
新能车属性离散化的分辨矩阵和信息增益算法
2021-05-13 08:36周爱国于江洋施金磊王嘉立魏榕慧
测控技术 2021年4期
周爱国, 于江洋, 施金磊, 王嘉立, 魏榕慧
(同济大学 机械与能源工程学院,上海 201804)
新能源智能车监控数据中部分连续属性的取值精度过高,导致后续挖掘算法会占用过多的空间和时间,且训练出的模型容易出现过拟合的情况。数据离散化的目的是将连续的属性取值转换为离散的区间值[1],以降低属性的取值精度,断点集合则是算法划分离散区间的依据。对于新能源智能车来说,理想的离散化算法应在保证故障分类效果的前提下,获得尽可能小的断点集合。
离散化算法可分为无监督离散化和有监督离散化。其中,无监督离散化不考虑类信息,因此这类算法效率高,但是离散化后数据的分类精度较差;而有监督离散化则使用故障类别信息作为启发条件,例如信息熵、方差等,从而有偏向性地设置断点,可以获得较好的离散化效果[2]。目前,常用的有监督离散化算法可分为:基于统计的离散化算法、基于类和属性相关度的离散化算法以及基于信息熵的离散化算法等[3]。其中,基于统计的离散化算法[4-6]虽然具有较强的数据理论基础,但计算过于复杂,故不宜采用;基于类和属性相关性的离散化[7]则需要保证离散区间不小于类别数,且容易丢失信息;而谢宏等[8]提出的基于粗糙集和信息熵的离散化算法,将信息熵和粗糙集理论结合起来,使用决策表的信息熵来描述断点的重要性,算法在连续属性取值较多时也具有较高的计算效率,适用于数据量较大的场景,是一种经典的数据离散化算法。
但谢宏等提出的算法存在候选断点数量较多、结果集无用断点较多的问题。高原等[9]提出了改进的快速数据离散化算法,该算法根据决策属性D的等价类定义了连续属性a的等价类数值串,并根据等价类数值串对之间的关系来判断是否存在可能的候选断点,实验结果表明所选的候选断点数量大幅减少。然而,构建等价类数值串并进行判断的时间复杂度为O(UlogU/U+UD),对于数据量较大的新能源智能车来说,会花费太多的时间用于构建等价类数值串。杨海鹏[10]在粗糙集以及信息熵的基础上,集成了模糊聚类的方法,采用特征空间重组方法进行粗糙集连续属性离散数据的模糊特征重构,提取粗糙集连续属性离散数据的信息熵,并对所提取的信息熵进行聚类分析,实现离散检验优化。实验表明采用该方法进行粗糙集连续属性离散检验的数据聚类性较好,但随着迭代次数的增加,收敛程度出现了明显的下降。徐东等[11]提出一种基于森林优化的粗糙集离散化算法,该算法依据变精度粗糙集理论,对多维连续属性离散化,通过设计适宜的值函数,构建森林寻优网络,迭代搜索最优断点子集。实验表明,相比于传统算法,该算法能避免局部最优问题,具有一定的通用性,但是受参数预设值影响较大,需进行相关实验来选择参数预设值。
因此,如何在保证分类效果的前提下兼顾算法的计算效率,以尽可能少的断点完成新能源智能车故障类别的划分是数据离散化的关键。基于此,本文提出一种基于分辨矩阵和信息增益率的有监督离散化算法,通过决策表的条件属性与决策属性构建候选断点分辨矩阵,以此判断相邻属性取值之间是否有可能的断点,从而减少不必要的结果断点划分。在此基础上,利用信息增益率作为评价指标,优先选择划分效果较好的断点集合,并设置阈值改善原来较为严格的停止条件以进一步提高算法效率。不管是在实际数据测试中,还是在不同数据集上的实验中,改进后的算法在不影响分类效果的前提下,效率明显提升,为新能源智能车连续属性的离散化提供了技术支撑。
1 经典算法
笔者提出的算法是在谢宏等[8]提出的算法上改进而来的,这里首先对该算法进行详细介绍。
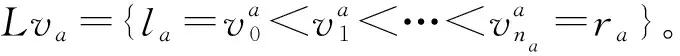

(1)
(2)

(3)
(4)

(5)
(6)
算法的具体步骤如下。
① 初始化P={U},Res=∅,Cand=∅,H=H(U)。
② 根据UACC算法计算Cand。

⑥ 若P中所有等价类中的决策值相等,则结束,否则转步骤③。
该算法的整体流程图如图1所示。

图1 基于粗糙集和信息熵的离散化算法流程图[8]
综上,基于粗糙集和信息熵的离散化算法可分为3个步骤:① 选取候选断点集合;② 从候选断点集合中筛选结果断点集合;③ 根据结果断点集合离散化连续属性。其中,步骤③只是按照固定的规则离散化连续属性,因此,算法效果的好坏主要取决于前两步。然而,该算法虽然计算效率高,但在候选断点和结果断点选取过程仍有以下不足之处:① UACC算法选区的候选断点数量较多,存在较多无用的断点;② 基于信息熵的结果断点选取不够合理,仅考虑了决策表的整体信息熵,而未考虑划分后子集的情况;③P中等价类的决策属性相等这个停止条件过于理想,算法不能及时停止。因此,本文针对这3点不足之处,提出对应的改进措施,并最终完成新能源智能车的监控数据离散化。
2 基于分辨矩阵和信息增益率的连续属性离散化算法
2.1 基于分辨矩阵的候选断点改进选取策略
理想的候选断点选取策略,应当在保证原有信息系统的分辨关系的前提下,选择最少的候选断点。ChiMerge系列算法[4-6]以及基于粗糙集[12-14]和信息熵的离散化算法都使用UACC算法选择候选断点,其流程如图2所示。
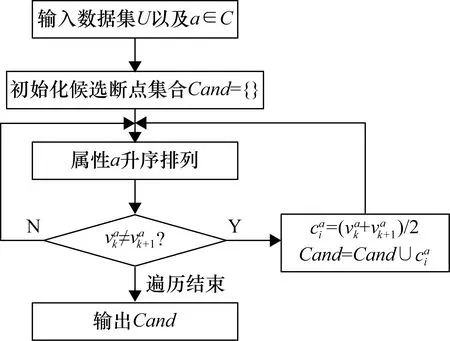
图2 UACC算法选取候选断点的流程图[8]
可见,该算法在选取候选断点时没有考虑类的信息,但由于将所有不同的取值都划分到了不同的区间,因此仍能保证原有信息系统的分辨关系。然而,该算法会选取过多无用的断点。以表1所示的新能源智能车监控数据为例,若采用UACC算法选取候选断点,则Cand={293.25,294.875,295.125,295.375,295.625,295.875}。然而,{293.25,295.375,295.875}的相邻记录均属于同一个故障类别,在这些记录之间加入候选断点,并不能帮助分辨故障的类别,反而会占用过多的内存,并且会增加后续结果断点选取花费的时间。

表1 新能源监控数据的连续属性取值
为了既保证实例的分辨关系又能获得较少的候选断点,可考虑在选取候选断点过程中引入样本的类别信息,从而减少候选断点集合规模。为此,提出一种基于分辨矩阵的候选断点选取策略。为了便于描述,定义映射函数fd(i,j)为
(7)
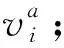
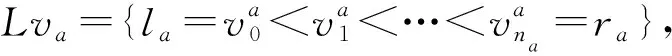

表2 根据属性a的等价类构建的候选断点分辨矩阵
文献[9]中定义的等价类数值串其实是通过该矩阵的列向量来构建的,列向量dj中所有取值为1所对应的属性取值就构成了dj的等价类数值串。本文则借助该矩阵中的相邻行来判断是否存在可能的候选断点,对于相邻行ri和ri+1来说,可能的取值情况分为以下3种。


结合上述分辨矩阵相邻行的取值分析可知,若属性a的相邻等价类均属于同一个决策等价类,则不存在可选的候选断点,否则,就应当添加候选断点。因此,基于分辨矩阵的候选断点选取策略的步骤如下。
① 对任意一个连续型条件属性a∈C,初始化候选断点集合Cand={}。
③ 由属性值序列Lva得到属性a的基本集U/IND(a)={A0,A1,…,Ana}。
④ 根据属性a的基本集以及决策属性建立CCM。
⑤ 遍历CCM的相邻行,若为情况①,则忽略该候选断点;否则,将相邻属性值的中值加入候选断点集合。
基于分辨矩阵的候选断点选取流程如图3所示。

图3 基于分辨矩阵的候选断点选择流程
该算法的时间复杂度取决于CCM的构建和相邻行的对比,设数据集的记录总数为n,属性a的取值个数为na,决策属性取值个数为nd。CCM构建过程主要记录属性a的等价类所包含的决策属性取值,时间复杂度为O(n),空间复杂度为O(na)×O(nd)。最终得到的CCM共有na行,相邻行则有na-1对,则对比相邻行的时间复杂度为O(na)。因此,基于CCM的候选断点选取算法的整体时间复杂度为O(n)×O(na),与O(n)同阶。另外,使用bitmap来存储CCM可大大减小存储空间,即用一个int型的变量来存储一个基本集所含有的类别情况,因此CCM整体占用空间大小为(na-1)×32-bit。
2.2 基于信息增益率的结果断点改进选取策略

(8)
(9)

综上,基于信息增益的选取策略仅考虑了断点给整体带来的不纯度下降,而没有考虑到断点对子集划分的影响。在C4.5决策树中,算法使用分裂信息熵来衡量测试属性取值数量的混乱度,从而改善了ID3算法对取值个数较多的测试属性的倾向性。而基于信息增益的选取策略本质上与ID3算法类似,只是每次新增断点后,划分的子集数量恒为两个。因此,本文提出基于信息增益率的结果断点选取策略。
(10)
(11)
此外,在C4.5决策树中,为了避免由于属性取值过少导致信息增益率过大,使得算法倾向于选取取值较少的属性,算法将首先选取信息增益大于平均增益的属性,然后再选取信息增益率最大的属性。类似地,本文首先将信息增益小于平均值的候选断点排除,而后再选取信息增益率最大的断点。
2.3 改进的停止条件
离散化算法的停止条件在很大程度上决定了最终的离散区间数量,停止条件过于严格,会导致算法选取过多的结果断点,离散化效果一般;反之,如停止条件过于宽松,选取的结果断点将过少,难以保证分类效果。因此,理想的停止条件应在保证分类效果的前提下,获得尽可能少的结果断点。
由图1可知,基于粗糙集和信息熵的离散化算法共有两个停止条件。
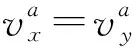

为了改善原算法中过于严格的停止条件,结合基于信息增益率的结果断点选取策略,设置如下停止条件。
① 当决策表的信息熵H(P)小于Hstop时,停止选取。原有的第一个停止条件是为了保证结果断点能够保留原有信息系统的分辨关系,然而,由于受不相容样本和不相关属性的影响,这种停止条件过于严格,有时难以触发。实际情况中,当决策表的信息熵下降到一定阈值时,说明此时依靠断点已经能将样本划分到纯度较高的子集中,故可以提前停止结果断点选取。
② 当最大信息增益率低于0时,停止选取。
综上,基于分辨矩阵和信息增益率的离散化算法步骤如下。
① 初始化P={U};Res=∅;Cand=∅;H=H(U)。
② 属性a升序排列求解基本集U/IND(a),并建立CCM。
③ 根据CCM选取候选断点集合Cand。


⑦ 若P中所有等价类中除了不相容样本外的决策值均相等,则结束算法,否则转至步骤④。
改进后的算法流程如图4所示。

图4 基于分辨矩阵和信息增益率的离散化算法流程图
3 算法性能测试
3.1 与经典算法对比实验
为了对比经典算法和改进算法的离散化效果,本文以新能源智能车的电池管理系统属性为例,分别采用谢宏等提出的传统离散化算法和改进后的离散化算法进行离散化。算法离散化过程中,二者选取的候选断点结果如图5所示。

图5 候选断点对比图
可见,传统算法共选取了1487个候选断点,改进算法选取了351个候选断点,减少了76.4%的无效断点。由于算法选取候选断点的过程很快,故改进算法在选取候选断点过程中节省的时间不明显。然而,后续的结果断点选取需要不断遍历每个断点计算信息熵,因此改进算法在结果断点选取上花费的时间相应地减少了76.4%,随着数据集的不断增长,改进算法的效率将明显优于传统算法。
二者选取的结果断点数量如图6所示,传统算法选取了349个结果断点,改进算法选取了138个结果断点,改进算法减少了60.5%的结果断点。原始数据中所有属性的取值个数为1505,改进算法将电池属性的取值减少为原来的9.17%,从而极大地减少了后续分类算法的计算时间和内存占用。

图6 结果断点对比图

图7 结果断点选取中的信息熵变化图
3.2 与近年提出的算法对比实验
为了进一步验证本文提出的基于分辨矩阵和信息增益率的离散化算法的有效性,从UCI数据库中选取含有连续型属性的数据集Iris、Wine、Shuttle、Ecoli,分别采用3种离散化算法进行离散化:算法A,谢宏等[8]提出的经典算法,即基于信息熵的粗糙集离散化算法;算法B,于宏涛等[15]提出的基于粗糙集理论与CAIM准则的C4.5改进算法;算法C,笔者提出的改进算法,即基于分辨矩阵和信息增益率的离散化算法。其中,算法B是近年提出的数据离散化算法,在不同数据集上均取得了不错的效果。实验结果如表3所示。

表3 UCI数据库离散化结果
由公共数据集的离散化结果可知,改进算法对多个数据库的离散化结果均具有最少的候选断点数量和最少的结果断点数量,且从测试集的预测精度来看,改进算法离散化后模型的预测精度有所提升。与经典算法以及近年提出的算法相比,笔者提出的改进措施在保证了离散化后数据的预测精度前提下,降低了候选断点数量和结果断点数量,其有效性得到了验证。
4 结束语
本文主要针对新能源智能车连续属性过多导致后续挖掘算法会占用过多的空间和时间,且训练出的模型容易出现过拟合的情况,在粗糙集理论和信息熵的基础上提出了基于分辨矩阵和信息增益率的离散化算法,主要内容如下。
① 针对传统离散化算法选取候选断点过多的问题,提出了基于分辨矩阵的候选断点选取策略,使用条件属性的等价类构建候选断点分辨矩阵,以此来判断相邻属性取值之间是否存在可能的候选断点,公共数据集的实验结果表明,该策略能够有效地减少候选断点数量,相比传统的UACC算法,将候选断点由1487个减少至了351个,减少了76.4%的无用断点,后续的结果断点选取也相应地节省了76.4%的时间。
② 为了使离散化算法选取更为合理的结果断点,借鉴C4.5算法对取值数量较多属性的平衡措施,提出了基于信息增益率的结果断点选取策略,并对传统算法中较为严格的停止条件进行了改进,新能源智能车的离散化结果表明,改进后的结果断点选取策略将结果断点数量由349个降低至了138个,减少了60.5%的结果断点,且断点划分后的子集信息熵和传统的结果断点选取策略相差不大。
改进后的算法在保持原来的分类效果的基础上,大幅减少了结果断点集的数量,提高了计算效率,对新能源智能车连续属性的离散化具有借鉴和参考价值。
猜你喜欢
军民两用技术与产品(2022年1期)2022-06-01
科教导刊·电子版(2021年6期)2021-05-06
——以大庆长垣萨尔图油田为例
石油地球物理勘探(2019年6期)2019-12-06
电脑报(2019年20期)2019-09-10
成都信息工程大学学报(2019年2期)2019-08-28
初中生世界·九年级(2019年6期)2019-08-15
雷达学报(2017年6期)2017-03-26
厦门理工学院学报(2016年3期)2016-11-10
广东石油化工学院学报(2016年3期)2016-05-17
池州学院学报(2015年3期)2016-01-05
