
一种基于数字孪生云平台的炼铁过程智能优化服务
2021-03-17 02:54周恒杨春节孙优贤
工程 2021年9期
周恒, 杨春节*, 孙优贤
The S tate Key Laboratory of Industrial Control Technology&College of Control S cience and Engineering, Zhejiang University, Hangzhou 310027, China
1.引言
炼铁的制造工艺复杂,它能不断地为其他行业提供基础材料。炼铁行业在原材料市场和能源市场都占据重要地位,其能源消费量占全球能源消费总量的10%以上。中国现今成为世界上最重要的钢铁供应国,生产的钢铁占全球总产量的一半。因此通过技术创新实现该行业的节能减排至关重要[1]。
用于解决基于制铁机制的转换理论和反应规则复杂性的传统方法,在高炉的建模和优化方面存在不足[2-3]。因此,研究人员仔细调查了炼铁过程中的各种智能建模方法。为了突出黑箱建模的优点,Chen 和Gao[4]提出了一种新的算法来提升高炉软边缘支撑向量机的透明度。Zhou 等[5]提出了一种基于递归学习的双线性子空间识别算法,对具有非线性的随时间变化的高炉进行建模和控制。此外,Li 等[6]利用模糊分类器,通过预测金属硅含量的发展趋势,判断产品质量和热状态。为了获得气体的流量分布和优化充电操作,Huang等[7]设计了一种基于高温工业内窥镜的三维(3D)形貌测量方法来检测高炉的炉料面。Li 等[8]随后提出了一种智能的数据驱动优化方案来确定高炉炉料面合适的分布位置。虽然这些方法都在一定程度上改善了高炉的运行,但整个炼铁过程都需要一个结合了各种服务的云计算框架。
云计算为客户提供计算机系统的按需服务、计算能力和数据存储服务,而客户不需要实际拥有相关对象[9]。大容量存储设备、低成本计算机和高容量网络的有效性促进了云计算的发展,而硬件资源虚拟化、自主公用计算和服务导向式架构的广泛发展也为云服务的增长做出了贡献[10]。事实上,许多公司已经在云平台上部署业务,这让云服务渗透到我们工作和生活的方方面面。例如,Yelp广告团队依赖预测模型来分析客户与广告互动的可能性。他们利用亚马逊弹性MapReduce上的Apache Spack(一个统一的分布式内存计算引擎)处理大数据和训练机器学习模型,这使得Yelp 的收入和广告点击率有所增加[11]。过去,12306(中国铁路客户服务中心)网站预订系统总是在特定时间数据访问量激增时崩溃。在春节期间,阿里云通过云计算处理余票的查询访问,有效地解决了这一瓶颈问题[12]。
随着高集成和大规模制造工业的快速发展,传统的方法在炼铁过程中在建模和优化方面十分受限。由于在操作中很难将相互冲突的目标联合起来,所以一个好的指示器总是会削弱另一个指示器的效果。为了同时优化几个目标,我们使用遗传算法(GA)中的加权方法将多目标问题转化为单目标问题。此外,我们在GA中引入自适应算法,以提高其搜索性能。在将GA 应用于实际问题之前,我们有必要通过建模的方法来学习算法的物理特征。为了满足对高精度和其他实时性要求,我们简化了递归神经网络的结构,将更新和重置门压缩为单门来模拟炼铁过程。因此,我们设计了一个基于分布式计算的云炼铁厂的多目标优化框架,如图1 所示。有了云上工厂的这个服务例子,与炼铁工厂合作的学者和研究人员可以在世界任何地方为这个工厂工作。综上所述,本文的主要贡献可以简要总结如下:

图1.云上炼铁高炉结构示意图。
(1)结合改进的GA与递归神经网络,以优化炼铁过程中的多目标问题。
(2)基于Rancher和Harbor框架构建了数字孪生的云计算平台。
(3)将混合多目标模型作为一种优化服务部署到云计算平台上。
2.方法论
炼铁厂在制造过程中通过可编程逻辑控制器、工业传感器和局部指示器产生大量数据[13]。中国有数百家炼铁厂和数千座高炉,这些工厂的数据量和计算需求远远超出了工厂的负担能力。如果一个高炉每分钟有数千个测量点可以采样,它每天的总数据量可以高达1 TB。然而,这些工业大数据没有得到充分的利用,反而给炼铁厂造成负担。尽管云服务和炼铁工艺都各自取得了重大进展,但很少有学术研究或工业应用试图将这两者结合起来。因此,我们设计了一个基于分布式系统的云上工厂(图2),充分利用这些工业大数据挖掘隐藏的信息。首先,暂时将过程数据存储在炼铁厂数据中心的本地服务器中。经过一些必要的预处理和重新格式化后,干净的数据将直接传输到关系数据库中。由于工厂的工业数据都备份在云数据库中,所以不需要扩展其存储设备容纳不断增加的数据量。然后,如果我们想修改算法或从云存储中训练数据集,可以从本地服务器或云数据库中提取样本。
云炼铁高炉由存储层、框架层和服务层组成。存储层通过云关系数据库对来自制造系统的数据流进行备份。计算框架层位于存储层和服务层之间,包含一个基于深度学习和进化算法的混合模型。此外,该计算集群是Apache Spark 的一个实例,与本地云服务提供商的虚拟机相互关联。有了计算框架和存储容量的支持,云上工厂能够为高炉炼铁过程提供多目标优化服务。最后,我们使用Apache Spark在虚拟机上部署多目标优化框架,为云上工厂提供云计算服务。工厂和学术界都可以从云炼铁厂中获益:炼铁厂不需要存储所有的生产数据,而学术研究人员可以在其他地方研究实际数据。通过使用Apache Spark和云计算,我们成功地将聚类、建模和优化模型的多目标优化服务应用到高炉炼铁过程中。
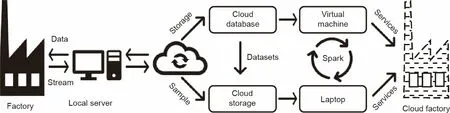
图2.云上工厂与实际工厂交互系统流程图。
混合模型的集成将聚类、建模和优化过程结合成一个不可分割的整体。在聚类分析预处理的基础上,我们采用建模方法获得了高炉炼铁过程的动态信息。然后,优化方法在临界约束条件下可以寻找生产指标的实时最优解。因此,该优化问题的目标函数如下:

式中,w为权重矩阵;ϕ和g为激活函数;dt为处置门;T为生成;F(x)是加权后的综合适应度函数;f(x)是单个优化目标的适应度函数;x是输入变量;h为神经元隐含状态。
聚类簇将对象的集合分为几个组,其中属于同一聚类簇的对象彼此之间比与其他聚类簇中的对象更相似[14-15]。它既是探索性数据挖掘的主要任务,也是用于机器学习统计分析的一般方法。一开始,我们利用高斯混合模型(GMM)将数据分到不同的聚类簇中,并选择理想的数据集实现知识发现。高斯混合模型是一个基于分布的模型,它适用于包含一定数量的高斯函数的数据集[16-17]。高斯混合模型的概率密度函数列于如下公式中。
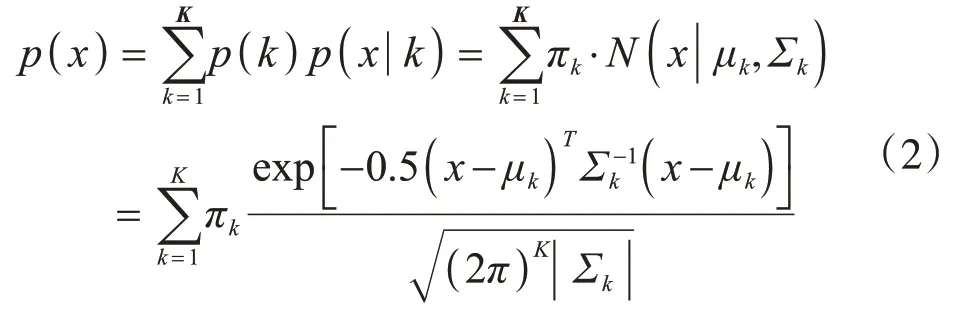
式中,k表示第k个聚类簇;μ为平均值;Σ为方差;p是概率密度函数;N是样本个数;π为混合权重,π的和为1。
当对炼铁过程的原始数据进行高斯混合模型聚类预处理时,有必要用智能方法重建炼铁过程。在各种深度学习方法中,递归神经网络(RNN)在学习时间序列数据的物理特征方面表现出色[18-19]。然而,传统的门控递归单元神经网络(GRU-RNN)的结构有些复杂,不能满足炼铁工艺行业的高实时性要求[20]。因此,为炼铁过程提出一个新的递归神经网络,它将GRU-RNN的更新和重置门简化为一个单一的处置门[21]。处置门控循环单元(dGRU)的数学定义如公式(3)所示,以及图3 为内部体系结构的可视化图。
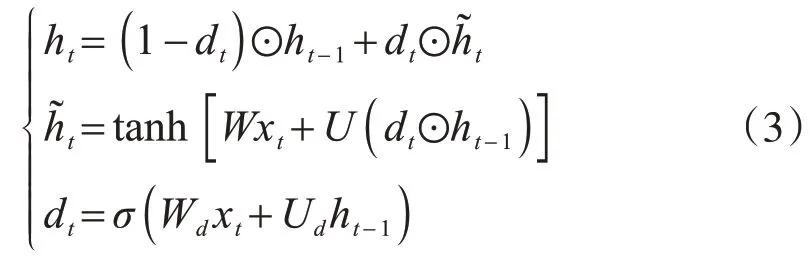
式中,激活状态ht是待激活状态和已激活状态ht−1之间的线性插值。U和W是输入变量和激活阈值的权重。Wd和Ud分别是重置门激活函数的权重和阈值。dt在历史记忆ht−1和候选信息xt之间做出了妥协。在dGRU 中进出单元的信息仅由一个门进行操作,从而提高了计算效率。dGRU 的反向传播将误差在时间和空间上进行反转,以更新其参数。因此,时间t−1时的反向传播误差如公式(4)所示:

图3.dGRU的内部结构。

式中,E为输出估计值;net 为dGRU 网络;δ为输出误差;l代表步长;d为重置门;代表候选状态。内部误差δd,t和δh,t可以转换为公式(5)中的表达式。

因此,用于更新dt和ht中的权值和阈值的梯度的原型如公式(6)所示。有了这种学习模式,dGRU 能够在迭代过程中优化其内部结构。

式中,ΔWd和ΔW是dt和候选激活状态中输入变量的权重;ΔUd和ΔU是dt和候选激活状态中激活阈值的权重。
在进化算法中,GA是解决组合优化问题的全局优化方法[22]。GA 的主要组成部分是编码/解码类型、适应性函数、遗传算子和控制参数。更具体地说,GA可以执行以下任务:
•编码优化问题的解决方案;
•创建在第t代中包含N(t)编码解决方案的总群;
•建立能评估解决方案最优解的适应性函数;
•利用遗产算子创建新的后代种群;
•设置控制参数。
近年来,对GA的研究大多集中在概率分布、遗传算子和染色体编码上[23-24]。尽管种群规模在很大程度上影响了计算效率,却很少受到关注。一般来说,种群规模与求解精度成正比,与计算效率成反比。为了解决这个问题,Koumousis 和Katsaras [25]提出了一种锯齿状的GA,它能周期性地增加和减少种群规模。为了同时保持准确性和效率,我们设计了一种自适应种群遗传算法(SAP‐GA),该算法的种群规模能随着适应性函数解的变化而变化[26]。每一代种群的理想适应性分布都应该是正态分布,但由于遗传算子的随机性,这往往难以实现。实际分布到正态分布的偏差程度被定义为偏度(Sk),如公式(7)所示。

式中,fe为中位数;fˉ为平均值;σ为标准差。偏态分布与种群规模之间的关系如图(4)所示,可用公式(8)解释。

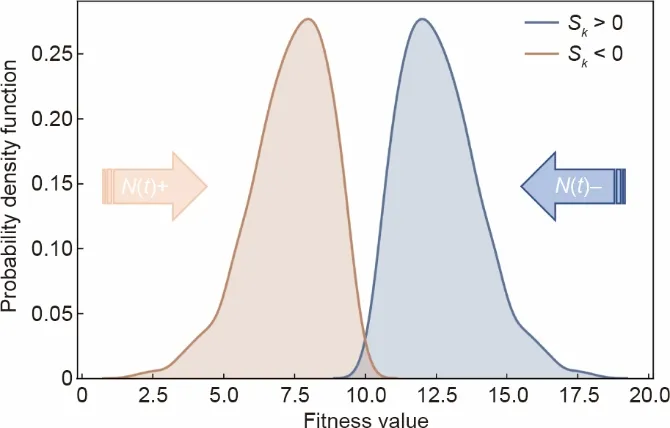
图4.适应性偏度与种群规模的对应关系。N(t)+和N(t)−代表在进化过程中种群的增减过程。
式中,Sk是适应性偏度;N是种群规模;k是种群规模转换区间的整数。至于SAPGA,Sk的上升趋势代表了较优解决方案的增加,导致需要增加新的候选方案以增加基因多样性。Sk的下降趋势表明存在大量较差的解决方案,为了保持SAPGA良好的搜索性能,需要将其排除。综上所述,当适应性分布的偏度从负转向正时,表明较优解决方案的比例在增加,或者较差个体在减少,候选方案的适应性需要调整回正态分布。
为了比较SAPGA 和标准遗传算法(SGA)的性能,我们根据模式理论对表1中符号的解的适应度进行了理论分析。

表1 文中的符号列表
在进化过程的后期,平均适应度的增加导致种群规模的减少。T是SAPGA的种群变得小于SGA的种群的世代。因此,我们做出如下定义的引理。
Lemma:N(t)SAPGA=N(t)SGA-k,其中t>T。
由于变异和交叉的影响,候选i在模式h下产生的后代的预期数量如公式(9)所示,符号的定义如表1所示。

在第t代,模式h下n时刻的适应度可以表示为公式(10)。

第t+1代模式h的预期平均适应度由两部分组成:一种是从种群继承的原始解,没有遭到破坏;另一种是重组操作产生的新解。
第t+ 1 代模式h下解的平均适应度由公式(11)表示。

式中,q为符合模式定理的候选染色体;α=作为比较,公式(12)中给出了SGA中模式h下解的平均适应度的相应原型[27]。

式中,β=(1-pc)(1-pm)n。
很明显,从公式(11)和(12)中可得,在模式h下,SAPGA比SGA具有更高的平均适应度。因此,自适应种群模式促使SAPGA具有更准确的解决方案和更快的收敛速度。
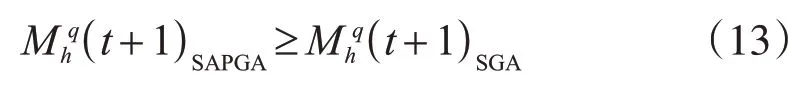
3.实验和结果
本节数据最初采集于一座工作空间为2650 m3的高炉。在上线前,需要验证算法,我们通过从Oracle数据库中采样,从本地服务器中获取数据集。由于数据质量是确定数据源的重要问题之一,因此使用高斯混合模型将数据集分成不同的类别,剔除不满足高数据质量要求的数据集。如公式(14)所示,Calinski-Harabasz 指数[28]作为一种聚类评估函数,通常被用来确定聚类中心的最佳数量。较高的Calinski-Harabasz 指数代表更好的聚类性能,原因在于聚类内部的协方差较小而聚类之间的协方差较大。因此,很容易确定图5 中的最佳簇数为4。此外,炼铁过程中存在三种工作模式:上升、下降和平稳运行趋势。
因此,实验剔除了性能最差的簇以调整铁的生产条件。
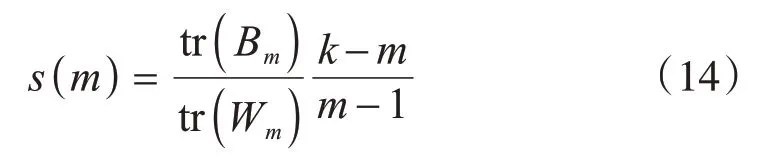
式中,k是样本数;m是簇数;Bm是不同簇间的协方差矩阵;Wm是簇内的协方差;tr是矩阵的轨迹。
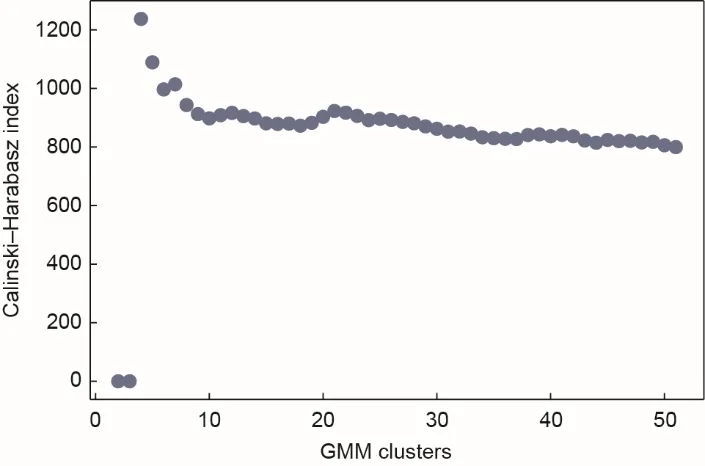
图5.高斯混合模型的簇个数与评价指标之间的关系。
将从云数据库中抽取的样本分为4组。将硅含量和顶压作为图6中簇的横纵坐标轴。黄色团簇在高顶压中分布较广,为高炉运行异常。为使炉顶气压力回收涡轮机高效工作,高炉炉顶压力必须保持稳定并在较小的范围内波动。因此,剔除数据集中在高顶压中分布广泛的集群,以提高数据质量。
剔除不满足条件的簇之后,dGRU由剩余的2000个样本进行验证,其中20%划分为测试数据集。深度神经网络的输入参数是渗透率指数、CO2、CO、烟气指数、理论燃烧温度、东北顶部温度、西南顶部温度、西北顶部温度和东南顶部温度。图7中的数据表明,dGRU-RNN在跟随输出参数(包括硅含量、焦炭比和铁产率)的变化趋势方面具有出色的性能。实际数据和预测数据的对比表明,dGRU单元具有较高的精度和较快的收敛性。如表2中所示,硅含量的均方根误差(RMSE)为0.025,意味着dGRU-RNN具有学习炼铁过程物理动力学的非凡能力。
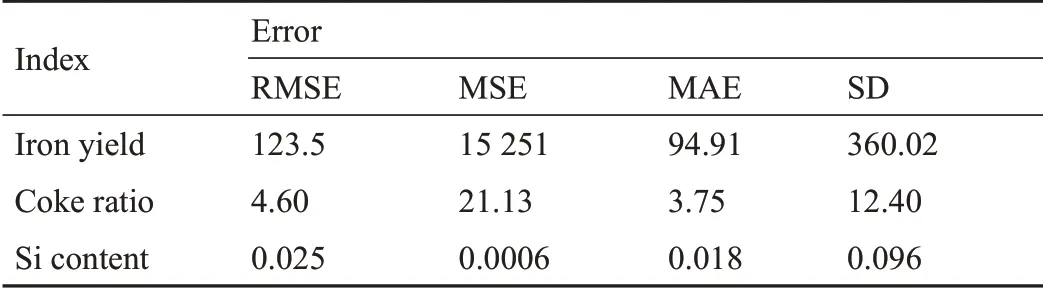
表2 预测数据与实际数据的比较

图6.存在簇时四分量高斯混合模型的表示。
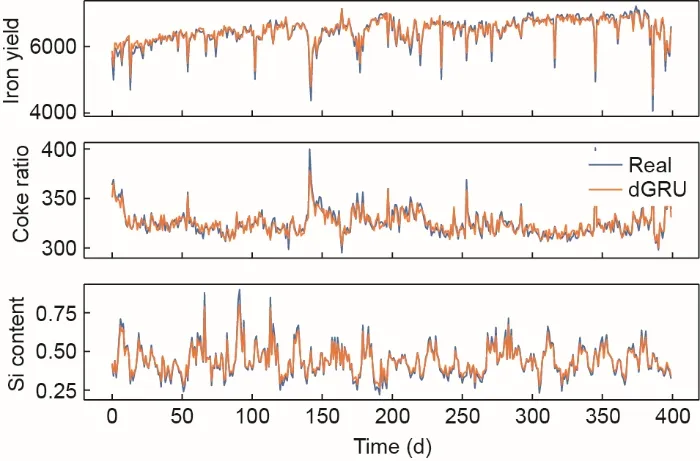
图7.dGRU-RNN对多个炼铁生产指标的预测结果。
焦炭比的波动比硅含量和铁产率似乎更平稳。为了更直观地理解模拟结果,预测的焦炭比及其相应的误差如图8所示。可以看出,dGRU-RNN大部分时间都可以跟踪焦炭比的变化趋势,误差很小。然而,在高焦炭比下的几个主要错误表明,深度神经网络模型在遇到突然变化时可能会出现低精度。因此,dGRU在处理稳定的工业过程(如高炉炼铁)方面具有巨大潜力。
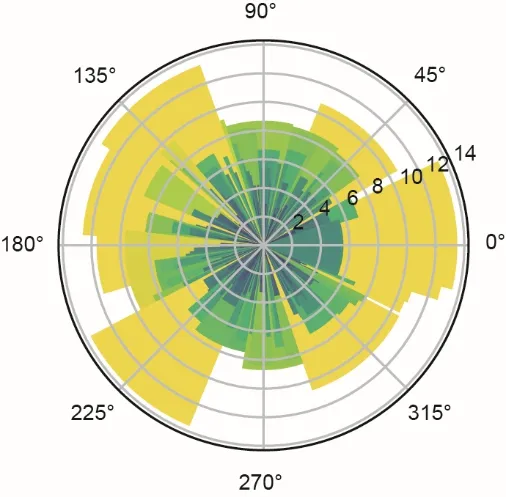
图8.极轴上的焦炭比误差条形图。宽度代表预测的焦炭比,半径是它们对应的误差。
SGA 存在许多变体,包括自适应遗传算法(AGA)和具有模拟退火突变概率的遗传算法(SAMGA)[29-30]。实验进行了以单对象优化为特征的4 个数值测试函数(图9),以比较SAPGA和SGA以及其他GA变体的性能。从图9 中可以发现测试函数(a)在(0,0)处具有最小值,测试函数(b)在(3, 0.5)处具有最小值,测试函数(c)在(π,π)处具有最小值,测试函数(d)分别在(3,2)、(−2.805,3.131)、(−3.779,−3.283)和(3.584,−1.848)处具有4个最小值。
4种GA变体对测试函数(d)的优化过程如图10所示,其中SAPGA 在搜索精度和收敛速度方面表现最为突出。SAPGA 可以在5 次迭代内收敛到最优,次数远少于其他GA。在某些情况下,SGA以及其他GA可能会陷入局部极限。然而,由于SAPGA自适应方案,其在测试过程中很少出现陷入局部最优的情况。适应度偏度和种群规模的组合导致了一个典型的现象,即在进化过程中解的数量会先增加然后减少,这有助于避免出现局部极值并提高计算效率。
为了获得更直观的优化效果可视化,图11 中通过将3D图形转换为2D平面,展示了测试函数(d)的优化解。结果表明,SGA 在最后阶段的最优点附近具有最广泛的种群分布。但是,SAPGA 具有高度集中的解,可以找到全部的4 个最佳点,表现出比其他GA 变体更好的性能。因此,在优化单目标优化问题方面,SAPGA 比其他3 个典型的GA变体更加强大。
经SAPGA 验证后,与dGRU 合并以优化实际炼铁过程。对于高炉而言,由于生产条件不同,出入料顺序可能会有很大差异。铁质硅含量和能耗焦炭比由现场工程师的操作水平决定,而铁产率可以根据当前和未来的市场情况动态变化。材料供应商、钢铁生产商和钢铁客户之间总是存在目标冲突。因此,炼铁厂依靠多目标优化算法来平衡这些相互矛盾的目标至关重要。在将模型上传到云上工厂系统之前,我们必须通过三个必要的步骤来验证多目标优化算法。首先,应用基于常规GRU-RNN 和SGA 的混合框架来优化高炉工艺指标。然后,改进算法取代传统算法,在时间和空间尺度上优化炼铁工艺。最后,将经过验证的dGRU-SAPGA 部署到独立模式下的分布式计算系统Spark中。

图9.GA变体的测试函数的3D图。f是GA在每次进化中的适应度。
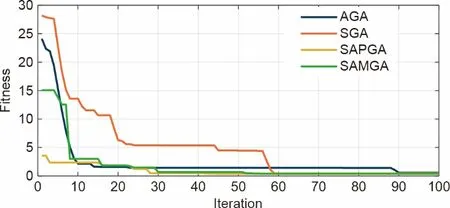
图10.GA在测试函数上的适应度迭代。

图11.测试函数(d)的GA解分布在第20代终止。
考虑到GA的随机性,每个测试重复100次。如图12所示,Spark 系统在计算效率方面有着巨大的优势。dGRU-SAPGA在分布式系统的平均运行时间为0.04 s,远小于本地服务器的0.10 s。在本地测试期间,修改后的混合框架dGRU-SAPGA 的运行速度略快于GRU-SGA。但是,dGRU-SAPGA的异常值多于GRU-SGA,这意味着后一种算法比前一种算法更稳定。

图12.不同方法的多目标优化计算效率。
我们已经将经过验证的混合框架dGRU-SAPGA 部署到云上工厂超过2 个月。如图13 所示,铁产率提高了1.29%,焦炭比降低了3.60%,硅含量平均降低了10.61%。
4.结论
一个高度集成的大型炼铁工艺制造工厂需要及时的响应和弹性的计算系统来应对各种工作状况。常规方法在炼铁过程中受到限制。因此,本文提出了一种基于混合模型的分布式计算方法来优化高炉炼铁过程中的冲突目标。在本地模式下,dGRU-SAPGA 在建模和优化炼铁过程方面表现出竞争优势。基于三步验证,我们将Spark分配系统中的混合优化框架应用于广西柳州钢铁集团有限公司2号高炉。框架应用两个月后,高炉多项生产指标明显提高。但是,需要注意的是,对于炼铁过程来说,仅靠多目标优化服务是不够的。基于分布式计算的云上工厂还需要许多其他服务,包括智能检测、数据融合、故障诊断和高级控制。
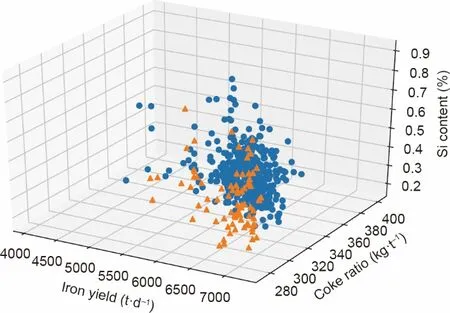
图13.多目标优化服务在高炉云上工厂中的效果。
致谢
感谢国家自然科学基金(61933015)的支持。感谢广西柳州钢铁集团有限公司。感谢实验室同事的辛苦付出。
Compliance with ethics guidelines
Heng Zhou, Chunjie Yang, and Youxian Sun declare that they have no conflict of interest or financial conflicts to disclose.
猜你喜欢
山东冶金(2022年2期)2022-08-08
太原科技大学学报(2022年1期)2022-02-24
计算机仿真(2021年1期)2021-11-18
昆钢科技(2021年3期)2021-08-23
昆钢科技(2021年3期)2021-08-23
昆钢科技(2020年5期)2021-01-04
计算机工程与设计(2020年4期)2020-04-23
四川冶金(2019年5期)2019-12-23
当代工人(2019年18期)2019-11-11
炎黄地理(2017年10期)2018-01-31
