
基于改进D-S证据理论数据融合的路段单元交通状态判别方法
2021-02-11 15:00王玉婷蔡晓禹
交通运输研究 2021年6期
王玉婷,李 静,蔡晓禹
(1.山地城市交通系统与安全重庆市重点实验室,重庆 400074;2.重庆交通大学交通运输学院,重庆 400074)
0 引言
高德地图2021 年1 季度发布的《中国主要城市交通分析报告》显示,我国361 个城市中,有59%的城市在通勤高峰时处于缓行状态,有1.66%的城市处于拥堵状态。由此可见,交通拥堵给城市交通运行带来了较大的挑战,亟需有效的应对措施。目前,准确的交通状态判别是智能交通领域的热点研究方向之一,也是实施有效管控措施、缓解拥堵问题的重要基础[1]。
国内外学者对数据融合、道路交通状态判别等已进行大量研究。按照获取方式划分,交通领域的数据可分为两类[2],一类是由传统的固定式检测器(如感应线圈、地磁等)获取的数据;另一类是移动型交通数据,如GPS 浮动车数据、手机信令数据、车联网数据等。单一来源数据面临信息不完整、不可靠等问题,需靠多源数据融合来弥补其不足。面向多源数据的融合算法中,基于多传感器数据的融合算法涉及分布式融合技术、卡尔曼滤波技术、有序加权平均法、模糊积分法、神经网络法等[3]。应用在交通领域,研究人员提出了基于交通流理论非线性函数的数据融合算法[4]、考虑虚假数据和交通状态的数据融合算法[5]、基于置信张量的数据融合算法[6]、D-S 证据理论融合算法等。在D-S证据理论方面,Wang等研究了基于证据理论的空域拥塞预测技术[7];胡林等对传统D-S 证据理论进行了改进,解决了证据的可信度问题,并将改进后的D-S 证据理论应用于车辆导航的地图匹配中,确定了车辆位置信息和方向信息判断规则[8]。已有的交通状态判别方法主要分为三类,分别为:宏观基本图法[9]、历史数据驱动的交通状态识别算法[10-12]、基于实时检测数据的交通状态识别方法。
综上,道路交通状态判别相关研究已积累了丰富成果,但尚存不足:(1)利用不同类型车辆数据进行判别时,通常采用统一的交通状态划分标准,未考虑不同类型车辆运行的差异性;(2)基于浮动车数据的交通状态判别研究大多只使用出租车或公交车一种浮动车数据,数据源较单一、状态判别结果较难全面反映实际情况。而DS 证据理论能将具有差异性的数据通过不精确推理进行融合,得到更客观、更符合实际的结果。鉴于此,本文考虑不同类型车辆运行的差异性,利用出租车、公交车、私家车3 种浮动车数据作为数据源,针对不同车种浮动车数据的差异及样本的不均衡性,引入D-S 证据理论并对其进行改进,来融合不同车种的浮动车数据,充分挖掘其中蕴含的交通信息,实现路段交通状态的准确判别。
1 不同车种浮动车数据特征分析
1.1 速度分布
不同类型车辆在车型尺寸、动力性能、服务对象等方面存在差异,因此其在交通流中的运行速度也各不相同。本文以重庆市江北区五红路路段单元为研究对象,采集了各类型浮动车在“畅通-拥堵-畅通”这一连续的状态变化过程中的速度数据,采样时间为2018 年11 月27 日14:00—19:00,数据样本情况如表1所示。通过数据预处理,得到以5min为时间间隔的各类型车辆速度平均值随时间变化的趋势图,如图1所示。
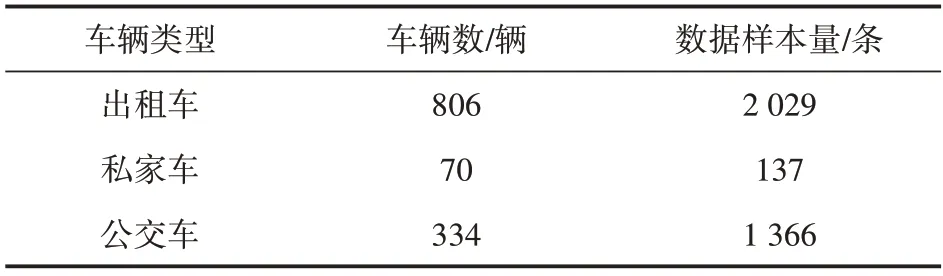
表1 各类型浮动车采样情况
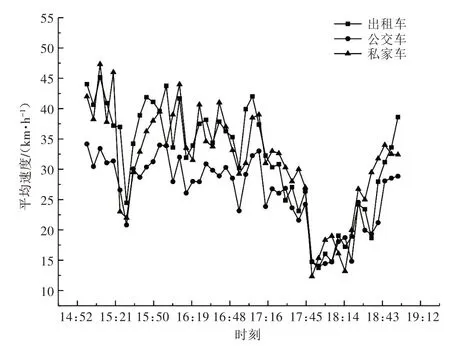
图1 不同类型车辆平均运行速度
图1 中,15:00—17:00 为非拥堵时段(15:30速度下降是因为发生了交通事故),17:00—19:00为拥堵时段。由图1 可看出,不同类型车辆在平均运行速度上存在明显差异,公交车的平均运行速度在拥堵前明显小于私家车和出租车,拥堵时3种车辆的运行速度几乎相同。
本文结合现有交通状态分级类别数[13]和交通流变化情况,将交通状态划分为畅通、较畅通、缓行、拥堵4 个等级。通过重庆市五红路路段单元的视频录像,分别对不同类型的浮动车提取各交通状态下的车辆瞬时速度,并求其标准差,得到各类型浮动车速度标准差随交通状态的变化趋势,如图2 所示。

图2 不同交通状态下不同类型车辆速度标准差对比
从图2 可看出:(1)在相同交通状态下,不同类型车辆速度离散程度存在明显差异,其中公交车的速度离散程度明显小于出租车和私家车;(2)同一类型车辆在不同交通状态下速度离散程度不同,整体均呈现出随着交通拥堵的加剧,离散度逐渐减小的趋势。
1.2 交通状态划分标准
采用模糊C-均值聚类(Fuzzy C-Means,FCM)算法确定交通状态划分标准,以其输出的聚类中心值作为各交通状态中的特征值,本文用速度表征交通状态特征值。由于1.1 节中提及的路段单元车速数据涵盖了从畅通到拥堵的4种交通状态,且各状态持续时间几乎相同,因此,由该路段单元数据获取的各交通状态的特征值能较好地反映实际交通运行状况。分别提取不同类型浮动车的速度数据进行模糊聚类,得到各交通状态特征值(见表2)。

表2 交通状态特征值对比
从表2 可看出,出租车与私家车的交通状态特征值差异不显著,两者与公交车在畅通与较畅通状态下特征值存在显著差异。
1.3 样本特征
受车辆出行随机性和浮动车覆盖率的影响,相同采样间隔下不同类型浮动车数据获取的样本量不同,而浮动车数据样本量与交通状态判别结果可信度之间存在相关关系。一般情况下,样本量越大,交通状态的判别结果准确性越高。
数据越聚集,用于反映数据总体趋势所需的样本量就可以越小;数据越离散,所需的样本量则越大。从图2 可看出,所有类型车辆在畅通下的速度离散度均最大,因此,在进行该状态判别时所需的样本量也应最大。
本文提取畅通状态下各类型浮动车的瞬时速度信息,分析各类型浮动车数据样本量与交通状态判别结果可信度间的关系。实验方法采用随机抽样,步骤如下:
第1 步:选取畅通状态下某一种浮动车车辆的所有瞬时速度作为抽样的总体。
第2 步:从总体中每次随机抽取n条数据样本(n=1,2,…,m),每条样本抽取次数k=100。
第3 步:针对每一次抽取的样本量方案,计算瞬时速度平均值v。
第4 步:计算v与对应数据聚类中心的欧式距离,欧氏距离最小者对应的交通状态即为判别出的路段单元交通状态。
第5 步:将不同样本量方案的交通状态判别结果与标准状态(畅通)进行对比,计算可信度。
第6 步:利用SPSS 软件拟合出数据样本量与交通状态判别结果间的函数关系式。
第7 步:重复第1 步~第6 步,获得3 种浮动车交通状态判别结果可信度为100%时所需的最小数据样本量,以及当样本量小于最小样本量时,交通状态判别结果的可信度大小。
根据以上步骤,计算出3 类车辆数据样本量与交通状态判别结果可信度间的关系如下:

式(1)~式(3)中:Pt为出租车数据交通状态判别结果的可信度;Pc为私家车数据交通状态判别结果的可信度;Pb为公交车数据交通状态判别结果的可信度;n为浮动车数据样本量(条)。
从以上关系式可看出:①出租车、私家车、公交车用于交通状态判别的最小数据样本量各不相同,当交通状态判别结果可信度为100%时,所需的最小数据样本量分别为18 条、25 条、16条;②不同浮动车数据样本量与交通状态判别结果可信度之间的关系式也各不相同。
以上结果表明,不同类型的浮动车数据在运行速度分布、交通状态划分标准方面存在差异,因此有必要针对不同类型的数据分别确定交通状态划分标准,避免因标准不同而导致的交通状态判别误差。而针对不同浮动车数据样本的差异性特征,在进行数据融合时应考虑样本量导致的各浮动车交通状态判别结果可信度。
D-S 证据理论能将具有差异性的数据通过不精确推理进行融合,得到更客观、更符合实际的结果。因此,本文将采用D-S 证据理论进行各浮动车数据的融合,从而实现交通状态判别。
2 D-S证据理论基本原理
假设现有一个问题需要判别,问题所有可能答案所构成的非空论域用Θ表示,Θ为识别框架,Θ={θ1,θ2,…,θj,…,θN},其中θj为识别框架的一个元素或一个事件,j=1,2,…,N,N为元素个数。在Θ中,基本信任分配函数m满足从2Θ→[0,1]的映射关系,设A表示Θ中的任一子集,记作A⊆Θ,基本信任分配函数满足如下条件[14]:

式(4)中:m(A)为事件A的基本信任分配函数,其反映了证据对事件A的信任程度;m(∅)=0 表明证据对于空集的信度为0;=1 表示证据赋予所有子集的信任度之和为1[15]。
由于数据源之间相互独立且不同的数据源检测误差不同,因此得到的基本信任分配函数存在差异。为提高目标检测准确度,D-S 合成规则具备对多个独立数据源所提供的信息进行融合的能力,该合成规则如下:

式(5)~式(6)中:m(A)含义同式(4);K表示所有证据间的冲突程度。K越大,表示证据间冲突越高;当K→1-时,为高冲突;当K<1 不成立时,证据无法合成。
3 基于改进D-S 证据理论的交通状态判别
针对D-S 证据理论处理高冲突证据时会存在结果与常理相悖的问题,国内外学者进行了深入分析,指出造成这种不足的原因有:①证据源本身问题,证据源的基本信任分配函数本身不合理,导致融合结果错误;②合成规则问题,传统D-S 证据理论的合成规则将数据源间冲突信息丢弃,导致融合结果不合理。本文考虑数据源在融合过程中自身数据的可靠性以及对数据源间冲突信息的合理分配,对D-S 证据理论从修正证据源和优化合成规则两方面进行改进,并基于改进的D-S证据理论构建路段单元交通状态判别模型。
3.1 改进的D-S证据理论
车辆出行的随机性以及检测误差等的影响会导致在同一判别时段,不同浮动车数据源采集的样本条数并不相等,可能出现某一种浮动车样本极少甚至没有的情况。如果样本少的数据源正好出现检测误差,那么经由该数据源只会得出错误的交通状态判别结果,会与其他数据源判别出的结果产生冲突。从样本与交通状态判别结果可靠度关系的研究中可看出,当数据样本较少时,该数据判别出的交通状态结果可靠性也较低。因此,在路段单元交通状态判别改进模型中,可利用各数据源交通状态判别结果可靠度对该数据源的基本信任分配函数进行修正,再利用优化后的合成规则进行数据融合,解决样本过少的问题。本文对D-S证据理论的改进方法如下。
(1)修正基本信任分配函数
n个数据源的基本信任分配函数分别为m1,m2,…,mn,数据在融合过程中的可靠度分别为α1,α2,…,αn,则基本信任分配函数修正规则如下[14]:

式(7)中:(Aj)为修正后的数据源i对焦元Aj的基本信任分配函数;m′i(Θ)为数据源i对目标结果的不确定程度。
(2)衡量修正后函数差异性
采用综合相似度衡量修正后基本信任分配函数的差异,综合相似度r的计算公式[16]为:
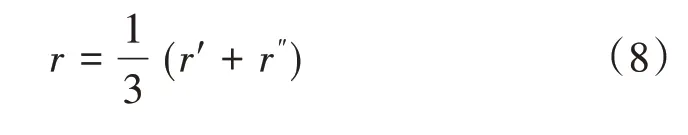
式(8)中:r′为证据间的细粒度相似度,通过模糊理论中的贴近度获得,计算公式如式(9)[17]所示;r″为粗粒度相似度,由粗距离和Pignistic 概率转换函数获得,计算公式如式(10)所示[18-19]。

根据各证据综合相似度,构造研究对象的综合相似度矩阵R:

式(13)中:rij为修正基本信任分配函数后的证据i和证据j间的综合相似度。
(3)确定冲突及不确定性分配权重
证据的支持度计算公式[19]如下:

式(14)中:Supi为证据i的支持度。
证据的可信度反映了在综合考虑所有证据的支持度后,证据在融合过程中的可信程度,其计算公式如下[19]:

式(15)中:Crdi为证据i的可信度。
不确定信息的值如果大于决策中所有目标焦元的信任值,会使得决策无法进行。因此,本文将不确定信息和冲突信息一同分配到各目标焦元中。为确定权重值,本文利用Pignistic 概率转化函数和各证据的可信度,得出所有证据对各目标焦元的综合决策概率w(Sk)。综合决策概率之和为1。用该概率作为冲突及不确定信息的分配权重,其计算公式如下:

(4)优化合成规则
优化后的合成规则将取消归一化的过程,融合结果由3 部分信息组成:证据间的一致信息、冲突信息K、不确定信息C。优化后的D-S 组合规则M(S)如下:

式(17)~式(19)中各参数含义同前。
3.2 交通状态判别模型
设S={S1,S2,S3,S4}为路段单元交通状态类型集合,其中S1,S2,S3,S4分别表示拥堵、缓行、较畅通、畅通状态,则模型的识别框架Θ={S1,S2,S3,S4}。出租车、公交车、私家车3 种浮动车数据源分别为模型中的证据1、证据2、证据3。
路段单元交通状态判别模型涉及的具体步骤如下:
(1)计算各种浮动车在判别时段内的瞬时速度平均值,并统计数据样本条数。

式(20)中:p为数据源类型,p=t,b,c分别表示出租车、公交车、私家车;np为p的采样条数;vp,i为i时刻采集的p类型浮动车的瞬时速度(km/h);为p类型浮动车的瞬时速度平均值(km/h)。
(2)根据各类型浮动车的交通状态划分标准及瞬时速度平均值,各证据的基本信任分配函数mp(Sj)计算公式如下[20]:
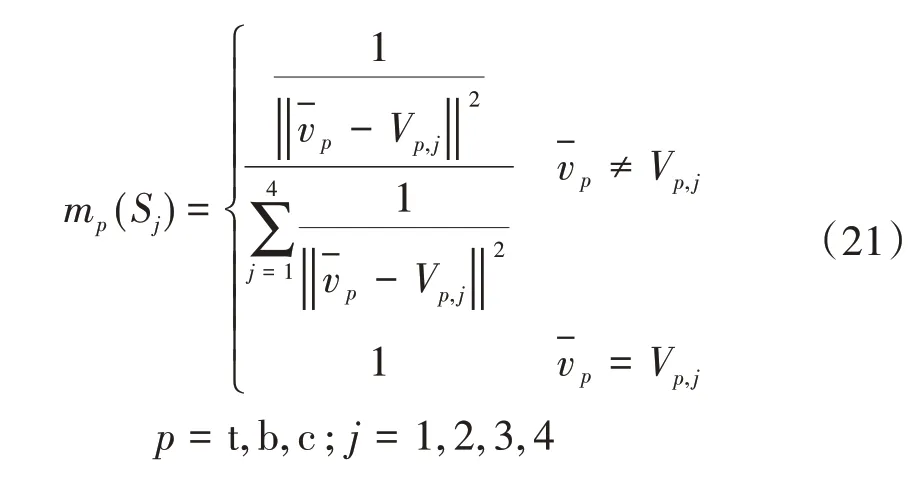
式(21)中:Vp,j为p类型浮动车在交通状态为j时的速度聚类中心值。
(3)利用1.3 节中获得的各浮动车判别结果准确率可信度作为融合过程中的数据可靠度,利用3.1 节提出的改进方法进行数据融合,得到融合后的交通状态判别结果。
4 实证分析
4.1 数据准备
选择重庆市江北区五红路某一路段单元作为交通状态判别效果实验路段单元,数据采集时间为2018年11月28日14:00—19:00。交通状态划分标准由另一与判别路段道路属性相似的路段单元得出,数据采集时间为2018 年11 月27 日15:00—19:00。数据样本量如表3 所示。路段实际交通状态根据拍摄的视频进行人工认定。

表3 各类型浮动车采样情况
4.2 D-S证据理论改进前后判别效果对比
选取2018 年11 月28 日14:00—19:00 三类浮动车速度分布差异较明显时的数据对模型进行测试,该时段采集的各浮动车基本信息为:出租车、公交车、私家车浮动车瞬时速度数据样本量分别为17 条、11 条、4 条,瞬时速度平均值分别为41km/h,30.55km/h,35km/h。该时段的实际交通状态为畅通。
基于传统和改进D-S 证据理论的交通状态判别研究结果分别如表4所示。

表4 多源数据高冲突情况下判别算例结果
由表4 可知:根据出租车数据,交通状态为畅通的可能性最大;根据私家车数据,交通状态为较畅通的可能性最大;根据公交车数据,交通状态为畅通的可能性最大。3 种类型浮动车数据的判别结果存在高度冲突(K=0.804,在左侧靠近1)。传统的D-S 证据理论方法得出交通状态为较畅通,判别错误;本文提出的改进的D-S 证据理论由于在融合时考虑了各浮动车数据样本量大小对融合结果的影响,并且对证据间的冲突信息进行了合理分配,得出了正确的判别结果。这表明本文提出的算法能解决传统D-S 证据理论在融合高度冲突信息时存在的缺陷。
4.3 多算法判别效果对比
从路段单元2 的实验数据中随机选取67 条样本进行模型效果评估,选取的样本组包含了高冲突和低冲突数据,将基于改进D-S 证据理论的判别结果、基于D-S 证据理论的判别结果、基于单一数据源(出租车、公交车、私家车)的判别结果进行统计和对比分析,如表5所示。
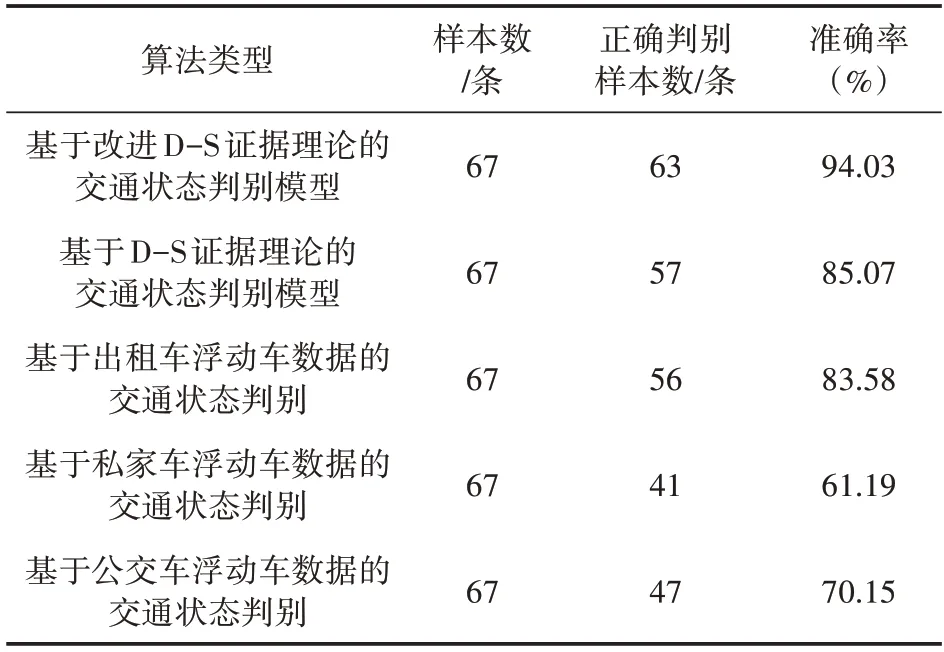
表5 各算法交通状态判别准确率
从表5 可看出:基于D-S 证据理论的判别方法准确率相比基于单一数据源的判别方法准确率有所提升,证明了将D-S 证据理论引入交通状态判别能有效融合不同类型的浮动车数据,提升判别准确率;基于改进D-S 证据理论的模型克服了传统D-S 证据理论在交通状态判别时的缺陷,判别准确率有了进一步提升。
5 结语
本文基于出租车、公交车、私家车3 种不同类型浮动车数据,构建了基于改进D-S 证据理论数据融合的路段单元交通状态判别模型,该模型可解决不同类型浮动车数据间交通状态判别结果高度冲突的问题。实例验证结果表明:
(1)通过引入D-S 证据理论对不同类型浮动车数据进行融合判别,能得到比任一单一浮动车数据源更高的判别准确率,说明D-S 证据理论能有效融合具有差异性的不同类型车辆浮动车数据,提升交通状态判别效果。
(2)本文提出的基于改进D-S 证据理论的交通状态判别模型避免了某一数据源样本量过小时,检测结果中的错误数据给最终融合结果带来的影响,能在一定程度上融合高度冲突的数据源信息,其判别效果相比基于传统D-S 证据理论的判别模型有进一步提升。
本文只对路段单元整体交通状态判别进行了研究,但部分特殊路段单元(包含公交专用道、定向车道等的路段)中不同车道的交通状态还可能存在不均衡性,后续可对这类路段单元各车道的交通状态判别进行研究,为交通管控提供车道级的高精度数据支持。
猜你喜欢
军民两用技术与产品(2022年8期)2022-10-10
内蒙古统计(2021年4期)2021-12-06
中国外汇(2019年19期)2019-11-26
测控技术(2018年4期)2018-11-25
制造技术与机床(2018年11期)2018-11-23
计算机与生活(2018年3期)2018-03-12
制造技术与机床(2017年9期)2017-11-27
中国科技期刊研究(2017年2期)2017-05-14
浙江大学学报(工学版)(2015年2期)2015-05-30
土木建筑工程信息技术(2013年4期)2013-10-17
