
基于深度残差网络的多损失头部姿态估计
2020-12-16 02:18齐永锋马中玉
计算机工程 2020年12期
齐永锋,马中玉
(西北师范大学 计算机科学与工程学院,兰州 730070)
0 概述
头部姿态估计是通过检测人脸方向与判断人眼注意力估计整个头部姿态,可应用于驾驶员监控[1]、注意力识别[2]以及面部分析等,例如交通管控人员对驾驶员头部姿态进行精准估计与预测能有效降低交通事故发生率,教师在课堂教学时通过估计与分析学生头部姿态,可判断其听讲情况及对课程的兴趣程度。近年来,头部姿态估计已成为计算机视觉领域的研究热点[3],研究人员采用不同仪器设备对其进行研究。其中,相机阵列、激光指示器、立体相机、深度相机、磁性与惯性传感器等可在成像环境受限情况下获得稳定的姿态估计图像[4]。然而上述设备需要人体穿戴或者在室内使用,使得头部姿态估计无法在自然场景下进行,此外穿戴设备的高成本也使其大范围推广应用受到限制。由于单目摄像机、手机、笔记本电脑等均可拍摄RGB图像,便于头部姿态估计的广泛应用[5],因此目前通常采用RGB图像进行头部姿态估计与分析。基于RGB图像的头部姿态估计方法包括基于外观的方法、基于模型的方法、流形嵌入方法以及非线性回归方法[6]。其中,基于外观的方法将头部视图与代表姿势标签的离散模型进行对比[7],利用不同类型模板匹配技术,评估输入特征与样本集的相似性。该方法主要通过对比人脸样本图像与二维人脸地标图像的特定关系来估计头部姿态,实现相对简单,但在实际场景中应用局限性较大[5],例如在不使用插值方法的情况下无法估计离散姿态位置。基于模型的方法使用几何信息、非刚性面部模型或者界标位置来估计头部姿态,该方法关键在于找到共面的面部关键点并估计与参考坐标系的距离[8],然而其对角度数据精确度要求较高,无法在角度退化的情况下使用。此外,基于模型的方法还可通过多个非共面关键点位置来评估,假设地标之间存在固定几何关系,将上述关键点位置与测量人体获得的平均掩模进行对比[9]来估计头部姿态。基于模型方法的准确性与从图像中所推理几何关系的真实性及数量相关,虽然关键点检测和跟踪技术发展较快[10],但是该方法的应用仍受到地标检测技术限制。例如,当头部姿态估计应用于智能系统身份和行为检测时,光照变化、遮挡、分辨率等因素都会对检测结果造成较大影响[11-12]。
随着深度学习技术的发展,基于深度学习的头部姿态估计得到深入研究并取得一系列成果。文献[5]采用浅层卷积神经网络分析头部姿态算法的鲁棒性,发现自适应梯度神经网络能更好地训练模型。文献[13]通过卷积神经网络将3D人脸模型与RGB图像进行拟合,使用密集的3D模型对齐面部标志得到3D头部姿态,但是引入了固有误差。文献[14]使用改进的GoogleNet[15]并利用多任务共同学习面部标志和头部姿态。文献[16]采用由5个卷积层和3个全连接层组成的卷积神经网络HyperFace进行头部姿态估计、人脸对齐与性别分类。文献[17]利用All-In-One神经网络为HyperFace增加微笑预测与年龄估计功能。上述方法虽然在一定程度上解决了自然环境中面部检测和头部姿态估计的问题,但是所得结果存在较大误差。
文献[18]在深度学习架构下使用更高级别的表示方法用于回归头部姿态,在选定的面部标志上使用2D热图形式的不确定性图,并将其通过卷积神经网络作为输入通道来回归头部姿态,然而该方法仅采用5个面部标志,对被遮挡头部姿态的识别十分有限[19]。上述方法对人脸特征点检测精度要求较高,在视线或光照不佳、遮挡严重等情况下其检测性能较差甚至检测失效。为解决该问题,文献[20]采用简单的卷积神经网络回归3D头部姿态,但只专注于面部对齐,未在公共数据集上进行头部姿态估计。文献[21]提出无关键点的头部姿态估计方法,划分3个分支对头部姿态的3个角度进行联合预测,每个分支通过分类和积分回归组合。文献[22]提出一种基于卷积神经网络的模型,该模型通过线性逆回归高斯混合来回归头部姿态。文献[23]结合无监督流形学习和逆回归质量的方法在光照、面部方向和外观变化等方面进行改进,提高了鲁棒性。以上方法都是采用地标检测进行姿态估计,虽然基于地标的方法在给定地标时能较好地预测头部姿态,但是在真实场景地标准确性较低的情况下会降低姿态估计精度。
为解决上述问题,本文提出一种基于深度学习的无关键点头部姿态估计方法,采用更多层的深度残差网络RestNet101[24]进行多角度回归损失设计,在文献[19]的基础上对梯度下降模式进行优化,同时与自适应方法相结合,使用卷积神经网络从图像强度估计头部姿态,并对不同数据集上头部姿态估计效果与测试精度进行分析。
1 头部姿态估计方法
1.1 头部姿态表示
头部姿态估计方法主要分为基于2D关键点检测的3D姿态推算方法以及无关键点检测的直接预测方法。其中,前者需对人脸关键点进行检测及分析,即通过建立关键点和3D头部模型之间的对应关系并执行对准来恢复头部3D姿态,这种使用卷积神经网络提取面部关键点的方法灵活性较好,但未使用面部全部信息,在未能检测到面部关键点的情况下,无法准确进行头部姿态估计。因此,本文提出一种无关键点的头部姿态估计方法[21],利用单目摄像机获取人体头部图像,采用欧拉角表示头部姿态,如图1所示。从偏航角(yaw)、仰俯角(pitch)、旋转角(roll)3个角度描述头部空间姿态。由文献[21]证明结果可知,使用卷积神经网络从图像强度估计3D头部姿态具有较高的准确性。

图1 采用欧拉角表示的头部姿态Fig.1 Head posture expressed by Euler angle
1.2 网络设计
传统无关键点检测的头部姿态估计方法使用卷积神经网络直接预测欧拉角,在大规模训练中存在训练不稳定、识别性能较差与速度较慢等问题,因此,本文使用更多层的深度残差网络RestNet101,将全连接层输出设置为198层,其中66层及其以下用于粗分类以辅助学习,66层以上用于精细分类以进行头部姿态预测。同时选择更好的优化器AdaBound[25]在训练网络中进行梯度优化,本文方法网络结构如图2所示。

图2 本文方法网络结构Fig.2 Network structure of the proposed method
采用Softmax分类器获得每层输出的交叉熵损失,同时计算偏航角、仰俯角、旋转角的均方误差,并联合其他层输出损失计算总损失,损失计算方法将在1.3节中具体介绍。本文方法所用网络的训练参数设置如下:训练迭代次数为200,每次迭代处理样本数量为36,学习率为0.001。对数据集处理如下:对于头部翻转的图像,改变偏航角和旋转角方向进行翻转处理;对于模糊图像,采用滤波器进行去模糊处理。
1.3 损失计算
Softmax回归由逻辑回归演化而来,用于解决多分类问题,属于有监督的学习方法。神经网络最后一层为Softmax函数,其与深度学习方法结合可用来区分输入图像的角度类别。
交叉熵损失计算在Softmax回归后进行,该计算在深度学习中使用较多。在神经网络中,交叉熵通常与Softmax函数组合使用,本文网络仍采用该模式以便对头部姿态进行有效预测。交叉熵函数的计算公式为:
(1)
其中,N为样本数,i、j为二维矩阵中的元素,h为分类概率。
本文所用回归损失函数为均方误差(Mean Square Error,MSE),即预测值与目标值之间差值的平方和,计算公式如下:
(2)
其中,y、y′分别表示真实值和预测值。
每个角度的损失表示为:
(3)
其中,L和MSE分别为交叉熵损失和均方误差损失函数,n为分类分支数量。本文中α、βi均为训练参数,α=2,βi={2,7,5,3,1,1}
2 实验与结果分析
本文使用AFLW2000[24]、 BIWI[26]和300W_LP[13]3个数据集进行分析和验证。AFLW2000数据集包含野外与姿态变化较大的2 000张人脸图像(偏航角为-90°~90°),并使用68个3D地标进行注释。BIWI数据集是应用较广泛的面部数据集,其中包含15 000张人脸图像(取自6位女性和14位男性)。BIWI数据集对于每一帧图像均提供深度图像、相应的RGB图像(640像素×480像素)和注释。300W_LP数据集广泛用于面部识别与头部姿态分析,是常用的野外2D地标数据集,由包含大量头部姿态的61 225张图像组成,并通过翻转扩展至122 450张图像。图3为AFLW2000数据集、BIWI数据集和300W_LP数据集的部分图像示例。头部姿态范围设置如下:偏航角为±75°,俯仰角为±60°,旋转角为±50°。地标真值以头部的三维位置及其旋转形式提供。

图3 3种数据集部分图像示例Fig.3 Sample images of three datasets
本文实验采用Windows10操作系统,CPU为Intel®CoreTMi3-8100,主频为3.6 GHz,显卡为Nvidia RTX2060,显存为6 GB,图形支持为CUDA10,实验环境配置为深度学习框架Pytorch1.0与OpenCV 3.4。通过计算偏航角、仰俯角、旋转角3个参数的均方误差与平均绝对误差(Mean Absolute Error,MAE)来评估本文方法在不同数据集上的表现,并分别给出相应数据集上头部姿态表示结果。采用图1中头部姿态表示方法,向下的轴线表示偏航角方向,向右的轴线表示仰俯角方向,垂直面部向前的轴线表示旋转角方向,从而立体化表示三维空间头部姿态信息,并通过可视化直观展示来评估头部转向与位置信息。
2.1 AFLW2000数据集上头部姿态估计
图4为本文方法在AFLW2000数据集上的部分头部姿态估计结果。可以看出,本文方法对不同图像的头部姿态估计稳定可靠,能较好地表示头部姿态,在室内外场景中鲁棒性均表现良好。

图4 AFLW2000数据集上的部分头部姿态估计结果Fig.4 Results of partial head poseture estimation onAFLW2000 dataset
本文使用粗、细粒度分类任务进行头部姿态估计,通过粗粒度回归定位人脸,采用细粒度评估姿态。将本文方法与FAN[24]地标[27]检测方法(以下称为FAN方法)以及文献[21]中无关键点的细粒度头部姿态估计方法(以下称为文献[21]方法)在AFLW2000数据集上的平均绝对误差进行对比,由于AFLW2000图像尺寸较小,而裁剪操作在脸部周围进行,因此更易检测到人脸区域,结果如表1所示。可以看出,在偏航角、仰俯角、旋转角3个角度的评估上,本文方法的平均绝对误差相较文献[20]方法下降0.759个百分点,表明本文方法对小图像的头部姿态估计性能较好,能在小分辨率与弱光下检测和评估头部信息。

表1 3种方法在AFLW2000数据集上的实验结果Table 1 Experimental results of three methods onAFLW2000 dataset
2.2 BIWI数据集上头部姿态估计
本文使用每个颜色通道ImageNet均值和标准偏差来标准化训练前的数据,并将BIWI数据集作为网络的大规模输入,通过RestNet101主干网络以及损失分类得到最终头部姿态估计结果。图5为本文方法在BIWI数据集上的部分头部姿态估计结果。可以看出,通过对BIWI数据集的简单处理,其更利于网络训练,该数据集图像中头部姿态角度覆盖范围更广,网络训练后头部姿态检测效果较好。

图5 BIWI数据集上的部分头部姿态估计结果Fig.5 Results of partial head poseture estimation onBIWI dataset
将本文方法与FAN方法和文献[21]方法在BIWI数据集上的平均绝对误差进行对比,结果如表2所示。可以看出,与其他两种方法相比,本文方法的偏航角、仰俯角和旋转角平均绝对误差更小,且MAE值降幅较小,这是因为BIWI数据集具有一定的帧间信息,使平均绝对误差降幅较小。

表2 3种方法在BIWI数据集上的实验结果Table 2 Experimental results of three methods onBIWI dataset
2.3 300W_LP数据集上头部姿态估计
图6为本文方法在300W_LP数据集上的部分头部姿态估计结果,从左到右4张图像的光线环境分别为室内、室外、正常光照和暗光环境。可以看出,本文方法的姿态估计均较准确,可适用于不同光照环境下的头部姿态估计。

图6 300W_LP数据集上的部分头部姿态估计结果Fig.6 Results of partial head poseture estimation on300W_LP dataset
使用300W_LP数据集分析训练过程并测试网络性能,并将本文所用AdaBound优化器与SGD、AMSGrad和Adam优化器进行对比以验证本文优化器的有效性。图7是RestNet101网络使用上述4种优化器在300W_LP数据集上所得训练精度与测试精度。可以看出:在训练阶段前150次迭代中,AdaBound优化器的训练精度接近98%,高于其他优化器,AMSGrad优化器的训练精度排在第二位;在训练阶段迭代150次后,各优化器的训练精度均明显提升,其中AdaBound优化器增幅最大,收敛速度最快;在测试阶段,SGD优化器测试精度曲线震荡较强烈,梯度下降不稳定,AdaBound优化器测试精度曲线收敛较快,梯度下降较稳定,测试精度达到95%以上,高于其他两种优化器。
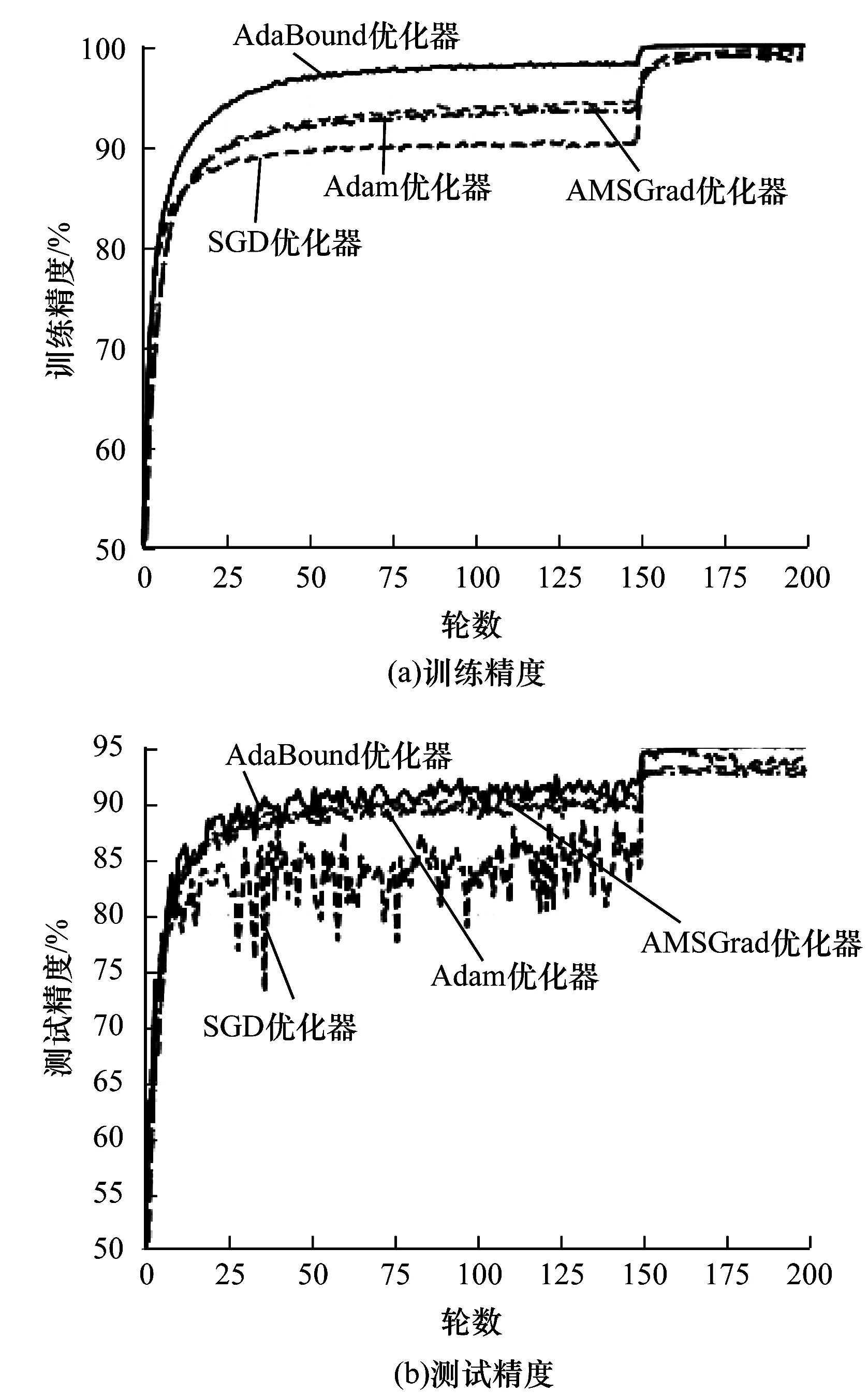
图7 4种优化器在300W_LP数据集上的训练精度与测试精度Fig.7 Training accuracy and test accuracy of fouroptimizers on 300W_LP dataset
在300W_LP数据集上的姿态评估测试中,本文方法在偏航角、仰俯角和旋转角上的平均绝对误差为1.801 6(FAN方法和文献[21]方法没有在相同条件下的实验数据),姿态估计性能较好。上述结果表明,本文通过增加网络层数、优化下降梯度,可提升训练速度与训练精度。
2.4 性能测试
2.4.1 鲁棒性分析
为进一步验证本文方法在真实环境中的鲁棒性,使用训练好的RestNet101网络模型在复杂光照、部分遮挡及极限姿态情况下进行测试,结果如图8所示。其中,图8中左起第1张和第2张图像为复杂光照环境,左起第3张和第4张图像分别为部分遮挡和极限姿态情况。可以看出,本文方法在复杂光照、部分遮挡以及极限姿态情况下头像姿态识别良好,具有较好的鲁棒性,满足复杂条件下头部姿态估计要求。

图8 本文方法鲁棒性测试结果Fig.8 Robustness test results of the proposed method
2.4.2 位姿估计的运算复杂度与实时性分析
为检验头部位姿运算复杂度,需分析头部姿态估计模型加载和处理时间,表3为本文方法在模型初始化、网络姿态角回归以及头部姿态估计3个阶段的耗时情况。可以看出在模型初始化阶段,由于需进行头部模型库调用与模型加载,因此初始化所用时间较长。在网络姿态角回归阶段,主要进行姿态回归和网络损失计算,在头部姿态估计阶段,主要进行输入帧模型对比与图像生成处理。3个阶段总耗时为89.16 ms,所用时间较短。

表3 本文方法在3个阶段的耗时情况Table 3 Time consumption of the proposed methodin three stages ms
在真实室内环境下,使用网络摄像头加载训练好的RestNet101网络模型,得到头部姿态测试结果如图9所示,视频帧尺寸为1 024像素×576像素。可见实际场景下头部姿态识别准确,说明该模型能较好地捕捉未训练过的目标。网络摄像头实际运行测试显示网络模型在 GPU 上每秒传输帧数(Frames Per Second,FPS)达到31,满足实时处理的需求。

图9 网络摄像头所得头部姿态测试结果Fig.9 Head posture test result obtained by Webcam
3 结束语
针对传统无关键点检测方法识别较差且速度较慢的问题,本文提出一种采用深度残差网络RestNet101的头部姿态估计方法,利用多损失分类训练深度残差网络,使用无关键点细粒度方法估计头部姿态,通过网络粗、细分类的分层设计进行头部姿态预测,并在训练阶段使用AdaBound优化器进行梯度优化。实验结果表明,与FAN地标检测方法和无关键点细粒度方法相比,该方法在AFLW2000和BIWI数据集上平均绝对误差更小。后续将在深度学习的基础上,从网络模型改进和数据集处理方面进行研究,进一步提高头部姿态估计精度。
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16
今日农业(2021年8期)2021-11-28
军事文摘(2020年22期)2021-01-04
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
唐山师范学院学报(2018年6期)2018-12-25
天津医科大学学报(2015年2期)2015-12-22
新高考·高一物理(2015年5期)2015-08-18
中国卫生(2014年2期)2014-11-12
新课程学习·中(2013年3期)2013-06-14
