
一种基于注意力联邦蒸馏的推荐方法*
2021-02-25 12:16马天翼
软件学报 2021年12期
谌 明,张 蕾,马天翼
(浙江省同花顺人工智能研究院,浙江 杭州 310012)
近年来,随着电商平台和移动互联网的迅猛发展,人们已经步入信息过载的时代.推荐系统作为连接用户和信息的桥梁,正变得越来越重要.目前,主流的推荐系统主要基于大数据下的离线和在线推荐[1,2],但该类推荐系统往往需要收集大量用户个人信息以及浏览、购买等用户行为记录,存在数据隐私泄露的风险.随着《中华人民共和国网络安全法》、欧盟《通用数据保护条例》等一系列严格的数据隐私保护法律法规出台,对此类数据的收集提出更多限制措施.另外,出于政策法规、商业竞争等因素,不同机构间的数据很难互通[3].针对以上问题,联邦学习范式被提出[4,5].该范式可使模型在不上传用户隐私数据的前提下进行联合建模,同时与领域和算法无关,可实现在不同数据结构、不同机构间协同建模,有效保护用户隐私和数据安全[6].
随着5G(the 5th generation mobile communication technology)技术的普及,用户设备端数据的上传速度和下载速度将高达10Gbps 级别,同时,移动设备的响应时间将降至仅1 毫秒级别,相比4G(the 4th generation mobile communication technology)下载速度快6.5 万倍[7];用户数据的爆炸式增长对机器学习模型的训练速度提出更高要求,与此同时,推荐系统随着模型的复杂度越高,联邦学习需要交换的权重系数也越多,给联邦学习下的模型移动端通信开销带来了严峻的挑战[8].知识蒸馏可用于将参数大的复杂网络(教师模型)中的知识迁移到参数量小的简单网络(学生模型)中去,用更少的复杂度来获得更高的预测效果[9].针对联邦学习设备间模型参数多和通信开销大,Jeong 等人[10]将知识蒸馏引入联邦学习场景,用于压缩每台设备模型参数的体量并减少通信次数.但除上述挑战和问题外,推荐系统在数据上仍存在着如下问题.
(1) 用户间行为数据差异较大,通常行为数据体现为长尾分布,使得设备间数据存在高度异质性;
(2) 真实推荐场景下数据大都为非独立同分布(non-IID),但大部分推荐算法往往仍基于独立同分布(IID)假设[11],该假设忽略了非独立同分布可能造成的数据、模型上的异质性.
在联邦蒸馏的场景下,以上问题会造成不同设备数据之间的差异,进而造成设备模型之间的差异.而知识蒸馏的引入,会进一步地扩大教师模型与学生模型之间的分布差异,使全局模型收敛速度慢,准确率低.针对以上问题,还没有针对推荐场景的联邦蒸馏算法及框架被提出.
本文提出基于注意力联邦蒸馏的推荐方法,该方法相比Jeong 等人[10]提出的联邦蒸馏算法做了如下改进.在联邦蒸馏的联合目标函数中加入KL 散度(Kullback-Leibler divergence)和正则项,减少因教师网络和学生网络间的差异对全局模型造成的影响,提升模型稳定性和泛化性能;在联邦蒸馏设备端流程中引入改进的多头注意力(multi-head attention)机制,使特征编码信息更加丰富,提升整体模型精度;提出一种自适应学习率的训练策略,利用混合优化的方法优化联邦蒸馏的联合目标函数,提高模型收敛速度,抵消注意力编码增加的计算量.该方法是目前第一个面向推荐系统场景的联邦蒸馏方法.
1 相关研究
1.1 联邦学习
数据的隐私保护一直是推荐系统的重要研究方向,联邦学习可在不共享隐私数据的情况下进行协同训练,能够有效地解决数据隐私问题[12].国内外一些学者对其进行了研究.Google AI 团队提出了联邦学习方法,该方法在不收集用户数据的情况下,在每台设备上独立完成模型训练,再将梯度数据进行隐私保护加密传输到中心节点服务器(联邦中心),最后,中心节点根据汇总结果将更新后的梯度(全局模型)再回传到每台设备上,从而完成每台设备的梯度和模型更新,解决了用户数据孤岛问题[13-14].目前,机器学习的很多领域都已引入联邦学习,如联邦迁移学习[15]、联邦强化学习[16]、联邦安全树[17]等.Yurochkin 等人[18]提出了贝叶斯无参联邦框架,通过实验证明了效率上的有效性,模型压缩比更低.Liu 等人[19]提出一种迁移交叉验证机制的联邦学习,能够为联邦内的设备模型带来性能提升;他们还提出灵活可拓展的方法,为神经网络模型提供额外的同态加密功能.Zhuo 等人[20]提出一种新的联邦强化学习方法,为每台设备构建新的Q 网络,解决了构建高质量的策略难度大的问题;更新本地模型时对信息使用高斯差分保护,提升了用户的隐私保护能力.Kewei 等人[21]提出一个联邦提升树系统,可以让多个机构共同参与学习,可以有效地提升分类准确率,同时让用户对自己的数据有更多的控制权.也有学者在联邦学习中引入其他算法,并对联邦学习效率问题进行研究.Sharma 等人[22]提出一种隐私保护树的Boosting 系统,能够在精度上与非隐私保护的算法保持一致.Ghosh 等人[23]提出了一种离群对抗方法,将所有节点和异常的设备一起考虑,解决了鲁棒异质优化问题,并给出了分析误差的下界.虽然联邦学习能够解决数据隐私问题,但随着用户数据量和模型复杂度的增加,存在着模型参数多和移动端通信开销大等问题.学者们希望使得通信负载与模型大小无关,只与输出大小有关.将教师模型中的知识迁移到学生模型中,降低复杂度的同时仍能保持较好的预测精度,知识蒸馏便是这样一种知识迁移的方法.
1.2 知识蒸馏
Hinton 等人[24]提出了知识蒸馏,将教师网络相关的软目标作为损失函数的一部分,以诱导学生网络的训练,实现知识迁移.Yim 等人[25]使用矩阵来刻画层与层之间的特征关系,然后用L2 损失函数去减少教师模型和学生模型之间的差异,并让学生模型学到这种手段,而不仅仅是利用目标损失函数进行知识的迁移.Heo 等人[26]利用对抗攻击策略将基准类样本转为目标类样本,对抗生成的样本诱导学生网络的训练,从而有效提升学生网络对决策边界的鉴别能力.但硬标签会导致模型产生过拟合现象,对此,Yang 等人[27]提出了一个更合理的方法,并没有去计算所有类的额外损失,而是挑选了几个具有最高置信度分数的类来软化标签,提高模型的泛化性能.
近些年,有学者提出将联邦学习和知识蒸馏结合起来.Jeong 等人[10]提出了一种分布式模型联邦蒸馏训练算法,能够有效解决用户通信开销大的问题.采用生成对抗网络生成数据,解决用户生成的数据样本非独立同分布的问题.Han 等人[28]提出一种保护隐私的联邦强化蒸馏框架,由事先设置的状态和策略组成,通过交换每台设备的策略值,从而共同训练本地模型,解决了代理隐私泄露问题.然而这些方法在解决非独立同分布问题上主要采用生成对抗网络或强化学习的方法将非独立同分布数据转为独立同分布数据,在实际应用中复杂性较大.
针对前述文献和方法的不足,尤其是因联邦学习回传梯度参数的方法参数多、计算量大、模型训练过程无法自适应调节学习率、蒸馏算法训练速度慢等问题,本文在第2 节提出并详细描述一种基于注意力机制的联邦蒸馏推荐方法.
2 一种基于注意力联邦蒸馏的推荐方法(AFD)
2.1 符号定义
推荐系统中通常包括召回和排序两个阶段:召回阶段对历史数据用协同过滤或其他召回算法召回一批候选Item 列表,排序阶段对每个用户的候选Item 列表进行CTR(click-through rate)预测,最后选取排序靠前Top-n的Item 作为推荐结果.
假设整个系统包含设备集K(共|K|台设备),每台设备包含Item 特征和用户特征,则设备k(k∈K)中的用户特征为Uk,Item 特征为Ik.r为第k台设备上的特征总数.Xk为设备k的本地数据,yk为设备k的本地数据对应的标签,pk为设备k上的本地数据对应的学生模型预测结果.E为全局训练轮数,t为所有数据的标签值(t∈T,T为标签集).Sk为联邦中心收集到的设备k的Logits 向量集合(本文的Logits 向量皆为经过softmax操作后的归一化的 向量值),即为学生模型;S/k为除去设备k后其他设备的Logits,为教师模型,为除去设备k后其他设备的Logits 平均值.本文提出方法所使用的主要符号定义见表1.

Table 1 Definitions of main symbols表1 主要符号定义
2.2 方法整体流程
本文提出的基于注意力和联邦蒸馏的推荐方法(AFD)运行在多个分布式设备中,包括在设备端运行的学生网络和运行在服务器端负责收集、整合、分发教师模型参数的联邦中心.协作流程如图1 所示.

Fig.1 Collaboration flow of attentive federated distillation图1 注意力联邦蒸馏协作流程
具体描述如下:
(1) 每台设备初始化一个基于深度神经网络的推荐(或点击率预测)模型(如卷积神经网络、DeepFM[29]等)作为学生模型,使用设备本地数据进行模型训练.其中,本地设备使用Attention 机制(见第2.4 节)对本地用户特征和商品特征进行编码,融合特征交叉信息得到特征Embedding 表达,并将这些表达作为本地模型的输入进行训练.使用Attention 机制可捕捉更多兴趣特征,同时,编码本身可减少本地用户数据泄露的风险;
(2) 本地模型训练收敛后,设备获取模型参数,并将模型参数上传至联邦中心.这里,上传的模型参数与常规联邦学习中的不同:联邦蒸馏方法上传的参数为本地学生模型最后Softmax层计算出的Logits 向量(每个推荐目标标签对应的Logits 向量,取多轮训练的平均值),而联邦学习方法上传的则是模型权重矩阵.对推荐标签数量较少或点击率预测任务(二分类),使用联邦蒸馏方法可大大减少上传参数的体量,缓解大规模设备下可能造成的通信拥堵;
(3) 联邦中心使用联邦学习算法将接收到的每台设备上传的标签平均Logits 向量整合为新的全局Logits向量.具体地,针对每台设备,联邦中心将其他设备发送的Logits 向量使用联邦学习算法构建出该台设备的教师模型,并将教师模型分发到每台设备中(该步骤具体流程详见表3);
(4) 设备接收教师模型,通过结合自适应学习率策略(见第2.5 节)优化联合损失函数(见第2.3 节),并以此指导学生网络的训练.联合损失函数包含教师网络、学生网络的损失,同时还包含教师网络与学生网络之间的差异度.该步骤算法流程详见表2.
以上描述中,步骤(1)和步骤(3)中的推荐算法和联邦学习算法不限,可根据实际需求自由组合.在下面的章节,我们将详细描述图1 流程及表2、表3 算法中使用的策略.

Table 2 Attentional federated distillation—Processes on devices表2 注意力联邦蒸馏算法——设备流程

Table 3 Attentional federated distillation—Processes on the federated center表3 联邦注意力蒸馏算法——联邦中心流程
2.3 联邦蒸馏
现有的联邦学习算法是对模型权重进行平均,由于推荐系统中模型复杂,权重参数众多,分配到每台设备上,模型参数回传到联邦中心,会占用大量的资源,并且联邦中心计算权重平均值也是一笔巨大的时间开销.当采用现有联邦蒸馏算法的损失函数进行优化时,仅仅分别计算了教师网络和学生网络与真实标签的误差值,却忽略了教师网络和学生网络本身的差异性给模型带来了影响,容易造成模型过拟合.通过实验发现,教师网络和学生网络本身的差异性对模型的推荐效果具有较大的影响.为了减少学生网络和教师网络之间差异大造成的影响,本文提出了一种新的目标函数.相比于传统目标函数只计算本地设备预测值与真实值之间的误差,本文提出的目标函数除了利用其他设备作为教师模型来指导本地学生模型训练,还将学生模型与教师模型之间的差别作为优化目标的一部分加入损失函数,降低设备间数据差异造成的影响.
首先,设备k(k∈K)的本地学生模型及联邦中心分发的教师模型在该设备上的损失函数可分别定义为

其中,f(·)为损失函数,pk和yk分别为设备k中学生模型对本地测试数据的预测值及其真实值,为教师模型 对本设备测试数据的预测值.假设全局模型共需训练E轮,则训练e轮(e∈[1,E])后的联合损失函数由学生模型损失、教师模型损失以及学生模型与教师模型差异组成(表2 第6 行),具体定义如下:

其中,α,β分别为学生模型和教师模型损失的权重参数,λ为正则项权重参数,ωk为设备k的模型参数(如神经网络中的Weights 和Bias),||·||2为L2 范数.为节省参数通信量(传统联邦学习算法如FedAvg 需传输模型参数)并增强模型的泛化性能,本文方法在联合损失函数中增加了L2 正则项(见公式(3)).由于高度偏斜的非独立同分布(non- IID)数据会让学生模型之间的分布差异增大,降低整个模型的收敛效率,本文通过使用KL 散度(Kullback- Leibler divergence)来衡量学生模型和教师模型之间的差异,并将该差异作为全局损失函数的一部分进行优化.差异计算方式如下:

公式(3)中,当e=1 时(即第1 轮全局模型训练),此时联邦中心尚未收集首轮本地设备的模型Logits,本地设备无需从联邦中心接受教师模型的Logits,此时,联合损失仅包含本地学生模型的损失;当e>1 时,联邦中心已完成首轮模型收集并分发教师模型,则本地学生模型的优化可同时使用学生模型、教师模型及学生-教师模型差异进行联合优化.同时,为加速模型收敛速度,本文提出一个可自动切换优化算法及选择合适学习率的优化策略,用于优化联合损失函数(见第2.5 节).优化后的本地学生模型对本地设备数据进行预测,得出新本地模型对应 每个数据标签的Logits,并通过下式更新设备k对应标签t的Logits(表2 第10 行):


联邦蒸馏的过程减少了传统联邦学习过程中的模型权重回收和分发造成的时间和通信开销,能够有效提升整体效率.同时,通过加入KL 散度,将教师模型和学生模型之间的差异性加入到损失函数中进行优化,从而缓解了数据差异带来的影响,提升模型的推荐性能.然而,联邦蒸馏虽然可以缓解Non-IID 的影响,但若设备之间数据差异较大或数据量较少,仍然需要其他优化手段来提高模型的精度.在下面的章节中,本文方法利用特征注意力编码得到特征间更多的交互信息来丰富本地特征.
2.4 特征Attention编码
在推荐场景中,用户兴趣和产品的种类具有多样性,一个用户可能对多个种类产品感兴趣,一个种类可能有多个产品,但最终影响模型结果可能只有其中一部分.以付费服务推荐场景为例:当一个用户同时购买了两个付费产品,很难区分他对哪个产品更感兴趣;但如果其中一个产品连续购买多次,另一个产品只购买过一次,那么说明连续购买年数这一特征,对模型的分类具有更高的权重影响.同时,对于不同的用户,可能是因为不同的特征而决定最后是否会购买.这类场景下,对用户交互过的商品和候选商品做特征Attention 编码尤为重要,可以有效地捕捉用户对不同商品及不同特征之间的差异性.由于不同的用户关注的兴趣点不同,用户兴趣呈现多样性变化,主流的深度神经网络(DNN)模型对用户的历史行为是同等对待,且忽略了时间因素对推荐结果的影响[30],离当前越近的特征越能反映用户的兴趣.然而,现有的基于联邦学习的推荐方法未考虑特征之间的交互关系.为了充分利用历史特征及特征交互信息,本文通过加入一个改进的Attention 机制,在特征向量进入模型训练之前通过Attention 机制计算用户行为权重,得出每个用户不同的兴趣表征.目前,基于Attention 机制的方法[31,32]通常在输出层前加入Attention 层,以捕捉用户和Item 的二阶交叉信息.与这些方法不同,我们并未在模型输出层前加入Attention 层,而是在模型输入前使用.这样做有如下目的:1) 保证框架灵活性,避免侵入现有本地模型的结构; 2) 尽可能丰富输入特征的信息,提高模型精度.
对于每一个用户,有一个等长于特征总数r的Attention 编码,其中,Attention 编码的每一个维度表示该特征的权重(即重要程度).由于用户线上的交互特征通常非常稀疏,当一个用户的特征值只有一个非零特征时,这个特征会得到很高的Attention 得分;而当一个用户有多个非零特征时,受限于Softmax计算的Logits 值,各个特征的Attention 得分反而不高,重点信息难以全部保留.本文使用的Attention 方法主要包含两点改进:1) 由于不同设备中数据特征维度空间不同,提出一种映射方法将不同设备数据映射到相同维度,进而允许其进行Attention操作;2) 增加Attention 编码的维度,增强特征交互的表征能力.
(1) Attention 编码映射
由于每台设备的数据特征空间不相同,首先需要将所有特征统一映射到一个dim维的Embedding 矩阵.具体地,通过创建特征embedding 向量[feature_count,dim],将单阶或多阶特征映射到[b,r,dim].其中,feature_count为所有特征的类别总数,b为一个 minibatch 的数据量(如 16,32),每批次训练数据维度为[b,max_feature],max_feature为所有特征的维度总和,r为特征总数量.映射过程中,若特征为单阶,如连续数值型特征,则特征Embedding 为该数字在Embedding 向量中对应的特征;若特征为多阶,如One-Hot 特征,则使用多阶特征所有特征值在Embedding 向量中对应特征的和作为该多阶特征的Embedding.具体搜索矩阵对第i个特征的Attention权重计算方式如下:

其中,Q为搜索矩阵,Si为特征i的查询键值,(·)T为矩阵转置.映射后的Q维度为[b,1,dim],Si维度为[b,r,dim],Vi维度为映射到[b,r,dim].P(·)为查询项与搜索矩阵的相似度,同时也为搜索矩阵Q对特征的权重系数,维度为[b,1,r].最后,再通过Softmax操作归一化到[0,1].具体如下:

(2) 增加Attention 的维度
传统的self-attention 是在序列内部做attention 操作,每次使用一个用户的特征去查询其和所有其他特征的匹配程度,共进行r轮相同操作得到attention 值.对于每个用户,只有一个等长于r的Attention 矩阵,Attention 矩阵的大小为[b,r].但推荐场景的数据集通常很稀疏,当一个用户只有一个非零特征时,这个特征会得到很高的分值;而当一个用户有多个非零特征时,重点特征的权重值反而难以取得较高的得分.本文方法将得到的搜索矩阵Q做矩阵变换,首先将权重系数矩阵由[b,1,r]转为[b×r,1],再利用矩阵乘法将结果与[1,m]相乘得到[b×r,m],再将权重系数矩阵转为[b,m,r].其中,m为新增加的Attention 的维度.对于每个特征,有m个等长于r的Attention 值,变换后矩阵的大小由[b,1,r]变为[b,m,r],从而增加Attention 的维度m,促使不同的Attention 关注不同的部分,减少了因召回商品数量不同造成的影响.通过求均值,将[b,m,r]变为[b,1,r],得到Attention 值ai,再根据权重系数对Vi进行加权求和,得到搜索矩阵Q的Attention 值.具体如下:

虽然特征Attention 编码能够丰富编码信息,提升模型精度,但由于增加了特征维度,可能会降低模型的训练速度.最后,本文提出一种分段自适应学习率训练策略,通过切换不同的优化器来加快模型收敛速度.
2.5 分段自适应学习率策略
目前,已有文献实证发现:在联邦学习及分布式训练中,Adam 等基于动量的优化方法会直接影响到联邦学习的效果.尤其在非独立同分布(non-IID)数据下,本地设备模型的更新方向可能与全局模型差别较大,从而造成全局模型效果下降[33,34].同时,推荐系统是一个复杂的非线性结构,属于非凸问题,存在很多局部最优点[35].
Bottou等人指出:SGD虽然可以加快训练速度,但因为SGD更新比较频繁,会造成严重的震荡陷入局部最优解[36,37].联邦学习需要在典型的异构数据的情况下,通过全局数据优化每台设备上的模型,因此需要一种快速、能适应稀疏和异构分布数据的优化策略.Gao 等人提出了多种自适应方法来缩放梯度,解决了在数据稀疏的情况下存在性能差的问题,但仅仅通过平均梯度平方值的方法无法提升收敛速度[38,39].Shazeer 等人提出了一种分段调整学习率方法,采用分段训练的方式,在不损失精度的情况下提升了训练速度,但需要根据经验来选择切换的时机和切换后的学习率[40,41].
针对以上问题,本文基于Wang 等人的工作[38],提出了一种分段自适应学习率优化方法,该方法的主要创新点为:1) 优化梯度下降过程,改进动量的计算方法,解决正相关性带来的收敛困难问题;2) 让算法在训练过程中自动由Adam 无缝转换到SGD 的混合优化策略,从而保留两种优化算法的各自优势,大幅缩短联合损失函数的收敛时间,并且保证了模型的准确性.
本地设备学生模型的目标函数为最小化联合损失(见公式(3)),即minGL,ω为学生模型参数(如神经网络模型中的Weights,Bias 等),则在时刻z目标函数关于模型参数的梯度Rz为

在基于动量的优化算法中,动量表示参数在参数空间移动的方向和速率.目标函数关于参数的梯度二阶动 量等价于当前所有梯度值的平方和.目标函数关于模型参数的一阶动量mz和二阶动量Vz分别为Rz和的指数移动平均.二阶动量Vz通过除以实现对Rz尺度的缩放控制,反映了梯度下降的速率.但在Adam 算法中,动量的计算本质上为动量Vz与梯度Rz的正相关性计算,会导致大梯度的影响减弱,小梯度的影响增强,最终会让收敛变得困难.本文假设过去时刻的参数梯度相互独立,因此可以利用过去q时刻的参数梯度Rz-q计算Vz,而无需引入相关性计算.具体地,该策略从最近的q时刻的参数梯度中选择一个最优值,即:

为解决上面讨论的正相关性计算带来的收敛困难问题,本文提出了优化后的二阶动量计算方法:

其中,μ1为权重参数.公式(12)使用最近q时刻的最优梯度代替当前梯度,避免了计算二阶动量所需的相关性计算.同样地,一阶动量的计算也可去相关性,即:在计算一阶动量时,也利用最近q时刻的参数梯度来更新mz.具体如下:

其中,μ2为权重系数.由公式(12)和公式(13)可得到时刻z的下降梯度:

其中,μ3为梯度下降的权重系数.最后,根据下降梯度更新z+1 时刻的学生模型参数ωz+1:

由于基于动量的Adam 算法会直接影响联邦学习的收敛效果,本文在学生模型训练过程前半段采用Adam优化,后半段采用SGD 优化,同时解决训练过程中相关性导致的模型收敛困难和收敛速度慢的问题.其中,优化算法的切换条件及切换后SGD 的学习率为该分段策略的两个关键点.
(1) 算法切换条件.
联邦学习中,利用自适应学习率的方法(如Adam)存在切换时间选择困难的问题:如切换过快,则无法提升收敛速度;切换过慢,则可能陷入局部最优解,影响收敛效果.受Wang 等人提出的从Adam 切换到SGD 的条件[38]的启发,当满足迭代轮数大于1 且修正后的学习率与原始的学习率的绝对值小于指定阈值ξ时进行切换,即:

其中,ηz为每个迭代都计算的修正后的SGD 学习率,与原始的学习率之差的绝对值小于阈值,则认为已经 满足切换条件,则切换为SGD 并以调整后的学习率继续训练.接下来介绍如何确定SGD 切换后的学习率.
(2) 切换算法后,SGD 的学习率.
SGD 阶段需确定的学习率包括初始学习率及修正后的学习率.Wang 等人提出将SGD 下降的方向分解为Adam 下降的方向和其正交方向上的两个方向之和[38],本文方法与前者的区别在于对正交分解后的方向进行修正.由于Adam 计算学习率使用的是二阶动量的累积,要想计算出SGD 阶段学习率大小,需要对SGD 的下降方向进行分解.本文将SGD下降的方向分解为Adam下降的方向和其正交方向上的两个方向分别乘以0.5(cos60°)再求和,其余部分与Wang 等人的方法一致[38].假设模型优化已由Adam 切换为SGD 阶段,首先要沿着模型预测方向(pk)走一步,而后沿着其正交方向走完相应步数.在当前时刻z,正交分解后的SGD 在Adam 下降方向上的 正交投影为,等价于Adam 的下降方向,即:


为了减少扰动,使用移动平均值来修正对学习率的估计,修正后的学习率如下:

其中,σ为SGD 权重系数.
3 实验及分析
3.1 数据集及实验设置
我们在Movielens[42]数据集和同花顺Level2 数据集上验证AFD 及策略的有效性.Movielens 数据集包含 2 000 个用户及用户特征、3 300 部电影以及电影的标签属性信息.实验中,选取电影评价数大于15 的电影和评价电影数量大于等于10 的用户作为训练样本[43].本文还在同花顺真实场景金融数据集中进行验证,数据集主要包含用户对Level2 产品的购买情况统计,特征包括了用户ID、用户历史购买信息、设备信息、用户对该产品的评价、用户自身属性特征、产品特征等.其中,离散特征18 项,连续特征22 项.实验中对特征进行预处理,包括缺失特征补全、去掉用户编码和标签字段缺失的用户、去掉用户非空特征数量小于3 的数据等.预处理完成后,训练集共有32 万用户及40 项特征,共78 万条样本数据;测试集共有12 万用户,40 项特征共25 万条样本数据.实验过程中,对原始数据进行去噪和脱敏处理,采用交叉验证的方式,将训练集和测试集分成4 份,并分发到4 台模拟设备,模拟联邦实际应用场景,每台设备上的数据相互独立.
为了对比不同联邦推荐算法的推荐准确率,我们将本文提出的基于注意力联邦蒸馏的推荐算法AFD 结合卷积神经网络(CNN)与结合联邦学习的其他3 种推荐算法进行对比实验,这3 种推荐算法包括:
(1) FWD:联邦学习(FedAvg)结合Wide&Deep 算法[44];
(2) FDIN:联邦学习(FedAvg)结合深度兴趣网络(DIN)算法[45];
(3) FD+CNN:联邦蒸馏算法[10]结合卷积神经网络.AFD+CNN 方法在不使用本文提出的3 个策略的情况下等价于FD+CNN.
AFD 与以上3 个模型的对比见表4.
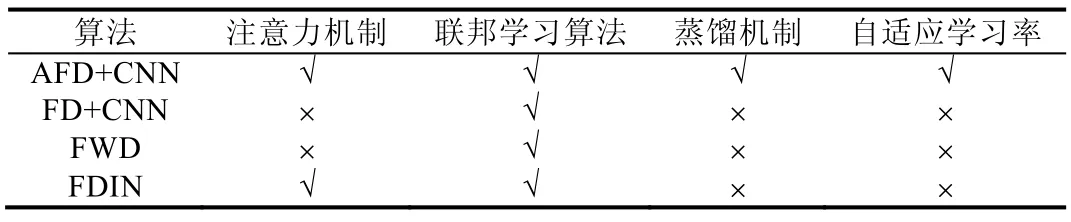
Table 4 Comparisons between AFD and baselines表4 AFD 算法和基准模型对比
本文模型及实验使用Tensorflow 实现,并且在Nvidia GeForce GTX 1080Ti GPU 上进行实验.AFD 及3 种方法的实验设置如下.
(1) AFD+CNN:attention 的维度m设为32.网络层参数设置,CNN 层数为5,隐藏层的大小hidden_units 设为128,两个卷积核为[64,64],最大池化层为[64,1],3 个全连接层为120,60 和2;
(2) FWD:Deep 部分全连接层为128,64 和2;
(3) FDIN:隐藏层单元数为32,全连接层为80,40 和2;
(4) FD+CNN:CNN 层数为5,2 个卷积层,1 个最大池化层,2 个全连接层.
3.2 评价指标
本文采用如下指标作为实验结果的评价指标.
• Time:模型迭代指定轮数运行的时间;
• Loss:模型损失函数(为与其他模型统一,AFD 评估学生模型原始损失,而非联合损失);
• AUC:ROC 曲线下面积,用来反映分类器的分类能力;
• ACC:准确率,表示分类正确的样本数占样本总数的比例;
• NDCG(normalized discounted cumulative gain):归一化折损累积增益;
• MAE(mean average error):评估算法推荐质量的指标,通过计算实际分值与预测分值的差异,来衡量推荐是否准确.
3.3 实验结果及分析
• 实验1:不同联邦推荐算法下的精度实验.
在两个数据集上的准备率对比结果如图2 所示,结果表明,本文提出的AFD 算法准确率高于其他3 种基准方法.在Movielens 数据集上,AFD 算法的平均准确率最高达到了0.84,FDIN 的准确率高于FD 和FWD 算法.在Level2 数据集上,AFD 算法的准确率达到0.92 左右,FD+CNN 的准确率为0.81 左右,FWD 准确率仅为0.67 左右,FDIN 约为0.83 左右,AFD 相比不使用本文提出的3 个策略的FD+CNN 算法在准确率上提升了13%.可以看出: FD+CNN在使用联邦蒸馏机制后,模型精度与FDIN相当.FDIN由于使用了Attention机制,总体精度优于除AFD外的其他方法.
表5 为4 台设备中的MAE 及全局模型的MAE.由表5 可以看出:由于数据分布情况不同,4 台设备中模型精度有较大差别.同一设备,FWD 误差值最大,FDIN 和FD 算法MAE 均小于FWD 算法.在Movielens 数据集上,FWD 算法的MAE 值最大,推荐效果最差,而AFD 算法MAE 值比FD 算法平均误差减少了约20%.在Level2数据集上,FD 和FDIN 算法MAE 结果近似,而AFD 算法比以上两种算法平均误差减少了约17%.同时,AFD 在4 台设备中均取得了最好的结果,表明AFD 相对于其他3 种基准算法推荐性能表现最佳.
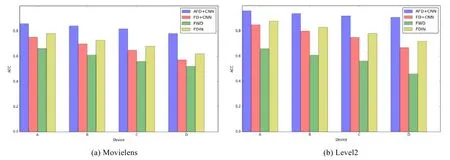
Fig.2 ACC on different datasets图2 不同数据集下的ACC
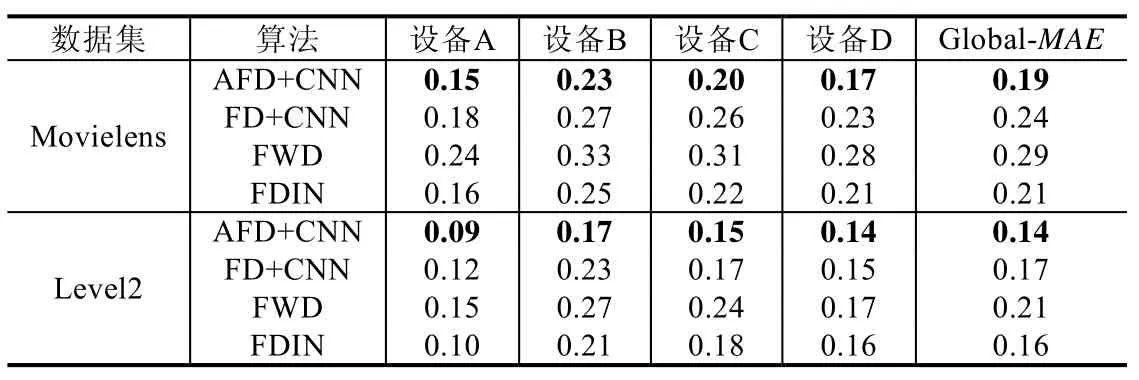
Table 5 MAE on Movielens and Level2 datasets表5 Movielens 和Level2 数据集下的MAE
由图3 可以看出:使用NDCG@5 作为评价指标,AFD 算法在4 台设备上的NDCG 值均高于其他3 种基准模型.其中,在Movielens 数据集上,AFD 的NDCG 平均值达到0.92,FWD 的NDCG 平均值为0.82,FD 和FDIN的NDCG 平均值接近(约为0.85).AFD 比以上两种算法NDCG 值提升了约8%;在Level2 数据集上,AFD 的NDCG 平均值在0.96,FWD 的NDCG 平均值在0.85,FD 和FDIN 的NDCG 平均值在0.87.AFD 比以上两种算法NDCG 值提升了10%.

Fig.3 NDCG on different datasets图3 不同数据集下的NDCG
由图4 可以看出,AFD 算法AUC 值均高于基准算法.其中,在Movielens 数据集上,AFD 算法的AUC 为0.78;在Level2 数据集上,AFD 算法的AUC 为0.86,FDIN 和FWD 算法的AUC 仅为0.66,FD+CNN 算法的AUC 为0.76.
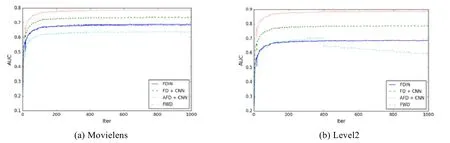
Fig.4 AUC on different datasets图4 不同数据集下的AUC
由图5 可以看出:随着迭代轮数的增加,AFD 可在迭代轮数小于200 轮时收敛,收敛速度略优于其他3 种算法.同时,AFD 在两个数据集上均取得了更低的损失:在Movielens 数据集上,AFD 的Loss 约为0.2;在Level2 数据集上,AFD 的Loss 可达到0.1 左右,均低于其他3 种基准算法.以上实验结果表明:本文提出的AFD 算法收敛速度更快,总体推荐性能更好.

Fig.5 Loss on different datasets图5 不同数据集下的Loss
• 实验2:自适应学习率在联邦蒸馏中的有效性验证.
为了验证改进后的自适应学习率方法的有效性,将算法的运行时间作为评价指标,对比AFD 与FWD,FDIN和FD 不同迭代轮数下的运行时间.实验结果如图6 所示.
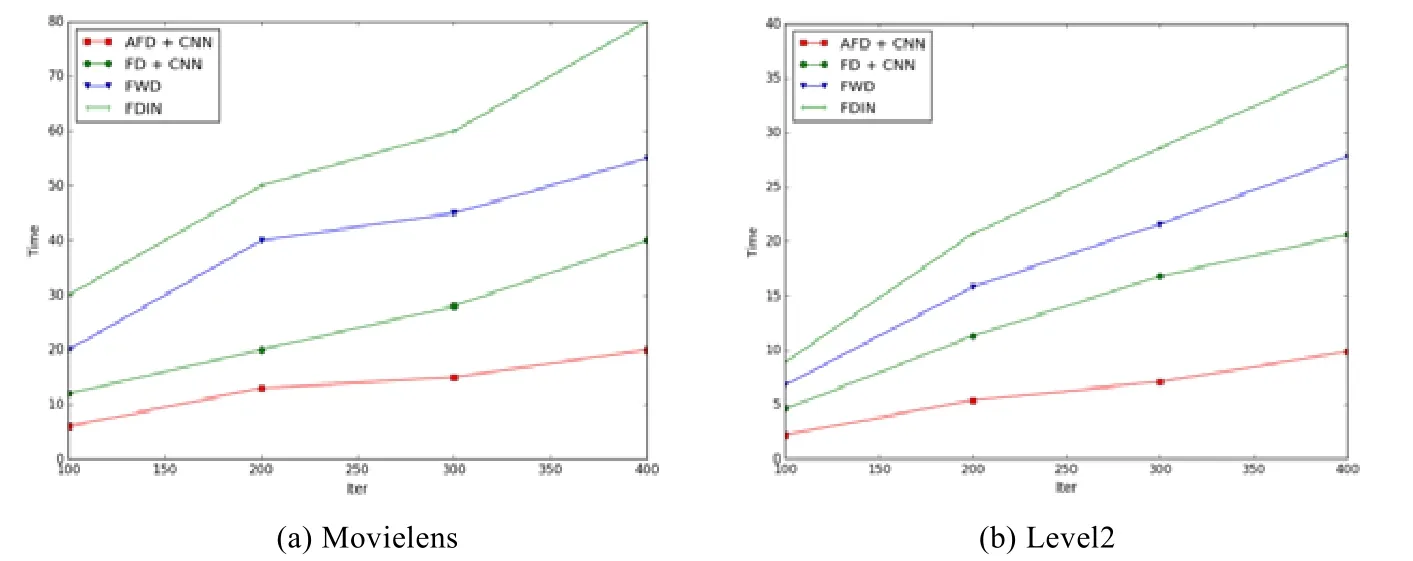
Fig.6 Running time of algorithmson different datasets图6 不同数据集上算法运行时间
从结果中可看出:在Movielens 数据集上,AFD 算法的耗时明显低于其他3 种基准算法,耗时曲线较平缓;在Level2 数据集上,FWD 和FDIN 算法的运行时间较长,随着迭代轮数的增加,运行时长呈线性增长,FD 算法运行时长小于以上两种算法.而采用自适应学习率策略的AFD 算法在相同轮数下耗时最短,同时,在200 轮以后,运行时长曲线增长更缓慢.在迭代400 轮左右,AFD 累计运行时长为9.8 分钟,FD+CNN 运行时长为20.6 分钟,AFD算法较FD+CNN 算法训练时间缩短52%左右,说明自适应学习率的方法能够有效的提升训练速度.
• 实验3:Attention 机制的有效性验证.
本实验将AFD 中的Attention 编码策略结合在其他3 个基准模型中,分别为联邦蒸馏算法结合CNN 及注意力机制(FD+CNN+ATN)、联邦学习结合Wide&Deep 算法和注意力机制(FWD+ATN)和联邦学习结合深度兴趣网络和注意力机制(FDIN+ATN).将NDCG、AUC、相同条件下训练时长(迭代次数400,minibatch 大小128,学习率0.001)和设备端MAE 作为对比指标,在Movielens 数据集和Level2 数据集上对比实验结果见表6.
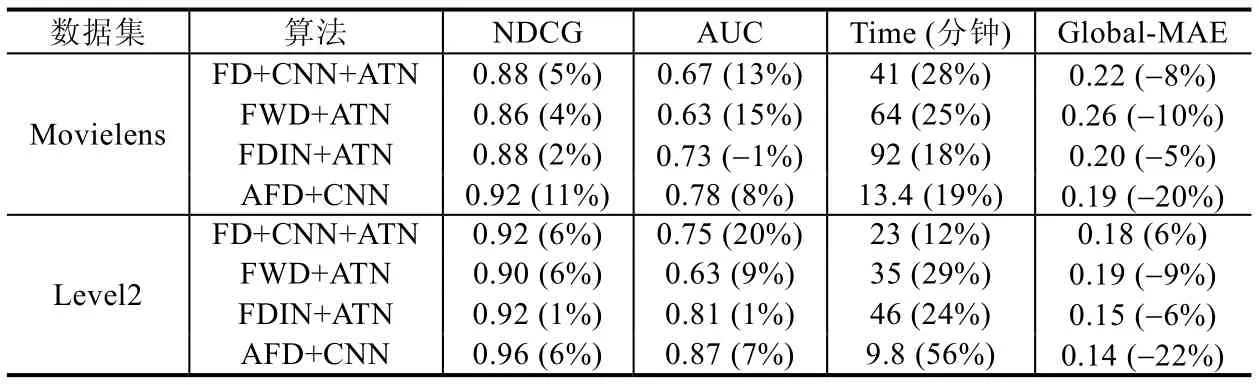
Table 6 Comparisons between baselines using attentional mechanism表6 各基准模型使用Attention 机制后的效果对比
表6 中,括号内的数字为加入Attention 机制后的方法相比未加入之前方法的提升/减少幅度.NDCG 和AUC该数字越大越好,运行时间和MAE 则越小越好.在Movielens 数据集中,FD+CNN 加入注意力机制后,NDCG@5值提升约5%,AUC 值提升约13%,Global-MAE 误差减少约8%,相同条件下训练时长却增加了约28%,说明加入注意力机制虽然对FD+CNN 算法精度有明显提升,但增加了计算量.FDIN 加入注意力机制后,Global-MAE 有明显降低,但NDCG 指标和AUC 几乎不变,训练时长增加了约18%,说明加入注意力机制对FDIN 算法精度提升有限.这是由于FDIN 已经在内部对集成了Attention 操作.对比实验中除FDIN 外,其他模型精度均有明显提升,但会增加算法的计算量,增加训练时间.从同花顺Level2 数据分析,可以进一步得出相同的结论.
• 实验4:Attention 编码后特征之间的关联性分析.
本实验对Attention 编码后特征之间的关联性进行分析,结果见图7.其中,图7 的横纵坐标均为Level2 用户和产品标签字段,颜色由浅到深表示两个特征的关联度逐级提高,关联度较高的特征能够获得较高的权重得分.

Fig.7 Visualization of feature interactions on Level2 dataset after attentional encoding图7 Level2 数据集下进行注意力编码后的特征交互可视化
可以看出,一些特征如level2_total_buy_time(Level2 产品历史购买次数),total_eventclicknum(Level2 产品历史点击次数),last7onlinetime(过去7 天的在线时长)等之间存在较强的特征交互,表明用户活跃度如点击次数和在线时长等特征对产品购买影响较大,符合现实业务中的观察结论.该结果表明:本文提出的Attention 策略可以提取出更丰富的特征表征信息(无需通过Attention 网络进行训练),增强设备数据,提升模型精度.
• 实验5:3 个改进策略对联邦蒸馏的有效性验证.
在最后一个实验中,验证本文3 个策略对联邦蒸馏方法框架的贡献程度,分别为联邦蒸馏加入KL 散度和正则项(FD+KLR)、联邦蒸馏加入改进后的注意力机制(FD+ATN)和联邦蒸馏中加入自适应学习率优化策略(FD+ ADA).为了验证3 个改进策略对联邦蒸馏的有效性,将NDCG、AUC、相同条件下训练时长(迭代次数400,minibatch 大小128,学习率0.001)和MAE 作为对比指标.对比实验结果见表7.
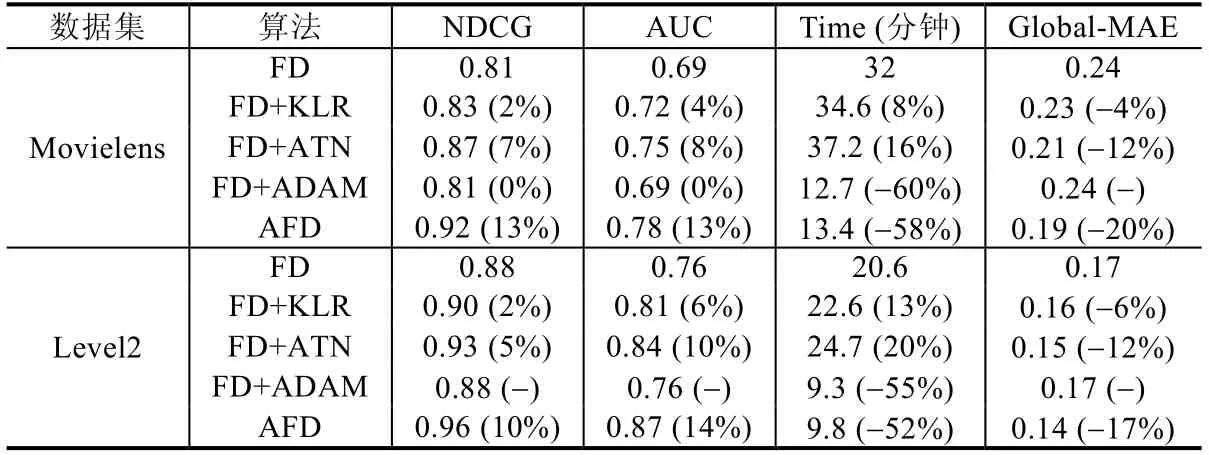
Table 7 Comparisons between three strategies表7 3 个策略的效果对比
从表7 结果可以看出:在Movielens 数据集中:比较加入改进算法前后的NDCG@5 指标,AFD 最高为0.92,FD+ATN 为0.87,分值最低的是FD+ADA 为0.81;加入注意力机制比原始联邦蒸馏算法有约7%的提升,其次是FD+ KLR,相比原始联邦蒸馏算法有约2%的提升;比较加入改进算法前后的AUC 值,加入FD+ATN 相比原始联邦学习算法有约8%的提升;对比加入改进算法前后的MAE,FD+KLR 和FD+ATN 相比FD+ADAM 误差减少了约4%和12%;从精度来看,提升最明显的是加入注意力机制(ATN),其次是引入KL 和正则项的联合损失优化策略(KLR),而自适应学习率策略(ADA)对精度的提升有限;但从训练收敛速度角度,ADA 策略取得了最大的收益,较只加入KLR 训练时间减少了约60%,说明该策略能大大提升学生模型的训练速度;FD+ATN 耗时最多,说明ATN 策略大幅提高了计算量;KLR 策略因只对目标函数做优化,对性能影响较少.从同花顺Level2 数据结果分析可以进一步得出相同的结论.
综上所述,在联邦蒸馏框架中加入注意力机制可以大幅提升模型的性能;加入KL 散度和正则项的联合优化策略可以减少特征之间的差异性带来的影响,从而提升模型的精度;最后,加入自适应学习率的训练策略在不损失或较小损失模型精度的情况下,可以大幅缩短模型的训练时间.加入3 个改进策略后,本文提出的AFD 在实验数据集上获得了最优的性能.
4 结 论
本文提出了一种改进的联邦蒸馏推荐方法,包括一个标准的模型优化联邦蒸馏算法.该算法引入了3 种策略:(1) 为增强设备中的数据特征,引入了一个改进的注意力编码机制;(2) 针对设备间数据差异可能带来的影响,引入了一个评估学生模型与教师模型差异指标及正则项的联合优化方法;(3) 为抵消注意力编码机制带来的计算量提升,提出一个改进的自适应学习率方法来切换不同优化方法,选择合适的学习率来加快模型收敛速度,使得训练时间缩短了52%左右.最后,通过实验在Movielens 数据集和同花顺Level2 线上数据集验证策略的有效性.实验结果表明:相比于3 种基准算法,本文提出的算法相比于原始联邦蒸馏算法训练时间缩短52%,模型的准确率提升了13%,平均绝对误差减少了约17%,NDCG 值提升了约10%,展示了良好的收敛效率和推荐精度.在未来的研究中可尝试的方向是:将联邦蒸馏与强化学习结合起来,为不同的设备制定不同的策略,无需回传或仅少量回传模型参数即可达到与回收模型相同的收敛效果,以大幅降低通信量.
猜你喜欢
中学生数理化·中考版(2022年9期)2022-10-25
房地产导刊(2022年5期)2022-06-01
建材发展导向(2021年12期)2021-07-22
建材发展导向(2021年7期)2021-07-16
中学生数理化(高中版.高二数学)(2021年12期)2021-04-26
家庭影院技术(2020年10期)2020-12-14
家庭影院技术(2019年7期)2019-08-27
当代陕西(2019年10期)2019-06-03
数学小灵通·3-4年级(2017年9期)2017-10-13
俄罗斯问题研究(2013年1期)2013-03-11
