Beni(XB)指标通过将隶属度引入到聚类评价中,可有效对模糊聚类进行评价;然而,当聚类数较大甚至趋向于样本总数时,XB指标随着聚类数的增加单调递减,单一使用XB指标难以有效判断合理的聚类数。为此,引入戴维森堡丁指数(Davies-Bouldin index,DBI),DBI可避免因只计算目标函数隶属度而易出现局部最优的现象,可有效弥补XB指标的不足。聚类评价指标定义如下。
a)XB指标的值
(19)
式中:xk,j为属于k类的第j个样本值;vk,c、vr,c为第k、r类的聚类中心参数值;ukj为样本xk,j对聚类中心vk,c的隶属度值,由聚类后得到。式(19)的分子衡量类内紧凑度,分子越小表示相似度越高;分母衡量类间分离度,分母越大说明类间差异性越大。IXB越小,说明聚类有效性越高。
b)DBI的值
(20)
式中:Si为第i类的类间分离度;Mi,k为第i类和第k类聚类中心的欧氏距离。IDB越小,说明聚类质量越优。
类间分离度
(21)
式中:Tk为第k类的样本数;zk为该类样本指标数值;zc为对应该类样本的聚类中心指标数值。
3 台区线损率标杆值预测模型
3.1 实用系数
实用系数是指年最大有功负荷与变压器容量的比值,用来反映用电用户对变压器的使用效率[17]。在实际生产中,工作人员经过多年的数据积累与分析比较,已建立起实用系数与使用年限、负荷率的概念并将其用于线损分析工作中。
每个用户在终期年份的实用系数
(22)
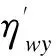
对于区域行业内的所有电力用户,按照容量大小进行加权平均,即可得到区域行业实用系数,即
(23)
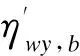
不同行业实用系数可以衡量该区域年运行负荷随投入年限的变化特性,年最大负荷在台区中表征该区域所有用电设备消耗功率总和的最大值,包括办公、商业、城乡居民等设备,而其用户设备功率之和又称该区域的综合用电负荷(其与时间的乘积为售电量)。综合用电负荷加上网络损耗功率就是系统中各发电厂供应的功率,称为电力系统的供电负荷(其与时间的乘积为供电量)。由于电力系统电能无法大量存储,故供售电量具有一致性,综合用电负荷与网损功率同步运行,所产生的电量对应为售电量与损耗电量。
利用实用系数可得到不同行业年负荷最大值随投运年限的变化率,年最大负荷为该区域运行最严峻的时刻(重载)。在此假定:①年最大负荷变化率高于或等于年平均负荷变化率;②用电功率与损耗功率的变化率相同。则可依据投运年限最大负荷的变化率来衡量其全年的平均变化率,将由实用系数获取的变化率反映到售电量与损耗电量。其意义是,若台区以行业实用系数的年最大负荷增长率作为年平均负荷增长率,则此时计算所得的线损率应当为下一年该类台区线损率的极大值,即为线损率标杆值。
3.2 合理线损率标杆值计算模型
基于FCM算法进行聚类获取的结果,在台区规划及运行参数上较为相近,为降低管理难度,可为聚成同一类的台区来设定线损率标杆值。根据统计学理论,建立一元高次回归模型,可用其一阶导数计算行业负荷变化的趋势项,并反映到线损率标杆值的计算中。实现步骤如下:
步骤1:收集台区线损影响因子参数,台区用户供、售电量数据及所处行业信息。对台区线损指标进行归一化后,采用FCM算法进行聚类分析,获取分类结果,依次定义为C1、C2、C3等类别。指标z归一化方法为
(24)
式中:z′为指标归一化后的值;zmax、zmin分别为样本中该指标对应的最大值与最小值。
步骤2:基于最优聚类评价指标参数,将待测台区分为若干类别,根据离群点判定每组聚类簇中偏离聚类中心前2%的台区,并将其作为噪声点删除。

步骤4:计算不同类别样本的线损率标杆值。以C1类样本为例,假定该类台区样本总数为d,对应每个台区的用户数量为kd,则该类台区的线损率标杆值
(25)

对于步骤2,由于FCM算法是全聚类算法,会将所有样本分门别类,无法识别样本集中的噪声点,而部分存在异常指标值的台区不应当作为标杆值计算的参考,离群点检测算法(如局部离群因子算法)可识别样本中潜在的指标异常值[18]。针对台区样本集,经过多次经验判别发现,当删除聚类簇2%样本时,剩余样本局部离群因子数值小于1,可认为遗弃样本为噪声点。
对于步骤4,基于第3.1节的2个假定可知,用电功率与损耗功率的变化率相同,用电、损耗功率的时刻相同,而供电量为两者之和,故用户供电量变化率与实用系数变化率相同。若假定实用系数变化率均为0,式(25)计算所得与线损率平均值相近。理由是:依据台区影响因子参数聚为一类的样本,在结构布局、运行属性上均相近,则其供电量也相近,若d个台区的供电量Ws1≈…≈Wsd,可推得
(26)
式中:WLd表示损耗电量;Ws,av为d个台区的供电量平均值。
若忽略台区样本总数d,式(25)还可计算单个台区的线损率标杆值,此时会出现一个特例:当该台区所有用户处于同一行业时,实用系数变化率抵消,所得线损率标杆值为样本原始线损率,表明该台区下一年的线损率只要不增加即“达标”。
4 实例分析
选取广东省某地区电网为测算实例,剔除线损率为负、参数存在缺漏等不符合要求的数据[19]后,汇总得到该区域1 862个低压台区年供售电数据及指标参数。依据实际影响因子参数获取情况,得到FCM聚类指标参数共8个,分别为导线截面积、无功补偿、供电半径、线路载流量、配变容量、功率因数、三相不平衡度和负荷率。部分样本参数见附录A表A1。
4.1 最优聚类数确定
本文引入了2个聚类评价指标来确定最优聚类数。设置聚类数区间为[2,16],通过计算比较该区间内不同聚类数下的聚类评估指标XB及DBI,选取评价指标的最小平均值作为合理聚类数,得到最优聚类结果为5类。评价结果详见附录A表A2。
确定最优聚类数后,采用本文提出的改进FCM算法对台区进行聚类分析,设定聚类数c=5,停止阈值ε=10-6,模糊系数m=2,最大迭代次数T=100。表2给出了经典FCM算法与改进FCM算法在循环运算100次后的结果,附录A表A3给出2种算法的初始聚类中心及最终聚类中心。2种算法的初始聚类中心有所差异,经典FCM算法随机选取初始中心,改进FCM算法选取高密度样本作为初始聚类中心,其指标参数值处于样本密集区域,一定程度上更加靠近最终聚类中心,从而减少迭代次数。通过优化初始聚类中心的选取,台区指标参数聚类迭代次数减少64.15%,计算耗时降低37.26%;由于2种算法的停止阈值及目标函数设定相同,最终聚类中心几乎一致,仅部分聚类簇样本数目有所差异,因而2种算法聚类效果评价指标相近,改进FCM算法的XB指标有小幅提升。

表2 聚类算法效果对比Tab.2 Effect comparison of clustering algorithms
4.2 改进FCM算法聚类结果
将归一化后的原始参数作为FCM算法输入参数进行聚类,图2为负荷率、配变容量、供电半径这3个参数的投影(均为标幺值)。5个聚类簇具有清晰的划分界限,分类结果覆盖不同维度的区域。基于改进FCM算法的聚类结果见表3。由于聚类样本数较大,不同类别台区线损率的极值及平均值均相似,无法对台区线损进行差异化管理,且这3种线损率标杆值不能体现负荷发展特性,进而难以对下一年的台区管理作出指导。

图2 聚类参数三维投影Fig.2 3D projection of clustering parameters
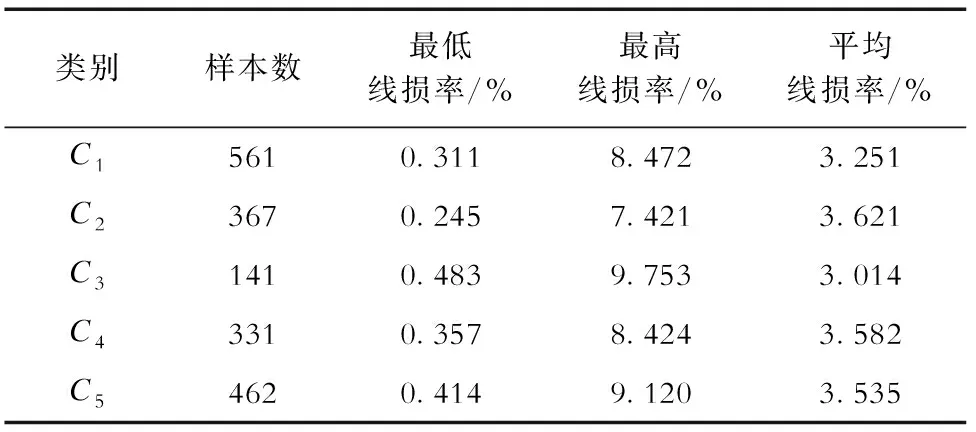
表3 基于改进FCM算法的聚类结果Tab.3 Clustering results based on improved FCM
4.3 行业实用系数曲线
供电公司将行业负荷划分为6大类,包括办公、住宅、商业、工业、文化娱乐、公共设施。根据该区域22年的实测用户负荷数据及报装容量,利用式(22)和(23)计算得到区域行业实用系数随投运年限的散点图(图3)及最小二乘拟合特征参数(表4)。如图3所示,实用系数拟合曲线在不同行业呈现不同的波动情况,其增长速度也有所差异。利用实用系数曲线对用户所处状态负荷进行趋势项预测,并纳入线损率标杆值的设定中。

图3 行业实用系数散点图Fig.3 Scatter diagram of industrial utility coefficient

表4 实用系数曲线特征参数Tab.4 Characteristic parameters of utility coefficient curve
4.4 合理线损率标杆值计算
针对第4.2节获得的聚类结果,根据离群点判定将每组分类中偏离聚类中心前2%的台区剔除,使得剩余聚类簇更加紧密,以更好地体现分类特征。根据第4.3节获取的实用系数拟合曲线参数,计算其一阶导数,并利用式(25)计算分类簇线损率标杆值,得到表5。
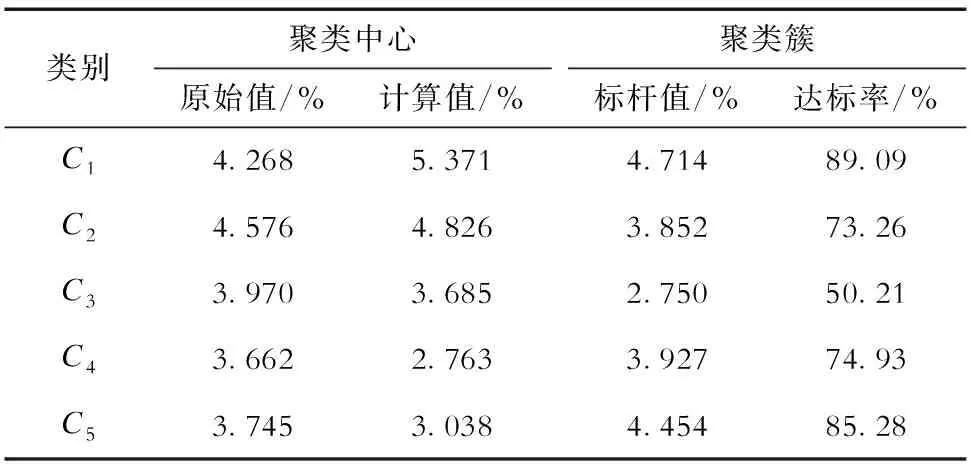
表5 合理线损率标杆值预测Tab.5 Prediction of reasonable line loss by benchmarking
将聚类簇标杆值与表4的平均线损率对比,仅C3类标杆值小于平均值,其线损达标率最低,为50.21%,而其余4个类别的线损达标率均高于70%。若仅计算单个台区的线损率变化值,如表5的聚类中心,可发现C1、C2类的聚类中心计算值高于原始值,说明台区下一年线损率不升高即可“达标”;而对于计算值远低于原始值的台区,在下一年的工作中需要加强关注。将实用系数曲线的变化特性纳入线损率标杆值计算中,使得标杆值的设定更加差异化;同时,通过计算单个台区及聚类簇台区的线损率标杆值,可从个体及整体2个方面评估台区线损率是否合理,避免台区线损计算一刀切的管理模式。
由于改造资金的限制,可对待改造台区进行整体性评估,在满足供电可靠性的基础上以降损空间最大为目标,对台区改造效益进行测算和疑似窃电评估[20]。考虑到市级配电网动辄上万个低压台区,对其进行分区域、分类别地设定对应的线损率标杆值,有利于增强供电企业差异化管理能力。
5 结论
本文提出一种测算台区线损率标杆值的方法,以广东省若干台区样本进行分析,得出以下结论:
a)设计的台区线损影响因子指标体系更合理,涵盖台区规划、运行、管理3个部门的工作。
b)以密度聚类的思想优化选取FCM算法初始聚类中心,使得台区指标参数最优聚类迭代次数减少,聚类速度更快。
c)考虑负荷及行业变化对台区线损的影响,基于统计学原理,将行业实用系数曲线趋势项纳入台区线损率标杆值的设定中,从个体及整体2个方面对台区下一年的合理线损率标杆值进行评估,增强供电企业差异化管理线损的能力。
猜你喜欢
水利学报(2022年3期)2022-06-07
河北电力技术(2022年1期)2022-03-25
中华建设(2020年5期)2020-07-24
网络文学评论(2019年6期)2019-12-13
汽车观察(2018年12期)2018-12-26
电子制作(2017年2期)2017-05-17
电子制作(2017年2期)2017-05-17
电子制作(2016年1期)2016-11-07
电子制作(2016年1期)2016-11-07
现代工业经济和信息化(2016年8期)2016-05-17
