
机器学习经典算法及其应用研究综述
2020-12-28 02:10徐洪学孙万有杜英魁汪安祺
电脑知识与技术 2020年33期
徐洪学 孙万有 杜英魁 汪安祺
摘要:机器学习是人工智能的一个重要子领域,是现阶段人工智能和数据分析领域的重点研究方向之一,我们有必要对机器学习有个全面而深刻的认识理解。根据训练样本及反馈方式的不同对机器学习算法分为监督学习、无监督学习及强化学习三类,介绍机器学习领域有代表性的若干经典算法及其应用,最后对机器学习算法的发展前景进行展望。
关键词:机器学习;监督学习;无监督学习;强化学习;深度学习
中图分类号:TP181 文献标识码:A
文章编号:1009-3044(2020)33-0017-03
开放科学(资源服务)标识码(OSID):
1 背景
机器学习领域的著名学者汤姆·米切尔(Tom Mitchell)将机器学习定义为:对于计算机程序有经验E、学习任务T和性能度量P,如果计算机程序针对任务T的性能P随着经验E不断增长,就称这个计算机程序從经验E学习[1]。这个定义比较简单抽象,随着对机器学习的研究越来越深入,我们会发现机器学习的内涵和外延也在不断变化。简言之,机器学习就是用计算机通过算法来学习数据中包含的内在规律和信息,从而获得新的经验和知识,以提高计算机的智能性,使计算机面对问题时能够做出与人类相似的决策[2]。
随着各行各业的发展,数据量增多,对数据处理和分析的效率有了更高的要求,一系列的机器学习算法应运而生。机器学习算法主要是指运用大量的统计学原理来求解最优化问题的步骤和过程。针对各式各样的模型需求,选用适当的机器学习算法可以更高效地解决一些实际问题[3]。
2 机器学习算法的分类
按照现在主流的分类方式,可以根据训练样本及反馈方式的不同,主要将机器学习算法分为监督学习、无监督学习和强化学习3种类型。其中监督学习是机器学习这三个分支中最大和最重要的分支。另外,作为监督学习与无监督学习相结合的半监督学习方法[4],暂不列在本文讨论范围之内。
2.1 监督学习算法(Supervised Algorithms)
在监督学习中,训练集中的样本都是有标签的,使用这些有标签样本进行调整建模,从而使模型产生一个推断功能,能够正确映射出新的未知数据,从而获得新的知识或技能[5]。
根据标签类型的不同,可以将监督学习分为分类问题和回归问题两种。前者预测的是样本类别(离散的),例如给定鸢尾花的花瓣长度、花瓣宽度、花萼长度等信息,然后判断其种类;后者预测的则是样本对应的实数输出(连续的),例如预测某一时期一个地区的降水量。常见的监督学习算法包括决策树、朴素贝叶斯及支持向量机等。
2.2 无监督学习算法(Unsupervised Algorithms)
无监督学习与监督学习相反,训练集的样本是完全没有标签的。无监督学习按照解决的问题不同,可以分为关联分析、聚类问题和维度约减三种。
关联分析是指通过不同样本同时出现的概率,发现样本之间的联系和关系。这被广泛地应用于购物篮分析中。例如,如果发现购买泡面的顾客有百分之八十的概率买啤酒,那么商家就会把啤酒和泡面放在临近的货架上。
聚类问题是指将数据集中的样本分成若干个簇,相同类型的样本被划分为一个簇。聚类问题与分类问题关键的区别就在于训练集样本没有标签,预先不知道类别。
维度约减是指保证数据集不丢失有意义的信息的同时减少数据的维度。利用特征选择方法和特征提取两种方法都可以取得这种效果,前者是指选择原始变量的子集,后者是指将数据由高维度转换到低维度。
无监督学习与人类的学习方式更为相似,被誉为是人工智能最有价值的地方[6]。常见的无监督学习算法包括稀疏自编码、主成分分析及K-means等。
2.3 强化学习算法(Reinforcement Algorithms)
强化学习是从动物行为研究和优化控制两个领域发展而来。强化学习和无监督学习一样都是使用未标记的训练集,其算法基本原理是:环境对Agent(软件智能体)的某个行为策略发出奖赏或惩罚的信号,Agent要使每个离散状态期望的奖赏都最大,从而根据信号来增加或减少以后产生这个行为策略的趋势[7]。
强化学习这一方法背后的数学原理与监督/非监督学习略有差异。监督/非监督学习更多地应用了统计学知识,而强化学习更多地应用了离散数学、随机过程等这些数学方法[8]。常见的强化学习算法包括Q一学习算法、瞬时差分法、自适应启发评价算法等。
3 机器学习经典算法及其应用
机器学习作为一个独立的研究方向已经经过了近四十年的发展,期间经过一代又一代研究人员的努力,诞生了众多经典的机器学习算法,但限于篇幅无法对所有算法一一整理总结,以下只列举了有代表性的一部分经典算法进行描述。
3.1 朴素贝叶斯(Naive Bayesian)
朴素贝叶斯算法基于统计学分类中的贝叶斯定理,将特征条件独立性假设作为前提,是一种常见的有监督学习分类算法。对于给定的一组数据集,朴素贝叶斯算法会求得输入/输 出的联合概率分布,然后在统计数据的基础上,依据条件概率公式,计算当前特征的样本属于某个分类的概率,选择概率最大的分类。
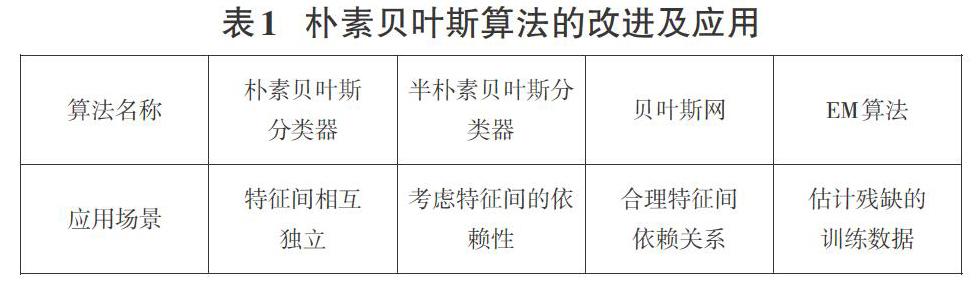
在实际情况下,朴素贝叶斯算法的独立假设并不能成立,所以其性能略差于其他一些机器学习算法,但是由于其实现简单、计算复杂度低且对训练集数据量的要求不大,使其在文本分类、网络舆情分析等领域上有着十分广泛的应用[9]。另一方面,由于实际应用中存在各特征相互干涉、训练数据集缺失等的情况,于是又从中优化演变出其他贝叶斯算法[10],以增强其泛化能力。朴素贝叶斯算法的改进及应用如表1所示。
3.2 K均值算法(K-Means)
K均值算法是一种常用的聚类算法。其核心思想是把数据集的对象划分为多个聚类,并使数据集中的数据点到其所属聚类的质心的距离平方和最小,考虑到算法应用的场景不同,此处描述的“距离”包括但不限于欧氏距离、曼哈顿距离等。
猜你喜欢
江苏教育·中学教学版(2016年11期)2016-12-21
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
科教导刊(2016年26期)2016-11-15
科学与财富(2016年28期)2016-10-14
