
汉语名名组合语义分析的计算研究
2020-09-29 07:44王萌符雅茹胡纯
现代语文 2020年6期
关键词:语料库
王萌 符雅茹 胡纯
摘 要:名名组合语义分析的主要目的是探讨修饰语和中心词之间隐含的语义关系。运用降级述谓结构理论,利用语料库自动获取隐含谓词,将修饰语和中心词之间的语义关系显性化。实验结果表明,该方法不仅可以为名名组合提供多种可能的语义解释,而且能够反映组成相似的名名组合之间细微的语义差别。这一研究成果不但能够服务于信息检索、问答系统等应用领域,而且可以为概念组合认知机制研究提供语义解释的依据。
关键词:名名组合;语义分析;隐含谓词;语料库
一、引言
名名组合(noun compounds)是一种特定类型的名词短语,它由相邻的名词序列组成,其功能整体上相当于一个名词,如“电脑 公司”“衣服 价格”和“汽车 质量 问题”等。学界通常把名名组合中的最后一个名词称为中心词(head),前面的名词称为修饰词(modifier)。名名组合广泛存在于英语、汉语、日语、德语等各种语言,是语言中的第一高频组合,它主要有以下几个特点:
第一,通过两个词语的组合来实现信息压缩,并以最少的文本呈现出来,这符合语言学中的“经济原则”(人们在交际时总是力求用最简洁的语言来表达复杂完整的意思)。因此,名名组合的使用非常普遍,经常出现在新闻媒体、科技报告及小说等各种文体中。
第二,名名组合的能产性很高。一方面,在日常生活中,人们根据交流的需要,不断产生新的概念组合来指称新出现的事物,如“傻瓜 相机”“板凳 队员”“凤凰 男”等。另一方面,在快速更新的科技领域中,专业术语通常以名名组合的形式出现,如“数据 总线”“光电 鼠标”等。
第三,虽然名名组合的构成比较简单(相邻的名词序列),但是它们在句法分析和语义解释上表现出较高的歧义性。特别是在汉语中,名名组合的分析效果对整个句法分析有着很大的影响。
以上特點使得名名组合在语言学和计算语言学领域成为一个热点研究课题,它所涉及的研究范围也越来越广泛,包括名名组合的自动获取、句法分析、语义解释、翻译以及语义焦点分析等。本文主要关注的是汉语名名组合的语义解释,运用降级述谓结构理论,利用语料库自动获取隐含谓词,探讨修饰语和中心词之间隐含的语义关系。
二、名名组合的语义分析
(一)理论语言学中的名名组合语义类型
在句法结构上,汉语名名组合可以分为主谓、定中、同位与联合。在语义分析上,名名组合内部隐含着复杂的意义构建过程,其语义关系一直受到学界的
重视,对语义关系的研究在逐步深入和细化,相关成果也颇为丰富。朱德熙从修饰语和中心语的意义联系出发,归纳出领属、质料、时间、处所等语义类别[1]。李宇明采用层级性分类方法,将N1与N2组合分为属性关系与非属性关系两大类,每一类下面再分若干小类[2]。袁毓林将名词定语分为领属定语和属性定语两类[3];文贞惠在这一分类的基础上提出了一个有层级的语义类别关系网络[4]。周日安系统研究了名名组合的句法语义,构建出语义匹配的演绎表,推演出名名组合的语义生成模型[5]。方清明以“双视点”视角对名名语义关系进行了细致的分类,提出了如质料、提取物、处所、部位等20种关系类型[6]。
(二)计算语言学对名名组合的语义分析
在计算语言学领域,很多实际的应用系统都可以利用名名组合的句法语义分析结果。降级述谓结构理论认为,名词和名词之间常常隐藏了谓词,其语义关系可以通过补入隐含谓词而揭示出来,如“电影 公司”可以是“[制作/发行/拍摄]电影[的]公司”。这种隐含信息的显性化对信息检索、问答系统、机器翻译等诸多自然语言处理任务都有所帮助。例如,在信息检索系统中,用户输入查询“偏头疼 疗法”,系统可以提供“[减轻]偏头疼[的]疗法”或者“[防止]偏头疼[的]疗法”等不同的语义解释来帮助用户改进查询及结果。
目前,研究汉语名名组合的语义解释主要有两大处理策略。第一种是自上而下的策略(top-down strategy),这种方法首先要求有一组已经定义好的、明确的关系集合,然后根据这个关系集合,为每个名名组合分配适当的语义关系。这实际上就是一个分类问题,也有学者将这种方法称之为“Inventory-based method”。Zhao等实现了具有名物化现象(nominalization)的汉语名名组合的自动语义分类,如“鸟类 迁徙”中的“迁徙”是名动词(具有名词功能的动词)。作者参照动词的语义角色(semantic roles)界定了四种粗粒度语义关系(Proto-Agent,Proto-Patient,Range和Manner),对300个短语进行了自动分类实验[7]。
随着研究的逐步深入,越来越多的研究者意识到,将语义关系归纳为有限的几个类型的做法是有缺陷的。首先,名名组合的语义关系是不能由一组固定的集合穷尽的,无论根据何种关系进行定义,总存在一些组合不能被正确归类[6]、[8];其次,固定的关系集合难以反映名名组合的多义性,一个名名组合根据不同的解释可以属于多个语义类;最后,各种语义分类体系孰优孰劣无法判断。因此,研究者开始采用一种非受限的、开放式的方法,不事先定义语义关系集合,而是通过大规模语料去发现词语组合时隐含的语义关系,并通过某种模式进行释义(paraphrase)。这就是第二种处理策略:即自下而上的策略(bottom-up strategy)。
在这种思路指导下,很多研究者尝试用动词来解释名名组合的语义关系,他们认为,动词在表达细粒度的语义关系上更具有表现力。这种研究思路在英文名名组合的语义解释上,得到了广泛认可并付诸实践[9]—[12]。例如,“night flight”的语义关系属于时间(Temporal)类型,两个名词之间更细微的语义关系可以通过加入一系列动词(如“arrive at,leave at,be at,be conducted at”)表达出来。2010年,国际语义评测会议(Semantic Evaluation,简称“SemEval”)提出一项英文评测任务“Noun Compound Interpretation Using Paraphrasing Verbs and Prepositions”,要求参赛者为测试短语提供释义动词集合,同时给出动词的排名;2013年,SemEval延续并扩展了该项评测任务“Free Paraphrases of Noun Compounds”。
汉语名名组合的释义研究也经历了从静态分类到动态演绎的过程,研究成果主要集中在对名名组合语义的静态分类上,采用动态方式释义的研究成果较少。王萌等首次采用动态策略,利用语料库(Chinese Sketch Engine)及Web数据,自动获取汉语名名组合的释义短语[13]。魏雪形式化归纳了名名组合的语义模式,对基于规则的汉语名名组合的自动释义方法进行了探索,利用知网生成释义短语,对网络搜索词进行语义分析[14]。刘鹏远、刘玉洁基于大规模真实语料,建立了中文基本复合名词短语语义关系体系及相应句法语义知识库, 其中包含18281条高频基本复合名词短语,每条短语标注了语义关系、短语结构等信息,可作为相关研究的基础数据资源[15]。
三、隐含谓词的获取
(一)降级述谓结构理论
名名组合的表层形式是“名1+名2”。降级述谓结构理论认为,名1和名2之间隐含了动词,通过补入动词,大致能将其语义关系揭示出来。不同语义关系隐含着不同的降级谓词,对应着不同的降级述谓结构。比如,“羊毛 背心”可解释为“羊毛[编织的]背心”,“英语教师”可解释为“[教]英语[的]教师”。袁毓林曾对汉语谓词隐含(implying predicate)进行过详细论述,从句法和心理实现性等方面对谓词隐含现象进行了验证,指出被隐含的谓词是句子的语义表达中不可或缺的成分[3]。周日安从名词的语义格(施事、受事、领事等)出发,列举了18种语义格的匹配情况,他指出研究名名组合的语义类型应持开放态度,可以以语义格为纵横坐标,构建名名组合语义关系的演绎表[5]。可见,采用降级述谓结构理论对名名组合进行语义分析,关键是要获取隐含谓词。
(二)隱含谓词
名词通常会指涉概念,每一概念都具有自己的特征,当名词与名词相组合时,某一方面的特征便会凸显出来。如“钻石”作为一种坚硬的材质可以被切割和打磨,也可以作为装饰物,“钻石 锯片”和“钻石 戒指”分别凸显了钻石的两种不同特征。这些特征可以通过不同的“动词”进行解释,即“[切割]钻石[的]锯片”和“[镶嵌]钻石[的]戒指”。因此,隐含谓词获取的主要任务便是找到所有可能的与名词概念相关的动词,在两个名词组合时,与被凸显特征相关的“动词”就是合理的隐含谓词。
那么,如何获取与名词概念相关的动词呢?在自然语言中,任何形式和结构都是为了表达一定的意义,而任何意义及其关联都要通过一定的形式和结构表现出来。从句法层次上看,连接动词与名词的最为直接的语法关系就是“述宾(verb-object)”和“主谓(subject-verb)”。因此,本研究从较易把握的形式线索——表层的句法结构入手,利用“述宾”和“主谓”两种语法关系,获取与名词概念相关的动词。这就要求我们所使用的语料是标记了主谓宾等句法结构信息的,而目前可以直接利用的中文句法树库资源有限,这会直接影响到动词的获取数量。我们的方法是,获取与名词在指定语法关系下具有搭配意义的动词,并不要求语料经过深层次的句法加工和标注。就目前的研究来看,中文词汇特征素描系统(Chinese Sketch Engine,简称“CSE”)便可胜任。
(三)中文词汇特征素描系统
Sketch Engine是一个大规模语料处理系统,该系统除了提供一般的关键词及语境查询外,还提供了词汇特征素描(word sketch)、语法关系(grammatical relation)以及同近义词分析(thesaurus)等自动产生的语法知识[16]。目前这个系统已经应用于英语、汉语、法语、德语、日本语等多种语言,产生了广泛的影响。中文词汇特征素描系统①是Sketch Engine系统与十四亿字的Chinese Gigaword语料相结合的产物,它提供了绝大部分中文词汇实际使用的描述,可以服务于诸多自然语言处理任务[17]。
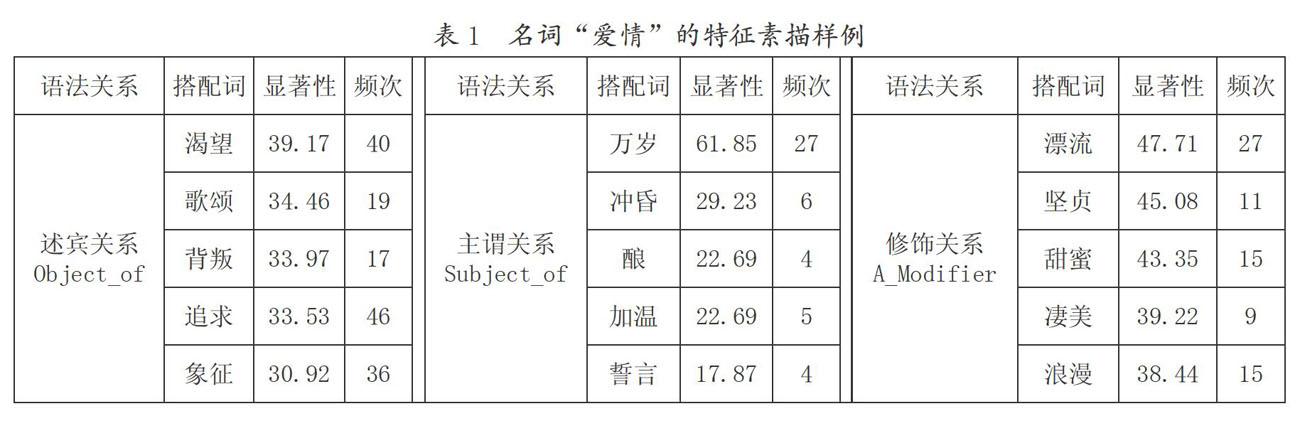
Word Sketch描述了词语在某些语法关系下与其他词语的搭配情况。根据词类的不同,其对应搭配词的语法关系也不同。例如,CSE中名词的搭配关系有述宾关系(object_of)、主谓关系(subject_of)、领属关系(possession/possessor)、修饰关系(A_modifier/N_modifier/modifies)及并列关系(and/or)等9种。所有的搭配关系可以用一个三元组(triple)来表示,即(word1,relation,word2),其中,word1是查询的关键词,relation是语法关系,word2是在这种语法关系下的搭配词。我们以“爱情”为例,运用该系统的查询结果制作了该词的特征素描,具体如表1所示:
表1列举了名词“爱情”在三种语法关系(object_of、subject_of、A_Modifier)下的搭配情况。其中,“频次”是指在相应的语法关系下搭配词出现的次数,如“爱情”作为“渴望”的宾语共出现了40次;搭配显著性的计算方法是互信息;搭配词语按照显著性的降序进行排列。
(四)获取步骤
利用CSE中的Word Sketch功能,可以方便地获取某个名词的在各种语法关系下的特征素描,本文只使用“subject_of”和“object_of”两种关系。以名名组合“n1 n2”为例,经过两个步骤即可获取隐含谓词。
第一步,将n1和n2作为查询关键词,分别获取它们在“subject_of”和“object_of”两种语法关系下的搭配词,只保留前200个显著性最高的搭配词,这样分别得到名词n1和n2的相关动词集合,分别记为VerbSetn1和VerbSetn2。
第二步,求取VerbSetn1和VerbSetn2的交集,得到名词n1和n2所共有的动词,作为最终的隐含谓词获取结果。
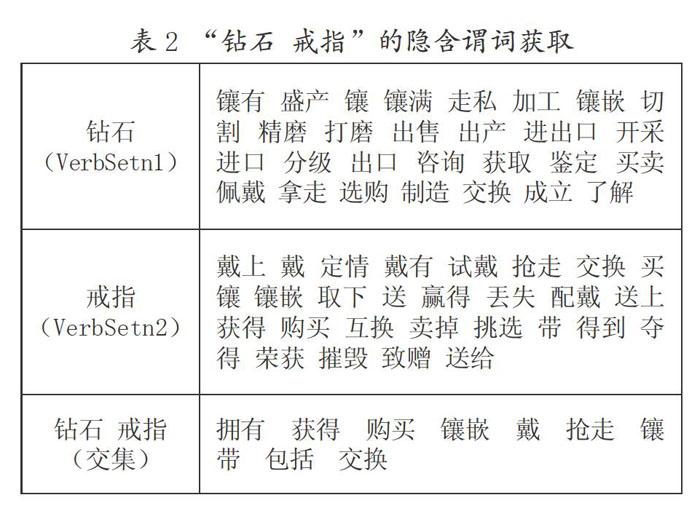
这里以“钻石 戒指”为例,来探究一下是如何获取隐含谓词的,具体如表2所示:
表2给出了“钻石”“戒指”这两个名词在subject_of和object_of语法关系下的搭配动词样例,以及它们交集的结果。可以看出,获取结果中的“镶嵌、镶、交换、获得”等动词,能够表达“钻石”和“戒指”的语义关系。
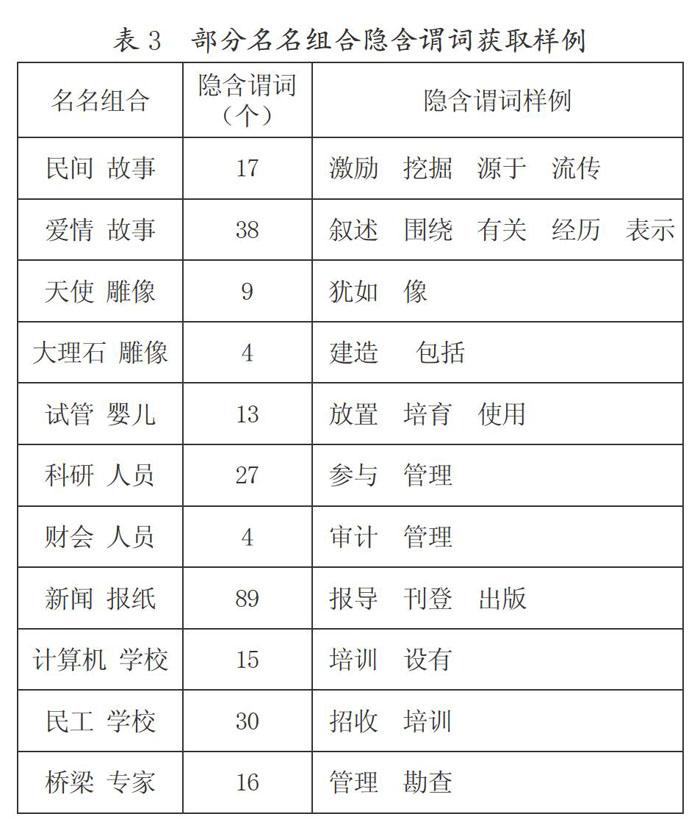
我们按照这一方法,获取了部分名名组合隐含谓词的结果,具体如表3所示:
表3给出了部分名名组合隐含谓词的结果样例,这里列出的只是显著性最高的且正确的词语。对于同一组具有相同中心词的名名组合,隐含谓词可以反映它们进行语义关联的方式,如“民间 故事”主要用“流传、源于、挖掘”等动词进行释义,强调的是故事的来源或发生地;而“爱情 故事”主要用“叙述、围绕、表示”等动词进行释义,强调的是故事的内容。
四、相关结果分析
本研究从《人民日报》语料中抽取了424个高频名名组合,并列出了部分样例,具体如表4所示:
经过上述步骤,获取到400个名名组合的隐含谓词,有24个名名组合不能获取隐含谓词(即两个集合的交集为空)。
我们为每个名名组合保留10个显著性最高的谓词,统计给出的候选中是否有正确的释义出现,基于此就可以计算整个方法的准确率。我们逐一考察了这400个名名组合获取的隐含谓词,其中385个名名组合都有正确的隐含谓词,只有15个名名组合获取的谓词完全不正确,准确率达到96.25%。
与以中心语或修饰语分类的方法相比,笔者所采用的方法具有一定的优越性。这里以名名组合“X公司”隐含谓词的获取结果为例,对此加以说明,具体如表5所示:
表5给出了一组具有相同中心词的名名组合“X公司”,中心语相同时并不表示其构成关系相同,通过隐含谓词可以有效地揭示其语义关系的差别。例如,“寿险 公司”使用“服务、经营、投资”等谓词,而“饲料 公司”使用“制造、开发、制作”等谓词,体现出这两个公司的不同职能范围。对于同一个名名组合,不同的隐含谓词代表了各种可能的语义解释,对于歧义具有分化作用,如“电影 公司”可以是“[制作/发行/管理]电影[的]公司”等。
本研究还对没有获取到隐含谓词的24个名名组合进行了分析。这些名名组合可以分为两类:第一类,如“国际 公司”“专业 市场”“外籍 人员”等名名
组合。把它们译为英文时,一些名词对应的是形容词。如“国际 公司”的英文是“international corporation”,名词“国际”变成了形容词“international”。在英文名名组合的释义任务中(参看SemEval2010 Task9),这类形容词作为修饰语的情况是不包括在内的。而在汉语中,对于这部分名词实际上充当了形容词功能的名名组合,是很难找到合适的隐含谓词的。第二类,如“皮包 公司”“文化 沉渣”“小康 步伐”等名名组合。认知语言学认为,名名组合是一种概念结合的产物,而“皮包 公司”是属于特征映射型语义关系[18],在这一组合中,“皮包”已失去原来的指称意义,而是指它所具有的特征。因此,对于这类名名组合,该方法是不能正确获取隐含谓词的。而“小康 步伐”其实是隐含了多个谓词“[迈]步伐[进入]小康”,该方法对此类名名组合也不能获取到隐含谓词。
五、余论
汉语名名组合的语义类型复杂多变,难以穷尽,它是开放的,处于不断的变化中。以基于隐含谓词的动态策略探讨汉语名名组合的语义解释,是当前研究的趋势和热点。本文主要是利用Chinese Word Sketch获取在指定语法关系下具有搭配意义的动词,通过这一方法获取的动词仍是有限的,今后我们将借鉴英文的相关成果,进一步改进隐含谓词的获取方法,通过定义模板利用Web数据进行扩充。同时,在获取到隐含谓词后,将利用释义模板恢复其完整的释义短语。这一方法不仅可以为名名组合提供多种可能的语义解释,而且能够反映组成相似的名名组合之间细微的语义差别。其研究成果不但能够服务于計算机语言信息处理的需求,而且可以为心理语言学关于概念组合认知机制的研究提供语义解释的依据。
参考文献:
[1]朱德熙.语法讲义[M].北京:商务印书馆,1982.
[2]李宇明.领属关系与双宾句分析[J].语言教学与研究, 1996.(3).
[3]袁毓林.谓词隐含及其句法后果——“的”字结构的称代规则和“的”的语法、语义功能[J].中国语文, 1995,(4).
[4][韩国]文贞惠.“N1(的)N2”偏正结构中Nl与N2之间语义关系的鉴定[J].语文研究,1999,(3).
[5]周日安.名名组合的句法语义研究[M].北京:中国社会科学出版社,2010.
[6]方清明.现代汉语名名复合形式的认知语义研究[D].广州:暨南大学博士学位论文,2011.
[7]J.Zhao,H.Liu & R.Lu.Semantic labeling of compound nominalization in Chinese[A].Proceedings of the Workshop on A Broader Perspective on Multiword Expressions[C].2007.
[8]Downing,P.On the creation and use of English compound nouns[J].Language,1977,(4).
[9]Girju,R.,Moldovan,D.,Tatu,M. & Antohe,D.On the semantics of noun compounds[J].Computer Speech and Language,2005,(19).
[10]Diarmuid,? Séaghdha.Learning compound noun semantics[D].Ph.D.thesis,University of Cambridge,2008.
[11]Nakov,P.Noun compound interpretation using paraphrasing verbs:Feasibility Study[A].Proceedings of the 13th international conference on Artificial Intelligence:Methodology,Systems and Applications(AIMSA)[C].2008.
[12]Nakov,P. & Hearst,M.Using verbs to characterize noun-noun relations[A].Proceedings of the 12th international conference on Artificial Intelligence:Methodology,Systems and Applications(AIMSA)[C].2006.
[13]王萌,黃居仁,俞士汶,李斌.基于动词的汉语复合名词短语释义研究[J].中文信息学报,2010,(6).
[14]魏雪.面向语义搜索的汉语名名组合的自动释义研究[D].北京:北京大学硕士学位论文,2012.
[15]刘鹏远,刘玉洁.中文基本复合名词短语语义关系体系及知识库构建[J].中文信息学报,2019,(4).
[16]Kilgarriff,A.,Rychly,P.,Smrz,P. & Tugwell,D.The sketch engine[A].Proceedings of the Eleventh Euralex Congress[C].2004.
[17]Huang,C.R.,Kilgarriff,A.,Wu,Y.,et al.Chinese sketch engine and the extraction of collocations[A].Proceedings of the Fourth SigHan Workshop on Chinese Language Processing[C].2005.
[18]刘正光.关于N+N概念合成名词的认知研究[J].外语与外语教学,2003,(11).
Computational Research on the Semantics of Chinese Noun Compounds
Wang Meng1,Fu Yaru2,Hu Chun3
(1.2.School of Humanities, Jiangnan University, Wuxi 214122;
3.School of Foreign Studies, Jiangnan University, Wuxi 214122, China)
Abstract:The semantic analysis of noun compounds is to recover the implicit semantic relations between the head and modifier.In this paper, we adopt the downgraded predication theory to paraphrase Chinese noun compounds. Corpus is used to acquire the implying predicates automatically. The experiment results show that this approach can not only provide the possible interpretations for noun compounds but also reflect the interesting, detailed semantic differences of similar noun compounds.In addition, our research can be applied in some other fields such as question answering, information retrieval and language teaching, and provide semantic interpretation for the study of cognitive mechanisms of concepts combination in psycholinguistics.
Key words:noun compounds;semantic analysis;implying predicates;corpus
猜你喜欢
校园英语·月末(2020年4期)2020-06-08
神州·下旬刊(2019年10期)2019-11-22
知识文库(2019年22期)2019-11-11
知识文库(2019年4期)2019-10-20
世界家苑(2018年11期)2018-11-20
求知导刊(2018年25期)2018-11-01
新教育时代·学生版(2018年13期)2018-10-21
知识文库(2018年21期)2018-05-14
师道·教研(2017年11期)2017-12-10
中国校外教育(下旬)(2014年7期)2015-04-03
