
基于WGAN的不均衡太赫兹光谱识别
2021-02-03 08:03朱荣盛刘英莉崔向伟
光谱学与光谱分析 2021年2期
朱荣盛,沈 韬*,刘英莉,朱 艳,崔向伟
1.昆明理工大学信息工程与自动化学院,云南 昆明 650504 2.昆明理工大学云南省计算机技术应用重点实验室,云南 昆明 650504
引 言
太赫兹(Terahertz,THz)波是指频率在0.1~10 THz之间的电磁波,在电磁波谱中位于微波和红外辐射之间[1]。近年来,随着太赫兹激发及探测技术的不断发展,目前已有一部分太赫兹产品在实际生活中得到运用,并展现出极高的使用价值及广阔的应用前景[2-3]。由于许多有机分子的振动、转动光谱以及分子间相互作用力落在太赫兹频率波段,可将其作为“指纹谱”实现对物质的定量定性分析[4-6];同时由于太赫兹所具有的瞬态性、低能性和相干性等特征,使其在光谱识别[7,8]和成像领域[9-10]得到飞速发展。
通过实验获取到的太赫兹光谱数据库存在数据规模不匹配问题,而标准机器学习方法在不均衡数据集中表现不佳,影响太赫兹光谱数据的识别准确率[11]。2014年,刘进军[12]提出基于惩罚机制的PFKSVM方法来克服K-SVM在最佳分类表面附近易于分类错误,并使用UCI公共数据集进行实验验证其方法在处理不均衡数据集中的优势。2019年,Tao等[13]提出了一种过采样技术,该技术使用实值否定选择(RNS)来生成人为的少数类数据,并将生成的少数类数据与多数类组合作为输出。但是,这些方法在太赫兹领域解决数据不均衡问题时并未考虑太赫兹光谱所反映材料的物理和化学性质。针对这一问题,本文提出了一种基于WGAN的不均衡太赫兹光谱识别方法来解决太赫兹光谱数据不均衡问题。
Wasserstein GAN是Arjovsky等[14]在2017年提出的一种改进GAN模型的新框架,该方法通过生成器与判别器的相互博弈产生以假乱真的数据,生成数据符合真实数据分布,并且能有效增加数据量。针对目前太赫兹光谱数据库中各物质数据量不均衡问题,本文提出一种基于WGAN的不均衡太赫兹光谱识别方法。首先利用生成对抗网络学习真实太赫兹光谱数据分布,在WGAN达到纳什均衡后用生成数据扩展太赫兹光谱数据集,使之达到类别均衡,最后采用多分类支持向量机对太赫兹光谱数据进行分类识别。
1 基于WGAN的太赫兹光谱识别方法
1.1 基础理论
太赫兹光谱数据为实数值,采用GAN训练数据,模型会出现梯度不稳定和多样性不足等问题[14]。针对这些问题,将Wasserstein距离作为生成对抗网络的衡量指标,定义如式(1)
(1)
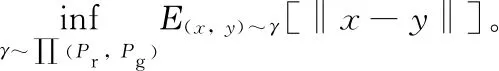
通过Kantorovich-Rubinstein对偶原理可得变换公式
W(P1,P2)=sup‖f‖L≤1Ex~P1[f(x)]-Ex~P2[(f(x))]
(2)
1.2 模型结构
生成对抗网络(generative adversarial network,GAN)是Goodfellow等[15]在2014年提出的一种概率生成模型,通过对抗过程估计生成模型的新框架。生成对抗网络由两个模型构成,生成模型G和判别模型D,随机噪声z通过生成模型G生成尽量服从真实数据分布pdata(x)的样本G(z)。
判别模型D是一个判别式网络,判定接收到的样本是否是来自pdata(x),因此有
Ex~pdata(x)[log(D(x))]
(3)
其中E指代期望,通过根据正类(即判别出x属于真实数据data)的对数函数构建。
生成器D通过训练不断提高欺骗判别器的概率,通过根据负类的对数函数构建,即
Ez~pz(z)[log(1-D(G(z)))]
(4)
生成对抗网络的本质是二元零和博弈问题,即通过生成器不断优化生成函数与判别器不断优化判别网络来达到最优状态,即
Ez~pz(z)[log(1-D(G(z)))]
(5)
生成对抗网络给出了一种生成数据的新形式,即可通过对抗性学习模拟真实数据分布。而物质的太赫兹光谱数据为实数值,将JS散度作为衡量值并不能很好的评估距离,因此通过使用Wasserstein距离来衡量生成部分和真实数据分布之间的距离,解决了生成对抗网络在生成太赫兹光谱数据时训练过程不稳定,模型优化困难等问题。
2 实验部分
实验以麦芽三糖(Maltotriose)、麦芽六糖(Malthexaose)和麦芽七糖(Maltoheptaose)在0.9~6 THz内的太赫兹透射光谱为例。首先通过S-G滤波对光谱数据进行滤波处理,然后通过三次样条插值获得相同的数据点。随机选择三种物质预处理后的各一条太赫兹光谱数据曲线,如图1所示。

图1 三种物质的太赫兹光谱Fig.1 Terahertz spectra of three substances
为了验证该方法的有效性,我们首先使用WGAN生成数据,将物质的光谱数据输入到WGAN模型中。其次,生成模型G根据输入数据的维度输出与测试数据相同维度的随机数。最后,判别模型D判别接收到的数据是否为太赫兹频谱数据。当判别模型D无法识别接收到的数据是真实数据还是生成数据时,该模型达到纳什均衡。以Maltotriose为例,根据真实太赫兹光谱数据生成数据。在实验设置中,设置最大迭代次数300 000次,每迭代1 000次模型保存一次数据。随机选取5种不同迭代次数图,如图2所示。当迭代次数为1 000轮和5 000轮时,生成的数据仅为随机噪声。随着迭代次数的增加,生成器不断学习。当模型迭代次数达到100 000轮时,生成数据逐渐类似于真实数据分布,当达到200 000轮时,WGAN模型所输出的生成数据分布基本符合真实Maltotriose数据分布。在对Maltotriose进行扩展数据时,选取迭代200 000轮后的生成数据。

图2 不同迭代次数下WGAN的生成数据图(a):原始数据;(b),(c),(d),(e),(f)分别代表迭代1 000轮,5 000轮、10 000轮、100 000轮和200 000轮后的生成数据Fig.2 WGAN generated data graphs under different iterations(a) is the original data;(b),(c),(d),(e),and (f) respectively represent the generated data after 1 000 iterations,5 000 rounds,10 000 rounds,100 000 rounds,and 200 000 rounds
为了验证WGAN处理不均衡数据集的效果,将三种不均衡物质的数据组成数据集Database1,经WGAN扩展后的均衡数据集为Database2。数据集中各物质光谱数据如下:(1)Database1:在数据库中随机抽100条Maltotriose数据、900条Malthexaose数据和8100条Maltoheptaose数据。(2)Database2:使用WGAN生成的数据将Database1中每种物质的数据补充为8 100条。在数据库中随机抽取每种物质2 700条数据作为测试集。
3 结果与讨论
数据集不均衡会对传统的机器学习模型系统产生负面影响。为了缓解此问题,将WGAN用于生成太赫兹光谱数据,以便使太赫兹光谱数据集达到类别均衡。实验证明,使用WGAN生成数据并扩展数据集,能够有效解决小样本数据偏向大样本数据问题。表1和表2分别为SVM模型在Dataset1和Dataset2数据集下训练后测试集的混淆矩阵。

表1 使用Database1训练模型后测试集的混淆矩阵Table 1 Confusion matrix of test database after training model with Database1
从表1可以看出,Maltotriose和Malthexaose都出现被预测为Maltoheptaose的现象,其中Maltotriose最为明显。但是没有大量Maltoheptaose被预测为其他两种数据的现象。
表2相比于表1,在数据预测偏向上得到改善,每种数据的偏向现象并不明显,其中,Maltotriose和Malthexaose并没有大规模偏向Maltoheptaose。根据表1,使用Dataset1进行SVM训练的模型测试集的预测准确性仅为65.69%。但是,当使用Database2训练SVM时,模型精度提高到91.54%,均衡数据集上SVM的识别准确率比不均衡数据集提高25.85%。为了证明WGAN在处理不均衡太赫兹光谱数据上的优越性,将WGAN与其他处理不均衡数据集的方法进行了比较,并以验证集的准确性作为度量。表3为不同不均衡数据集处理方法的准确率对比。
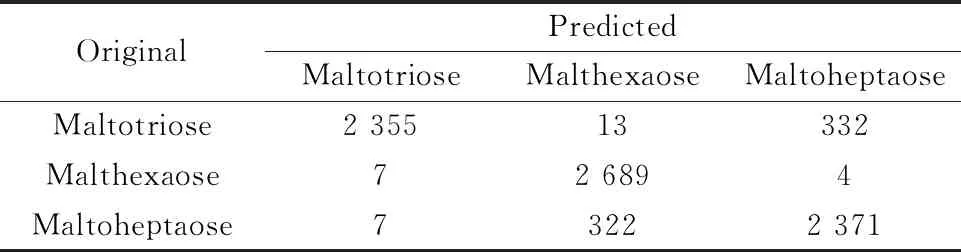
表2 使用Database2训练模型后测试集的混淆矩阵Table 2 Confusion matrix of test database after training model with Database2
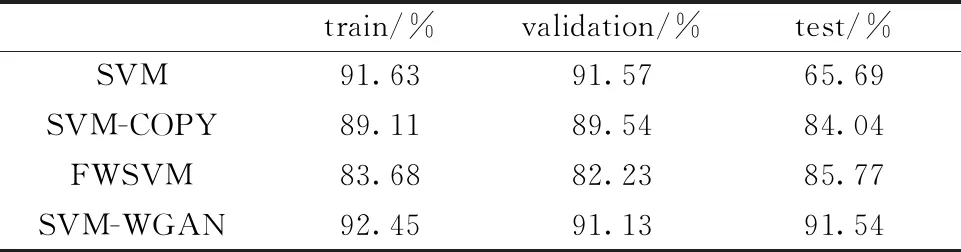
表3 不同算法下数据集的准确性对比Table 3 Comparison of the accuracy of the dataset under different algorithms
由表3可知,4种分类算法在dataset-1数据集上的训练集及验证集的准确率都能达到80%以上。虽然未采用扩展数据的SVM模型能在训练集和验证集上得到良好的识别准确率,但是在测试集上由于不均衡数据固有的缺点,导致识别准确率很差。SVM-COPY和FWSVM的测试集准确率都在85%左右,这两种方式是现阶段比较流行的处理不均衡数据集的方法,但是由于并没有在数据集中增加有效的太赫兹光谱数据,所以测试集上的识别效果不是太理想。因此,利用WGAN模型能够有效的生成太赫兹光谱数据,同时又能保证模型识别准确率。
不均衡度也是影响不均衡数据分类识别准确率的因素之一,为了验证WGAN在不同不均衡度下的有效性,将不均衡度为16,81和256的数据集分别组成Imbalance1,Imbalance2和Imbalance3数据集,通过WGAN扩展后的数据集为Imbalance1_WGAN,Imbalance2_WGAN和Imbalance3_WGAN数据集。实验结果表明,不均衡度对测试集影响较大,随着不均衡度的增加,测试集整体识别率呈现下降趋势。通过使用WGAN扩展数据集后,可以有效改善这一现象。表4为不同不均衡度下的识别率对比。
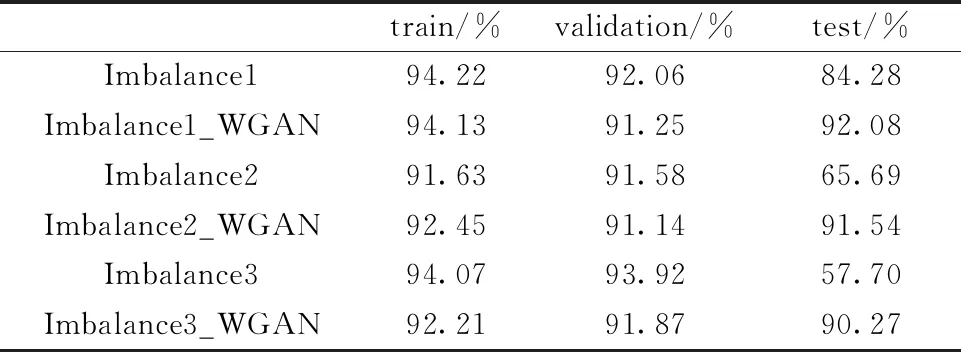
表4 不同不平衡度下训练集和测试集的准确率对比Table 4 Compares the accuracy of the training set and test set of the dataset under different unbalance
4 结 论
针对太赫兹光谱数据库中不均衡数据的分类问题,提出一种基于WGAN的太赫兹光谱识别方法。利用生成对抗网络生成符合真实太赫兹光谱数据分布的生成数据,扩充太赫兹数据集,解决类别不均衡问题。相比于传统方法,该方法能自动从真实数据中学习数据分布并生成数据。不仅能有效扩充太赫兹光谱数据库,并且有较高的识别率。由于基于生成对抗网络的太赫兹光谱识别方法可与多种机器学习方法相结合,并能适应不同不均衡度的要求,所以在未来实际应用中有广阔的前景。
猜你喜欢
数码设计(2020年16期)2020-12-08
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
雷达学报(2018年1期)2018-04-04
雷达学报(2018年1期)2018-04-04
雷达学报(2018年1期)2018-04-04
数学物理学报(2017年5期)2017-11-23
电子技术与软件工程(2016年8期)2016-07-10
中兴通讯技术(2016年2期)2016-03-24
北方经贸(2014年8期)2014-09-21
