
基于支持向量机的智能烟草市场监管模式探索摘要技术
2021-05-07 10:44吴英昊申长新
数字技术与应用 2021年3期
吴英昊 申长新
(山东聊城烟草有限公司临清营销部,山东聊城 252600)
0 引言
近几年,互联网经济发展迅速,人们的生产生活及工作方方面面都受到深刻影响。互联网具有信息传播渠道宽、反应快速、平民化、全民化、隐蔽性的特点,涉烟违法犯罪分子正是看到了这一点,通过互联网非法生产、销售、运输卷烟,甚至走私国外热销卷烟、雪茄烟,作案手段先进,违法行为隐蔽,犯罪分子难以抓获,这就要求我们烟草专卖执法人员更要深入学习互联网技术,运用互联网思维,创新烟草市场监管模式。
智能市场监管技术,主要使用营销数据中的多个维度数据,以时间为窗口,基于支持向量机构建一套异常数据智能监测方案。算法主要基于各个门店的总销量、品牌销量、单品销量、是否紧俏、扫码频度、扫码时间、库存量、存销比、地理位置权重等维度数据,通过既往门店运营情况,训练门店异常评估模型。为不将同量纲的维度数据统一到同一数量级下,对多维度数据采用归一化算法,让特征向量中不同特征的取值相差不大,加快模型收敛的速度,提高模型训练的精度。考虑到门店数据的智能适应性,增加了基于时间窗口的模型自动更新机制,从而增强模型的自学习能力。
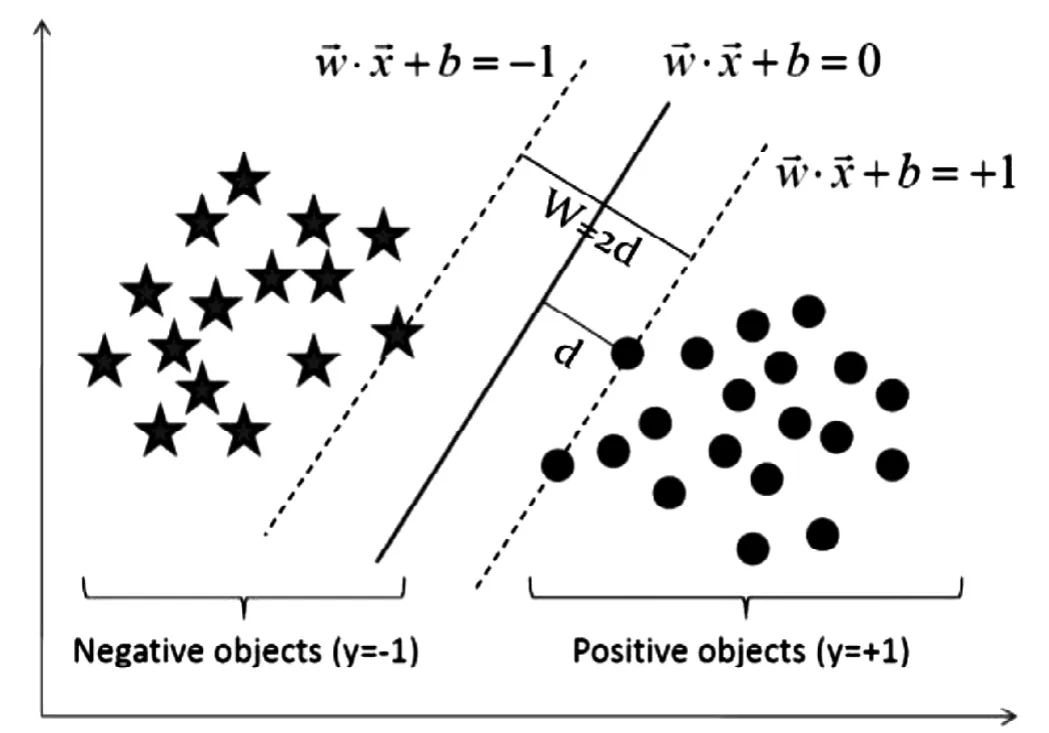
图1 支持向量机分类模型Fig.1 Support vector machine classification model
根据实际需求,本文从将异常销量预测分析角度出发,基于支持向量机(SVM)进行销量维度的预警分析与智能监测,进而从海量数据中深入挖掘风险数据。
1 异常销量预测模型
1.1 支持向量机
支持向量机[1]是一种经典的机器学习算法,在小样本数据集的情况下,可以实现较为准确快速的收敛预测。通过理解线性可分支持向量机的工作原理,进而引入解决复杂问题的核函数支持向量机,实现对门店数据的智能监测功能。
线性可分支持向量机对应着将两类数据正确划分并且间隔最大的一条直线。支持向量机分类模型如图1所示,其基本想法是求解能够正确划分训练数据集并且几何间隔最大的分离超平面。对与线性可分的训练数据集合而言,线性可分分离超平面可以有无穷多个,但是几何间隔最大的分离超平面确是唯一的。通过模型训练,不断收敛,调整参数,进而获得最终可接受误差范围内的分离超平面,实现对数据集的分类标识。
利用SVM分类理论,分别异常销量关系构建的用户网络的拓扑结构进行基本特征量的大数据分析,并在此基础上,利用多子网复合复杂网络模型,对营销用户多关系复合网络进行了实证研究。
未解决多维度数据线性不可分问题,在此次训练模型中,引入核函数方案实现对高维数据多标签分类效果。
1.2 数据集初步标注
基于支持向量机的机器学习算法与其他监督类学习算法相同,均需要提前对已知的数据分类进行标注。考虑到门店各类数据的复杂度,起初通过对既往门店做常规性统计分析,对各个门店数据进行分析统计,完成对门店类别的初次标注工作。
1.3 门店初步分类
使用初次标记数据,对既往3年内数据,以时间为窗口,对历史数据进行分组,整合,训练,收敛计算,完成对门店进行初次分类标记。初次标记过程中,尤其需要注意对历史数据训练收敛速度以及收敛效果,引入多维度参数,尽量消除局部最优解对整体最优解的干扰。
对门店分类结果进行统筹分析,确保数据收敛结果可信,并再次对门店分类进行修正,再次训练模型[2]数据,得到可上线初始基础数据模型。线上初始基础模型的构建,需要注意线上运算效率以及模型动态训练的性能。
本例中设计到用户数量多,数据维度多,不同数据维度对整体预测结果的影响不同,在模型训练过程中,需要注意数据归一化的处理对预测结果的影响,多次验证、多次模型训练,最终达到预测结果准确性目的。
1.4 滑动窗口模型重建
考虑到数据模型维度需要对生产环境进行动态修正,保持模型预测的准确性,本文采用基于时间窗口滑块方式实现对生产数据维度参数的动态分块、交叉分块,并结合用户随访门店结果,对模型进行自动化模型重建[3]。引入滑动窗口模型重建机制,主要增加了模型自助学习能力,实际上是将时间因素引入到模型预测环节,用于提高模型在对各类环境因素的预测鲁棒性。滑动窗口模型重建的流程为:
1.5 新旧模型交叉验证
考虑到新模型为系统自动训练,为避免数据维度明显失真导致近期模型训练失真问题,数据预测模型采用新旧模型单独预测,预测结果智能裁决机制,保证模型预测数据的合理性与真实性,从而得到门店的销量异常预警。
1.6 完整数据流-模型训练(图2)
1.7 完整数据流-模型预测(图3)
2 研究成果与分析
2.1 实现营销数据获取自动化
为实现烟草营销数据监测功能,首先需要解决云POS商户销量基础数据问题。日常分析过程中,我们为了能够分析经营数据,需要手动登陆到云POS系统中,手动筛选出需要的数据,并下载为Excel文档,然后再使用Excel分析需要的数据。为了解决此问题,我们整理了日常需要使用的数据字段、数据内容,使用自动化脚本实现了每日将Excel文档内容的自动化下载,并且将Excel导入到了数据库。

图2 模型训练流程图Fig.2 Model training flow chart

图3 模型预测流程图Fig.3 Flow chart of model prediction

图4 简易SQL脚本图Fig.4 Simple SQL script diagram
2.2 实现营销数据清洗自动化
我们在日常工作中,为了分析各个商户的异常数据,需要从成百上千的商户中分析他们的销量数据、规格数据、扫码数据等信息,有时还需要横向、纵向对比销量信息是否存在异常,工作量巨大,并且效果不是很理想。我们在充分调研需求、分析问题的情况下,对日常工作中的数据进行模型化分析,与协作单位研发人员共同制定了:节假日异常数据模型、经营异常商户模型、月销量异常模型、周销量模型、存销比异常数据模型等,并于每天早晨7:40前基于最新营销数据完成数据模型的计算、分析功能,从而实现了数据的清洗自动化功能。
2.3 实现营销数据异常自动推送功能
数据模型计算后,系统会自动在每天准时将昨日异常商户信息发送至工作群。站长、客户经理等根据当日推送数据指定当日重点关注商户,并及时回访、检查。
根据每项异常数据,均可查看到当日通过模型计算出来的异常商户信息。
2.4 积累研发性文档成果
改变以往分析数据只能依赖Excel的方式,我们在成果研究过程中,逐渐发现在Excel中好多功能实现起来比较麻烦,为此,我们与协作单位学习使用如何通过简易的SQL实现数据的分析功能,简易SQL脚本图如图4所示,可以通过脚本形式便捷操作数据,清洗数据,管理数据,训练数据模型。
3 结语
采用核函数支持向量机技术构建门店销量预测模型,增加了对未知门店异常数据的启发式发现,在实际应用效果中,相对于传统基于统计学规律结果更加精准,灵活。
采用基于时间窗口的数据模型重建技术,可对数据维度进行交叉分块、动态分块,提升了数据预测模型的鲁棒性。
采用新旧模独立预测,系统智能裁决技术,增加了线上预测结果的一致性,消除了数据尖峰带来的模型失真。
猜你喜欢
当代水产(2021年7期)2021-11-04
家庭影院技术(2021年6期)2021-07-28
汽车观察(2019年2期)2019-03-15
中央民族大学学报(自然科学版)(2018年3期)2018-11-09
电子测试(2017年12期)2017-12-18
汽车与驾驶维修(汽车版)(2017年2期)2017-03-18
上海商业(2016年20期)2016-06-01
测绘科学与工程(2013年1期)2013-03-11
中国土地科学(2011年11期)2011-03-20
