
基于区间估计的建筑能耗监测最小样本量模型研究
2020-08-29 01:42王秋月张吉礼
建筑热能通风空调 2020年7期
王秋月 张吉礼
大连理工大学建设工程学部
0 引言
公共建筑实时监测目的并不仅是为了获取样本建筑终端能耗值,还要从建筑终端能耗数据中总结总体建筑能耗变化特性,寻求节能潜力。而样本数量决定了样本建筑是否能够反映研究区域总体建筑的能耗情况。若样本数量太小,样本数据不足以反应整体建筑能耗水平。若样本数量太大,则造成了不必要的数据堆积,因此,合理的样本建筑数量在保证数据准确性的前提下,对于减少建筑能耗监测的经济成本,明确建筑能耗监测平台建设规模,增加建筑能耗数据统计分析的速度及有效性具有重要作用。
国内外学者对于建筑能耗、能效的研究分析都建立在一定数量的建筑基础上进行。主要分为两个方面,对单体建筑进行研究或者选择建筑群进行研究。在对建筑群的选取上,多为随机选取或者选取典型性建筑进行研究。龙惟定[1]选取上海市9 栋办公建筑调查,发现办公建筑的最大平均能耗量和最小平均能耗量相差2.21 倍。李峥嵘[2]选取上海市32 栋公共建筑的能耗及运行管理资料进行调查,其中包括学校、仓库、医院、体育馆、办公、商场及旅馆,指出办公、商场及旅馆的能耗占上海市总能耗的25.9%。李沁[3]通过对重庆市207 栋公共建筑的基本信息进行调研收集,并对145 栋公共建筑的总体用电数据进行统计分析,估计总体用能水平分布,以确定建筑能耗统计定额水平。JosephC Lam[4-5]等选取香港20 栋典型性办公建筑作为样本建筑,研究五种气候指标:温度、湿度、风速、太阳辐射、清洁指数对办公建筑用电的影响进行研究。可以看出,研究者认为对建筑群能耗、能效进行分析,需要考虑建筑不同功能、不同气候区等指标来选取样本建筑,但是没有对到底选择多少样本建筑是合理的进行讨论,也没有标准来说明研究样本是否能够代表所研究区域。
赵加宁等人通过对我国建筑能耗统计中关于居民合作、建筑分类、调查方式、数据收集四个方面的问题进行了分析[7],认为了解建筑物的单项能耗,需建立测试平台和能耗统计数据库,为使测试建筑具有代表性,应采用统计学原理对建筑能耗进行调查。以深圳地区为例,由于目前国内缺乏建筑统计抽样测试数据,因此采用能耗模拟软件,模拟8 类公共建筑能耗,给出置信度为87%,极限误差为0.1 的情况下,样本容量随建筑总量的变化趋势,指出不同功能建筑总数超过1000 栋时,对于给定估计精度,样本容量不再大幅变化,为样本量选取提供指导思想[8]。冯可梁(2014)[9]认为合理的样本数量有利于在保证数据准确的前提下减少能耗统计成本。William chung[10]也简单交代了如何选取样本建筑,他将办公建筑按照一定特点分为五组,规定每组随机选取30 栋办公建筑构建分步回归模型,对香港办公建筑能效水平进行研究,认为香港办公建筑的能源消耗总量呈上升趋势,但是其能效水平在逐步提升,即提高建筑能效的最大贡献在于增加了节能量,而不是减少了能源使用量。以上研究者认为合理的样本建筑将对研究结果有正向促进作用,但没有给出一个可参考的统计学样本量计算方法。
因此,对某一地区究竟需要监测多少栋样本建筑、方能较准确、客观地反映该地区建筑的总体用能特征的问题亟待解决,本文将从统计学角度出发,研究解决合理监测建筑数量的问题。
1 建筑能耗抽样误差与样本量大小的关系
将全体建筑称为总体,为了解研究区域总体建筑的能耗特征,通过对总体抽样监测得到代表总体的样本建筑,但因为信息是分布在每个样本建筑上的,所以需要对样本建筑数据进行加工,把样本的信息浓缩到不包含未知量的样本函数中,这个函数称为统计量如样本均值、方差等都为统计量,概括总体的函数称为总体参数,通过样本统计量对总体参数进行估计即会产生抽样监测误差。抽样监测误差是由于抽样引起的,确切的说抽样误差其实是由于样本建筑的随机性引起的误差。对于任何一种建筑能耗抽样监测方案,其可能的样本建筑都有很多,而实际选择的只是一些建筑,因此选取哪些建筑一定程度上具有随机、偶然性,抽到另一批建筑,对总体能耗参数的估计就会有不同,这就是建筑能耗特性推断中误差产生的根本原因。
假设总体公共建筑用电数据服从某种分布,而样本建筑用电数据具有某种相同的分布情况,因此可以用样本建筑的分布估计来推断总体建筑的用电分布[11]。同样,根据样本建筑的能耗数据对总体建筑能耗进行估计和推断,即使精确性很高,由于建筑数据源的随机性,其结论也要采取一种概率的陈述方式,表示总体参数被包括在由样本建筑统计值做出的区间估计范围内的相应概率有多大。在统计学假设检验中,研究者常常先控制第一类错误的发生概率,即给定犯第一类错误概率的最大允许值α,称为显著性水平,其意义为估计总体参数落在某一区间内可能犯错误的概率。1-α 为置信度或置信水平,表明了该区间估计的可靠性。
下面基于概率统计中心极限定理[11],推导监测中抽样误差与样本容量的关系式。
给定概率意义下的最大绝对误差或相对误差称为误差限,置信度和误差限的关系满足:在指定的显著性水平α 下,允许的最大绝对误差和最大相对误差分别为Δ,r,应有

式中:Δ 为一常数;r=Δ/θ;θ 为总体参数,可以是总体的单位面积能耗值的均值或者方差等,kWh/m2;为样本统计值,可以为样本建筑的单位面积能耗值的均值或者方差等。
根据中心极限定理,在大样本情况下,无论总体服从什么分布,样本估计值的分布渐进正态分布,因此,样本建筑量n 充分大,应有
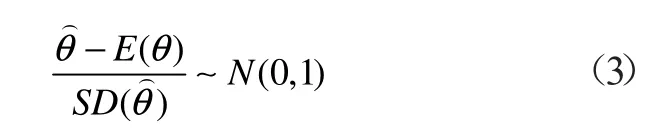
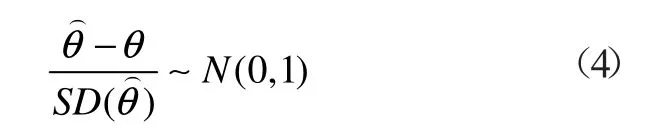
根据正态分布的性质,有

因此可得出样本抽样的绝对误差和相对误差表达式:


对于一定量的样本建筑,其单位面积年用电量可以认为是随机变量X,对变量X 计算其样本统计值如方差,标准差和变异系数。其计算公式可写为
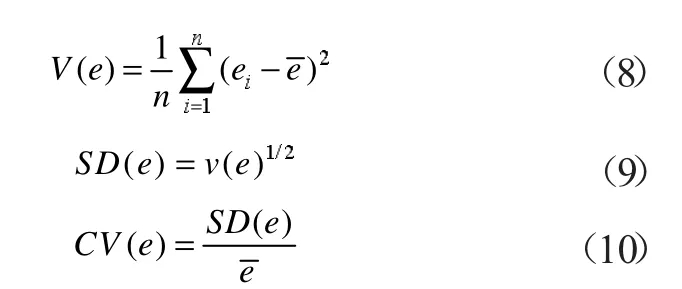
式中:n 为随机变量个数,即样本建筑数量;ei为第i 个指定样本建筑的单位建筑面积年用电量为单位建筑面积年用电量的样本均值;V(e)代表研究对象单位建筑面积年用电量的样本方差;SD(e)代表研究对象建筑单位建筑面积年用电量的样本标准差;CV(e)代表样本抽样变异系数,变异系数反映了样本统计值对均值的离散程度。
式(6)和(7)给出了绝对误差、相对误差和抽样方差、变异系数的关系,结合式(8)~(10),可以看出样本方差和变异系数是样本建筑量n 和总体建筑量N 的函数,因此能耗抽样监测中,只要对能耗估算精度提出要求,不论是以Δ,r哪种形式给出,都可以计算出合理样本量下限,称之为最小样本量。
2 建筑能耗抽样监测最小样本量模型
2.1 研究思路
对概率分布估计最重要的是计算分布的均值和标准差。建筑能耗概率分布是反映总体建筑能耗特性的一个重要指标,大多数实际问题中,可以认为或近似认为总体服从正态分布,即使实际情况呈现偏态分布,仍可以将源数据经数据转换服从正态分布。本文主要研究方法论问题,因此假定建筑能耗总体服从正态分布,因此,建筑能耗监测中,最小样本量需要满足对总体建筑能耗概率分布均值和标准差准确估计的需要。本节从统计学理论的区间估计理论出发,结合随机抽样理论及建筑能耗抽样误差与样本量大小的关系,构建面向建筑能耗评价的最小样本量模型,分析其在建筑能耗估算和特性评价中的应用。
其主要步骤为:
1)数据准备。假设待分析建筑群、区域或地区能够获取的样本建筑能耗数据集总量X 能够代表该建筑群、区域或地区建筑能耗数据集总体e。对数据集X内建筑进行编号从1 到N,每个建筑编号对应着该建筑的能耗信息1,..,eN,每抽取第i 个编号即代表抽取该编号对应的建筑,则选取该建筑能耗指标ei(即随机变量)进入抽样训练模型进行计算。
2)计算随机变量的期望和标准差。由于样本数据集X 服从正态分布,则指定时间段内建筑能耗评价指标的真实期望和标准差可以根据以下公式计算:

3)进行随机抽样。对选入训练集的建筑数据总体进行简单随机抽样,第k 次抽样的建筑量为n(k)。
4)基于样本计算ni(k)对正态随机变量的期望和标准差进行区间估计。对于给定的置信水平1-α,依据正态总体均值和方差的区间估计理论,分别计算其对应的置信区间μi(k)±Δμ(k),σi(k)±Δσ(k),具体计算公式详见下节求解步骤。
5)计算相对误差值,进行合理性判断。分别将样本n(k)对应的随机变量的期望和标准差的绝对误差值Δμ(k),Δσ(k)与真实期望μ(0)和标准差σ(0)进行对比,计算相对误差值,判断相对误差值与允许的相对误差常数ε 的关系。允许的相对误差常数ε 的取值通常取5%,10%,15%。
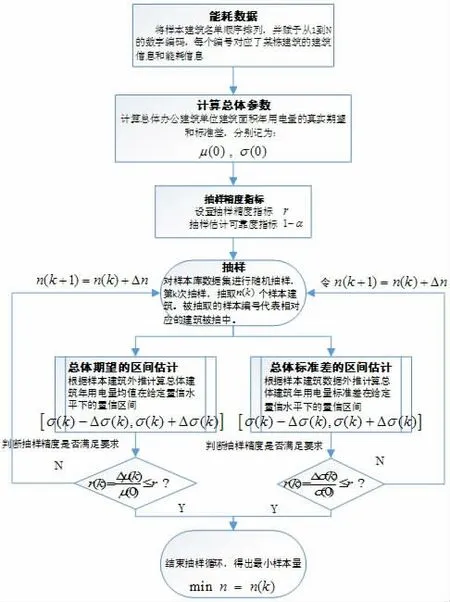
图1 建筑能耗监测下限样本量算法流程
6)如果样本nj(k)对应的建筑能耗特性指标的期望和标准差的联合区间估计满足精度设计要求,则终止抽样循环,认定第k 次抽样的样本量nj(k)为指定时间段P 内,指定建筑群、区域或者地区建筑能耗特性指标评价所需的合理建筑数据量,称为最小样本量。否则,增加抽样规模,继续进行第k+1 次抽样,并设第k+1次抽样的样本量ni(k+1)=ni(k)+Δn,其中Δn 表示抽样步长,为一常数。接着需重复上述步骤第(3)步至第(5)步。
7)讨论不同样本量对估算建筑能耗特性评价指标精度的影响。
8)讨论不同允许误差值对样本量的要求。
其具体流程如图1 所示。
2.2 基于正态总体均值和标准差的联合区间估计建筑样本量模型
根据总体均值和方差公式,可对建筑能耗特性指标估算的最小样本量进行求解,构建面向建筑能耗评价的最小样本量模型。其求解过程如下:
假设指定建筑群、区域或者地区建筑能耗特性指标总体服从正态分布,有,随机变量即样本建筑能耗数据集为为样本建筑数量。一定的置信常数1-α 下,指定建筑群、区域或者地区的建筑能耗特性指标实际期望和方差的联合置信区间推导过程如下:
由于总体方差σ2未知,因此σ2用无偏估计量样本方差S2代替,构造自由度为n-1 的统计量,其中

为方便起见,取
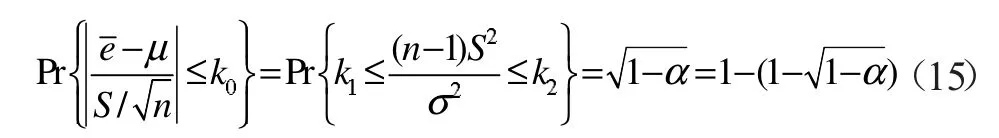
所以

整理得μ2和σ2的联合区间估计域分别为:

因此,建筑能耗特性评价指标监测值均值μ2绝对误差和相对误差分别为:
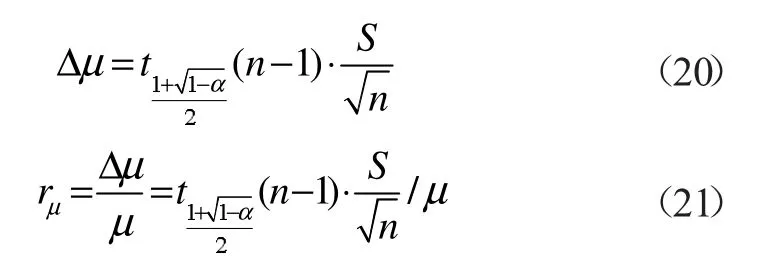
同时,建筑能耗特性评价指标监测值标准差σ 的绝对误差和相对误差可以通过以下方式计算。
由于σ2的置信区间为
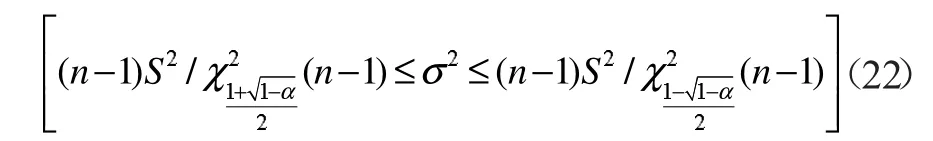
因此σ 的置信区间为
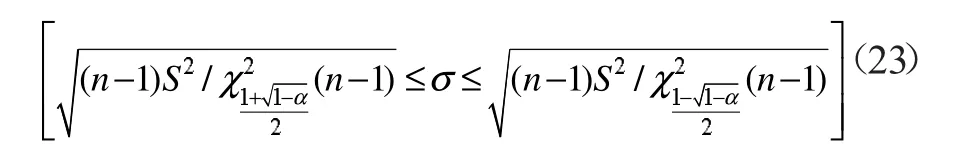
所以标准差σ 的绝对误差和相对误差分别为:

根据rμ,rσ,当被允许的最大相对误差为常数rmax,令rμ≤rmax,rσ≤rmax,分别求得对应的nμ,nσ,并令

可得min n 即为指定建筑群、区域或者地区建筑能耗数据估算所需的合理建筑数据量,称之为最小样本量。
3 算例分析
3.1 建筑能耗数据来源
作者课题组自2010 年始从事建筑节能理论研究及关键技术开发工作,已累计完成覆盖7 省的公共建筑能耗监测工作,累计监测面积达618 万m2。本研究将在已有的辽宁省建筑能耗监测系统平台中完成,该项目涵盖了辽宁省14 个地级市共50 余栋大型公共建筑。该项目覆盖建筑类型多样,包括机关办公建筑,政府办公建筑,大型商场,校园建筑以及医院等,能耗数据类型齐全,为本项研究工作提供了丰富的试验样本数据源。
以辽宁省监测平台公共建筑2014 年能耗数据为例,已有样本建筑50 余栋。为了得到公共建筑合理的样本建筑量,假设该类建筑样本建筑能耗分布基本代表了研究区域总体该类建筑的能耗分布,在不改变原有样本分布的情况下,在训练模型中设置随机种子,扩充样本X 使其约等于研究区域建筑总量,形成新的随机样本训练数据集X,使其仍然服从原样本数据分布,计算X 均值和标准差,研究被抽取的建筑能耗平均值和标准差的变化情况。本算法以R 软件为算法开发工具,R-Studio 为集成开发环境。
3.2 计算分析
3.2.1 单位建筑面积年用电量抽样均值和标准差对样本量的影响
首先分析单位面积年用电量和样本量之间的关系。令显著性水平α 取常数0.05,置信水平为95%,计算样本均值为87.56,标准差为29.06。进入随机抽样,首先选取10 个有效样本建筑数据,然后根据上节算法模型计算每增加一步长(实验步长为1)的样本抽样均值和标准差。
如图2 所示,以双坐标形式表示,其中横坐标表示样本数量,纵坐标分别表示样本能耗抽样均值和标准差可能出现的数值,图中点虚线分别代表样本能耗平均值和标准差,可以看出,样本抽样均值和标准差的可能值,随着样本量的增加而逐渐趋于样本的均值和标准差,当样本量增大到一定程度后,样本抽样均值和方差波动范围稳定并缩小至样本均值和标准差。表明随着被抽取监测的样本建筑数量的增多并且增大到一定的值,用于能耗评价的数据量的增大,用于统计推断的公共建筑的单位建筑面积年用电量对数的期望和标准差波动逐渐减小,当给定波动幅度,从概率学角度来讲,此时用于能耗特性分析的样本数据可以代表总体数据特性,即可确定该幅度对应的样本数量。这说明,用于统计分析的建筑能耗数据样本量的下限值是存在并可确定。
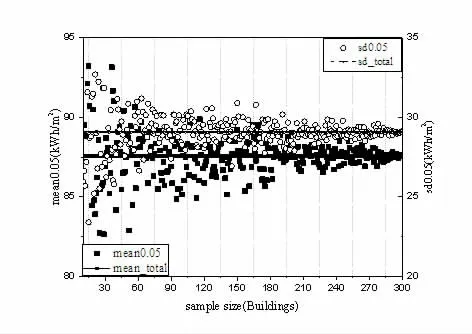
图2 均值,标准差与样本量关系趋势图
3.2.2 误差限对合理样本量取值的影响
令显著性水平α 取常数0.05,置信水平为95%时,分析误差限对样本量下限的影响。绘制样本抽样均值和方差的绝对误差,样本抽样均值和方差的相对误差与样本量趋势图。
从图3 可以看出,绝对误差的变化趋势为:随着被抽样建筑数量的增加,单位面积年耗电量的期望和标准差的绝对误差逐渐降低。当样本量增加到一定临界值时候,绝对误差随着样本量下降的趋势变得缓慢,甚至保持不变。相对误差的变化趋势为:随着被抽取样本建筑数量的增加,单位建筑面积年耗电量的期望和标准差的相对误差逐渐降低。当样本量增加到一定的临界值时候,相对误差随着样本量下降的趋势变得缓慢,而当被抽取样本建筑数量达到一定的临界值时,样本抽样均值和标准差的相对误差均小于20%。当样本量达到该临界值时候,增加样本量对相对误差下降的趋势影响变弱,即认为此时样本建筑能耗情况已经能够代表总体建筑能耗情况,称此时的建筑样本量为最小样本量,当抽样监测建筑数量约等于73,此时抽样均值的相对误差为8%,标准差的相对误差为20%。同时,建筑能耗标准差的相对误差均大于均值的相对误差,这表明标准差的准确估计相对于均值而言更重要,对标准差的准确估计需要更多得到样本建筑。这与建筑能耗数据之间差异很大,数据离散程度较高时需要更多的样本建筑才能反映总体建筑的能耗情况这一实际相符。

图3 抽样误差限与样本量关系趋势图
4 结论
从统计学角度论证了建筑能耗监测下限样本量的存在并求解了最小监测样本量值,使得建筑能耗统计或者监测过程中,可以更科学的确定合理的样本建筑数量,而不是依赖经验。同样,该方法适用范围广,不局限于建筑类型及研究区域气候条件控制,仅受研究对象均值和标准差的影响,对建筑能耗监测规模的确定具有重要推动作用。
猜你喜欢
内蒙古统计(2021年4期)2021-12-06
中学生数理化(高中版.高考数学)(2021年3期)2021-06-09
中国卫生统计(2019年3期)2019-07-10
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
中学生数理化·七年级数学人教版(2019年6期)2019-06-25
建筑与装饰(2018年20期)2018-12-13
中国神经免疫学和神经病学杂志(2018年6期)2018-01-15
初中生世界·九年级(2017年10期)2017-11-08
医学理论与实践(2012年4期)2012-12-09
中国卫生统计(2012年1期)2012-12-04
