
一种融合社交关系的矩阵分解推荐模型
2020-08-19 07:25吴清春贾彩燕
计算机工程 2020年8期
吴清春,贾彩燕
(北京交通大学 a.计算机与信息技术学院; b.交通数据分析与挖掘北京市重点实验室,北京 100044)
0 概述
随着互联网快速发展,人们获取信息的方式越来越多,然而大量无关的信息会干扰用户对所需信息的选择。推荐系统作为用户快速获取信息的有效途径,已被广泛应用于各个行业,但用户对项目评分数据的稀疏性阻碍了推荐系统性能的提升,如在商业推荐系统中,可用商品评级的密度通常小于1%,这使得传统推荐算法[1-3]无法达到理想的推荐水平。此外,传统的推荐系统通常只考虑用户对商品的评级信息,而忽略了用户之间的社交关系或信任关系。
社交媒体的广泛使用产生了大量的社交关系,并且在现实世界中人们总是易受他人的影响,倾向于与具有相似偏好的人相互交往,而这些相互交往的人由于彼此影响变得更加相似。因此,可以利用这些信息来提高商品评级预测的质量。在此假设下,研究者提出多种基于社交网络的推荐模型。实验表明,融合社交网络信息的推荐模型能改善传统模型的推荐性能,尤其当用户对项目的评级矩阵稀疏时,推荐性能会有较为明显的提升,但仍存在一些问题,例如:现有数据集中社交网络的数据形式大多为0-1数据,并且仅包括用户之间是否信任的信息,难以区分用户之间的社交信任程度;部分模型对社交关系建模时仅考虑用户之间的显性社交关系,在商品评分数目较少或社交关系信息较少的情况下,模型的推荐效果不佳;部分挖掘用户隐性社交关系的方法如聚类、社区发现等方法,因类或社区大小的定义不同可能会引入额外的社交噪声影响推荐效果。
本文对仅考虑直接交互关系的矩阵分解(Matrix Factorization,MF)推荐模型SoReg进行改进,采用基于信号传播的社区发现算法计算社交网络中用户之间的拓扑相似度,将其作为用户的信任值并通过设置阈值构建加权社交信任网络,进而提出融合社交信任网络的推荐模型SoRegIM。
1 相关工作
一些学者提出通过社会关系信息来改进推荐方法,基于近邻的社交推荐模型[4]、基于图的推荐模型[5-6]、基于物质扩散的推荐模型[7]、基于矩阵分解的推荐模型[8-9]和其他的一些社交推荐模型[10-12]相继被提出。
基于矩阵分解的推荐模型算法具有灵活性高、推荐性能好等特点,是当前推荐系统中的主流方法。本文以融合社交关系的矩阵分解型推荐模型为基础,研究基于社会关系的推荐方法,包括通过社交网络中直接相连的用户信息来优化推荐性能的算法,以及通过社交网络中的用户关系进行聚类并融合商品评分信息来提升推荐性能的方法。SoRec[13]对评级矩阵和社交关系矩阵执行同因子分解,同时学习用户特征、社交特征以及项目特征。文献[14]提出的社会模型TrustMF,同时考虑了用户对其他用户的信任以及被其他用户的信任信息,使用户从信任和被信任两个方面进行建模,学习两个不同的特征向量。文献[15]通过使用捕捉当地和全球社会关系的方法,提出一个新的框架LOCABAL,利用当地和全球社会上下文进行推荐,在当地社交信息中假设具有朋友关系的用户之间品味相似,而在全球社交信息中使拥有较高声誉的用户权值更大,从而发挥更大的作用。文献[16]提出的推荐模型FangPMF,将社交信任信息分解成4个维度进行衡量,从不同的角度充分考虑社会信息,并使用支持向量回归对多个信任维度进行整合,将其与原始概率分解的模型相结合。文献[17]同时使用社交网络信息和评分信息学习用户信任和被信任矩阵,将其用于最终的评分预测模型中。
上述将社交信息融合到推荐模型中的方法已被证明能够有效提升传统推荐方法的推荐性能,然而这些方法仅关注显性的社交关系,当用户评分信息和社交中直接相连用户都比较少时推荐性能提升有限。也有学者采用社区发现或聚类算法挖掘隐性的社交关系。文献[18]使用社区发现算法挖掘社交网络中不同的社会关系,提出一种重叠社区正则化的模型MFC,假设同一社区中的用户偏好相似。文献[19]提出了基于社交维度的推荐模型SoDimRec,但同一社交维度中包含不具有社交关系但兴趣可能相似的用户。文献[20]通过建立社区信任模型获取用户综合信任度,并利用重叠社区发现算法为用户划分专属虚拟社区进行信任传播,将其用于协同过滤算法得到推荐结果,但这种基于聚类的社交兴趣推理方法可能会产生社交噪声,并且难以区分同一社区内不同用户之间的信任强度,可能会给推荐系统带来不良的影响。因此,有必要根据社交网络的拓扑信息计算用户之间的链接强度,建立社交信任网络进而获得合适的社会推荐模型。
2 基于矩阵分解的推荐模型框架

(1)

3 基于社交网络拓扑关系的推荐模型
3.1 社交信任关系网络构建
在现有的社交网络数据集中,数据形式多为二值型数据,常见的社交网络二值型描述方法不能充分描述用户之间的信任程度,这也导致大部分使用社交信息的推荐算法在推荐准确性上提升有限。社交网络中的节点表示用户信息,网络的拓扑结构能体现出节点之间的紧密程度,因此,社交网络中节点间的拓扑关系能够间接反映两个用户之间的相关程度,将通过拓扑关系计算的节点间的相关程度称为用户拓扑相似度。本文通过挖掘社交网络中用户的拓扑关系,计算用户之间的拓扑相似度,用于近似刻画用户之间的信任程度;另一方面,在社交网络中许多用户的直接邻居较少,因此,有必要考虑间接邻居的信任度对用户评级产生的影响。在对社交网络中直接相连的用户计算相似度时,将用户拓扑相似度超过一定阈值的间接用户连接起来,形成新的社交信任网络。
本文使用signal相似度[21]来计算社交网络中用户间的拓扑相似度。假设用户之间的信息通过τ步传播后,该用户对网络中的其他用户拥有一个影响度,用户信息传递方式如下:
S=(A+I)τ
(2)
其中,I是n维单位矩阵,A是网络的邻接矩阵,τ是信息传递的次数。在进行标准化处理后,得到用户间的拓扑相似度为:
(3)
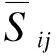

图1 用户间社交关系表示Fig.1 Representation of social relationship among users
3.2 SoReg模型
SoReg是文献[22]提出的一种基于社会正则化的社交推荐模型,该文献认为用户的偏好与其直接相连的邻居一致。SoReg模型的目标函数如下:

(4)

(5)
3.3 SoRegIM模型
经典社交推荐模型SoReg[22]只对社交网络中直接相连的用户施加相似度约束来改进评级预测,社交信息利用率有限。而在现实世界中,用户不仅仅受到与他直接相连的用户的影响,社交网络中拓扑相似度较大的用户之间的兴趣应该更接近。因此,本文利用社交网络中用户之间的拓扑关系,考虑直接邻居、间接邻居及其链接强度构建信任网络(如图1(b)所示)。此外,在计算用户之间相似度时不仅使用用户评级信息,而且还使用用户之间的社会信任强度,进而构建一个新的推荐模型SoRegIM,其最小化的目标函数为:
(6)
上式最后一项中Z的定义如式(7)所示,用于保证用户之间的特征尽可能接近,使得社会信任强度高且评分相似度大的用户之间的用户特征向量相似度尽可能高。
(7)
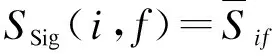
(8)

通过对Ui和Vj求偏导,利用梯度下降法可以计算出目标函数(式(6))的极小值,其中,Ui和Vj求解如下:
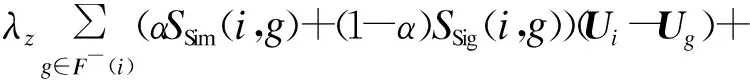
(9)
4 实验与分析
本节在3个公开的数据集FilmTrust、Ciao和Epinions上通过实验验证SoRegIM模型的性能,并利用均方根误差(Root Mean Square Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)两个评价指标进行评价。
4.1 数据集
本文实验使用的数据集信息如表1所示,这3个数据集中的数据都包含用户评级和用户社交关系信息。FilmTrust是一个电影推荐网站,用户可以按照自己的喜好对电影进行打分,也可以对其他用户添加信任关系。Ciao是一个物品评论网站,用户可以对不同物品进行打分和和添加评价,同时可以和其他用户建立有向社交关系。Epinions是一个著名的消费者评论网站,其提供了各种商品的比较信息,用户可以对商品进行打分和评论,同时每个用户都有一个信任列表,可以添加对其他用户的信任。

表1 实验数据集信息Table 1 Information of experimental data set
4.2 评价指标
使用平均绝对误差(MAE)和均方根误差(RMSE)进行评价,计算公式如下:
(10)
(11)

4.3 对比模型与实验参数
为评估本文模型的有效性,选取推荐系统领域中7个经典的矩阵分解相关模型进行对比,具体如下:
1)PMF[2]:仅使用用户评分信息,是一种概率矩阵分解的模型。
2)SoRec[13]:使用用户评分信息和社交网络中直接邻居信息,是一种对评级矩阵和社交关系矩阵执行同因子分解的模型。
3)SoReg[22]:使用用户评分信息和社交网络中直接邻居信息,是一种通过定义社会正则化来捕捉用户间强依赖连接的模型。
4)LOCABAL[15]:使用用户评分信息和社交网络中直接邻居信息,是一种同时考虑用户信任与专家信息的推荐模型。
5)SocialMF[23]:使用用户评分信息和社交网络中直接邻居信息,是一种将信任传播机制应用到概率矩阵分解中的模型。
6)MFC[18]:使用用户评分信息和社交信息,是一种将社交正则化应用在不同重叠社区上,利用已有重叠社区发现算法从社交网络中挖掘社团的模型。
7)SoDimRec[15]:使用用户评分信息和社交信息,是一种考虑不同社交维度中用户弱依赖链接,采用传统社区发现算法识别用户社交维度的模型。
对各模型的参数进行如下设置:将所有模型的隐空间特征个数设置为10,λu和λv设置为0.001;在SoRec模型中设置λc=1,λz=0.001;在SoReg模型中设置β=0.001;在LOCABAL模型中设置α=0.5;在SocialMF模型中设置λT=1;在MFC模型中设置λz=0.001;在SoDimRec模型中设置λ1=10,λ2=100;在本文SoRegIM模型中设置α=0.8,β=0.02,λz=0.001。
4.4 实验结果
本文选择80%的数据作为训练数据,以预测其余20%的评分,实验结果是五重交叉验证的平均值,如表2所示,其中加粗数据为最优数据。可以看出,PMF的准确度不如其他模型,这进一步表明利用社交信息可以提升推荐的准确性。SoRec、SoReg、LOCABAL和SocialMF使用了社交网络中直接邻居信息,MFC和SoDimRec通过聚类的方法考虑到间接邻居,虽然与只使用直接邻居信息的模型相比性能有所提升,但由于聚类个数难以确定,容易出现兴趣不太相似的用户在同一类中的情况,从而产生社交噪声。本文构建了社交信任关系网络,并定义了信任强度,避免了多余的社交噪声。由表2结果可知,与7种经典模型相比,本文模型的性能有所提升,特别在稀疏数据集FilmTrust和Epinions上提升明显。

表2 本文模型与7种经典模型的MAE和RMSE指标对比Table 2 Comparison of MAE and RMSE indexes of the proposed model and seven classical models
4.5 参数影响
在本文模型中,参数β、α和λz会对推荐效果产生不同程度的影响。其中:β是通过signal相似度计算出的用户拓扑相似度定义的阈值,用于控制重构社交信任网络的稀疏程度;α用于控制评分相似度和社交关系信任度在整体用户相似度中所占的比例;λz用于控制社交信息对模型的贡献程度。本文通过实验分析在Epinions数据集中这些参数对SoRegIM模型推荐性能的影响。图2~图4分别显示了β、α和λz不同设置下本文模型的MAE和RMSE指标。由图2可以看出,β=0.02时推荐性能最好,当阈值β设置过低时,额外引入的用户信息过多可能造成社交噪声,当阈值β设置过高时,则会忽略掉部分重要的社交信息。在图3中,α=0表示用户相似度仅考虑社交信息,α=1表示仅考虑评级信息。由图3可以看出,在计算用户之间相似度时同时考虑评级信息与社交信息推荐性能最好。由图4可以看出,λz的变化对推荐结果有一定的影响,λz=0.01时推荐性能最好,随着λz的增大,信任的用户可能产生过度影响,而当λz较小时,信任用户产生的影响太小会导致推荐效果相对传统方法提升有限。
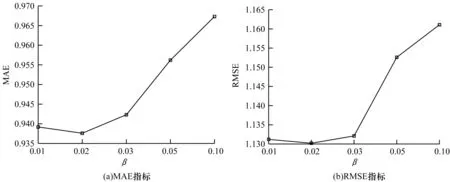
图2 参数β对推荐性能的影响Fig.2 Impact of parameter β on recommendation performance
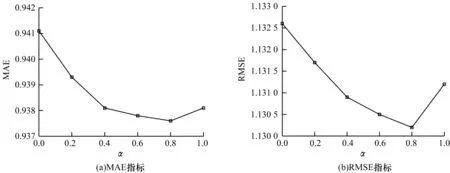
图3 参数α对推荐性能的影响Fig.3 Impact of parameter α on recommendation performance

图4 参数λz对推荐性能的影响Fig.4 Impact of parameter λz on recommendation performance
5 结束语
在网络信息量爆炸式增长的背景下,本文构建一种融合社交网络用户拓扑关系的矩阵分解型推荐模型。该模型考虑用户的直接和间接邻居并挖掘其链接强度,在计算相似度时不仅利用用户在项目上的历史评分,同时还同时考虑用户之间的社会关系。实验结果表明,通过融合社交信息可大幅提高模型的推荐性能。但本文模型仅考虑用户之间的关系,下一步将考虑项目之间和偏好相异用户之间的关系,探索其对用户评级行为的影响。
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
第一财经(2020年4期)2020-04-14
文苑(2018年17期)2018-11-09
桃之夭夭B(2017年2期)2017-02-24
中央民族大学学报(自然科学版)(2016年3期)2016-06-27
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
高中生·青春励志(2014年11期)2014-11-25
