
数据驱动的AVS3 像素域最小可觉差预测模型
2021-02-04 06:28李兰兰刘晓琳吴珂欣林丽群魏宏安赵铁松
数据采集与处理 2021年1期
李兰兰,刘晓琳,吴珂欣,林丽群,魏宏安,赵铁松
(福州大学物理与信息工程学院,福建省媒体信息智能处理与无线传输重点实验室,福州350108)
引 言
大数据时代促进多媒体技术和现代通信技术的迅速发展,也为视频技术带来新的机遇与挑战。视频能够最大程度地表达内容,是人们生活中不可缺少的一部分。视频压缩技术主要是通过去除视频数据中的各种冗余信息来提升视频压缩比,便于视频的储存传输。目前的视频编码标准针对视频数据进行压缩编码,去除了大量时域冗余和空域冗余,但仍存在部分的视觉感知冗余。为了使视频的压缩性能得以进一步提升,研究人员通过研究人眼视觉感知系统特性(Human visual system,HVS),将视觉感知冗余数量化,并将其运用到视频编码标准中。
基于HVS 构建的最小可觉差(Just noticeable distortion,JND)模型对视觉感知冗余的量化估计较为准确,对感知视频编码优化效果较好。JND 模型是从心理学的角度出发,通过模拟人类视觉系统的感知特性得到人眼的最低视觉门限阈值,当变化值低于阈值时,人眼将无法觉察出该变化。对于JND 模型的研究,文献[1]提出了JND 阈值的产生原因是潜在的时空敏感性和空间掩蔽效应。文献[2]介绍了无序隐藏对JND 估计的影响。文献[3]提出通过使用视觉显著性来调整JND 阈值,消除更多的感知冗余。文献[4]提出了一种结合视觉显著性和JND 量化控制算法,为每个编码树单元分配自适应的量化参数,节省比特率。文献[5]提出了一种基于感知失真度量的高效视频编码早期SKIP 模式决策方法,节省了时间复杂度。
JND 模型主要分为像素域JND 模型和变换域JND 模型,根据二者不同的特性作用在不同的领域。变换域的JND 模型适用于边缘区域和纹理区域的JND 阈值估计,因此在图像/视频处理中应用较为广泛[6-7]。文献[8]提出了一种更广义的离散余弦变换(Discrete cosine transform,DCT)域中的可见性模型,可以估计DCT 核任意大小且残差变换系数任意分布的失真可见性程度,实现了比特率降低的显著性能改善。文献[9]通过结合HVS 的双目特性、背景亮度和每个DCT 分量的空间频率,提出了一种DCT 域的三维最小可觉差模型,可以在保持图像主观质量损失较低情况下节省比特率。文献[10]通过将视频压缩中的量化操作应用到PVCJND 建模中,提出了一种显著量化失真模型,用于任何视频压缩方案之前的预处理。
像素域JND 模型由于其阈值表示的意义更加直观而常被用于视频编码的运动估计、率失真优化以及预测残差块的自适应滤波。文献[11]提出将JND 感知模型应用于H.264/AVC 编解码器,通过JND阈值自适应地控制编码器的残差量化,从而提高率失真性能和整体压缩效率。文献[12]提出一种基于视觉注意力的像素域JND 模型,通过自适应调节拉格朗日乘子实现根据视觉冗余度调节率失真的优化过程。文献[13]通过建立JND 模型对原始的率失真优化算法进行改进,利用JND 值自适应修正量化参数和调节朗格朗日乘数,实现编码比特和失真的感知平衡。文献[14]提出了一种基于变换域与像素域结合的即时差分JND 模型,对于HEVC 的变换跳过模式采用了现有的像素域JND 模型,对于变换非跳过模式则采用变换域JND 模型,以进一步减少感知冗余。
目前的AVS3 视频编码标准[15]主要是基于客观度量标准来编码视频数据,在消除视频时域/空域冗余信息方面发挥了很大的作用,但在消除感知冗余方面仍存在进一步优化的空间。在AVS3 视频编码中应用JND 计算视觉感知冗余,可以进一步提高视频编码性能。本文提出通过主流的JND 大型主观数据集来获取人眼真实的像素域JND 阈值,基于深度神经网络构建符合主观感受的像素域JND 预测模型,在AVS3 中嵌入像素域JND 阈值构建的自适应残差滤波器进行编码优化,可以在保证人眼主观感知体验质量几乎不变的情况下节省更多的码率,优化AVS3 视频编码器。
1 像素域JND 预测模型
1.1 基于数学统计的像素域JND 模型
像素域JND 模型能够更加简单直观地数量化感知冗余。像素域JND 阈值影响因素主要有两个:亮度自适应掩蔽和纹理掩蔽。亮度自适应掩蔽指的是人类视觉系统对相对亮度更加敏感。大量研究表明,亮度自适应掩蔽阈值与背景亮度之间满足一种如图1 所示的非线性“U”形关系[16]。纹理掩蔽效应是指人眼对于纹理复杂区域所能容忍的JND 阈值要高于纹理平坦区域,因此现有的大部分像素域JND 模型的基础框架都是将亮度自适应与纹理掩蔽进行非线性叠加,如式(1)所示。
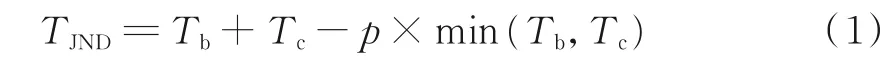
式中:TJND表示像素域JND 阈值;Tb表示亮度自适应掩蔽;Tc表示纹理掩蔽;p 为可以补偿掩蔽因子之间重叠的增益减少因子,通常取经验值0.3。
大部分像素域JND 模型主要是通过分析各种人眼视觉特性,优化如式(1)所示的像素域JND 基础模型,通过数学公式推导出像素域JND 阈值。然而各种研究表明人眼视觉特性非常复杂且受很多因素影响,数学模型推导的像素域JND 阈值无法考虑到所有影响因素,与人眼真实视觉感知存在一定的偏差,无法完全符合人眼主观感知特性,较难保证不同视频编码场景的适应性。

图1 亮度自适应阈值与背景亮度关系图Fig.1 Relation between luminance adaptive threshold and background luminance
1.2 基于数据驱动的像素域JND 模型
深度学习的发展为图像视频编码领域带来了新的发展潜力。与基于数学统计方法构建的JND 模型不同,通过深度神经网络构建合适的像素域JND 模型,能够实现适应更多场景和更符合人眼真实视觉感知体验的像素域JND 阈值预测。因此本文提出基于现有的大型视频主观数据库VideoSet[17]获取符合人眼真实的像素域JND 阈值,通过获取的像素域JND 阈值和VideoSet 视频集来构建像素域JND预测模型。由于VideoSet 主观数据库涵盖了多种场景下的JND 统计,因此本文基于该数据库构建的像素域JND 预测模型能够适用于更多的视频编码场景。
1.2.1 基于主观数据库的像素域JND 阈值
VideoSet 主观数据库是根据JND 理论测量的大规模主观测试数据集,视频集包括220 个5 s 序列,每 个序列具有4 个分 辨 率(1 920 像素×1 080 像素,1 280 像素×720 像素,960 像素×540 像素和640 像素×360 像素),共有880 个未压缩的视频序列。通过ITU-R BT.2022[18]建立主观实验环境进行大量的主观实验,统计得出每个原始视频所对应的最小可觉差的量化参数QJND。
本文通过对原始视频与对应的压缩视频(量化参数为QJND)组成的视频对进行处理,获得每个原始视频的像素域JND 阈值。为了增加数据的多样性和数量,在神经网络进行训练时有更好的泛化性能。本文将原始视频和对应压缩视频切割成大小为64 像素×64 像素的编码宏块(Large coding block,LCU)。通过计算每个原始视频LCU 与对应压缩视频LCU 的平均绝对误差(Mean absolute error,MAE),将其作为原始视频LCU 块像素点的像素域JND 阈值,如式(2)所示。

式中:l(i,j)为原始视频像素值;l′(i,j)为对应的压缩视频(量化参数为QJND)像素值;m 为LCU 的边长64。
对计算所得的每个LCU 的像素域JND 阈值进行统计分析,分布规律为纹理复杂的LCU 像素域JND 阈值较大,纹理简单的LCU 像素域JND 阈值较小,符合像素域JND 阈值分布的一般规律。原始图像与加入计算所得的像素域JND 阈值噪声后的失真图像对比以及局部细节图对比如图2 所示。从对比图中几乎无法察觉到原始图像与失真图像之间的区别,因此本文利用VideoSet 主观数据库获得的像素域JND 阈值在很大程度上符合人眼视觉主观感受。

图2 原始图像与失真图像对比Fig.2 Comparison of original and distorted pictures
1.2.2 J-VGGNet 网络构建
由于像素域的JND 阈值产生原因主要与背景亮度和纹理分布相关,并且大量研究表明人眼对于亮度敏感而对于色度并不敏感,因此本文将每个原始视频LCU 块的灰度图矩阵作为神经网络的输入,而目标变量为每个LCU 块的像素域JND 阈值TJND-LCU,表达式为

式中:p(x,y)为原始视频LCU 块内每个像素点灰度值;m=64。预测函数基于改进后的J-VGGNet 网络实现。

图3 J-VGGNet 结构图Fig.3 Framework of J-VGGNet
本文提出的J-VGGNet 网络主要是以VGG16[19]网络模型作为基本网络结构,其结构如图3 所示。VGG16 网络拥有较深的网络结构和较小的卷积核与池化核,使其能在参数个数一定的情况下获取更多图像特征,因此本文所提出的像素域JND 预测模型通过深度神经网络来提取图像特征,与数学统计的JND 模型人工提取图像特征的方式相比表现更佳。
VGG16 网络每个卷积层之后紧跟Relu 激活函数可增加其非线性特性,因此本文构建的深度像素域JND 预测模型可以充分拟合复杂的非线性关系。由于本文主要将VGG 网络用于提取图像特征后进行非线性预测,与原来的VGG16 相比,所提出的J-VGGNet 对于卷积层做了精简并去掉了用于分类的Softmax 激活层,减少了网络训练参数,训练速度得到提升。因此本文的J-VGGNet 网络主要结构包括10 个卷积层和3 个全连接层。
本文所提出的J-VGGNet 网络的优化算法主要是采用了随机梯度下降法(Stochastic gradient descent,SGD),并结合了动量梯度下降法,动量参数设为默认值0.9。由于该网络主要是用于进行非线性预测,故选用均方误差(Mean square error,MSE)作为损失函数,计算公式为

训练样本为VideoSet 视频集中未进行压缩的原始视频LCU,样本标签为通过VideoSet 数据库所获得的LCU 像素域JND 阈值。将处理之后的样本集分为训练集与验证集,并按照9∶1 分布,训练集由257 400 对数据组成,验证集由28 600 对数据组成。深度学习框架选择Pytorch,迭代次数设为50 次,Batch_size 设定为64。
2 自适应JND 残差滤波
通过以上构建的JND 模型可以预测出与人眼视觉特性相符合的像素域JND 阈值。本文基于该模型所预测的像素域JND 阈值构建自适应JND 残差滤波模型,并将其嵌入AVS3 标准的高性能编码平台HPM 中进行编码,如图4 所示。先将视频信号信息传入已经训练好的JND 模型中,对每帧视频信号进行分块得到LCU,再预测出每个LCU 块的像素域JND 阈值,基于文献[20]的残差滤波公式构建自适应JND 残差滤波器,将其嵌入运动补偿与残差块变换量化之间的位置。自适应JND 残差滤波计算公式为

图4 本文所提算法框图Fig.4 Framework of the proposed algorithm

式中:p(x,y)为原始残差像素值;p′(x,y)为经过滤波后的残差像素值为残差块的平均像素值。当残差块像素点值与平均像素点值之差小于TJND-LCU时,将该残差像素值设为平均值若差值绝对值大于TJND-LCU,则对残差像素值进行自适应调整。
3 实验结果及分析
为验证本文提出的JND 模型对AVS3 视频编码的优化效果,将基于JND 阈值所构建的自适应残差滤波器引入AVS3 的高性能编码平台HPM 中,并且以HPM5.0 为参考进行测试。本次测试采用的是AVS3 标准的通用测试序列,共6 组,其中测试序列Basketball 和Cactus 分辨率为1 920 像素×1 080 像素,其他4 组测试序列分辨率为1 280 像素×720 像素。HPM5.0 的配置文件为encode_RA.cfg;编码使用的量化参数Q 为22、27、32 和37;最大LCU 尺寸为64 像素×64 像素,最大划分深度为4。
表1 描述了嵌入本文算法模型的AVS3 视频编码框架与AVS3 标准视频编码框架HPM5.0 的编码比特数和Y 分量峰值信噪比Y-PSNR 值的对比,图5 给出了本文算法模型与HPM5.0 的测试序列编码比特数的直观对比。图6 为HPM5.0 和所提算法模型解码视频的主观感知对比。表1 中ΔB 为节省比特率,其计算公式如式(6)所示。其中Bref为HPM5.0 编码比特数,Bpro为所提算法模型编码比特数。

编码时间复杂度计算公式如式(7)所示,其中Tref为HPM5.0 编码时间,Tpro为所提算法模型编码时间。

结合表1 和图5 可以看出,本文所提出的模型算法与AVS3 标准视频编码框架相比,节省了最高21.52%、平均5.11%的码率,且编码时间没有增加。由此可说明在保证客观质量差异较小的情况下,本文提出算法模型在一定程度上可以提升视频压缩率。
多尺度结构相似性(Multi-scale structural similarity,MS-SSIM)是结构相似性(Structural similarity,SSIM)评估方法的改进,用来衡量两幅图像多种尺度下的结构相似性平均值,最大值为1。MSSSIM 平均差异值表示HPM5.0 标准算法的解码视频与本文算法模型解码视频之间的相似度差异值。由于MS-SSIM 考虑到了人眼视觉系统特性,可以较好地反映人眼的主观感受,与主观评价相似度高,因此可作为客观评价指标PSNR 的补充。目前,MS-SSIM 已被AVS3 标准采纳为质量评价算子。因此本文采用MS-SSIM 对HPM5.0 标准算法和所提出的模型算法进行主观质量评价,如表2 所示。结合表1、2 可以看出,当码率平均节省5.11%时,所提算法模型解码视频与HPM5.0 解码视频的Y 分量MS-SSIM 平均差异值仅为0.000 429,几乎可以忽略不计。
传统图像质量客观评价标准PSNR 不能很好地反映人眼感知失真,为了验证所提算法主观感知质量与比特节省率关系,本文进行了主观质量测试实验,实验结果如图7 所示。所有的测试人员均在相对安静的环境中进行主观实验,实验中要求每个测试者观看2个连续显示的编码视频,并且比较所提算法的编码视频与HPM5.0 编码视频哪个感知质量更好。主观实验中27 位测试人员对每个序列编码视频对的主观感知结果统计表明:认为本文所提算法编码视频质量更好的总人数与认为HPM5.0 编码视频质量更好的总人数各占50%左右。由此可以认为,测试人员感受不出HPM5.0 编码视频与所提算法编码视频的感知差异,即本文所提出的像素域JND 预测模型编码视频与HPM5.0 编码视频相比可认为是感知无损的。
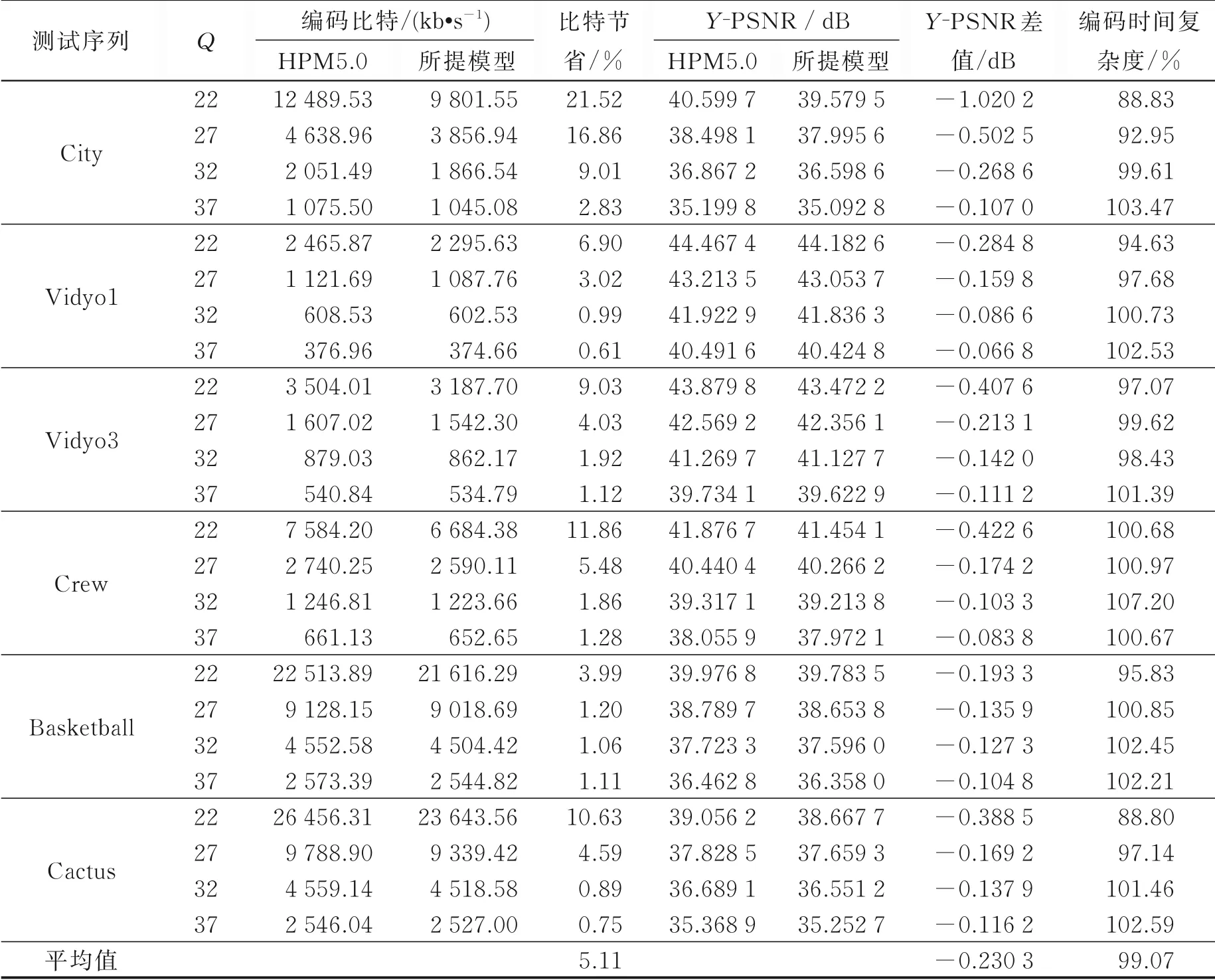
表1 本文所提模型与HPM5.0 的码率对比Table 1 Bitrate comparison of the proposed model and HPM5.0

图5 本文所提模型与HPM5.0 测试序列编码比特数对比Fig.5 Bitrate comparison of the proposed model and HPM5.0 on test sequences

图6 测试视频序列解码视频对比(Q = 27)Fig.6 Comparisons of the reconstructed frame of the test sequence(Q = 27)

表2 本文模型与HPM5.0 的Y 分量MS-SSIM 平均值对比Table 2 Comparison of Y-MS-SSIM of the proposed model and HPM5.0
结合表1 和图7 主观实验结果可以说明,所提算法可以在节省一定码率的情况下保证主观感知质量无损,从而达到消除感知冗余、优化AVS3 视频编码器的目的,体现了所提算法在编码性能上的先进性。

图7 主观实验结果Fig.7 Subjective experimental results
4 结束语
本文提出了一种基于神经网络和大型JND 主观数据库构建的像素域JND 预测模型,并将该模型引入AVS3 视频编码器中进行编码优化,一定程度上消除了编码过程中的感知冗余。为了验证所提算法模型性能,本文设计了客观实验和主观实验。实验结果显示,与HPM5.0 标准算法相比,所提模型在降低编码码率的同时,主观感知质量几乎没有损失,对AVS3 的编码优化效果较好。下一步将考虑结合时域影响因素对JND 预测模型进行调整,消除更多感知冗余,进一步提升AVS3 编码效果。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
中共云南省委党校学报(2022年1期)2022-04-26
北京航空航天大学学报(2020年10期)2020-11-14
小学生优秀作文(低年级)(2020年4期)2020-07-24
自动化学报(2019年6期)2019-07-23
快乐语文(2019年9期)2019-06-22
中学生数理化·八年级物理人教版(2018年11期)2019-01-31
优雅(2016年12期)2017-02-28
北极光(2016年6期)2016-08-17
电影故事(2016年5期)2016-06-15
