
深度神经网络图像描述综述
2021-05-14 06:27田英杰种法广王子超
计算机工程与应用 2021年9期
许 昊,张 凯,田英杰,种法广,王子超
1.上海电力大学 计算机科学与技术学院,上海201300
2.国家电网公司 上海电器科学研究院,上海200437
近十年是深度学习进入高速发展的黄金时期,各领域基于深度学习算法的研究取得了丰富的成果,其工业化的应用也惠及到人们生活中的方方面面。例如,可以使用指纹、人脸或者虹膜进行手机解锁,在YouTube 观看外语视频时可以实现实时翻译字幕的显示。在年初爆发新型冠状病毒的关键时期,大部分车站、高速收费站等都可以使用红外线检测仪来安全快捷地检测人体的体温,年初时由于疫情大家都戴起了口罩,这也带来了一些小的生活烦恼:很多通过人脸识别解锁的手机“认不得”自己了,但是随着深度学习在大数据中的学习,这一问题很快得到了解决。深度学习在图像领域:图像分类[1-3]、目标检测[4-6]、场景识别[7-9]等得到了广泛应用,随后出现了多模态的图像语义技术,也就是将图像和文本跨模态建立联系,进而使计算机能够从人类思维的角度出发去处理图像中的信息,并能够识别各目标之间的联系,最终以文字的形式表示出来。这项技术在人们的生活中也得到了有效的应用,例如能够对盲人进行导航。基于这样的需求,能够通过实时采取和分析视频图像,将采取的图像信息进行处理并输出成一段文本,最后通过文本转语音传入盲人的耳中,使得盲人能够实时地感知周围的环境。对于智能机器人的发展也同样重要,图像描述的技术能够准确识别出提取图像中的关键内容,并进一步理解图像中各物体间的关系,相当于让它有了一双能够感知世界的“眼睛”,这对于机器人技术的发展也具有巨大的推动作用。图像描述在图像检索系统也有着一定的应用价值,传统的图像检索技术主要是利用图像的标签进行对应索引的建立,但如果标签存在错误,图像就不能被正确检索,如果将图像描述技术应用其中,图像检索系统能正确地理解图像内在目标的语义,这样系统也就能对庞大的无标签图像进行正确有效地检索,这样图像检索的效率就能得到提高,检索的范围也得到拓展。除此之外,该技术在其他领域也有着应用前景,例如生成医学CT图像的报告,新闻标题的生成等。近年来,图像描述的技术也趋于成熟,图像描述的技术也发展到视频描述,例如根据短视频进行一篇新闻报告的生成等。可以看出,图像描述技术在现实中的有着巨大的实用价值。
图像描述作为把计算机视觉和自然语言处理相结合的跨模态跨领域的任务。一般地,它将输入的图片通过卷积神经网络提取图像特征并利用循环神经网络等方法生成一段文字的描述,这段描述要求和图片的内容高度相似。这对于人类来说是很简单的,通俗来说就是看图说话,几岁的儿童就能很详细地描述一张图片的内容。但对于计算机来说还是有很大的难度的,这要求计算机利用模型来提取图片内的特征以及一些高层语义信息,然后利用自然语言处理的方法表达图片中的内容。
最初,传统的图像描述算法是通过模板填充[10-11]的方法来生成图像描述,它主要是通过局部二值模式、尺度不变特征转换或者方向梯度直方图等算法提取图像的视觉特征,并根据这些特征检测对应目标、动作及属性对应的单词词汇,最后将这些单词填入到模板中。不难看出这样的方法虽然能够保证句型语法的正确性,也有着很大的局限性,由于使用的模板是固定的,它也依赖于硬解码的视觉概念影响,这样生成的语句格式相对固定且形式单一,应用的场景也很局限,正因为这样天然的缺陷,后续的改进也变得更加繁琐而无法应用到实际的场景之中。还有一种是基于检索[12-13]的方法,它主要是将大量的图片描述存于一个集合中,然后通过比较有标签图片和训练生成图片描述两者间相似度来生成一个候选描述的集合,再从中选择最符合该图片的描述。这样的方法能保证语句的正确性,但语义的正确性却难以保证,因而对图像描述的正确率较低。
得益于深度学习的发展,借助深度学习的方法推进跨模态学习成为当前的主流,这也是目前使用最多的基于生成的方法。这类方法的大致流程是先将图像信息编码后作为输入放进模型,随后利用此模型生成该图像对应的文本描述。如图1所示,这样的模型一般采用编码器-解码器架构,编码器使用卷积神经网络(CNN[1])提取图像特征,解码器采用循环神经网络(RNN[14])来生成文本描述。这是在图像描述中普遍应用且效果最好的模型,它在语句结构的完整性、语义的正确性,以及泛化能力得到了一致的认可。
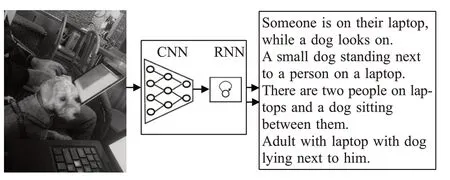
图1 基于CNN-RNN的图像描述
1 基本架构及改进
1.1 编码器-解码器架构
本章对基于深度神经网络[15]的图像描述[16-17]基本架构和改进进行介绍。首先,当前图像描述基本都是在编码器-解码器架构上进行改进,基于编码器、解码器上的改进主要如图2所示。
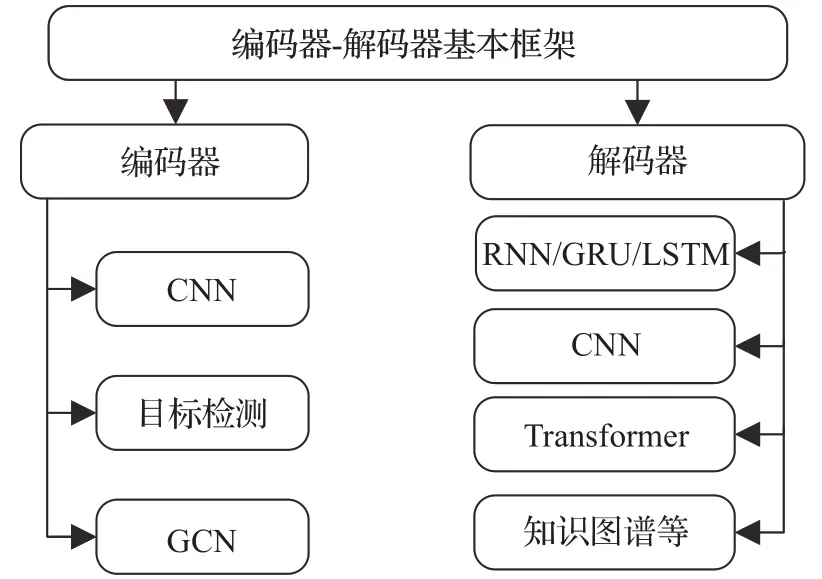
图2 基本架构概述
在2015 年,Vinyals等人[18]提出一个NIC 的模型,这个模型的灵感来自于谷歌2014 年有关机器翻译的工作,也就是著名的系列到序列(seq2seq)模型[19],它着重解决的是语言翻译的问题,最终也取得了很好的成绩,这也是编码器-解码器架构的最初提出。在机器翻译里,输入的是源语言,输出的是目标语言的翻译文字,由于两句话的长度可能不等,该模型采用RNN 网络对句子进行了编码,转化为一个固定长度的向量,然后再将这个向量输入到另一个RNN 网络来进行解码,进而输出翻译后的句子。这样的结构在机器翻译的模型中实现了变长序列到变长序列的一个映射。对应到NIC 模型中就是图片到文字的一个映射。如图3所示,这篇论文中的模型基于机器翻译模型上进行了改进,编码器使用基于CNN的InceptionNet提取图像特征信息,解码器依旧使用RNN处理输入的图像信息来生成描述。在同一时期,Karpathy 等人[20]提出的结构和NIC 模型几乎一致,区别在于它使用VGGNet[21]作为图像特征提取器。

图3 NIC模型
在NIC 模型的训练阶段使用的是COCO 数据集中训练集和数据集中的图片及其对应的文本描述。在编码阶段,模型用CNN 将图片编码为向量I,I是一个224×224×3 的向量,这里的CNN 使用的是Google Inception Net 后接一层全连接层。对于图片相应的文本描述,为每句描述添加一个start 和end 标记,也就是图3 中的<BOS>和<EOS>。假设提取的语料库有m个词,首先将句子中的每个单词编码成独热编码(one-hot)的形式,如图3中的每一个LSTM模块的输入都是一个m维的向量,然后通过一个矩阵变换将这个m维向量转换为一个512 维的向量,即和图像的编码维度相同。而在解码阶段,模型使用的是单层的LSTM 网络,可以用下列公式描述这个过程:

其中,N-1 表示句子的长度,不包括<BOS><EOS>标记,LSTM可以表述成ht+1=f(ht,xt),ht表示为t时刻LSTM的输出,这个公式可以理解为每一步的输出是上一步的输出和当前时刻的输入的函数。对应到公式(1)中,h-1=0,初始值为0,h0=f(h-1,x-1),x0=WeS0,如此循环。LSTM每一步的输出后会接一个softmax分类器,维度等于语料库中的词汇量,模型的损失是每一步正确预测单词的负对数似然之和,如公式(2)所示:

使用这个损失函数来最大化每一步输出单词的概率。在接下来的训练阶段,NIC 模型选择已经在Imagenet上训练好的CNN模型,训练的第一阶段固定CNN的参数不变,参与训练的有LSTM 和wordembedding 的参数。在第二阶段再把CNN、LSTM 和wordembedding这三部分的参数一同进行训练。在预测阶段,有两种生成描述的方式:第一种是在LSTM 生成单词的每一步选择模型输出概率最大的一个单词,直到预测输出到<EOS>标记停止。第二种是使用beamsearch,需预先设定一个值N,论文中选用的值是3,那么在第一步选择输出概率最大的三个单词,第二步依旧选择概率最大的三个单词并与上一步生成三个单词的组合,即九个短语的组合,然后再选取其中概率最大的三个短语,以此类推。最终模型训练出来的模型具有很好的泛化能力。
Showandtell[18]和Neural Talk[20]介绍了图像描述的编码器-解码器架构,可以说是图像描述在深度神经网络的启蒙之作,对后续图像描述的发展有着深远的影响,使编码器-解码器架构成为图像描述的主流,对其他相关预测模型也有着一定的借鉴意义。
1.2 基于编码器改进
Fang等人[22]对编码器进行了改进,该方法可以分为三步:第一步检测单词,采用使用多实例学习来训练视觉检测器来识别生成描述中常见的单词,包括名词、动词和形容词等不同部分。这样的方法可以避免有些描述性词汇如beautiful 不能在图片中被框出。第二步生成句子,采用统计模型MELM 来预测下一个单词的概率。第三步重新排序句子,选择最符合的语句。通过提取关键词作为输入来生成描述的方法为后续结合图像和语义的编码方法提供了借鉴。
Li 等人[23]在特征提取方法上使用目标检测算法Fast R-CNN 提取目标检测框作为图像特征,并使用该特征额外训练属性分类器来获取对象的属性,比如物体的颜色、材质等。随后将图像特征和属性特征输入到视觉语义LSTM 中进行解码。在编码阶段使用目标检测算法能够提取带有类似注意力效果的图像特征,为解码器生成高质量文本提供了可能。Anderson 等人[24]的工作使用类似的编码器并改进了解码器,得到了当时的最优结果。
1.3 基于解码器改进
编码阶段主要是基于图像领域知识的应用,解码阶段则是自然语言处理领域知识的创新改进和应用。
Wang等人[25]提出了一种新型的解码结构。人类在看图描述的过程中,一般是先定位图片的位置和他们之间的关系,然后再详细说明物体的属性。以此为基础,他们设计了一种coarse-to-fine 的方法。首先由Skel-LSTM使用CNN提取的图像特征来生成骨架语句,然后使用Attr-LSTM 为骨架语句中的词语生成对应的属性词,最后将这两部分结合生成完整的最终描述语句。
Mathews等人[26]为了生成高精度且具有语言风格的图像描述,提出了一个分离语义和风格的结构,通过两组GRU 单元来实现的。一组GRU 提取图像特征中的语义对(词语、属性),另一组GRU是基于一本小说训练得到。基于上述输入的语义对来生成最终富有语言风格的描述。
此外,Aneja 等人[27]提出了一种不同于用LSTM 或者RNN 进行解码的方法,该工作启发式地利用卷积来进行图像描述,达到不比传统LSTM差的效果。它的输入输出和RNN 一样,都进行了wordembedding,但将RNN 的部分换成了MaskedCNN,使用这样的方法能够避免RNN 的时序限制,如此可以在相同的参数量下有更快的训练速度。
受模板生成方法的启发,Lu 等人[28]提出了一种“插槽”的图像描述方法,其生成句子中的插槽与图像区域相关联,直接依据图像特征去预测单词。该结构在编码阶段使用目标检测算法Fast R-CNN提取图像的区域特征。解码阶段将句子中的词语分为视觉词与文本词,如果当前时刻所产生的词是文本词,那么这个单词通过语言模型从文本词汇库中生成;如果是视觉词,由目标检测算法直接由图像标定区域特征产生的视觉词进行填充,最终形成描述。使用神经网络模型来提取句子模板,有效地解决了传统模板填充语句呆板的问题。
Yu等人[29]提出使用Transformer作为解码器,Transformer是一种仅使用Attention而不使用RNN或CNN的模型。该工作使用Faster R-CNN模型从图像中提取视觉特征,经过Transformer 进行再编码后输入另一个Transformer进行解码,编码部分也可不经过Transformer的编码直接输入到解码器中。由于Transformer能够获得图像和文本各自注意力状态以及图像文本间的联合注意力,因此能够生成更高质量的描述文本。
人类在描述一张图片时,不仅从图片本身获得相关信息,还有着其他相关背景知识地支撑。知识图谱的发展和应用也为这一方向提供了可能。Lu 等人[30]在图像描述中引入了知识图谱相关的知识。该工作先使用CNN和LSTM的编码器-解码器架构来生成图像描述的文本模板,然后使用基于Knowledge Graph的集体推理算法,根据实体类型和频率在模板中为每个槽填充通过知识图谱检索的特定命名实体。最终的描述结果在结构语义上能够得到不错的提升。
1.4 小结
上述简要介绍了图像描述在编码器-解码器架构上的一些代表性工作。(1)在编码阶段主要表现在引入了目标检测和关键词提取。对于图像特征的提取影响着后续文本生成的工作,在编码阶段要求更好地提取图片内的信息以及图片内各目标之间的联系、目标检测以及注意力机制等方法的使用都是出于这样的目的。(2)为了编码器输出的特征能够更好的应用,在解码阶段创造性地引入卷积神经网络(CNN)解码、双层解码器和知识图谱等外领域的知识。不难看出,在未来相当一段时间内,图像描述的研究工作还会在编码器-解码器架构上进行创新和发展。
2 方法实现及改进
在编码器-解码器架构上对于图像描述算法的后续改进主要有这样四种方法:注意力机制、对抗生成网络、强化学习、图卷积神经网络。图4 简要概括了各类方法。
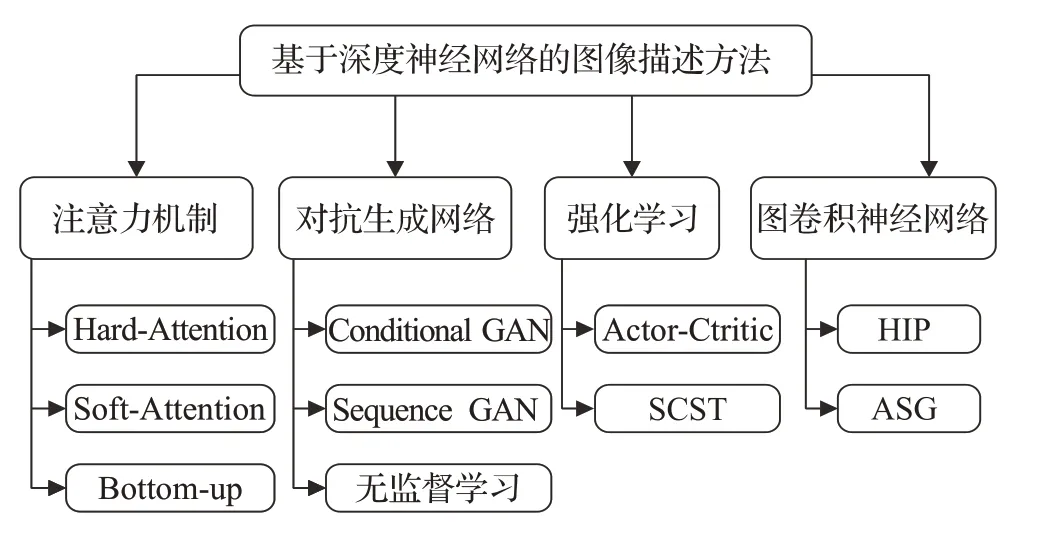
图4 基于深度神经网络的图像描述方法
2.1 注意力机制
2.1.1 概念
从最基本的意义上讲,注意力定义为从所有可用信息中选择一个子集进行进一步处理的过程。视觉注意对于建立图像内部表示的时空连贯性至关重要。注意力机制在图像描述领域的引入得到了惊人的效果。
随着生成描述语句的多样复杂化,对应的句子向量也变长,为了应对这样的长序列,注意力机制在图像描述中应用逐渐广泛。目前图像描述主流的注意力机制有这样几种:自注意力(Self-Attention)[31]、硬注意力(Hard Attention)[32]、软注意力机制(Soft Attention)[32]。
自注意力机制是一种与单个序列自身不同位置相关联的注意力机制,其目的是计算同一序列的表示形式。例如语句“A dog is running after a cat.”句中单词的生成都依赖于与其余单词的内在联系。每个单词vi与序列中其他单词vj的内在联系eij可以用公式(3)表示:

在经过softmax层归一化后可以得到对应每个单词的注意力权重,以此来进行选择后续的单词生成。
在图像描述模型应用中,自注意力机制一般结合Transformer 模块使用,Yu 等人[29]应用的Transformer 模块中有这样的自注意力机制,这个模块能够获得图像信息和文本信息各自注意力状态以及图像信息和文本信息之间的联合注意力状态,因此使得模型性能得到不错的提升。
硬注意力机制将集合向量中权重最大的一个向量赋值为1,其他向量权重值为0,这样就达到了只关注权值为1 向量对应图像区域的目的。其上下文向量z^t可以用公式(4)表示:

其中,ai表示图像区域i的向量,st,i表示当图像区域ai被选中时取值为1,否则为0。
在图像描述模型应用中,应用硬注意力机制能减少训练的时间成本,缺点是模型不可微,需要采用更复杂的技术进行处理,例如使用蒙特卡洛方法或者强化学习等。
软注意力机制给以集合向量中每一个向量介于0与1 之间的注意力权重,权重之和为1。其上下文向量可以用公式(5)表示:

其中,αt,i表示图像区域ai在t时刻被解码器选中输入下一时间步长的概率。
在图像描述模型应用中,应用软注意力机制可以使得模型更加平滑且可微分,缺点是当输入数据量很大时,相应的参数量将很大,对于硬件要求很高。相比而言,由于软注意力机制良好的解释性,其在主流的研究中得到了更广泛的应用。
2.1.2 相关工作
Xu等人[32]在2016年在NIC模型的基础上把注意力机制应用在图像描述的图像特征中。其基本思想是将编码阶段获取的图像特征进行注意力处理,解码阶段使用LSTM。在NIC模型中,生成预测句子中的每一个单词时,没有考虑图片中对应的位置,它接受的输入是上一步预测得到的单词和隐藏层的输出,注意力机制就是在预测每一步单词的同时加入对应在图片中的位置信息,即ht+1=f(ht,xt,z^t),z^t∈RD。如图5所示,模型在预测下划线单词能关注图中亮点部分信息,而不是使用整张图片的编码信息进行输入。该文章提出了两种注意力机制:硬注意力机制和软注意力机制。训练时模型接受的输入是一张图片和对应的描述,描述中的每一个词会被编码为一个one-hot向量。在LSTM中的解码部分,与NIC 模型从CNN 的最后接一个全连接层来生成固定长度的向量不同,而是直接获得卷积的结果,也就是一张张特征图。特征图的尺寸为n×n,数量为D,实验可知,每一张特征图中对应位置也就是关注的图片中的相同的位置,整张图片关注区域的集合可以表示为a={a1,a2,…,aL},ai∈RD,L=n×n。这里集合中的每一个向量也就对应图片中某个区域的特征信息。

图5 Attention机制可视化
Lu 等人[33]提出了注意力机制的改进工作。这项工作考虑生成描述时与视觉信息无关词的问题,如“the”“of”这些词和图片内容是无关的,而且有些需要视觉特征来生成的词,也可以直接通过语言模型进行预测,例如“taking on a cell”后生成“phone”,因此在LSTM 上进行了扩展,加入了“岗哨向量”,存储着解码器中已有的知识信息。同时提出新的自适应注意力机制,使得模型在生成每个词时,可以决定模型是关注视觉信息还是只依靠语言模型,如果需要关注视觉信息,通过空间注意力来决定关注图像的哪个区域,其机制如图6 所示。自适应上下文的向量定义为C^t,这个向量融合图像的空间特征和视觉哨岗向量βt。具体计算公式如公式(6)所示:

这个创新的改进在当时达到了最好的水平,并且在现在的COCO排行榜上仍排名很高。
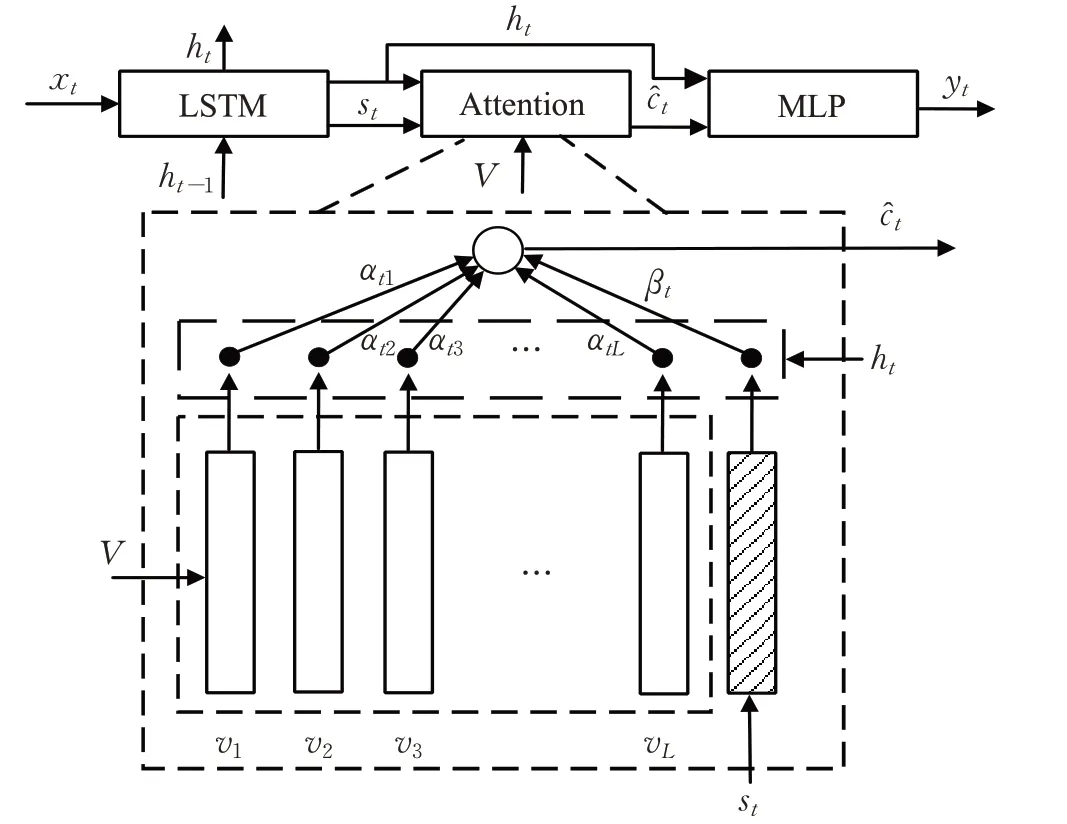
图6 视觉岗哨的自适应注意力模型
Anderson等人[24]引入了Top-down、Bottom-up机制。该模型编码器使用目标检测算法Faster R-CNN来进行提取图像的区域特征。为了提升提取特征的能力,对Faster R-CNN 的输出和损失函数进行了改进,设计了属性分类的部分。Bottom-up机制用来提取图像各区域的特征向量,Top-down的机制用来分配Bottom-up提取的特征对文本描述的贡献度,两者提取到的特征组合得到联合注意力权重。在解码阶段使用一个双层LSTM模型,分别是Attention LSTM和Language LSTM,由软注意力加权后的图像特征向量和Attention LSTM 的输出作为Language LSTM 的输入,产生最终的描述。这样的Top-down、Bottom-up 机制能够使模型关注图像中重要的对象目标,使得描述的结构主次分明。这项工作在编码和解码阶段的改进在当前仍具有极高的利用价值。
Huang等人[34]在文献[35]工作的基础上加入了AoA(Attention on Attention)模块,该模块增加另一种注意来扩展了常规注意机制。该模块通过两个线性变换生成一个“信息向量”和一个“注意门”。信息向量通过线性变换从当前上下文和关注结果中导出,并存储注意力信息与来自当前上下文的信息。注意门获取查询信息和注意力结果,并通过另一个线性变换加以sigmoid 激活得出。随后,AoA通过使用逐元素乘法将注意门应用于信息向量来增加另一个注意力,得到“关注信息”,即预期的有用知识。在该模型中,AoA模块应用在编码器和解码器中,在编码器中,首先提取图像中的特征向量,并采用自注意力模块对它们之间的关系进行建模,然后应用AoA 来衡量它们之间的关联程度。在解码器中,AoA 模块能过滤词嵌入向量ct中无关的信息,仅保留注意力部分,随后使用LSTM进行解码输出。这样组成的一个AoANet,结合强化学习能够更好地解决不相关注意力问题,达到当时最优的性能。
2.1.3 小结
注意力机制最初在计算机视觉领域提出,在自然语言处理领域也得到了广泛的应用。对于结合计算机视觉和自然语言处理的图像描述研究来讲,注意力机制已成为不可缺少的一个组件,也是当前研究的重点之一。在解码器生成下一时间步长的单词时,注意力机制能够起到让模型将“注意力”集中到图像中最相关的那个区域,使得图像和生成文本间联系更加紧密,因此能达到很好的效果。
2.2 生成对抗网络的方法
2.2.1 概念
先前的图像描述方法主要通过极大似然估计(MLE)的思想来训练模型,即最大化训练样本出现的可能性。传统的编码器-解码器架构在训练上多采用交叉熵作为损失函数,这样会使模型在生成的图片描述会高度模仿Ground Truth,这是全监督学习的优势,也是局限所在,它生成的描述会更加泛化,从而抑制了多样化的表达。基于这样的考虑,有研究者把在图像领域有着优异表现的生成对抗网络方法融入到图像描述中。
生成对抗网络(GAN)[36],由一个生成网络和一个判别网络组成,二者互相竞争训练,最后达到一种平衡。如图7 所示,生成网络通过机器生成数据(大部分情况下是图像),目的是“骗过”判别网络,判别网络判断这张图像是真实的还是机器生成的,目的是找出生成网络做的“假数据”。GAN 的核心思想是基于判别网络的“间接”训练,判别网络本身也在动态更新。
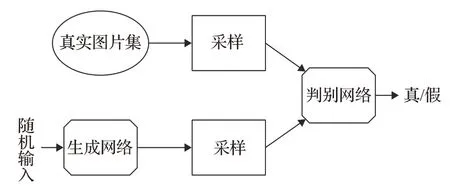
图7 GAN基本结构
2.2.2 相关工作
Dai等人[37]首次将Conditional GAN 运用在图像描述,该方法生成的图片描述贴近人类的表达,改善了句子的自然性和多样性。如图8所示,该模型由一个生成网络和一个判别网络组成。生成网络使用传统的编码器-解码器架构,用CNN提取的图像特征及噪声作为输入,用LSTM生成句子。随后通过蒙特卡洛树搜索算法从判别网络得到损失,并通过策略梯度算法更新参数,输入图像得到伪造的句子描述。判别网络用LSTM 对句子编码,然后与图像特征一起处理,得到一个概率值。在训练判别网络时,把对自然性的判别和对相关性的判别区分开,也就是说,判别网络既要判别句子是否像是人类生成的,又要判别句子和图片是否相关。这项工作以产生多样性描述为切入点引入了Conditional GAN 的结构,实验证明在多样性会明显好于传统的模型,但是该模型算法和人类描述还是有着不小的差距。
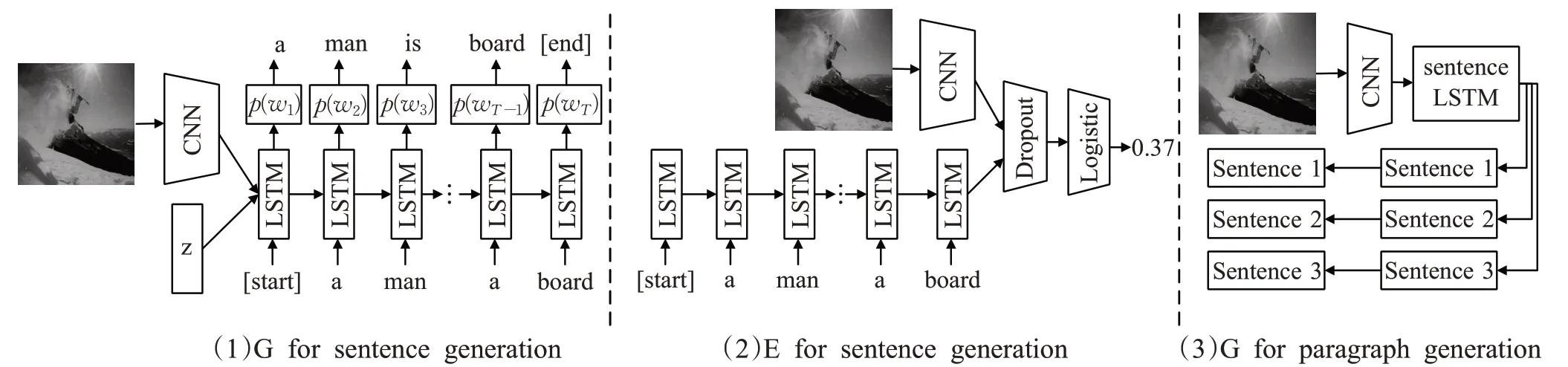
图8 Dai等人模型
同年,Shetty等人[38]也同样使用了Conditional GAN的结构在图像描述上,其主体结构与上一项工作差别不大。不同之处主要是在输入项中除CNN 和噪声特征外,还有目标检测的特征,通过常用的目标检测网络Faster R-CNN 得到。为了让生成网络捕捉到更清晰的目标信息,在改用Gumbel-Softmax[39]的技巧把采样过程近似成连续可微的操作取代策略梯度算法来更新参数。与文献[37]区别在于提出了一个判别网络,它接受图片与其对应的描述,并惩罚生成网络组内相似度高的描述。这个判别网络有两个计算距离的核心,一个计算图片与描述间的距离来判断描述是否准确,另一个计算不同描述间的距离来判断描述是否足够多样化。这种的机制能够使得生成网络生成更加多样化的描述语句。
此外,Zhang等人[40]提出的模型由两个不同的GAN组成。第一个GAN 基于文本描述生成初始的形状,基础的颜色,然后从随机noise中绘出背景分布,产生低分辨率图像,第二个GAN通过结合文本描述,进行图像的细致化绘制,产生高质量的图像。Shekhar 等人[41]拓展了COCO数据集,并通过对抗样本验证了Lavi模型的鲁棒性,Dai 等人[42]则使用对抗样样本训练解决图像描述任务生成的描述缺少独特性的问题。可以看出,在使用生成对抗网络来训练的模型能解决生成的描述缺少多样化的问题。
以上的方法主要是基于公开数据集上的有监督学习,近年来有些研究者开始使用无监督的方式训练图像描述的模型。Feng 等人[43]首次提出了这样的一个无监督的模型,它使用对抗文本生成方法在语料库中训练一个语言模型,生成网络接收CNN提取的图像特征,产生基于该特征的句子。判别网络判断该句子是模型产生的,还是来自语料库的真实句子。生成网络通过生成尽可能真实的句子来骗过判别网络,为了实现这个目标,模型在每个时间步骤给生成网络一个奖励,并将此奖励命名为对抗性奖励。通过预训练好一个视觉检测器,对每幅图像中检测里面的视觉概念,如果生成的句子里包含了视觉概念,那么给奖励。为了产生的描述比较准确,图像和句子被投射到一个共同的潜在空间。给定投影图像特征,可以解码对应的描述,进一步用于重建图像特征。同样,可以将句子从语料库编码到潜在的空间特征,然后重建句子。通过对生成的句子进行双向重构,使得生成的句子能够很好地表达图像的语义,进而改进了图像字幕模型。这样基于无监督学习的模型能够更好地生成多样性描述,为研究者的后续研究提供了一个新的方向。
2.2.3 小结
通过生成网络和判别网络间的博弈,生成对抗网络的在图像描述算法中的应用能使解码器生成比较逼真的句子,文字更加自然和多样。但也存在着在评价标准中得分不高的缺点。
2.3 强化学习的方法
2.3.1 概念
强化学习[44]是机器学习一个领域,它主要包含智能体(Agent)、环境(Environment)、行动(Action)、奖励(Reward)四个元素。智能体通过交互和反馈的方式进行训练,环境从中获得惩罚或者奖励,最终解决特定的任务。图9 描述了强化学习的基本流程。强化学习在深度学习各领域也有着广泛的应用,传统的图像描述研究,都是将单词生成看成一个分类的问题,主流模型也是利用交叉熵损失函数来训练模型。但是利用交叉熵损失函数训练存在以下问题:模型训练和测试阶段存在曝光误差,交叉熵损失函数无法直接对不可微分的评价标准进行微分运算。强化学习能够同时解决这两个问题,它能够直接用来优化不可微分的评价标准。

图9 强化学习基本结构
2.3.2 相关工作
Ranzato等人[45]将BLEU和ROUGE-2评价指标作为强化学习的奖励来训练模型。在训练阶段,句子的前几个单词使用交叉熵损失函数训练,剩下单词采用强化学习训练。随着逐步提高强化学习的比例,最终整个语句都用强化学习进行训练。针对在图像描述中交叉熵损失函数无法直接对不可微分的评价标准进行微分运算的问题,Liu等人[46]提出在强化学习中将SPICE和CIDEr评价指标作为奖励,并使用策略梯度来优化上述指标的参数。该模型使用蒙特卡罗方法来抽取样本并估计每次时序上的回报奖励。在加入强化学习后,图像描述算法的效果有了显著的提高。
Ren 等人[47]同样使用强化学习训练图像描述模型,并采用了Actor-critic 结构。该模型将智能体定义为图像描述生成网络,环境状态定义为当前状态的视觉特征和生成的描述,行动定义为可用单词,奖励定义为在同一向量空间内图像和其真实描述对应的视觉向量和文本向量之间的相似度。其策略、奖励和价值函数利用深度神经网络进行近似,视觉特征使用VGG-16网络进行编码,语义特征使用RNN 网络进行编码。它通过上述结构训练一个“策略网络”和“价值网络”相互协同来生成图像描述。策略网络由VGG16 和LSTM 组成,它用于在给定当前状态预测下一步操作。价值网络在策略网络结构基础上添加用于回归任务的多层感知器,用于评估给定图像特征的下一个单词和生成语句的前一个单词。实验证明在COCO 数据集上该结构能够达到当时最优的结果。
Rennie等人[35]提出了一种新的序列训练方法,简称SCST(Self-Critical Sequence Training),并证明SCST算法可以极大地改善图像描述算法的性能。该方法通过直接对CIDEr评分标准进行优化,该模型基于策略梯度的强化学习算法建立一个基线,即通过贪婪搜索算法选出概率前n大的句子作为这个基线,模型会抑制得分在基线以下的语句,激励得分在基线以上的语句。这可以使模型更有效地对CIDEr评分标准进行训练,并使用策略梯度来更新模型。这样的SCST 方法在MSCOCO数据集上取得了当时的最优结果。后来的很多研究者也在这样的一个模型进行了改进。
2.3.3 小结
强化学习在图像描述算法中的应用主要表现在对评价标准的直接优化,从源头上能显著提升生成描述的质量,因此在已有模型上加入强化学习算法能够有效地提升模型的性能。
2.4 图卷积网络的应用
2.4.1 概念
图卷积网络(GCN)是对图数据类型执行卷积的网络,而不是CNN对像素组成的图像执行卷积。一般地,图数据可以用G=(V,E)来表示,V代表图的顶点,E代表图的边,图10描绘出图卷积网络的基本框架。
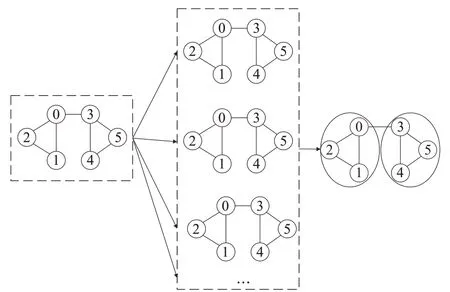
图10 图卷积网络结构
CNN旨在从图像中提取最重要的信息以对图像进行分类,GCN 也会在图形上通过过滤器来寻找有助于对图形中的节点进行分类的基本顶点和边缘。在CNN中,所有像素之间的节点连接是统一的,这足以解决图像分类的问题。但在节点连接是动态的情况下,CNN将达到其极限,因为CNN 仅适用于具有规则结构的数据(欧几里德域数据),而GCN 能够处理非欧几里德域数据。因此GCN在处理图像分类等任务上有着优异的性能。
2.4.2 相关工作
Yao 等人[48]提出了一个层次解析(HIP)的结构。该结构会将图片解析成树状结构:整张图片作为该结构的根节点,由Faster R-CNN 提取图片得到的一系列Region-level区域作为中间节点,由另一个Faster R-CNN来提取图片的Instance-level 区域作为叶子节点。在该层次结构上,构建具有区域级别的有向边的语义图,其中顶点表示每个区域,而边缘表示各区域之间的关系。利用图卷积网络丰富该语义图各区域间的视觉关系,这能显著改善图像描述的质量。该模型使用了GCN结合图像内两种不同的特征,使得能在解码阶段生成高质量的描述,增强了模型的可解释性。
Chen等人[49]提出了一个抽象场景图(Abstract Scene Graph,ASG)的结构,见图11。应用图结构来提取图像内主观想表达的物体、属性以及关系特征,该结构能够更细粒度反映出用户主观想表达的描述意图,同时生成的描述也更加多样化。ASG模块中设置三类节点:物体节点(obj)、属性节点(attr)和关系节点(rel),这样能够充分抽取出图像中的特征,在应用图注意力机制和更新机制下,通过Up-Down Attention 中的双层LSTM 来生成多样性的描述。上述模型能够基于给定的ASG模型来主动地实现更好的交互性、可解释性、多样性描述。Wang等人[50]使用了类似的图结构对图片中的节点进行增强,并使用时序卷积神经网络(TCN)沿时间维度建立多张图片之间的交互,得到集合中图像内部关系和跨图像关系的特征,最后输入到层次化解码器中来生成一段小故事。上述跨图片生成可解释性段落的思路也是未来图像描述的一个研究方向。

图11 ASG结构
2.4.3 小结
人类看图描述时,会将图像抽象看作一个场景,然后观看和推测图像内各目标之间的关系,将这样的关系转化为图结构能够更好地保存特征的可解释性与推理性。因此在图像描述中应用GCN能更好将图像中物体间的特征保留,并和文本更好地匹配来生成高质量的描述文本。
2.5 小结
在现在主流的图像描述模型中,都会在编码器-解码器的基本架构上加入注意力机制来提高模型的性能,注意力机制能够在生成文本时突出图像中的主体,并能够准确表述出主体间以及与其他目标之间的关系,这也是目前注意力机制在图像描述模型广泛应用的原因。生成对抗网络(GAN)的应用,其通过生成网络和判别网络间的博弈来生成更加生动的、贴近原图片的自然化描述,虽然其评价得分不高,其特点对于机器人视觉或者盲人导航却很适用。强化学习从评价标准出发,利用强化学习的方法对其进行优化,可以说是更加标准化的一种措施。这对于图像检索、医学CT 报告生成这样有格式化需求的场景是个不错的选择。GCN能有效地抽取图像内各个目标之间的联系,并对节点特征信息和结构信息进行端对端的学习,其在图像描述的公开数据集上能够生成具有交互性、可解释性、多样性描述。只是随着网络层数的增加,模型的性能会大幅下降,并且其可扩展性差,模型参数过于冗余,收敛慢,训练时间长。各方法的性能对比如表1所示。

表1 不同图像描述方法性能对比
3 实验分析与对比
本章首先整理了目前应用于图像描述的公开图像数据集,分别进行介绍和对比,接着介绍了针对图像描述领域的主流评价标准,最后在此基础上对现有不同图像描述结构的性能进行实验对比和分析。
3.1 数据集
深度学习是在大量数据集的基础上驱动实现的,公开数据集的提供有利于各领域的发展。在图像描述领域,目前广泛应用的数据集主要有以下三种,主要对比如表2所示。

表2 数据集对比
(1)Microsoft COCO数据集[51]
MSCOCO 数据集被广泛运用于目标检测、目标追踪以及图像描述。该数据集旨在通过将对象识别问题置于更广泛的场景理解问题的上下文中,从而提高对象识别的最新水平,并通过收集包含自然环境中常见对象的图像来实现。该数据集使用专业机构人为地对图片进行描述,每张图片收录5 句或者15 句参考描述,可以想象这项工作消耗了大量的人力物力。MSCOCO数据集对应的标注集,一般以json 格式保存。第一种是MSCOCO C5,每张图像包含5 句参考描述。第二种是MSCOCO C40,这个标注集对应只包含着5 000 张图片,这些图片是从MSCOCO数据集中随机筛选出来的,与C5 不同的是,它的每张图片包含着40 句参考描述。一般使用C5 标注集即可满足训练的要求,通常使用MSCOCO数据集也一般默认使用MSCOCO C5。这个数据集也是目前图像描述研究者实验的首选。该数据集有超过33 万张图片,其中20 万有标注描述,包含91类目标,328 000张图像中总共有250万个带有标签的实例,这也是目前最大的语义分割数据集。
(2)Flickr8K[52]和Flickr30k[53]数据集
从数据集的命名可以看出这两个数据集分别包含了8 000和30 000(确切是31 783)张图片。这些图片从Flickr相册网站选出。该数据集每张图片具有5句人工标注的参考描述,这两个数据集的验证集和测试集使用的图片数量都是1 000 张,剩余的图片用于训练阶段。可以看出,相比MSCOCO数据集,这两个数据集在数量方面存在着明显的不足,但由于MSCOCO数据量太大,在训练过程中会花费大量的时间,Flickr 数据集在初探图像描述时可以使用来进行实验来验证模型的效果。
(3)Visual Genome数据集[54]
Visual Genome(VG)数据集是斯坦福大学李飞飞组在2016 年发布的大规模图像语义理解的数据集,初衷是该数据集能够像ImageNet那样推动图像在高级语义理解方面的研究。该数据集包含超过10 万张图像,其中每个图像平均具有21 个对象,18 个属性以及对象之间的18 对关系,在标注数据方面包含了每张图片的目标,属性以及图像内目标间的关系。该数据集规范化区域描述中的对象、属性、关系和名词短语,以及Word-Net同义词集的问题答案对。它代表了图像描述、对象、属性、关系和图片问答的最密集最大的数据集。而针对VG 数据集中的区域标注过程,该数据集的人工标注并不是直接标注目标间的关系,不然标注员往往倾向于标出一些高频而琐碎的关系,如wearing(woman,shoes),而非聚焦图片中最显眼的部分。在生活中,人们在用自然语言描述图片时,也更倾向于捕捉图片的主体部分,所以,标注员最终被要求先给出描述,再根据描述来标注区域(region)、边界框(bounding box)、目标(object)、关系(relationship)等其他内容。在最原始的VG数据集中,数据太过庞大,其中目标的标注也过于杂乱,还有命名模糊和boundingbox重叠的问题。在2019年Liang等人[55]对这个数据集进行了改进,该数据集旨在提取图片中真正与视觉相关的联系,同时也改善了原VG数据集中谓语冗余的问题。在此使用此数据集进行特征表示的预训练后,在图像描述模型的性能上有着普遍的提升。该数据集提出时间相对较短,不少的研究工作开始使用这个数据进行预训练,相信在不久的未来,VG数据集会得到更加广泛的应用。
3.2 评价指标
很显然,评价标准有权威性的是人类自己,但是要对深度学习中海量的数据进行评价单靠人工是不现实的,因此人们也提出了各类自动评价标准,旨在最终实验的结果尽可能和人工评价相关接近。最主流的评价标准有以下几种:BLEU、ROUGE、METEOR和CIDEr。
(1)BLEU[56]
BLEU(Bilingual Evaluation Understudy)最初是用于评估从一种自然语言机器翻译为另一种自然语言得到文本的质量的一种算法。这和图像描述算法评价生成文本的要求是一致的,即对生成的待评价语句和人工标注语句间的差异进行评分,得分输出在0~1 之间。该标准现已成为图像描述算法应用最广泛的计算标准之一。
对于图像Ii,图像描述算法对于这个图像生成的描述语句ci,人工标注的五个描述语句集合Si={si1,si2,…,si5} ∈S,要对ci进行评价。BLEU 的计算公式如下所示:
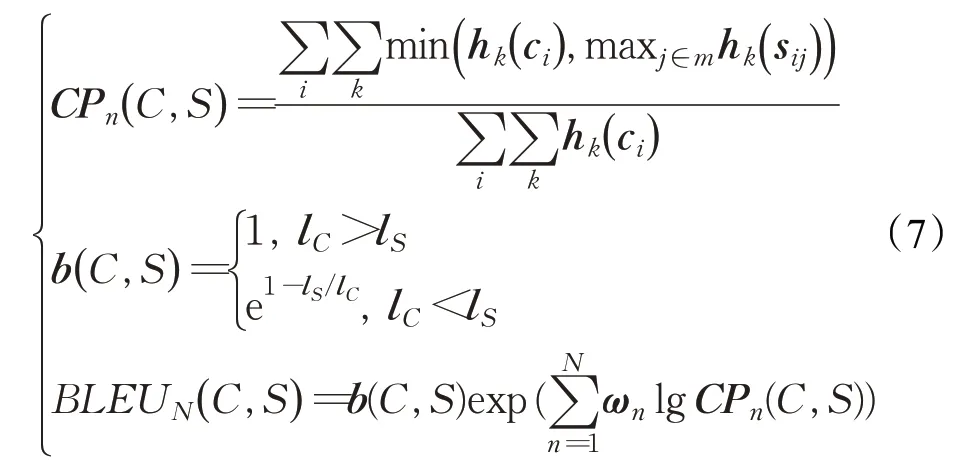
其中,每一个语句用n 元组ωk来表示的,n 元组ωk在人工标注语句sij中出现的次数记作hk(sij),n 元组ωk在待评价语句ci∈C 中出现的次数记作hk(ci),lC是待评价语句ci的总长,lS是人工标注语句的总长度。b(C,S )是一个简洁性惩罚机制,由于BLEU 的评价标准设计倾向于更短的句子,因为这样的精度分数会很高,为了解决这个问题,该标准使用了乘以简洁性惩罚参数来防止很短的句子获得很高的得分,具体规则在公式(7)中可以看出,如果有多个候选的参考语句,该标准会选择待评价语句和参考语句两者长度最近的那个参考语句进行计算评价。BLEU得分越高,性能也就越好。
(2)ROUGE[57]
ROUGE最初是用于评估自然语言处理中的自动摘要和机器翻译的评价标准,它是由自然语言处理领域内多名专家对指定数据给出专业的描述,然后将自动生成的摘要或翻译与其进行比较。通过比较两者之间如n元语法,词序列和词对重叠的数目来评价自动摘要或者翻译的质量。通过与专业性摘要的对比评价,能有效提高模型的可靠性。ROUGE得分越高,性能也就越好。
(3)METEOR[58]
METEOR 最初也是用来评价机器翻译输出的标准。该算法基于整个语料库的精度和召回的调和平均值。简而言之,它对比待评价语句和参考语句之间一元组的重叠部分,并根据语义、词干形式、精确度来匹配一元组。相比BLEU 标准,由于这个标准引入了外部知识,因此评价时更加接近人类的判断。METEOR 得分越高,性能也就越好。
(4)CIDEr[59]
不同于上述标准,CIDEr是专门设计用于评价图像描述算法的,它通过计算每个n 元组的TF-IDF 权重得到待评价语句和参考语句之间的相似度,以此评价图像描述的效果。一个n 元组ωk在人工标注语句sij中出现的次数记作hk(sij),在待评价语句中出现的次数记作hk(ci),n 元组ωk的TF-IDF权重gk(sij)如下所示:
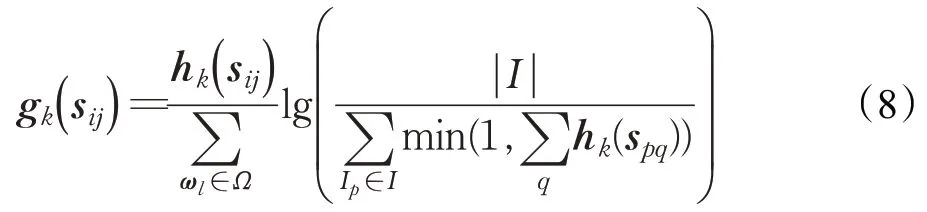
其中,Ω 是所有n 元组的语料库,I 是数据集中所有图像的集合。可以看出,当有n 元组频繁出现参考语句中,TF 给以该n 元组更高的权重,IDF 则会降低该n 元组在生成语句中的权重。简而言之,该方法会降低对图像视觉内容没有帮助的高频单词的权重。
对于长度为n 的n 元组的CIDErn评分计算公式如下:

其中,gn( ci),gn( sij)分别是gk( ci)和gk( sij)生成的向量,‖gn( ci)‖,‖gn( sij)‖则是对应向量的模。同样的,CIDEr的得分越高,表明待评价语句和参考语句之间的相似度越大,生成的语句的质量也就越好。
3.3 实验结果对比与分析
本节主要进行实验的复现和对比,以BLEU、METEOR、CIDEr三种不同的标准进行评价分析。实验环境基于Ubuntu18.04 系统,CPU 为Inteli9-9900k,GPU为NVIDIA GeForce RTX 2080Ti,16 GB内存,Python3.7+Cuda10.1的Pytorch或者Tensorflow深度学习环境。
实验数据集使用MSCOCO2014的数据集和500 MB左右包含图像描述注释的json 文件,在处理注释文件时,删除了非字母字符,将剩余的字符转化为小写字母,并将所有出现小于5 次的单词替换为特殊的单词UNK。最终在MSCOCO数据集中得到9 517个单词,也就是最终使用的语料库。
将生成语句的最大长度设为16,采用Dropout 方法防止过拟合,参数一般设为0.5。在训练损失函数阶段,训练轮数一般设为30,其他参数如解码器输出向量维度及解码器隐藏层维度D,beam search(集束搜索)数量N,批处理大小B在表3 中列出,D列中有两个维度(如500/1 000)表示解码器中两个不同的解码器,其各自隐藏层的维度。

表3 模型参数
表4 和表5 中列举主流的一些图像描述模型。表4中列举了上文所述在编码器-解码器架构的代表模型。NIC[18]和模型[20]是传统的编码器-解码器架构,一般地,以NIC 模型作为基准模型进行对比。模型[22-24]从编码器端进行改进,相比NIC 模型,这些模型的评价指标得到了提升,这主要得益于更好地提取和利用图像的特征。在模型[22]中是在编码中将关键字语义和图像的特征进行结合,模型[23-24]利用目标检测的算法提取图像特征,这样可以提取图像中的关键信息,能够使得生成文本更加完整精确。模型[25-30]从解码器端进行改进,相比NIC 模型,这些模型的指标也得到提升。利用LSTM、GRU、Transformer 以及知识图谱等方法来解码图像特征,将图像编码更好地“翻译”成文字描述。其中Transformer和知识图谱的方法最终的指标提升最为显著,主要是由于Transformer结合图像和文本各自的注意力信息以及两者之间的联合注意力信息,知识图谱得益于引入了外部知识体系,以此来能生成更接近人类的描述。可以得出这样的结论:解码器端更好地提取并利用图像的特征是会得到性能的提升,在编码器和解码器端提高图像信息和文本信息的关联交互也能有效提高模型的效果。

表4 编码器-解码器架构的模型

表5 不同方法融合模型
表5中列举了添加注意力机制(Up-Down[24]、Xu et al.[32]、Lu et al.[33]、AoANet[34])、生成对抗网络(G-GAN[37]、Dai et al.[42]、Feng et al.[43])、强化学习(SCST[35]、Liu et al.[46]、Ren et al.[47])、图卷积神经网络方法(HIP[48]、Chen et al.[49])融合后模型的性能。显而易见,加入注意力机制、强化学习后,实验的效果都得到了显著的提高,所有的评价指标都有着不错的提升。但是将对抗生成网络应用到模型中后,文献[37]的指标降低了,但生成的文本其实更加自然多样化,这是由于评价指标的限制,多样的描述文本反而得不到很高的评分,这也是未来研究需要改进的地方。基于图卷积神经网络的模型[48-49]在CIDEr的评价中得到了所有模型中最高的得分,并有着显著的优势,可以看出图结构在图像特征提取时能够更加细粒度提取图像内各对象之间的关系,生成更加高质量的文本。
4 目前挑战及未来发展方向
4.1 主要挑战分析
近年来,在某些格式要求相对固定的领域,图像描述算法能很好地代替人类生成满足需求的文本,比如医学图像报告,通知文书等。目前,对于编码器-解码器架构的改进还有着很多的挑战。
(1)模型如何正确理解图像的关键物体,并建立物体间的联系,对最终模型的性能有着关键的影响。如何更好地提取和利用图片中的特征,主流模型一般是使用卷积神经网络或者目标检测算法进行特征提取,但图片中的高层语义还是无法得到表述。基于注意力机制的模型,能够一定程度上从图片部分区域出发去生成更符合人类角度的描述,但还是存在一定的缺陷,当前在公开数据集下训练的模型对未知的物体还是无法正确地生成描述。
(2)图像描述的模型较为复杂,由于参数较多,模型训练的步骤比较复杂,训练时间也较长,一般都以指数量级继续训练,使得在实际应用时实时性不高。
(3)目前的模型依赖公开数据集训练,这样模型输入一般是固定的图像特征,这样对于同一个图像的描述内容基本没有变化,生成的文本会相对单一。
4.2 未来发展方向
图像描述是一个相对新的研究任务,经过研究人员近几年的发展,取得了巨大的进步。基于现有的研究成果,图像描述任务仍有着很大的发展空间。
4.2.1 从有监督到无监督
图像描述一般都是采用成对的图像-文本集的有监督学习,在实际应用时,获取这样成对的图片文本是一个耗费大量人力和时间成本的工程,这对于工业应用来说,获取数据的成本太高了。无监督学习可以摆脱这样的图像-文本集,大大节省了人力物力。使用公开数据集的图片和从目标网站爬取的文本语料库进行无监督学习,结合GAN的方法可以有效地解决问题,这样生成的文本也更加得丰富多样化。
4.2.2 从死板单一到丰富多样化
传统方法从同一张图片生成的描述基本是没有变化的,这并不符合图像描述的初衷,因此采用无监督学习以及Conditional GAN、SeqGAN 的应用,可以生成更加自然灵活的语句。
4.2.3 从语句到段落化
仅仅从图像中生成一句话往往很难完整地概括图片中的完整内容,因此从图片生成段落是一个必然的趋势,从几张有关联的图片生成一段故事也成为可能。
4.2.4 从复杂到轻量化
当前的图像描述模型较为复杂,在实际应用时往往很难落实,设计出更加轻量级的网络结构能够更方便地部署到工程落实中,乃至到手机等小型智能设备中,将这样的技术落实到现实生活中能够更好方便人类,自动驾驶、导航视觉障碍者都急需这样的技术支持。
4.2.5 评价标准的更新
现如今的图像描述不再满足接近训练文本,这在近几年的发展中已经趋于成熟,自然多样化的文本描述才是图像描述的要求归宿,因此现如今的评价标准已经无法满足这样的需求了,新的评价标准需求迫在眉睫。
5 结束语
本文从图像描述在深度神经网络中的发展应用出发,结合模型结构和算法的演变发展综述具有代表性质的图像描述方法,并对此进行不同方法的大致分类,在此基础上进行梳理和对比,并在公开数据集上进行了实验对比。实验表明,图像描述在基于编码器-解码器架构上已逐渐趋于成熟,在编码阶段旨在提取更高层次的语义关系来为后续解码阶段生成更为相关的描述,生成对抗网络和图卷积神经网络的引入为生成更多样化、人性化的描述提供了可能。为了应对当前社会环境的应用需求,图像描述的发展还有着不少的挑战。因此,基于深度神经网络的图像描述进一步研究还有很大的发展空间。
猜你喜欢
小学生必读(低年级版)(2021年10期)2022-01-18
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
新世纪智能(语文备考)(2020年4期)2020-07-25
家庭影院技术(2019年8期)2019-12-04
成都信息工程大学学报(2018年3期)2018-08-29
制造技术与机床(2017年7期)2018-01-19
电子器件(2015年5期)2015-12-29
电测与仪表(2014年13期)2014-04-04
语文知识(2014年4期)2014-02-28
