
基于个性化场景的5G基站节能方法
2021-05-28 05:07
移动通信 2021年3期
(中国电信股份有限公司研究院,广东 广州 510630)
0 引言
国内5G网络所使用的频谱资源,决定了单个5G基站覆盖距离较短,覆盖相同区域,比4G网络需要更多的基站。5G基站耗电量预计将是4G的3~5倍[1],给运营商的运营成本带来极大挑战。因此针对基站的节能降耗研究势在必行。
针对基站节能场景问题,国内外学者展开了深入的研究工作,且取得不错的成果。基站节能场景这种分类问题,按照建模方法可以分为两类:第一类是基于简单的线性模型或专家经验,依靠人工经验判断与操作;第二类是基于机器学习算法,如梯度提升回归树、神经网络等。实验证明,机器学习算法比传统方案具有更好的节能效果。
时间序列聚类算法是一种挖掘时间序列间相似性的有效方法,可以从数据中发现一些潜在的模式。近些年有很多学者将聚类算法应用到用户行为、业务分析等方面,取得不错的成效。Jeffrey Erman[2]等人采用K-Means和DBSCAN算法有效识别相似通信特征的流量组;Jiang ZHU[3]等人对微博用户时序数据的聚类分析发现了不同群体的情感特征等。李文璟等人[4]提出基于对称KL距离的用户互联网行为时序聚类方法;王潇迪等人[5]提出了基于负荷曲线形态聚类的k-shape算法在电力负荷的应用。
以上方法对初始值敏感,容易陷入局部最优,且目前涉及基站侧数据的聚类分析文献较少,对节能场景定义也相对保守和固化。为此,本文在提出一种基于轮廓系数迭代修正的AP聚类算法,无需预设参数,对基站业务的日负荷曲线进行自适应聚类;并考虑到“潮汐效应”导致网络资源利用率低的问题,结合周效应和汐节能时段对场景进行个性化定义,大大提高可节能空间。
1 数据描述和模型构建
1.1 数据描述
(1)研究对象
由于本文需要利用大量历史数据研究分析基站可节能的场景,考虑到在规模较小或者业务不发达的城市,人们对网络的需求量少,基站负荷变化规律不显著。因此,选取规模大、网络业务活跃的某个城市某运营商基站作为研究对象,从而验证模型的可行性及泛化性。
(2)变量描述
由于运营商数据量庞大,对历史数据的保存时间有限。为此,选取某城市某运营商2019年连续10周的时间序列数据,涵盖六万多个基站每日24小时的小时级业务负荷数据记录,除了业务负荷数据之外,还收集了影响业务负荷的相关因素的数据,如:
1)设备数据。包括生产厂商、室分、频点、方向角等。
2)业务数据。包括激活用户、PDCP(Packet Data Convergence Protocol)上下行平均流量等。
3)网络数据。包括上下行PRB(Physical Resource Block)利用率、各类信道占用率等。
(3)预处理
由于信号干扰、设备故障等问题,基站采集的数据往往存在缺失或噪音,需要对原始数据进行预处理,得到标准、连续的数据,以便挖掘和分析。
1)缺失值填补
针对时间序列数据常见的缺失,利用周期信息进行缺失值填补(简称周期性填补法[6])。
2)异常值处理
为保证聚类算法的有效性和指标解释的合理性,将指标数值超出正常取值范围,直接取上、下界数值。
3)特殊过滤
超低负荷基站(所有时点的负荷极差值小于0.1)属于全天候可节能,可采取深度休眠等策略,不在本文研究的范畴。
1.2 模型构建
(1)Affinity Propagation聚类[6]算法
不同于传统聚类算法,Affinity Propagation算法不需要指定聚类簇数或其他描述聚类个数的参数,而且样本中的所有数据点都可当作潜在的聚类中心,通过信息在节点之间传播直至产生一组高质量的聚类簇。
首先,基于节点间距离的定义,构建节点间的相似度矩阵做为输入,所有节点均作为等机会的候选聚类中心点。聚类过程中,候选聚类中心通过吸引信息矩阵(见式(1))和归属信息矩阵(见式(2))竞争,为避免震荡,引入阻尼系数λ更新迭代,淘汰部分候选中心,最终筛选出L个高质量的聚类中心(聚类数为L),即自动得出最优聚类中心,而避免事先人为指定,非聚类中心点也根据证据信息综合判断归类至合适的中心点完成聚类。

式中,R(i,k)表示i节点支持k节点为聚类中心点的支持度,其值越大,则k点成为聚类中心的可能就越大;A(i,k)表示k节点适合成为i节点的聚类中心的适应度大小,其值越大,则i节点与k节点为同一类的可能越大;S(i,k)和S(i,k')分别为相似度i行k列和i行k'列元素。

式中,λ∈(0,1]。
1)相似度矩阵
两两特征向量间的相似程度用欧式空间距离矩阵Ed来表示:
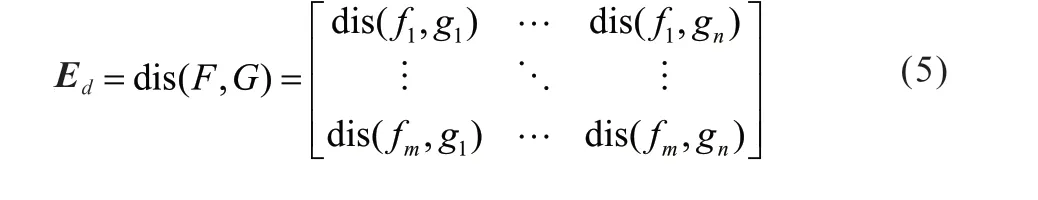
2)偏向参数
偏向参数(Preference)k是衡量点能否成为聚类中心的评判标准,该值越大,这个点成为聚类中心的可能性就越大。利用聚类评价指标选择合理的偏向参数值,能有效减少迭代次数,提高聚类精度。
3)轮廓系数
轮廓系数[7]是评价聚类效果好坏的一种方式,在相同数据的基础上用来评价不同算法、或者算法不同参数下对聚类结果所产生的影响。
根据样本i的簇内不相似程度ai和簇间不相似程度bi,定义样本i的轮廓系数:

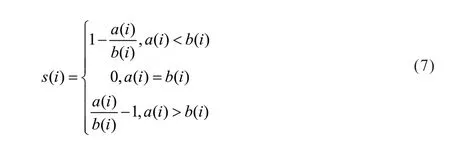
(2)优化
利用轮廓系数对偏向参数进行修正,采用改进AP聚类算法对负荷曲线进行自适应聚类,从而优化和改善聚类效果。优化Affinity Propagation聚类算法流程图如图1所示:

图1 优化AP聚类算法流程图
2 实证分析
基于上述方法,本文以某城市某运营商15 857个基站2019年连续10周的历史业务负荷作为试验数据,进行分析和验证。
2.1 基站业务负荷的周效应识别
本文采用Python软件进行建模和分析,具体过程如下。
第一步,对历史负荷数据进行缺失值填补、异常值剔除等一系列的预处理;
第二步,基于一个基站的日负荷曲线,采用AP聚类算法得出聚类结果,并计算结果的轮廓系数;
第三步,通过网络搜索法遍历中值的多个分位数,调整AP聚类的偏向参数(Preference),重复第二步;
第四步,选取轮廓系数最大的结果作为该基站最优的聚类结果,并识别所属的周效应类型,三种类型定义如下。
(1)周效应明显:如果聚类结果的轮廓系数大于0.65,则说明该基站日负荷曲线的聚类效果较佳,可认为该基站的周效应明显。
(2)周趋势一致:如果聚类结果的轮廓系数小于0.65且平均相似度大于0.9,则说明基站的日负荷波动是极度相似的,即该基站属于全周的趋势一致。
(3)无明显效应:除了上述两类基站以外,皆认为没有明显的变化规律。
2.2 日潮汐效应与汐节能时段识别
第一步,计算基站的潮汐效应系数,判断是否存在日潮汐现象。
假设f(x)为A基站一周七天24小时的业务负荷曲线函数,则潮汐系数定义为:
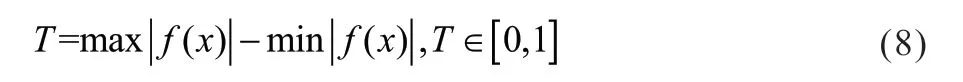
当潮汐系数T>0.5,则判定该基站存在明显的日潮汐现象,否则,日潮汐现象不明显。
第二步,对存在日潮汐现象的基站,计算日的潮时段和汐节能时段,结合周效应和汐节能时段,进一步定义基站的节能场景。
2.3 个性化节能场景的智能识别
结合基站的周效应类型及其日潮汐现象,准确识别日间多个有规律的可节能时段,作为基站的个性化节能场景:
对于周效应明显的基站,根据日分类的类别数,可分为两或三种模式(其他不考虑);再根据日天数,将两种模式基站分为1+6周效应、2+5周效应和3+4周效应,其中1+6周效应代表该基站一周七天的业务负荷曲线可分为两类,第一类为1天,第二类为6天的多种组合(如第一类为周日,第二类为周一到周六);对于三种模式基站,则可分为1+1+5、1+2+4等多种周效应。
在周效应下,进一步对不同类别的日潮汐现象做细分,两种模式基站分别对应第一类和第二类的汐节能时段,三种模式基站分别对应第一、二和三类的汐节能时段,从而更加精确、细化地描述该类基站的个性化节能场景。对于周趋势一致的基站,即一周七天都有相似的业务走势,只需要根据第一类日潮汐效应的汐节能时段,就可对其个性化节能场景进行定义。
针对上述对个性化节能场景的定义,智能识别出3个场景做示例,实现差异化节能策略。
(1)周效应明显的基站
图2为广州某商务大厦基站(ID:856338)在20190603-20190812共十周的业务负荷变化情况。从图2(a)可看出,该类型基站每周重复着相似的波动规律,即一周的前期负荷都比较高,到周末负荷处于低谷。

图2 广州某商务大厦基站20190603-20190812的业务负荷曲线图
图2(b)为日负荷曲线聚类效果图,可直观看出聚类效果较好,该基站的业务模式可分成两类,即周一至周五负荷曲线大致相同,而周末日负荷走势大体一致,可认为属于周效应明显基站。考虑到商务办公类基站在工作日的业务负荷要明显高于周末,汐节能时段在凌晨0-7点;而周末员工放假,出现全天候可节能的场景,符合实际情况,具有明显的周效应现象。因此,该基站的个性化节能场景为“5+2周效应(工作日效应):工作日的0-7点,周末全天候”。
(2)周趋势一致的基站
图3为新塘民营工业园基站(ID:485435)在20190603-20190812共十周的业务负荷变化情况,该类型基站日业务负荷曲线走势大体一致,在凌晨处于业务低峰期,经日潮汐分析输出汐节能时段,即0-7点,识别该基站的个性化节能场景属于“周趋势一致:每日0-7点”。
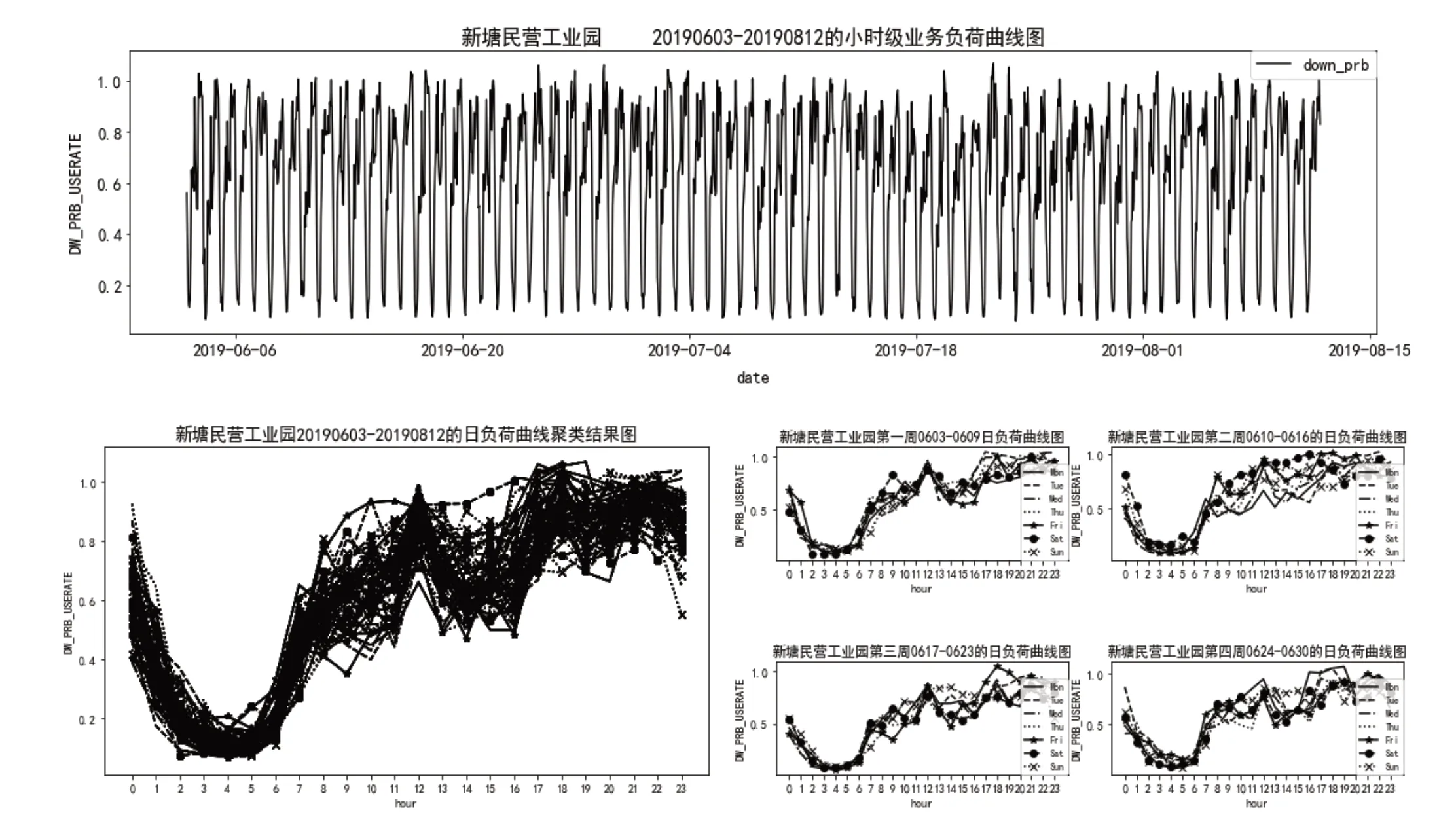
图3 新塘民营工业园基站20190603-20190812的业务负荷曲线图
(3)无规律基站
图4为花山支局基站(ID:856338)在20190603-20190812共十周的业务负荷变化情况,可看出该类型基站日业务负荷是随机波动的,经聚类得轮廓系数仅为0.236 171,没有明显的规律,不适合执行节能策略,以免影响用户体验。

图4 花山支局基站20190603-20190812的业务负荷曲线图
2.4 节能效益评估与分析
根据优化AP聚类和潮汐分析,可快速、有效地自动识别基站的个性化节能场景,周期性选择节能方式,智能化启闭节能策略,如表1所示。

表1 基站的个性化节能场景
从结果可得,广州某商务大厦基站(ID:856338)的个性化节能场景为5+2的工作日效应,第一类(周一至周五)汐节能时段在0~8点、19~23点,第二类(周末)汐节能时段在0~23点,一周可节能时长高达108个小时,可采取一周两策,在两种模式下的节能时段分别启闭合适的节能方式,预估站点能耗最大可节省64%。新塘民营工业园基站(ID:485435)个性化节能场景属于周趋势一致下,单日的汐节能时段在1~7点,可实施一周一策略,每周可节能时长42个小时,预估站点能耗最大可节省25%。而花山支局基站(ID:485710),考虑到该类基站容易出现突发情况和随机波动,为保证用户体验,不宜实施节能策略。
结果表明,个性化节能场景的智能、高效识别对能耗管理有显著的指导意义,基于某城市全量基站数据可测算出,在保证不影响网络性能指标KPI前提下,平均可节省功耗超过20%,具有良好的节能应用效果。
3 结束语
本文提出基于基站的日负荷特性指标,通过改进AP聚类算法,并结合日潮汐效应和节能时段,智能、高效地识别出基站的个性化节能场景。算例证明聚类效果的可靠性和识别节能场算法的有效性,有助于运营商在满足业务QoS[8]需求的基础上,提高基站的能源效率,达到5G基站节能的目的,可进一步应用到现网,实现5G基站能耗的智能化管理,优化网络资源,提升运营商市场竞争力和可持续发展能力。
猜你喜欢
凤凰动漫(军事大王)(2022年9期)2022-11-05
VOGUE服饰与美容(2019年6期)2019-07-17
中国生殖健康(2019年8期)2019-01-07
探索科学(2017年4期)2017-05-04
电子制作(2017年9期)2017-04-17
生活用纸(2016年6期)2017-01-19
中国交通信息化(2016年8期)2016-06-06
发明与创新(2015年33期)2015-02-27
发明与创新(2015年29期)2015-02-27
西南军医(2015年5期)2015-01-23
