
机器学习在工业网络入侵检测中的研究应用
2021-03-13 06:33宗学军郑洪宇纪胜龙
小型微型计算机系统 2021年2期
何 戡,曲 超,宗学军,郑洪宇,纪胜龙
1(沈阳化工大学 信息工程学院,沈阳 110142)
2(黄淮学院 智能制造学院,河南 驻马店 463000)
3(奇安信科技集团股份有限公司,北京 100000)
1 引 言
在工业信息技术的高速发展下,工业控制网络(Industrial Control Network,ICN)日趋成熟,但与此同时,威胁网络安全的木马、病毒等计算机恶意程序已不再局限于传统互联网之中,工业控制网络安全正经受着严峻考验.无论是2010年的“震网”病毒事件还是“WannaCry”永恒之蓝勒索蠕虫事件都表明,解决工业控制网络安全问题刻不容缓[1].
相较于传统IT网络,在工业控制网络中建立安全体系要保证生产的稳定性和实时性,进一步考虑工业网络环境的特殊性,如在工业设备之间专用的工业通信协议和工业控制网络独特的结构.威胁狩猎(Threat Hunting)作为近年来如claroty,dragos等国际新型公司的工业安全检测手段,在2020年的全球信息安全大会(RSAC-2020)的ICS village中被重点关注,Sherri Davidoff等人在会上的报告中发表了以威胁狩猎为核心的FireEye Managed Denfense安全产品.
入侵检测系统(Intrusion Detection System,IDS)与威胁狩猎在原理上有很高的相似性,是判断网络状态的一种常见网络安全技术,两者都能以机器学习算法作为核心,快速有效的辨识样本数据类型,检测入侵行为.在我国网络安全等级2.0保护标准中将入侵检测定为等级保护三级并作为强制选项[2].
在对入侵检测问题的研究中,Nasrin Sultana等人基于软件定义网络(SDN,Software Defined Network),利用机器学习方法实现基于网络的入侵检测技术(NIDS,Network-based Intrusion Detection System)[3].Moayad Aloqaily等人采用深度信念(deep belief)和决策树方法构建了针对智能汽车云服务的入侵检测系统[4].Majjed Al-Qatf等人提出STL(self-taught learning)学习方法进行特征学习和降维,有效提高了SVM算法的精度[5].
XGBoost以CART树为基础,检测效率高,关注于样本残差,不会高度依赖于数据集,可自定义损失函数且引入了对模型复杂度的惩罚项,能降低噪声干扰并限制模型复杂度,是一种高效的机器学习算法.
目前数据集的简化方法关注降低样本特征数量.其中一部分以主成分分析(Principal Component Analysis,PCA)为代表,对数据集进行降维来降低样本特征数量,同时能去除数据噪声.但这一类方法无法对处理后样本特征的意义进行解释,阻碍了对入侵行为本质特征的进一步研究.另一部分方法,如计算信息熵判定特征复杂程度或遍历特征组合来选定特征子集,都不能针对某一种选定算法选择重要特征.
综上所述,本文使用密西西比州立大学SCADA实验室的能源系统攻击数据集作为主要研究对象[6],采用交叉验证对比多种机器学习算法,重点使用XGBoost算法进行研究,并在此基础上提出一种针对选定算法的改进包裹式特征选择方法简化数据集,提高入侵检测效率并表现各特征在选定算法中的重要性.该方法在辽河油田油气集输公司的工业控制网络中进行了应用,有效阻止了外部网络的入侵行为.
2 工业控制网络安全分析
对工业控制系统的攻击主要针对上位机、工业控制器和工业控制网络,再间接对工业生产设备乃至生产整体造成影响.上位机是人机交互的接口,其中的工业组态软件承担着监控现场状态的任务,包含丰富的现场生产信息,成为了入侵的首选目标.在工业环境逐渐开放的当下,上位机失去了物理隔绝的天然屏障,面临着IT系统中窃听、拒绝服务攻击(DOS)等常见安全问题,同时也暴露出组态软件的安全漏洞和工业通信协议的脆弱性等工业控制系统中独有的安全问题[7].
工业控制器的种类繁多,承载的工业通信协议也不尽相同,多数工业通信协议在设计之初并未考虑到在开放环境下的安全性问题.例如,MODBUS作为早期工业通信协议,缺乏加密和授权,地址和命令等信息完全以明文传输,能轻易被解析.S7COMM作为西门子公司私有协议,虽然格式未公开,但出现过针对S7协议的CPU终止攻击、口令破解等情况[8].工业通信协议作为传递信息的工具,一旦被黑客利用,能达到恶意操纵现场设备,篡改关键数据等目的,对工业生产构成了严重威胁.
工业控制网络是工业控制系统的重要组成部分,以现场总线或工业以太网等作为通信介质,以具有通信能力的控制器、传感器、执行器、测控仪表作为网络节点,采取开放式、数字化、多节点通信的方式完成工业测量或控制的一种特殊网络[9].随着国家对工业互联网建设的大力推进,工业控制网络安全的重要性逐渐凸显.
数据作为工业生产中的核心生产要素,涉及企业和生产安全,是信息时代的重要资源.攻守双方都能从工业控制网络的通信数据中获取信息,优化行动策略.入侵检测对通信数据进行筛选判断,能有效检测入侵行为,但面对工业控制网络实时性和稳定性要求,以及安全漏洞和攻击手段的与日俱增,传统入侵检测方法逐渐不能满足实时更新和应对未知攻击的安全需求.因此,通过利用机器学习算法的自学习能力和泛化能力提高检测准确率,降低误报率十分必要.同时,当前工业控制网络的数据量逐渐增大,给入侵检测的数据分析带来了极大负担,通过特征选择方法选择数据重要特征,能进一步提高入侵检测效率[10-11].
3 算法原理和特征选择
利用机器学习来解决入侵检测问题,本质上要解决的是一个多分类问题.本文提出一种改进包裹式特征选择方法,需要在选定分类算法后,根据在不同特征子集条件下算法模型的结果,提取重要特征.
3.1 算法原理
3.1.1 支持向量机
支持向量机通过控制经验风险和置信范围值来控制泛化能力,以训练过程出现的误差调整模型,将置信范围最小化作为优化目标.
为了处理样本线性不可分问题,支持向量机算法引入了核函数技术,用样本在原始空间中的计算结果来替代样本映射到特征空间后的内积,解决了样本映射后内积计算困难的问题.研究过程中使用高斯核函数[12]:
(1)
其中xa,xb是需要计算内积的样本变量,δ为高斯核函数带宽,控制局部作用范围.
3.1.2 K近邻算法
K近邻算法对数据集的依赖程度高,算法原理是根据数据集内已有样本点,计算得出待分类样本x最近的K个样本,根据多数样本的类别确定样本x的类别[13].
3.1.3 AdaBoost算法(Adaptive Boosting,自适应增强算法)
AdaBoost算法在每轮训练时生成基分类器并调整样本权重,让后续基分类器将重点集中在错分样本上,最终将基分类器加权组合形成最终的强分类器[14].
3.1.4 随机森林
随机森林以决策树作为基分类器,在树节点分裂时随机选择样本特征子集,以最优特征划分,最终根据多个基分类器结果共同决定样本分类,相对于传统决策树,随机森林提高了泛化能力[15].
3.1.5 XGBoost(Extreme Gradient Boosting,极限梯度提升算法)
XGBoost算法是基于GBDT(Gradient Boost Decision Tree,梯度提升决策树)算法的一种串行集成算法[16],相对于AdaBoost算法,XGBoost算法关注于降低每一次迭代的残差,可表示为:
(2)

在算法实现过程中,以降低残差为目的训练树的结构和结点分裂规则,最终将样本分类至叶节点,再通过累加叶节点分数获得最终评分,确保算法不会因样本的某些极端特征数据导致学习误差.XGBoost算法允许自定义损失函数,增强了泛化能力.XGBoost算法的目标函数可整理为:
(3)

(4)
γ表示叶结点惩罚系数,λ表示L2正则化系数,增大两者会让算法在训练过程中倾向于更简单的模型.T表示叶结点总数,w表示树的叶结点得分向量.
3.2 包裹式特征选择
为了提高检测效率,提取重要特征,在得出最优算法的基础上,提出一种改进包裹式特征选择方法[17],执行过程与算法过程分离,在选择特征子集后,以在此特征子集下的模型运算结果评价特征子集优劣.对包裹式特征选择的改进体现在以下两点:
1)累计特征得分的后向(backward)子集搜索(subset search).
改进的包裹式特征选择方法基于后向子集搜索.假设样本特征总数为M,特征子集选用的特征数量为N(N≤M),先在N=M的情况下(使用样本所有特征)得到选定模型的准确率,以此作为基准值.然后,逐步降低N值,并设定N最小值限制(组成特征子集的特征数量最小值).此时,从所有特征中随机取N个特征组成特征子集,可能的组合数量为:
(5)
特征子集放入模型得出对应准确率,如果准确率大于或等于基准准确率,则将参与的特征得分加一;小于则不做任何处理,继续运行.设置N个特征下的最大循环次数和最大采样数,防止算法过度关注某些特定的特征组合.
2)根据特征得分和准确率增长值组合特征并验证.
以特征得分由高到低顺序取特征组成特征子集并放入模型中验证性能,特征数目从1开始,每经一次验证组成子集的特征数量加1,记录得出的对应准确率.
根据不同特征子集下的模型准确率计算按特征得分依次增加每个特征时的准确率增长值,再以增长值为依据重复特征子集验证过程,比较在不同特征子集下的选定算法模型性能,表现各特征重要性.
算法过程以伪代码形式描述为:
算法1.针对特定算法的改进包裹式特征选择方法:
输入:原始数据集,算法模型,特征子集最小特征数P1,最大循环次数P2,最大采样数P3.
输出:得分编号序列S1,增长值编号序列S2.
1.以原数据集为对象,得出模型准确率为ACC,设原数据集特征数为M,令N=M-1,i=0,j=0,n=1,所有特征初始得分为0.
2.WhileN≥P1:
3. While(i≤P2)and(j≤P3):
4. (N值较大时采用遍历)随机取其中N个特征,得出模型准确率ACC′
5. If(ACC′≥ACC):
6. 参与本次过程的特征得分加1,j=j+1
7. Else:
8. Continue
9.i=i+1,End While
10.End While
11.特征编号按得分从大到小排序,得分相同时,按在原数据集中顺序排序,得到得分编号序列S1
12.按序列S1中编号取对应的前n个特征组成特征子集,计算在此特征子集下的模型准确率并记录,n=n+1,循环该过程,直至n=M
13.根据上一步不同特征子集下的模型准确率计算增加每个特征时的准确率增长值,按增长值排序特征编号,得到增长值编号序列S2.
所得S1、S2序列,即为针对选定算法,分别根据得分和准确率增长值,按特征重要性排序的特征编号序列.
4 验证与分析
使用windows10,i7-8700,16GB内存系统下的Weka软件,python3.6编程语言,sklearn模块,XGBoost模块和相关常用模块进行研究,使用python下的matplotlib模块作图.
4.1 数据集及其预处理
以密西西比州立大学SCADA实验室的能源系统攻击数据集作为主要研究对象.通过采集实验室规模天然气管道控制系统的通信数据,由专家整理后形成此数据集.数据集样本共分为8类,包括标签为“0”的正常通信数据样本和另外7种攻击数据样本,每个样本除标签外共有26个特征,在整理过程中非数值特征在数值化和热编码处理后,特征全部以数值形式存在,样本基本信息如表1所示.

表1 能源系统攻击数据集样本情况Table 1 Samples of energy system attack data sets
原始数据集以arff文件格式存储,为方便处理需要用Weka软件转换为csv格式.对除标签外的特征进行归一化处理:
(6)
得到可直接用于算法模型的数据,其中x表示需处理的样本特征值,xmin、xmax表示该特征的最小值和最大值,x*为归一化后样本特征值.
该数据集囊括了工业控制领域中常见的攻击类型,样本特征也从控制系统的通信协议和硬件设备出发,包含指令的发出地址、响应地址、指令类型、设备的控制模式、设定值、测量值等工业控制系统中的常见信息,是在同类工业控制领域中具有普遍性的工业入侵检测数据集.
4.2 验证方法及评价标准
4.2.1 验证方法
采用10折交叉验证方法对各模型性能进行检验,该方法可以更客观的评价模型对数据集整体的性能.
4.2.2 评价标准
以准确率(Accuracy,ACC)、灵敏度(Sensitive)、F值(F-Measure)、漏警率(Missing Alarm,MA)和虚警率(False Alarm,FA)评价结果.模型的输出有四种分类:真正类(True Positive,TP)和真负类(True Negative,TN),分别表示被正确分类的正常样本和异常样本.假正类(False Positive,FP)和假负类(False Negative,FN),分别表示正常样本被错分为异常样本和异常样本被错分为正常样本.可将准确率(Accuracy,ACC)描述为:
(7)
在研究中,为评价模型整体性能,消除样本不平衡对模型造成的影响,引入F值(F-Measure)进行评价:
(8)
α是调整参数,实验中选取α=1,此时有F1评价标准:
(9)
F1评价标准可以对模型进行综合评价,值越高说明模型性能越好,其中R是召回率(Recall),P是精确率(Precision):
(10)
(11)
对应两者,有漏警率(Missing Alarm,MA)和虚警率(False Alarm,FA):
(12)
(13)
在实际工业生产中,对异常行为重点关注,即漏警率和虚警率越低越好.为检验对异常样本的识别能力,引入灵敏度(Sensitive)概念,计算公式形式与召回率公式相同,但将需检测的一类样本看作正常样本,其他类看作异常样本进行计算.
4.3 实验结果及分析
4.3.1 算法实验结果对比分析
将能源系统攻击数据集作为研究对象,采用10折交叉验证,以XGBoost算法为例,交代对样本数据的辨别过程.
首先,在对原始数据集进行预处理后,保证比例不变将数据集分为10份,完成10折交叉验证准备工作.
然后,按10折交叉验证规则,采用XGBoost算法进行训练和测试.在XGBoost算法的训练过程中,训练样本在每次进入模型后计算在预设数目CART树计算后的样本残差,循环这个过程,直至残差小于预设值或在规定预设轮数内残差不再下降,停止训练并用测试集对模型进行测试,输出评价结果,继续下一轮交叉验证.
最后,在得出10折交叉验证的10轮结果后,计算各评价标准的平均值,得出结果如表2、表3所示.

表2 各算法对不同类型样本的灵敏度和准确率Table 2 Sensitive and accuracy of each algorithm to differenttypes of samples
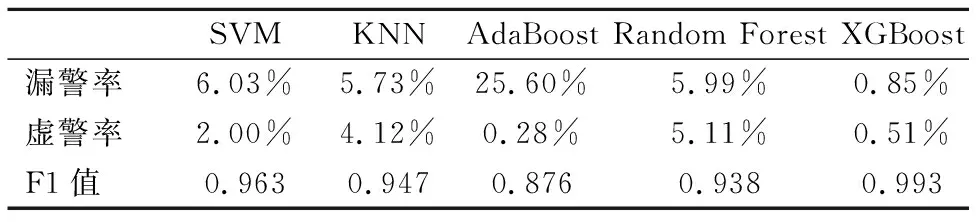
表3 各算法的漏警率、虚警率、F1值Table 3 Missing alarm,false alarm and F1 of each algorithm
从表2可以看出,XGBoost算法对各类的灵敏度最平稳,有相对最高的准确率,且在其他算法对NMRI(简单恶意响应注入)类型攻击灵敏度较低情况下,仍拥有对该类攻击较高的灵敏度.根据密西西比州立大学SCADA实验室对数据集的研究报告可知,NMRI类型的攻击对特征Measurement(测量值)的影响最为明显,有可能会使此特征数值远高于或远低于正常数值.XGBoost算法因其良好的泛化性,能有效学习到NMRI类型样本中的极端特征规律.SVM算法和KNN算法因其特点无法对这种情况实现有效分类.AdaBoost算法从对不同类型样本灵敏度表现上来看,很有可能陷入了过拟合.推断随机森林算法因为Measurement特征的上下极值差距大且划分多,导致在此特征上产生的权值不可信,让算法对NMRI类型攻击出现了判断失误.
从表3可以看出,AdaBoost算法的过拟合情况导致了极低漏警率和极高的虚警率,除此之外,XGBoost算法的漏警率和虚警率最低,F1值最高,综合表现最好.
从以上评价标准中可以得出结论,在以能源系统攻击数据集作为研究对象情况下,XGBoost算法在各评价标准下表现最优,在5种机器学习算法中性能最好.
此外,使用澳大利亚数据中心采集的UNSW-NB15入侵检数据集对以上的机器学习算法性能再次进行验证.UNSW-NB15入侵检数据集是由澳大利亚数据中心在2015年采集、整理而成,符合当前的网络环境,是近年来国内外针对入侵检测研究的首选数据集[18,19].在保证各类样本比例的条件下,取与能源系统攻击数据集样本总量相近的样本作为实验对象,同样采用10折交叉验证,算法模型中的参数几乎不变的情况下,测试结果如表4所示.

表4 各算法对UNSW NB15数据集的测试结果Table 4 Test results of each algorithm on UNSW NB15 dataset
UNSW NB15入侵检数据集除正常样本外还包含9类异常样本,且样本特征除“所属类别”外还有41种特征,复杂程度高于能源系统攻击数据集.因为样本的复杂程度增大,在采用相同数量的样本时,各算法模型对样本的学习未能达到最佳状态,但从结果可以看出,此时XGBoost算法的性能依旧优于另外4种算法.
综上所述,在以上的实验中XGBoost算法的表现优于另外几种算法,作为实验对象的数据集也在自身领域具有普遍性.因此,选择XGBoost算法作为后续研究对象.
4.3.2 特征选择结果
继续以能源系统攻击数据集作为实验对象,在XGBoost算法的基础上采用提出的包裹式特征选择方法得到对应的序列S1、S2.特征编号以原数据集特征顺序,从0开始至25共26个特征,按S1中特征编号顺序添加特征组成特征子集,S1序列为:[0,6,8,10,18,21,24,2,4,11,3,23,9,5,14,20,1,12,16,13,15,19,22,25,17,7],特征子集的特征数量及对应模型准确率如图1所示.

图1 根据特征得分添加特征的运算结果Fig.1 Result of adding features based on feature scores
对S2进行相同处理,S2序列为:[0,24,18,3,8,20,6,10,2,21,22,25,11,1,13,15,16,23,9,5,14,19,7,4,17,12],结果如图2所示.
图1、图2中实线为按S1、S2顺序增加至横坐标对应数量特征时的准确率曲线,虚线为使用全部特征时的准确率,两图中实线最终都收敛于稍高于虚线的值,但与虚线值相差不大(0.05%左右).

图2 根据增长值添加特征运算结果Fig.2 Result of adding features based on the growth value
由图1和图2对比可知,图2曲线收敛快于图1,在特征数量为8时与虚线值几乎相同.可以看出对于XGBoost算法模型,使用S2序列的前8个特征,即采用对应编号为0,24,18,3,8,20,6,10的特征组成特征子集就能达到接近全集的效果,准确率单调递增且增长值依次递减,可认为在此数据集使用XGBoost算法的情况下,这8个特征最为重要,可以替代样本中的其他特征信息完成入侵检测任务,减少了算法需要处理的数据总量,提高了入侵检测效率.
在数据集中,这8个特征按S2序列顺序依次代表:0—指令发出地址,24—测量值,18—设定值,3—响应寄存器地址,8—响应方读取指令函数编号,20—表示系统是由“泵”控制,还是由“螺丝管”控制的编号,6—请求方读取指令函数编号,10—通信协议指令函数编号.这8个特征都是工业控制系统中的常见数据信息,在整理后成为有价值的数据集,方便研究者总结入侵行为的规律,并在类似的工业系统中关注这些特征.
在密西西比州立大学SCADA实验室对数据集的分析报告中,总结了与特定异常类型有强关联性的10个特征,这10个特征就包括了提取的8个特征中除编号3外的7个特征,侧面证明了与XGBoost算法结合的包裹式特征选择方法在总结特征重要性的问题上是有效的,这种方法筛选了重要特征,提高了入侵检测算法效率,为研究入侵行为数据规律提供了参考.
4.4 算法应用及其结果
运用XGBoost算法并结合包裹式特征选择方法的入侵检测在辽河油田油气集输公司的工业控制网络中进行了应用.该公司的控制网络曾遭受外部网络的恶意渗透,对PLC进行了未授权的读写操作.
在对现场的网络机柜和外部网络间安装工业防火墙(见图3)并装载入侵检测算法后,截获了由外部网络发出的非法命令,有效避免了企业信息的泄露和对工业设备的非法操作.

图3 现场工业防火墙Fig.3 Industrial firewalls on site
5 结束语
针对工业控制网络的入侵检测问题,主要采用在同类工业控制领域中具有普遍性的能源系统攻击数据集作为研究对象,引入多种机器学习算法对比验证,得出综合性能最优的XGBoost算法解决入侵检测问题.在此基础上,通过包裹式特征选择方法提取对XGBoost算法重要的特征,提高入侵检测效率的同时,也为总结攻击行为的规律提供了研究方向,在同类数据集中具有推广和应用价值.今后工作中,将分析工业控制网络异常行为的规律、总结共性问题作为研究重点.
猜你喜欢
中学生数理化·高一版(2022年1期)2022-04-05
健康之家(2021年19期)2021-05-23
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
健康体检与管理(2021年10期)2021-01-03
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
数学教学通讯·初中版(2015年5期)2015-06-17
