
短文本特征的组合加权方法
2020-09-26 08:15谭有新滕少华
广东工业大学学报 2020年5期
谭有新,滕少华
(广东工业大学 计算机学院,广东 广州 510006)
最近,网络评论的日益增加使得文本信息已经成为一个潜力巨大的宝藏[1],例如电影评论,很多公司和机构通过分析这些评论来了解顾客的偏好和电影的质量[2-3]。需要了解和利用这些评论,就需要情感分析。情感分析是自然语言处理的研究领域,它从文本中提取和分析观点、情感和主观性[4]。由于满足分析这些评论的重要性,它引起了越来越多的兴趣,并成为一个活跃的研究主题[5]。而文本分类(Text Classification,TC)的任务就是有效分析大量数据,最终将文本内容分为不同类别,它通常被用于情感分析[6]。
TC是将文档形式的每段文本自动分类为预定义类别的过程[6]。通常,它包括4个阶段:(1) 文档表示;(2) 特征选择; (3) 特征加权; (4) 最终分类。TC面临两个主要问题,第一个问题是如何从特征空间中有效选择有用的特征。对于使用特征加权进行TC,已经进行了广泛的研究,普遍的特征加权是基于文档频率进行加权。在特征本身对文档情感的意义上进行研究的较少。
考虑到以上的挑战,本文认为如果根据特征对于文本情感的贡献度来进行特征的选择会从特征空间中更加有效地选择有用的特征。并且提出一种特征加权方法,该方法结合特征在文档中的重要性和情感中的贡献度对特征进行加权,能够更好地表示该特征的意义,有效地提高了模型的分类能力。
1 相关工作
情感分析是文本挖掘的一个子领域[7]。近年来,由于论坛、博客、电子商务、网站、新闻报道以及其他社交网站的大量出现,情感分析引起了研究人员的极大兴趣[8-11];尤其是客户对上述网站上的产品和服务的在线评论对传统的决策流程产生了重大影响[12-13]。因此,情感分析可帮助决策人员更好地了解和探索其客户对产品或服务的观点。实际上,由于各种原因,个人和公司总是对他人的观点感兴趣。例如,当一个人想要购买新产品时,他可能首先从先前购买过该产品的购买者那里获取意见,然后,基于这些评论,他将决定是否购买该产品[14]。同样,销售产品和服务的公司也要注意消费者对其产品的评论,这些评论涉及关于客户关注的问题、商品信息和用户喜好[15]。此外,在另一项研究中观察到,与传统的客户调查方法相比,基于Web的评论(即情感分析)具有易于访问且成本低的优势。
特别是,情感分析是识别目标群体中对文档中表达主题的观点是肯定还是否定的过程。情感分析通常将评论分为正面评论或负面评论[16]。负面评论(即客户投诉)传达了有关客户对产品/服务不满意的原因的重要信息[17]。因此,情感分析有助于保持客户。在不同的论坛或博客上阅读所有观点不仅困难,而且公司要管理大量评论以评估其产品或服务也具有挑战性。因此,有必要研究出可以提高此类非结构化评价的准确性的方法[18]。
文本的情感分析中面临2个主要问题:(1) 特征选择,即如何从特征空间中有效选择有用的特征。由于训练数据通常很庞大,因此减小特征空间的尺寸有助于节省大量的计算成本。(2) 特征加权,与特征选择(被选择的特征均被平等对待)不同,特征加权中特征的重要性被用作确定特征权重的标准。
特征选择方法分为过滤方法、包装方法和嵌入方法[19]。过滤方法使用变量排名作为按顺序选择变量的主要标准,因此也可以称为排序方法。特征排序的优点是计算量小,避免过度拟合,并被证明对于某些数据集有不俗的表现[20-22]。排序方法的缺点之一是所选子集可能不是最佳的,因为可能获得冗余子集。由于忽略了基础学习算法,因此找到合适的学习算法也变得很困难[23]。同样,没有理想的方法来选择特征空间的尺寸,包装方法使用预测变量作为黑盒,并使用预测变量性能作为目标函数来评估变量子集。自评估以来 2n子集成为NP(Non-deterministic Polynomial)难题,通过采用启发式搜索子集的搜索算法找到次优子集。可以使用许多搜索算法来找到变量的子集,该子集可以使目标功能(即分类性能)最大化。嵌入方法希望减少包装方法中用于完成重新分类的不同子集的计算时间[24-25],主要方法是将特征选择纳入训练过程的一部分。包装方法和嵌入方法容易得到过拟合的结果,但随机森林由于其3个随机过程(产生决策树的样本是随机生成,构建决策树的特征值是随机选取,树产生过程中裂变的时候是选择N个最佳方向中的随机一个裂变的)符合强大数定理,在一定程度上消除了过拟合。
在传统的文本分类任务中,TF-IDF(Term Frequency-Inverse Document Frequency)等传统的无监督术语加权方案被广泛使用。研究人员还使用包括卡方校验Chi-Square在内的特征选择方法、信息增益IG(Information Gain)、优势比OR(Odds Ratio)、相关性Correlation、互信息MI(Mutual Information)来计算特征权重。有实验研究了加权因子(例如特征选择函数)如何影响分类性能[26],使用IG和增益比GR(Gain Ratio)来替换TF-IDF方案中的IDF(Inverse Document Frequency)值的实验结果表明,这些方法并不比TFIDF好[24]。有人提出了混合加权方法,基于机器学习和词典的方式进行加权,发现效果好于单纯的加权方式[27]。
与传统的文本分类相比,在情感分类领域,特征加权方案的研究相对较少。2008年最先将机器学习方法用于情感分类[9],并通过使用不同的特征加权方案比较了支持向量机、最大熵和朴素贝叶斯分类器的性能。研究人员分析了信息检索领域中使用的各种特征加权方案对情感分析的影响[26],选择了TF-IDF和其他经典加权方案,基于轻度评论进行广泛的实验,当使用文档频率信息的归一化对数比率作为特征权重并使用SVM分类器时在一系列数据集上获得良好的性能[28]。有研究使用优化方法获得特征权重的值[29],通过使用不同类别的文档中特征术语的统计信息。邓志鸿等[2]提出一个新的情感词的监督术语加权方案,称为ITD*MI(Importance of a Term in a Document* Mutual Information)算法,这种监督术语加权方案基于两个基本因素:文档中术语的重要性ITD(Importance of a Term in a Document)和表达情感的术语的重要性ITS(Importance of a Term for expressing Sentiment)。与以前的源自信息检索的无监督术语加权方案相比,该方案可以充分利用可用的标签信息为术语分配适当的权重。
2 短文本分类方法
本文基于随机森林来设计特征选择算法,采用袋外数据OOB (Out of Bag)做测试集。CWSTF方法是利用重抽样技术构造多个数据集,分别在每个数据集上进行特征重要性度量,然后给每个特征重要性度量加上权值,得出其重要度,并进行特征的选择。不采用主成分分析等方法进行降维是为了更好地保留原特征的物理意义。根据随机森林得到的重要度进行特征的选择,一方面是为了减小后续分类的计算时间,另一方面可以减少复杂度。文本情感分类中特征的加权一般考虑两个影响因子,一个是该特征在文档中的重要度,另一个是该特征在情感分类上的重要度。将两者结合起来进行特征加权,最后使用SVM等分类器进行分类计算,评判特征性能。
2.1 经典方法
在这里简要描述3种用于特征选择的方法和1种特征提取的方法,即信息增益IG、相关性Correlation、卡方校验Chi-Square和混合特征提取。
2.1.1 信息增益IG
在文本分类中利用信息增益进行特征选择,信息增益体现了特征的重要性,信息增益越大说明该特征越重要。
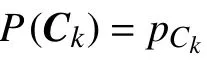
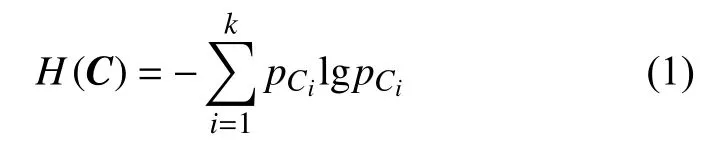
条件熵的计算为

其中T 表示一个单词。
则总的信息增益计算为

信息熵体现了信息的不确定程度,熵越大表示特征越不稳定,表示类别之间的数据差别越大;条件熵体现了根据该特征分类后的不确定程度,越小说明分类后越稳定。
2.1.2 相关性Correlation
Correlation估计特征子集并对特征子集而不是单个特征进行排序。
启发式方程:

Correlation的核心是采用启发的方式评估特征子集的价值。启发方式基于的假设:好的特征子集包含与类高度相关的特征,但特征之间彼此不相关。
Ms为包含k个特征的特征子集s的启发式矩阵,rcf是特征与类的平均相关性,rff是特征与特征的平均相关性。
2.1.3 卡方校验Chi-Square
卡方检验的公式如式(5)所示,其中A为实际值,T为理论值。

D值越大,说明两个变量越不可能是独立无关的。对于特征变量x1,x2,x3,···,xn,以及分类变量y,只需要计算D(x1,y)、 D(x2,y)、···、D(xn,y),并按照 D的值从大到小将特征排序,然后选择阈值,大于阈值的特征留下,小于阈值的特征删除,这样就可以筛选出一组特征子集。
2.1.4 混合特征提取
基于机器学习的特征提取方法使用常见的词袋技术,其中列对应于单词,行对应于权重值,例如术语频率TF(Term Frequency)和TF-IDF。基于词汇的特征提取方法抽取了4种不同的功能,它们是:正字数、负字数、正涵义计数和负涵义计数。将两者混合能得到一个新的特征集。
2.2 短文本特征的组合加权方法
本文设计了一种基于随机森林的短文本特征化方法,图1表示了该分类模型的一个流程。使用监督学习对短文本特征进行加权选择和权重改变,使其增加对分类器的分类能力。
Part A中的特征经过随机森林的权重评估后进行特征选择,以筛选出特征子集,具体流程如图2所示。

图1 短文本特征的组合加权方法过程Fig.1 Process of combined weighting method for short text features

图2 基于随机森林的特征选择流程Fig.2 Feature selection process based on Random Forest
Part B中的特征将前一部分经过随机森林评估的权重作为特征的情感贡献度,与特征子集中单词的文本重要度相结合作为特征的最终权重进行加权。
2.2.1 数据预处理
一般网络文本集合中含有大量的噪音,在这些噪音的影响下,进行文本的情感分析会受到干扰,得到的结果正确率也会降低。因此在进行情感分析之前必须要对文本数据集进行一系列的预处理工作。
预处理工作包括4步:(1) 去除无意义标注;(2) 删除停用词;(3) 词形还原;(4) 构造词袋模型。
预处理首先去除了HTML标签。HTML是网络评论中常见的标签,而且与文字等混杂在一起,将此标签删除是必要的。其次,在文本中一般的标点符号和数字也会占用很大的空间,而“,”“。”“1”“2”等标点符号和数字不会影响用户的情绪分析,因此数字和标点符号也被删除。
文本中出现频率很高,但实际意义又不大的词。这一类主要包括了语气助词、介词、连词等,通常自身并无明确意义,只有将其放入一个完整的句子中才有一定作用的词语,如常见的“in”“and”“then”之类。文档中如果大量使用停用词容易对页面中的有效信息造成噪音干扰,所以在运算之前都要对所索引的信息进行消除噪音的处理。在第二步中也将其删除。
文本中有许多单词表示同一个意思但是其时态或者形式不同,这些单词不会表现为词根的形式,但是如果将它们分为不同的单词又会占用大量的计算空间并且会让每个单词出现的概率更加小。例如,“studied”“studying”等属于同一个意思但是时态不同,需要将它们都转化为“study”。这个过程被称为词形还原,其中单词的无效结尾通过将借助词汇的词根形式去除。此外,由于计算大小的限制,取出8 000个单词作为其特征词,预处理数据集用于下一阶段的特征提取。
最后使用了词袋模型,选择使用该模型的原因是因为它能更加形象地表示一个文档的构成,例如一句话“this movie is very fantastic!”,本文将其表示为w1=“this”,w2=“movie”,以此类推,一句话表示为S={w1,w2,···,wM}, M表示一句话中的词汇总数。一个包含 K 句话的数据集最终被表示为一个矩阵Q(K×M)。
2.2.2 基于随机森林的特征选择
本文使用随机森林来作为特征选择的方法。要确定选择的特征,首先要计算出特征在文本情感的分析中发挥的作用,即特征在文本中的情感贡献度。
首先对原始数据进行Bootstrap取样,为了保证分类的正确率,CWSTF经过多次重复取样构造多个数据集。设原始的数据集为 D,特征个数为 N,经过重抽样后的数据集为Repeated Sampling_D (简记为RS_D),数据集个数为 M。在每个RS_D数据集上构造一棵决策树,首先需要知道这个数据集中的正负情感的文本概率分布为
P(X=xi)=pi,i=1,2
根据式(1),其正负文本 X的熵定义为

文本中的特征Y 与正负文本 X的联合分布为
P(X=xi,Y=yj)=pij,i=1,2;j=1,2,···,m
根据式(2),在文本类别确定的情况下文本中每个特征的条件熵为

H(X)表示对文本 X分类的不准确性,H(Y|X)则表示在特征Y 给定的情况下对文本分类的不准确性。当本文评判该特征对于文本的分类起到好的效果时,选择对两者的差值进行比较,两者的差越大,则该特征具有更强的分类能力,通过信息增益G(X,Y)来选择第一个分支节点,见式(7)。
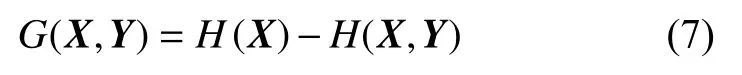
由于普通的决策树容易产生过拟合的结果,所以在每个节点的选取中只随机选择n(n <N)个特征来作为比较。决策树的生成如下。
输入:数据集RS_D,特征集合Y
输出:决策树T
(1) 若RS_D中所有实例属于同一类,则T 为单节点数,并将类别作为该节点的类标记,返回T ;
(2) 否则,随机取出n(n <N)个特征,按照式(7)中计算 Y中各特征对RS_D的信息增益,选择信息增益最大的特征Y g;
(3) 对Yg的每一个可能值 yj,依Yg=yj将RS_D分割为若干个非空子集RS_Dj,将RS_Dj中实例数最大的类作为标记,构建子节点,由节点及其子节点构成树T ,返回T ;
(4) 对于第 M个子节点,以RS_Dj为训练集,以Y-{Yg}为特征集,递归调用步骤(1)~步骤(3),得到子树Tj,返回Tj;
(5) 当所有特征都成为节点或者{Yg}的个数为n 时,结束递归,返回T 。
这样就能为一个RS_D数据集构造一棵决策树。依次对 M个RS_D数据集用同样的过程生成决策树,就会有 M个不同的RS_D数据集产生 M棵决策树。如图1所示,采用多数投票方法对结果进行预测。根据决策树的预测结果可以获得一个T×(M+2)的矩阵,矩阵的每行代表着要预测的样本,矩阵的前 M列分别表示 M棵决策树对每个样本的预测结果,第M+1列代表前 M棵决策树对每个样本综合投票的结果(前 M列中每行中占多数的样本分类结果判定为该样本的最终分类结果放在第M+1列),第M+2列代表测试数据的真实分类结果。则第i棵决策树的可信度可由式(8)得到:

其中Si表示第i棵决策树的权重, Fij表示第i棵决策树对第j个样本的预测结果, Ej表示所有决策树对第j个样本的集成预测结果。
由于决策树对于OOB的预测能力不一,所以设置一个阈值σ ,当Si的值小于σ 时,认为这棵树的构造不符合本文的需要,即丢弃不用。然后再使用剩下的树对特征进行加权。阈值的选取过小设置就没有意义,过大会造成树的样本数太少。根据经验,本文中选择σ =0.6。阈值判断示意图如图3所示。

图3 阈值判定示意图Fig.3 Schematic diagram of threshold determination
通过给特征添加噪声对比分类正确率,得到一个特征的重要性度量。 M个RS_D数据集可以得到M个特征的重要性度量,但是每个RS_D数据所获得的特征重要性的权重不同。因此CWSTF方法的主要步骤就是计算特征的重要性度量值和权重的大小。
第j个属性的特征重要性度量是由R和Rj的差值所决定的,其中R表示对特征添加噪声前的分类正样本的个数, Rj表示对特征添加噪声后的分类正确的个数。本文基于OOB样本数据来做特征的重要性度量,为了避免OOB数据类别严重不均给算法结果带来的影响,采用 K折交叉验证来计算特征的重要性度量值。由于采用的是五折交叉验证,每个RS_D数据集分成5份,5份数据集交叉作为测试数据集,因此在同一RS_D数据集上,R 和Rj需要分别计算5次,最后第j个特征的重要性度量 Iij是由5次产生的平均差值来决定的。
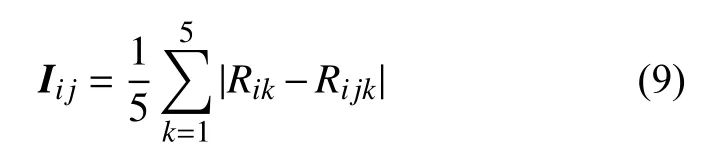
其中i代表第i 个RS_D数据集, j代表第j个特征,k 代表第k层数据。
从式(7)和式(8)可以得出每一棵决策树的可信度和每棵树中每一个特征的重要性度量,因为在性能不同的树中相同特征的表现能力可能不同,所以要得出最终的特征情感贡献度需要将两者结合起来。最终的特征情感贡献度 Zj可通过式(10)计算:
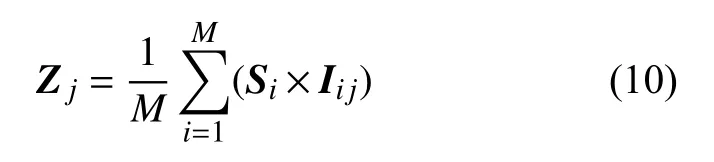
选择后的特征个数为 γN,γ 为按特征重要度由

3 实验及分析
3.1 实验环境
本次实验一共采用2个数据集。第1个数据集是IMDb Movie Review数据集(简称为IMDB数据集)[27]。IMDB数据集有50 000个英文评论,其中积极评论25 000个,消极评论25 000个。由于大小原因,本文取出5 000条评论。其中正面评论2 310条,负面评论2 690条。本文将两种数据集中75%的数据用作训练,25%的数据用于测试。第2个数据集是STS-Gold数据集[31]。STSGold数据集包含3 000条推文,每条推文都被标记为5类之一:负面、正面、中性,混合或其他。本文仅使用了2类推文(消极和正面),总共使用了2 032条推文。其中包含632条正面评论,1 400条负面评论。本文将75%的数据集用作训练,25%的数据集用作测试。
本实验是在Windows操作系统的计算机上运行,采用的语言是Python,版本号为3.7.4,最后结果使用正确率F值作为本文方法性能的评价标准。输入的特征集尺寸 γ从1.25%~100%,分析其特征子集对分类效果的影响。
分类器使用SVM、NB、ME、KNN机器学习方法。
3.2 特征重要度评估
效果较好的特征的组合加权法策略是对词频标准化后的ITD(特征在文档中的重要性ITD由该特征在该文档中出现的次数以及该文档所包含特征的最大词频决定)和基于交互信息的ITS结合[2]。
选取同样是结合情感重要度的ITD*MI算法与本文的方法做比较。为了更直观地对比ITD*MI算法和本文的方法,抽出了经过2种方法加权后重要度排名前10位的特征。ITD*MI算法得到的重要度排名前10位的词及其权重,见表1。经过CWSTF方法筛选之后得到的重要度排名前10位的词及其权重,见表2。
从表1中可以看出根据ITD*MI算法,排名最靠前的10个(甚至前几十个)没有太大的具体意义。也就是说,这类特征往往获得非常的权值,而事实上它们在表达情感上不一定真的重要。而表2显示,根据本文的方法筛选出来的特征都含有非常明显的情感倾向,而且含有具体的含义,大概率能表现一个文档的情感倾向。
3.3 实验结果与比较
本节显示了本文提出的方法在IMDB数据集和STS-GOLD数据集得出的实验结果,并与其他方法进行了比较。
(1) 本部分介绍IMDB数据集使用各种方法获得的结果的分析,CWSTF方法下的不同分类器评估结果以及与Kumar的混合功能方法[27]作比较。
图4显示了CWSTF方法整体表现优于使用混合功能的特征选择方案在不同分类器下的分类效果。在ME分类器下正确率略弱于Correlation方法,但是其他均优于混合方法。

表1 根据ITD*MI算法获得的特征排名(前10)Table 1 Feature ranking based on ITD * MI algorithm(top ten)

表2 根据CWSTF方法获得的特征排名(前10)Table 2 Feature ranking obtained by the CWSTF method (top ten)

图4 IMDB数据集中使用不同方法的正确率Fig.4 Accuracy using different methods in IMDB dataset
图5~8显示的是使用IG、Correlation、Chi Square和CWSTF不同特征选择方案在SVM、NB、ME、KNN中获得的正确率, γ为按特征重要度由高到低的占比,0.125 ≤γ ≤1。横坐标表示特征子集在总特征集中的占比。
通过图5~8,可以看出CWSTF方法下的结果。
① NB分类器在γ值为0.6时正确率达到63.89%,所以使用NB分类器时只需使用60%的特征子集就可以很好地表示整个数据集,减少了40%的特征表示空间。
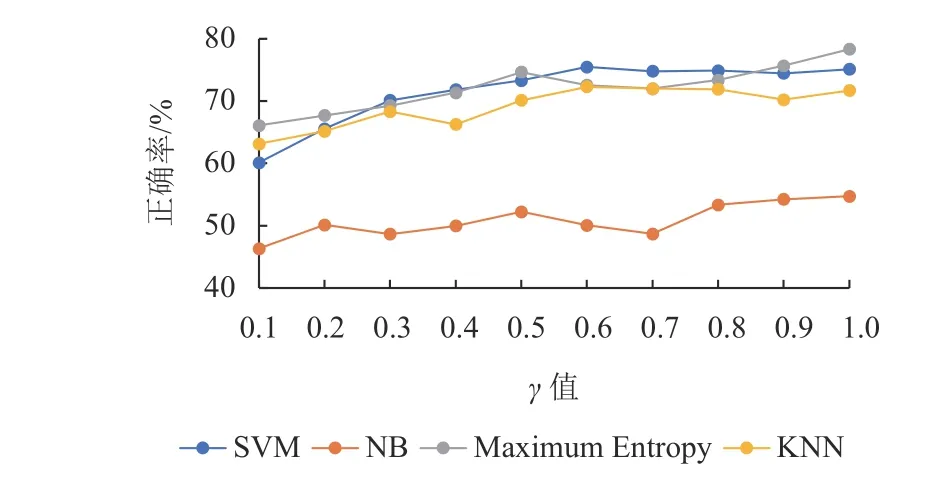
图5 使用IG的分类器随γ 值变化的正确率Fig.5 The accuracy of the classifier using IG as a function of γ value

图6 使用Correlation的分类器随γ值变化的正确率Fig.6 The accuracy of the classifier using Correlation as a function of γ value

图7 使用Chi Square的分类器随γ值变化的正确率Fig.7 The accuracy of the classifier using Chi Square as a function of γ value

图8 使用CWSTF的分类器随γ值变化的正确率Fig.8 The accuracy of the classifier using CWSTF as a function of γ value
② ME分类器在特征子集较小时分类效果较差,在 γ值为0.6时正确率达到较高值,正确率为81.34%,减少了40%的特征表示空间。
③ KNN分类器在γ 值为1的情况下达到最好的正确率为76.36%。
④ SVM分类器在 γ值为0.5的情况下达到最高的正确率为82.38%。
表3~5总结的结果对比Kumar的混合功能方法,通过考虑特征子集的数目为2 000,5 000,8 000时进行对比达到的正确率和F值。加粗的数值表示在相同分类器下不同特征选择方法所获得的最好结果。

表3 特征数为2 000的方法准确度和F值对比Table 3 Comparison of method accuracy and F value with 2 000 feature number

表4 特征数为5 000的方法准确度和F值对比Table 4 Comparison of method accuracy and F value with 5 000 feature number

表5 特征数为8 000的方法准确度和F值对比Table 5 Comparison of method accuracy and F value with 8 000 feature number
从表3可以看出本文的方法在特征数为2 000的情况下使用SVM分类器会优于其他的3种方法,但是在NB、ME、KNN分类器下会略差于其他几种方法。
从表4可以看出本文的方法在特征数为5 000的情况下使用SVM和NB分类器会优于其他的3种方法,但是在ME、KNN分类器下会略差于其他几种方法。
从表5可以看出本文的方法在特征数为8 000的情况下使用SVM、NB和ME分类器会优于其他的3种方法,但是在KNN分类器下会略差于其他几种方法。整体来说优于其他3种方法。
总之,本文的方法在SVM、NB和KNN3种分类下最高的正确率和F值都高于其他3种方法。
(2) 本部分介绍STS-GOLD数据集使用各种方法获得的结果的分析,CWSTF方法下的不同分类器评估结果以及与Kumar的混合功能方法[27]作比较。
图9显示了CWSTF方法整体表现优于使用混合功能的特征选择方案在不同分类器下的分类效果。在KNN和NB分类器下正确率略弱于Chi Square方法,但是其他均优于混合方法。
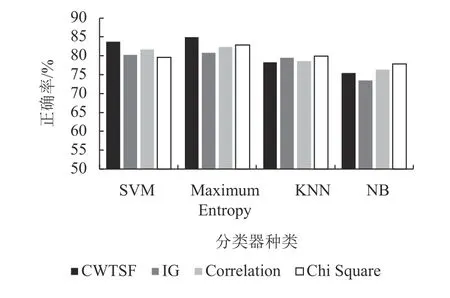
图9 STS-GOLD数据集中使用不同方法的正确率Fig.9 Accuracy using different methods in STS-GOLD dataset
图10~13显示的是使用IG、Correlation、Chi Square和CWSTF不同特征选择方案在SVM、NB、ME、KNN中获得的正确率, γ为按特征重要度由高到低的占比,0.125 ≤γ ≤1。横坐标表示特征子集在总特征集中的占比。
通过图10~13,可以看出CWSTF方法下的结果。
① NB分类器在 γ值为1时正确率达到75.43%,但是其在γ值为0.4时正确率能达到73%左右,表明其特征子集的表达能力还是较强。
② ME分类器在特征子集较小时分类效果较差,在γ值为0.5时正确率达到较高值,正确率为84.90%,减少了50%的特征表示空间。
③ KNN分类器在 γ值为0.7的情况下达到最好的正确率为78.28%,并且其特征子集的尺寸空间减少了30%。

图10 使用IG的分类器随γ 值变化的正确率Fig.10 The accuracy of the classifier using IG as a function of γ value

图11 使用Correlation的分类器随γ值变化的正确率Fig.11 The accuracy of the classifier using Correlation as a function of γ value

图12 使用Chi Square的分类器随γ值变化的正确率Fig.12 The accuracy of the classifier using Chi Square as a function of γ value
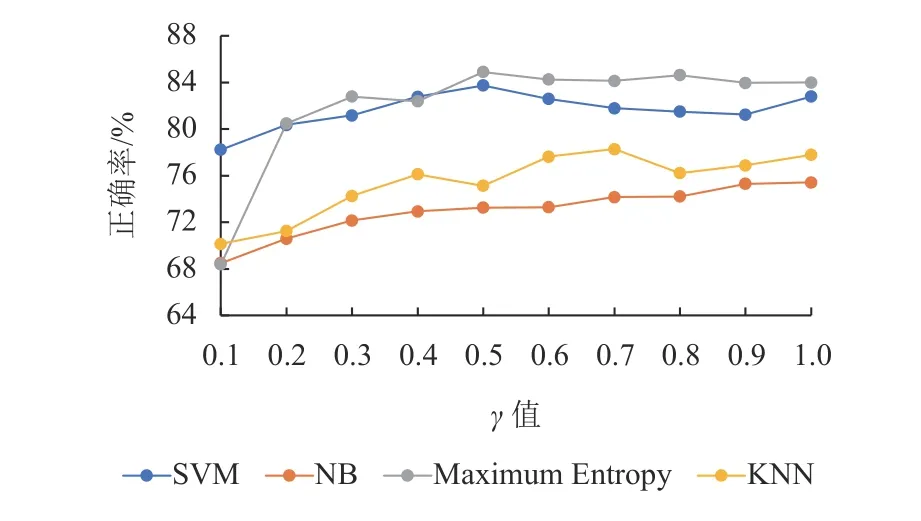
图13 使用CWSTF的分类器随γ值变化的正确率Fig.13 The accuracy of the classifier using CWSTF as a function of γ value
④ SVM分类器在 γ值为0.5的情况下达到最高的正确率为83.74%。
表6~8总结的结果对比Kumar的混合功能方法,通过考虑特征子集的数目为2 000、5 000、8 000时进行对比达到的正确率和F值。加粗数值表示在相同分类器下不同特征选择方法所能获得的最好结果。

表6 特征数为2 000的方法准确度和F值对比Table 6 Comparison of method accuracy and F value with 2 000 feature number

表7 特征数为5 000的方法准确度和F值对比Table 7 Comparison of method accuracy and F value with 5 000 feature number

表8 特征数为8 000的方法准确度和F值对比Table 8 Comparison of method accuracy and F value with 8 000 feature number
从表6可以看出本文的方法在特征数为2 000的情况下使用SVM和ME分类器会优于其他的3种方法。
从表7可以看出本文的方法在特征数为5 000的情况下使用SVM和ME分类器会优于其他的3种方法,但是在KNN和NB分类器下会略差于其他几种方法。
从表8可以看出本文的方法在特征数为8 000的情况下使用SVM和ME分类器会优于其他的3种方法。
总的来说,本文的方法在SVM和ME 2种分类下最高的正确率和F值都高于其他3种方法。在其他2种分类器下结果与其他方法的最高正确率相差不大。
4 结论与展望
本文提出一种短文本特征的组合加权方法,通过特征对于分类的贡献度进行特征筛选,并且考虑特征在文档中的重要性,将两者组合进行权重考虑。在IMDB数据集上和STS-GOLD数据集上的结果表明,该方法的分类正确率比较以往方法有较好的提升,而且该算法能适应不同类型的数据集。但是不同分类器上的表现不尽相同,需要提取不同尺寸的特征子集来适应各个分类器。在今后的工作中希望能够设计算法直接提取出一个较好的特征子集,并且改进加权规则,使特征子集能够适应较多的分类器。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
中华养生保健(2020年7期)2020-11-16
南京大学学报(数学半年刊)(2020年1期)2020-03-19
吉林大学学报(理学版)(2018年4期)2018-07-19
电子制作(2017年23期)2017-02-02
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
