
基于关联规则与WPA-BPNN光伏发电功率预测
2020-09-24 01:05肖建于宋香鹏徐成振
湖北民族大学学报(自然科学版) 2020年3期
谷 鹏,肖建于,宋香鹏,徐成振
(淮北师范大学 计算机科学与技术学院,安徽 淮北 235000)
随着全球对环境污染问题的重视,太阳能因为其清洁且丰富被世界大多数国家所利用.然而光伏发电功率受辐照度、温度等气象因素影响较大,导致有较高的随机性和波动性[1].这将导致在接入电网系统时造成冲击,影响电网系统的安全和稳定,因此准确预测光伏发电功率是很有必要的[2].
近年来,光伏发电预测引起了国内外研究学者的兴趣.预测光伏发电功率的点预测方法主要可分为物理方法、统计学方法和元启发式学习方法等[3].物理方法是利用数值天气预报的数据结合光伏物理模型得到发电预测值[4],但需要详细准确的地理信息和天气数据,且物理模型的公式也存在误差.统计学方法是输入辐照度、发电功率等数据,通过曲线拟合、估计参数来建立输入和输出的模型实现预测[5],但需要收集和处理大量数据.元启发式学习方法对输入的样本数据进行训练,得到输入和输出的关系,常见的有神经网络[6-9]、支持向量机[10]、粒子群算法[11]、遗传算法[12-13]、马尔科夫链[14]和卡尔曼滤波算法[15-16]等,但冗余的样本影响预测精度且容易陷入局部极值.吉锌格等[17]利用互信息熵筛选输入样本,提高神经网络预测精度.李正明等[18]利用粒子群算法优化深度信念网络,精度有一定提高.姚仲敏等[19]在预测光伏发电功率时运用遗传算法和粒子群算法优化BP神经网络结构,相比与传统BP神经网络精度更高.陈铁等[20]采用狼群算法优化BP神经网络的初始权值和阈值,对变压器进行故障诊断,改进的BP神经网络诊断精度更高.
综上所述,为了解决因输入与输出关联性小而造成的预测精度差和BP神经网络易陷入局部优值等问题提出基于关联规则与WPA-BPNN的光伏发电功率预测方法.首先利用Apriori算法找出光伏功率样本数据中与发电功率有强关联规则的属性组合作为输入样本,再利用WPA得到BP神经网络的最优初始值,最后两者结合对光伏发电进行预测.基于真实数据对模型进行分析,验证了本模型在预测精度上有着明显提升.
1 关联规则介绍
关联规则是数据库中各属性间的关系,即表现为一个事务发生时频繁产生的项[21].其主要概念描述为:
事务:设T={t1,t2,…,ti}是i个不同项的集合,其中每个事务I是T的非空子集,且每个事务都有单独对应的标记.
关联规则:设X⊆I,Y⊆I且X∩Y=∅,则定义X⟹Y构成一条关联规则,其中X、Y分别是前件和后件.
支持度:X∪Y在事务数据集D中的数量占事务总数的百分比,记为支持度support(X→Y).当值越接近1,表示X和Y的关联程度越高,计算公式为:
(1)
置信度:事务数据集D中,在出现X的同时也出现Y的概率,记为置信度confidence(X→Y).置信度越大则可信度越高,计算公式为:
(2)
频繁项集:当关联规则满足给定的最小支持度时,则称这个项集为频繁项集.
序列关联度和置信度:引入文献[22]中定义的序列关联度和置信度,若对序列A和序列B,其中有n条满足最小支持度的规则,则序列关联度和置信度的计算公式分别为:
(3)
(4)
当满足设定的最小关联度数和置信度,则认为这两个序列具有强关联关系,否则这两个序列无关.而神经网络的输入变量若选用与输出结果关联度小的变量,会降低预测模型的精度,所以利用关联规则找出与输出结果关联性强的变量.
2 WPA优化BP神经网络
2.1 WPA算法原理
狼群算法是模拟狼群的狩猎行为提出的仿生智能算法,将狼分为三种类型,分别为头狼、探狼和猛狼,在狩猎过程中头狼负责决策发令;探狼以猎物为目标在空间中搜索;猛狼根据头狼命令对猎物进行围攻[23].该算法是通过不断迭代搜索找到最优解,其基本原理如下.
第1步:狼群初始化.设狼群在N×D空间内狩猎,N为人工狼总数,D为空间维数.则人工狼i的位置为:
Xi=(xi1,xi2,…,xid),i∈[1,N],d∈[1,D].
(5)
x=xmin+r×(xmax-xmin),r∈[0,1].
(6)
式中,r为区间范围内均匀分布的随机数,xmax和xmin分别表示搜索空间的上下限.
第2步:探狼游走行为.探狼在搜索猎物时执行游走行为,探狼i在第d维的位置公式为:
(7)
式中,h表示探狼游走的个数,stepa表示探狼游走的步长,p表示所处的方向.
第3步:头狼召唤行为.猛狼根据头狼发出的召唤向其靠近,过程中若当猛狼的猎物气味浓度大于头狼,则取代为新的头狼并重新召唤.否则猛狼继续移动直到头狼附近.猛狼在k+1代的进化中第d维的位置公式为:
(8)

第4步:狼群围攻行为.当头狼和猛狼的位置小于dnear时,狼群将发起围攻.距离公式为:
(9)

(10)
式中,stepc为攻击步长,λ为[-1,1]区间的随机数;在围攻中,若感知到猎物气味浓度比原位置强,则更新人工狼的位置.
第5步:狼群更新机制.猎物按照狼的强弱分配,弱小的狼会被淘汰,当淘汰适应度最差的X匹狼,然后随机生成X匹狼,X为[n/(2×β),n/β]区间的随机整数,β为狼群更新时的比例因子.当算法满足精度要求或达到最大迭代次数时,头狼的位置则为最优解否则重复第3步和第4步.
2.2 WPA-BPNN算法步骤
WPA算法优化BP神经网络的初始权值和阈值,就是将每匹狼的位置作为BP神经网络的初始值,利用WPA算法的迭代过程求得BP神经网络的最优权值和阈值,如图1所示,其主要过程如下.

图1 WPA-BPNN算法流程图Fig.1 Flow chart of WPA-BPNN algorithm
第1步:确定神经网络的结构,初始化参数.设置各匹狼的初始位置、狼群数目、探狼的比例、最大迭代数、步长系数、最大游走次数、更新比例系数和距离判定系数.
第2步:根据狼的位置赋值BP神经网络的权值和阈值,通过训练样本对BP神经网络进行训练,将误差作为猎物的气味浓度.
第3步:探狼按照式(7)执行游走行为,当有探狼闻到的气味浓度Yi大于头狼Ylead或者达到最大游走次数,则执行下一步.
第4步:猛狼按照式(8)执行围攻行为,响应头狼的召唤向目标逼近,当Yi>Ylead,则将猛狼取代头狼发起召唤.否则猛狼一直逼近直到di≤dnear,然后执行下一步.
第5步:按照式(9)对参与围攻的狼更新坐标位置.
第6步:判断是否达到最优精度或者最大迭代数,若达成,则输出头狼的坐标作为BP神经网络的初始权值和阈值,否则继续执行第2步.
3 实例分析
3.1试验数据和输入变量的选取
数据集来源于国能日新提供的国内某光伏电站历史数据,采集间隔15 min,收集有风速、风向、温度、湿度、压强、实际辐照度等数据.选取2018年4月至5月的光伏发电功率序列作为预测样本数据,将前1800组作为训练集,后400组作为测试样本集,并将训练集作为关联分析的样本.
光伏发电功率数据是数值型的,而Apriori算法的输入数据需要布尔型,因此需要K-means算法对数据进行离散化处理.由于数据中的数量级不同先对其进行归一化操作.设定聚类数为4,以湿度、辐照度和风速为例,聚类结果如表1~表3所示.
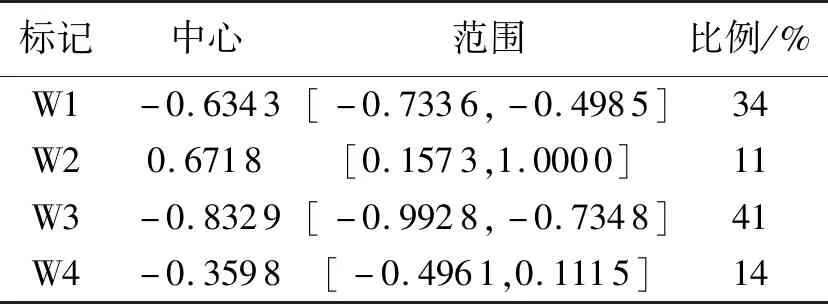
表3 风速聚类结果Tab.3 Wind speed clustering results
从表1、2、3中可以看出,湿度、辐照度和风速分别被聚类成四个类,利用H、R、W将聚类结果符号化表示便于进行序列关联规则分析.将最终序列符号化的结果利用Apriori算法设定最小支持度为0.05,最小置信度为0.9,找出项集中的频繁3项集,如表4所示.再利用式(3)和式(4)计算序列关联度和置信度,设定最小关联度为0.1,序列最小置信度序列为0.9.因要选用三个变量作为BP神经网络的输入,所以筛选出三个因素组合对应发电功率的关联规则,结果如表5所示.

表5 序列关联规则Tab.5 Sequential association rules

表4 关联规则Tab.4 Association rules

表1 湿度聚类结果Tab.1 Humidity clustering results

表2 辐照度聚类结果Tab.2 Irradiance clustering results
由表中结果可以得出三元素组合中温度、辐照度和湿度的组合与光伏发电功率关联度最大,序列置信度达到0.95代表这条关联规则可信度高,可用作BP神经网络的输入变量.
3.2 试验结果对比分析
利用WPA-BPNN算法对光伏发电功率进行预测,将温度、辐照度和湿度作为输入,隐藏层神经元数量经试验由表6所示,当数量为7时训练误差和测试误差最好,确定BP神经网络模型为3-7-1的网络结构.狼群数目设置为120,最大迭代次数设为200,最大游走次数设为20,探狼比设为4,距离判断设为500,步长设为1 000,更新比例设为6.

表6 隐藏层测试结果Tab.6 Hidden layer test results
预测模型在Matlab R2020a环境下运行,为了准确验证所提预测模型的精度,选择与传统BP神经网络模型进行对比,将不使用强关联规则作为输入的设为模型1,使用强关联规则作为输入的设为模型2,本文所提模型设为模型3.利用训练好的三个模型分别对2018年5月27日和5月30日两种天气情况进行试验预测,图2和图3给出了各模型预测对比结果,图4和图5给出了各模型预测误差对比结果.

图4 稳定情况误差对比 图5复杂情况误差对比 Fig.4 Comparison of stability error Fig.5 Error comparison in complex situations

图2 稳定天气预测对比 图3复杂天气预测对比Fig.2 Comparison of stable weather forecasts Fig.3 Comparison of complex weather forecasts
使用平均百分比误差EMAPE和均方根误差ERMSE作为评价模型的标准,误差值越低则模型精度越高.其公式为:
(11)
(12)
式中pai代表第i个时刻的实际光伏发电功率值,pi代表第i个时刻预测的光伏发电功率值,k代表数据总数.
预测结果的评价如表7和表8所示,由表中结果可知本文所提模型3的方法精度比模型1和模型2都要高.模型1中当不用强关联规则作为输入变量时,由于变量中混有与光伏发电功率相关性较小的变量,干扰BP神经网络的训练造成预测精度差,由图可以看出预测值总体偏离实际功率值,其在稳定天气中,MAPE%为16.56,RMSE%为2.269,精度一般,而在复杂天气中预测精度更差,MAPE%为44.552 8,RMSE%为3.900 1,预测结果没有实用价值;模型2中在没有引入WPA算法优化的情况下,由图可以看出预测值出现较大波动,影响了整体精度,在稳定天气中,MAPE%为10.417 1,RMSE%为1.179 1,相对于模型1有一定提升,而在复杂天气中,MAPE%为20.643,RMSE%为2.468 3,误差较大;而且模型3中,波动性相对与模型1和模型2较小,很少出现30%以上的误差,预测值更贴近真实发电功率值,在稳定天气中,MAPE%为6.253 8,RMSE%为0.492 5,精度较高,而在复杂天气中,MAPE%为10.689 6,RMSE%为1.896,误差较模型1和模型2有很大提升.

表8 复杂天气模型评估结果Tab.8 Evaluation results of complex weather model
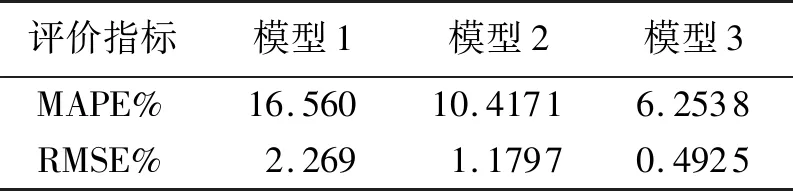
表7 稳定天气模型评估结果Tab.7 Assessment results of stable weather model
根据以上情况分析,在复杂天气情况下,误差减少最为明显,MAPE%最大达到34%.
4 结语
光伏发电功率短期预测对电网稳定地纳电具有重要意义.因此,本文提出利用狼群算法优化BP神经网络,即用狼群算法求得BP神经网络的最优初始权值和阈值,并利用关联规则算法选择BP神经网络的输入变量.通过仿真试验可知:利用关联规则算法选取BP神经网络的输入变量,可以得到与输出结果关联性强的因素,减少干扰因素,对神经网络的训练更具针对性,从而提高BP神经网络的精准度.本文利用狼群算法与BP神经网络相结合,利用狼群算法选取BP神经网络的最优权值和阈值,可以避免神经网络因不当的初始值导致陷入局部最优解和收敛速度慢的问题.
猜你喜欢
计算机工程与应用(2022年15期)2022-08-09
小型微型计算机系统(2022年4期)2022-05-09
核科学与工程(2021年4期)2022-01-12
新世纪智能(数学备考)(2021年9期)2021-11-24
小读者·爱读写(2021年9期)2021-09-26
新少年(2020年10期)2020-10-30
当代陕西(2019年15期)2019-09-02
乐活老年(2019年5期)2019-07-25
计算机应用(2018年5期)2018-07-25
学苑创造·A版(2018年11期)2018-02-01
