
一种抗相似性攻击的匿名保护方法
2020-09-08 08:17徐雅斌
北京信息科技大学学报(自然科学版) 2020年4期
高 帅,徐雅斌,3,武 装
(1.北京信息科技大学 网络文化与数字传播北京市重点实验室,北京 100101;2.北京信息科技大学 计算机学院,北京 100101;3.北京信息科技大学 北京材料基因工程高精尖创新中心,北京 100101)
0 引言
信息化时代,数据分享可以对预测决策、科学研究、企业经营提供强有力的支持[1]。然而,这些数据很可能含有个人信息或敏感数据,如果直接分享有可能会造成个人隐私的泄露。在大数据和人工智能技术快速发展的今天,保护用户隐私不被泄露的同时尽可能减少信息损失成为迫切需要解决的问题[2]。
分类型敏感属性值语义相似[3]也会造成个人隐私信息的泄露。在抵抗相似性攻击方面,王平水等[4]在l多样性匿名的基础上提出了一个(l,c)匿名模型,为敏感属性值设置敏感度,通过敏感度限制敏感属性值在等价类中出现的频率,从而抵抗相似性攻击。张冰等[5]提出了一个(s,l)匿名模型,以敏感集合中非敏感属性值的分布度量敏感值的相关性。赵爽[6]提出了基于敏感度的(a,l)匿名方法,为敏感属性值设置敏感度,并定义等敏感度组的概念,通过对等价类中各等敏感度组设置不同的出现频率,控制敏感属性值的分布,抵抗相似性攻击。张健沛等[7]提出了一个SABukt-closenees模型,该模型在传统的t-closeness模型基础上将EMD距离和KL散度(kullback-leiber divergence)相结合,构建距离度量标准,由此判断属性值的相似度。杨高明等[8]提出了(k,l)-多样性模型将数据集中离散属性和连续属性的联合概率分布作为对象间相似性的度量标准。王海元[9]提出了一个(k-ε)匿名模型,该模型基于分类型属性语义层次树来度量分类型属性的相似性。王良等[10]提出了FVSk-匿名模型,该模型为敏感属性值构建真子树,真子树中任意一层下的节点互不相似,在构建等价类时,敏感属性值分别从每层的不同真子树的节点中选择,从而保证等价类中的敏感属性值互不相似。钟浙云等[11]提出一个(k,l,e)匿名模型,该模型要求在满足k匿名的同时,每个等价类中有l个互不e-相近的敏感属性值。贾俊杰等[12]在k匿名模型的基础上提出了一个(p,k,d)匿名模型,要求等价类在满足k匿名的基础上至少有p个d相异的属性值。蒲东等[13]提出一种个性化(p,a,k)匿名模型,将敏感属性值分为高、中、低3种敏感级别,对不同敏感级别的属性设置不同的约束条件。桂琼等[14]提出一种(r,k)匿名模型,该模型改进等价类中的隐私泄露风险定义,使敏感属性值的泄露风险小于给定的阈值r。程楠楠等[15]提出一种能够抵抗背景知识攻击和相似性攻击的(θ,k)匿名模型,将确定了k值的等价类分成θ组,使其记录在组内保持敏感属性值相似,达到抵抗背景知识攻击的效果;在组间保持敏感属性值相异,达到抵抗相似性攻击的效果。孙进考[16]提出了(k,lI,c)匿名模型,其中lI代表多样性参数I是随着敏感属性值的敏感程度不同而变化的,每个敏感属性值在等价类中出现的频率均不超过阈值c,且等价类中的敏感属性种类不小于该等价类中敏感度最高的敏感属性值对应的l-多样性参数。胡杰[17]提出基于敏感度分组的(l,c)匿名模型,根据敏感程度强弱将敏感属性值划分为多个敏感组,分别为每个敏感组设定不同的约束条件,通过阈值c约束属性值在等价类中出现的最高频率,达到抵抗相似性攻击的目的。
现有的针对敏感属性值相似数据的隐私保护方法存在以下问题:1)通过限制等价类中相异敏感属性值的个数抵抗相似性攻击,难以生成敏感属性值互不相似的等价类;2)为不同的敏感属性值设置的敏感度缺乏设定的依据,且选取困难。
1 总体框架
为了抵抗相似性攻击,本文提出一种抗相似性攻击的匿名模型,研究思路如下:1)敏感属性值聚类。根据敏感属性值构建敏感属性值语义层次树,由此计算敏感属性值相异度e,并根据敏感属性值相异度进行聚类。聚类后可以保证从不同分组中选取出的数据敏感属性值互不相似;2)准标识符聚类。每次从数据量最多的前k组聚类结果中各取1条准标识符距离其最近的记录构成大小为k的初始等价类放到新的集合中,隐匿无法划分到初始等价类中的数据;3)准标识符泛化。对每一类的准标识符进行泛化。
相比现有模型本文的模型具有如下特点:
1)为抵抗相似性攻击,首先按敏感属性值相似度聚类形成多个组,然后从不同等价类选取记录构成敏感属性值互不相似的等价类。相比现有模型中通过限制等价类中相异敏感属性值出现的个数,具有更好的适用性,而且不需要为敏感属性值设置敏感度。
2)按敏感属性值聚类产生的分组S={E1,E2,…,EI},每次从数据量最多的前k个组中取出数据聚类后对S重新降序排序,始终保证前k组中数据量最多,使得在分组数小于k时,剩余分组中数据量最少,降低隐匿率。
2 敏感属性值聚类
2.1 敏感属性语义层次树的构建
在进行敏感属性值相异度聚类之前需要构建敏感属性值语义层次树,根据敏感属性值语义层次树计算敏感属性值的相异度。敏感属性值(sensitive attributes)是与个体隐私相关的属性或者属性组合,如身体状况、薪资、家庭住址等。
以医疗数据为例,首先筛选出数据集中所有敏感属性值,然后构建敏感属性值语义层次树。图1为疾病的语义层次树示例图。树的根节点为疾病属性的全集,树中父节点为子节点的泛化,叶子节点是具体的属性值。
2.2 敏感属性值的相异度聚类
两个敏感属性值间的相异度可用两个叶子节点在语义层次树上的路径距离来度量。例如,图1中胃炎与胃溃疡在语义层次树上距离相近,且他们的父节点也相同,因而相异度较小;而肺炎与胃溃疡在语义层次树上距离较远,到达公共父节点的路径也较长,因而相异度较大。
给定两个叶子节点vi与vj所在层次为di,dj,vi与vj的最小公共节点vc所在层次为dc,如果满足式(1),则称vi与vj相异程度为e。
e=min{(di-dc),(dj-dc)}
(1)
敏感属性值的相异度聚类过程如下:
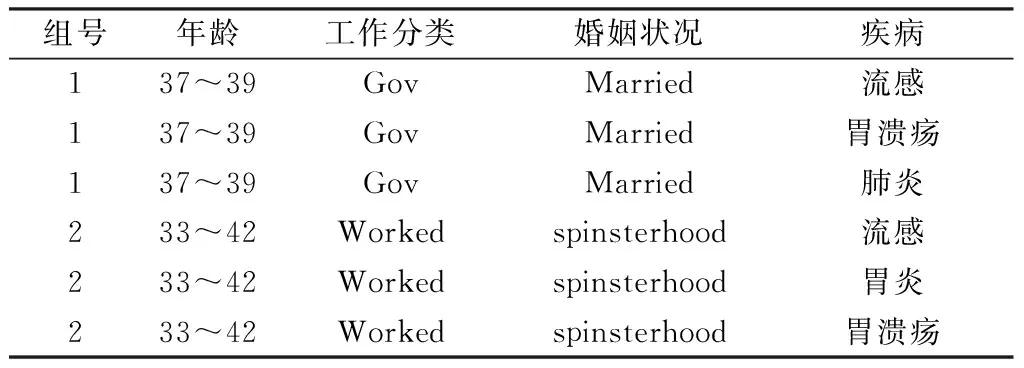
从敏感属性值集合S中选取一个敏感属性值vi,根据敏感属性值语义层次树遍历集合中其余敏感属性值,并计算与vi的相异度。设e=1,若vi与vj的相异度为1,则将敏感属性值为vi、vj的记录划分为一组,然后将vi、vj从集合S中删除。敏感属性值聚类产生的一个数据子集Ei如表1所示。

表1 敏感属性值聚类产生的一个数据子集
3 准标识符聚类
在敏感属性值相似度聚类完成后,还需要对准标识符进行聚类。准标识符(quasi-identifiers,QI)是指不能唯一确定个体身份的属性或者属性组合,但这些属性与其他数据表链接时能确定个体身份。
数据记录之间往往具有内在关系,尤其是当数据
量较大时,某些数据记录在某个准标识符上具有相似的取值。为此我们可以通过聚类,将具有较多共同特征的准标识符属性聚为一类。在进行敏感属性值相异度聚类基础上,可以进一步对准标识符进行聚类。
对准标识符进行聚类的过程如下:将敏感属性值相异度聚类产生的分组Ei按组中数据量降序排列,每次从数据量最多的前k组各取1条准标识符距离最近的数据,构成准标识符距离最近的初始等价类,放入新的集合中。然后对Ei重新排序继续从数据量最多的前k组选取数据,直至分组数小于k。由于每次都从数据量最多的前k组取数据,当剩余分组数小于k时,分组中数据量最少,能够使更多的数据聚类到初始等价类中。
设k=3,准标识符聚类算法如下:
输入:原始数据集T,等价类大小k,相异度e
输出:满足抵抗相似性攻击的匿名表T′
1) 将T中数据按敏感属性值相异度聚类,生成若干组S={E1,E2,…,Ei},按每组中数据量大小降序排序。
2) While(S.size()>=k){
3) 从E1中选取1条记录r1作为质心。
4) For(inti=1;i 5) 从Ei中选取距离质心最近的1条记录 6) }//此时取到了r1,r2,r3三条记录 7) Deleter1,r2,r3fromS 8) 对S={E1,E2,…,Ei}按每组中数据量大小降序排序。} 9) 泛化准标识符。 10) 隐匿无法划分到初始等价类的数据,得到满足抵抗相似性攻击的匿名表T′。 下面以表1中的数据为例,给出对age、workclass、marital-status三个准标识符进行聚类的过程中相似度聚类产生的分组数据量变化情况。此处k=3,Ei的数据量变化情况如表2所示。 表2 准标识符聚类过程中Ei数据量变化 表2为敏感属性值相似度聚类产生的分组Ei中数据量随准标识符聚类数据量变化,准标识符聚类产生5个分组,每个分组中初始数据量分别为5,4,3,3,2。第一次从数据量最多的前3组每组各选1条数据后,每组中的数据量变为了4,3,2,3,2。重新对分组按数据量降序排序,继续选取数据。最后,当分组数小于3时,组中剩余2条数据。相比不对分组进行排序的方法可以降低剩余数据的数量。准标识符聚类的结果如表3所示。 表3 准标识符聚类后的初始等价类 对初始等价类做泛化处理可采用局部泛化的方法,将不同准标识符泛化到不同层次。在具体实现上,将数值型准标识符取最值作为等价类的两个边界值,泛化为[最小值~最大值],将分类型准标识符泛化为等价类中所有属性值的最小公共父节点,泛化后的等价类如表4所示。 表4 满足(3,1)匿名的等价类 从表4可以看出,每组中的数值型属性用当前组属性值的值域表示,分类型属性用当前组中所有属性值的公共父节点表示。每个等价类中的准标识符相同但敏感属性值互不相似,使每条记录遭受相似性攻击的概率为1/k。k为等价类大小,在表4中k=3。 实验采用UCI 机器学习中心的标准Adult数据集,共有48 842 条数据,去除含有空值数据后的可用数据为30 162 条记录,选取其中的age、workclass、education、marital-status、race、sex、occupation七个属性进行实验。选取其中的age、workclass、marital-status、race、sex、education作为准标识符属性,将属性occupation作为敏感属性。属性描述见表5。 实验的硬件环境是Intel(R) Core(TM) i7-4790 CPU @ 3.60GHz,8.0 GB RAM,Windows 10 专业版操作系统,eclipse oxygen3,算法的实现语言为Java。 表5 数据集属性描述 5.2.1 信息损失度 对准标识符进行泛化会造成数据质量的下降,在一定程度上影响数据的可用性,因此必须将数据质量的下降程度控制在一定的范围之内。数据质量的下降程度可以用信息损失度来衡量,信息损失度越小,数据的可用性越高。计算方法如下:首先计算每一个准标识符的信息损失;然后计算每个元组的信息损失;最后,计算整个数据集的信息损失。 数据的类型不同,数据损失度的定义和计算方法也不同。 1)数值型属性信息损失度(information loss of numerical,ILN) 在原始数据表T中,属性N是一个数值属性,一个记录t在N上的取值为v,泛化后记录在N上的取值为v′,则记录t在属性N上的损失度为 (2) 式中|v′|与|v|分别表示v′与v的区间长度。例如age的取值为{23,25,30,35},泛化后用[23,35]表示,则age属性值为{23}的信息损失度为((35-23)-(23-23+1))/(23-23+1)=11。 2)分类型属性信息损失度(information loss of classified,ILC) 对于分类型的属性,可以首先为每个属性构建泛化树,然后通过泛化树计算分类型属性的损失度。例如workclass属性的值域为{private、federal-gov、local-gov、state-gov、sef-emp-inc、sef-emp-not-inc、withou-pay、never-worked},对应的泛化树如图2所示。 下面给出分类型属性的损失度计算方法。 在原始数据表T中,属性C是一个分类属性,一个记录t在C上的取值为c,泛化后的记录在C上的取值为c′,则记录t在属性C上的损失度为 (3) 式中|c′|与|c|分别表示c′与c中包含的元素个数。图2中,workclass的属性值为{local-gov},泛化后可用{gov}表示,则workclass属性的信息损失度为(3-1)/1=2。 有了数值型和分类型数据的信息损失度计算方法就可以计算元组的信息损失度。 设原数据表T中,准标识符中包含数值型属性Ni,分类型属性Ci。元组t泛化后为t′,将元组t泛化到t′的信息损失度IL(information loss)为各个准标识符属性的信息损失度之和,即: (4) 设在数据表T中,元组r1,r2∈T,将r1,r2泛化后的等价类元组记为rg,则r1,r2之间的距离可定义如下: d(r1,r2)=IL(r1,rg)+IL(r2,rg) (5) 设在原始数据表T中有n个元组,则泛化原始数据表T的信息损失被定义为 (6) 5.2.2 隐匿率 隐匿率(SuppRatio)是指隐匿处理的数据记录在数据表所有数据记录中所占的比例: (7) 式中:t为隐匿的记录数量;|T|为数据表总的数据量。隐匿率越小,发布的数据效果越好。 本文将14个occupation属性值划分为7类,取e=1。实验分别用本算法和文献3提出的(a,k)算法、文献18提出的(a,l)-k算法在相同数据集上进行隐私保护处理,然后对比数据集的信息损失度和隐匿率。 文献3提出的(a,k)匿名算法、文献18提出的(a,l)-k算法与本算法都是为抵抗相似性攻击在k-匿名模型的基础上进行改进,都使用聚类算法实现,都使用UCI机器学习中心的adult数据集进行实验。而且实验环境相似的地方较多,因实验环境不同而影响对比实验结果的因素较少,所以选取该算法与本算法进行对比。 5.3.1 信息损失度实验及结果分析 对于不同的k、不同的数据量,两个算法的信息损失度对比实验结果分别如图3、图4所示。 由图3、图4可以看出,在相同的情况下本算法的信息损失度小于(a,k)与(a,l)-k匿名算法。原因如下:本算法每次从数据量最多的分组中按照准标识符间距离聚类,将准标识符距离最近的数据生成初始等价类,所以信息损失度要小于(a,k)与(a,l)-k匿名算法。 5.3.2 隐匿率实验结果及分析 对于不同的k值、不同的数据量,不同算法的隐匿率对比实验结果如图5、图6所示。 由图5、图6可以看出,在相同条件下本算法隐匿率要低于(a,k)与(a,l)-k算法。原因如下:每次按准标识聚类k条数据后,对按敏感属性值聚类产生的分组重新排序,始终从数据量最多的前k组选取数据,当分组数小于k时,每个分组中无法划分到初始等价类的数据量最少,所以其隐匿率要小于(a,k)与(a,l)-k算法。 本文针对抵御敏感属性值相似攻击的隐私保护问题展开研究,在对已有方法进行分析的基础上,提出了(k,e)匿名方法。首先按照敏感属性值相似度聚类,从生成的不同分组中选取记录,生成敏感属性值互不相似的等价类;然后,按照准标识符间的距离聚类,使生成的等价类中记录的准标识符距离最近,由此减少信息损失度。相比已有方法,本方法不需要为敏感属性值设置敏感度,而且可以生成敏感属性值互不相似的等价类更好地抵御相似攻击。实验结果表明,本方法具有较低的信息损失度和隐匿率。 本文主要是针对单一的敏感属性值开展的研究和实验,下一步将研究如何抵御多维敏感属性的相似性攻击。

4 准标识符泛化
5 匿名模型的实现与评估
5.1 实验数据集及实验环境

5.2 评价指标
5.3 实验与结果分析
6 结束语
猜你喜欢
计算机应用(2022年8期)2022-08-24
新高考·高三数学(2022年3期)2022-04-28
北京大学学报(自然科学版)(2021年3期)2021-07-16
台湾农业探索(2020年4期)2020-10-29
电脑爱好者(2020年19期)2020-10-20
计算机系统应用(2020年8期)2020-03-22
台湾农业探索(2019年5期)2019-09-10
中文信息(2017年12期)2018-01-27
高中生·天天向上(2015年11期)2015-10-21
科技与创新(2014年11期)2014-08-21
