
结合相机阵列选择性光场重聚焦的显著性检测
2021-06-15 09:09王世刚
中国光学 2021年3期
冯 洁,王世刚,韦 健,赵 岩
(吉林大学 通信工程学院,吉林 长春 130012)
1 引 言
显著性区域检测研究的目的是从图像中标记出最容易引起人注意的目标或最能表达图像的内容,常应用于图像检索[1]、图像压缩[2]、目标识别与跟踪[3]、图像融合[4]以及图像分割[5]等领域。
根据人类视觉选择注意机制,目前的显著性检测方法大致可分为自底向上和自顶向下两类。自底向上的显著性检测模型是由数据驱动的,利用图像的亮度、纹理、颜色和空间位置等特征,判断目标区块与周围的差异,进而计算出显著性。自顶向下的显著性检测模型[6-8]是由具体检测任务驱动的,需要通过类标签进行监督学习。Yan等人[9]提出了综合这两种机制的显著目标检测方法,由感知格式塔法则指导自底向上的模型,自顶向下模型则是使用计算模型描述注意力的背景连通性并生成优先级图。该方法的有效性虽优于无监督技术,但检测结果与基于监督的深度学习方法仍有一些差距[10]。与自顶向下的显著性检测模型相比,自底向上的显著性检测模型通常执行速度快并且易于适应各种情况,因此已得到广泛应用。Achanta等人[11]提出了一种频率调谐方法,从整个图像的色差得出显著图。Cheng等人[12]提出基于直方图的对比度和基于区域的对比度,其考虑了空间距离,克服了色彩对比度的局限性。Goferman等人[13]提出上下文感知方法,增强了显著目标附近的其他显著点。Fu等人[14]提出了结合颜色对比度和颜色空间分布的显著性检测算法的流程以及抑制噪声和伪影的细化过程。Sun等人[15]提出了融合高低层多特征的显著性检测算法,结合高层先验知识和低层的4种显著性特征,利用类间差异最大阈值对高低层特征进行线性和非线性融合,最终得到高质量的显著图。
近年来,基于图的显著目标检测方法[16-19]因其简单、高效等特点而备受关注。这些算法将图像表示为以超像素为节点的图,图的边为节点与给定种子或查询节点的相关性,通过传播模型将标签在图中扩散。传播模型一般基于聚类假设和平滑度假设,聚类假设认为同一集群中的节点应该具有相同的标签,平滑度假设则认为相同流行结构上的节点应该具有相同的标签。虽然这些方法的性能优于大多数自底向上的显著性检测方法,但是仍存在一些缺陷。例如,Yang等人[16]提出的基于图的流行排序算法中,用作背景查询的4个边界,可能会存在与前景相邻的情况,在背景估计中使用这样有问题的查询可能导致结果不理想或不完整。另外,采用标准平滑约束可能会遗漏区域局部信息。Wu等人[17]针对背景查询可能不可靠的问题,提出了边界显著性度量以去除边界种子中的显著性区域,获得可靠的背景查询,提高检测精度。Li等人[18]引入正则化随机游走排序来计算像素级的显著图,结果能反映出输入图像的更多细节。Wu等人[19]在标签传播模型中使用变形平滑度约束,考虑节点及其相邻节点平滑度,防止与背景对比度低的节点的错误标签传播。
但针对包含多个显著性目标和显著性目标的某些区域与背景区域对比不明显的场景,上述方法所得显著图不够精细,甚至会丢失某些显著性区域。故本文提出一种结合相机阵列选择性光场重聚焦的显著性检测,采集同一场景的多幅视点图像,利用场景的深度、聚焦等信息结合基于图的显著性检测方法,同时采用结合全局和局部平滑度约束的传播模型来解决上述问题。本文的主要贡献在于:第一,利用场景的多幅视点图像进行显著性检测,对中心视点图像进行结合bokeh渲染和超分辨的重聚焦,使得本文方法能够结合场景的深度和聚焦信息进行显著性检测。第二,在基于图的显著性检测方法的基础上提出了一种结合全局和局部平滑度约束的传播模型来防止错误标签的传播。另外,在包含多个显著目标的场景中,通过选择对场景的某一深度层进行重聚焦,同时对其他深度层产生不同程度的模糊,可以更精确、细致地检测出位于该深度层上的显著目标,一定程度上实现了可选择的显著性检测。
2 本文方法实践过程
本文提出的方法分为两个主要步骤,如图1所示。第一步,首先利用同一场景的多幅视点图像进行视差估计,所得视差图用于指导中心视点图像的重聚焦渲染[20]。重聚焦渲染过程结合了bokeh渲染和超分辨率重建,利用基于深度的各向异性滤波器对指定的聚焦深度层进行渲染,模糊其他深度层中的非必要元素,然后通过超分辨率重建生成重聚焦后的图像。第二步,首先对重建的结果进行超像素处理,然后以超像素为节点建立图模型,通过结合了全局和局部平滑度约束的传播模型得到显著性粗图。最后,利用目标图进行细化,得到最终显著性检测的结果。

图 1 结合相机阵列选择性光场重聚焦的显著性检测算法的框架图Fig. 1 Framework diagram of the saliency detection algorithm combined with selective light field refocusing of camera array
2.1 结合bokeh渲染和超分辨进行重聚焦
将bokeh渲染和超分辨率重建集成到一个方案中,可在提高bokeh渲染性能的同时提高重聚焦后图像的分辨率[21]。首先采用RGDP (Reliability Guided Disparity Propagation)算法[22]对视点图像进行视差估计,用以指导bokeh渲染。考虑到在实际图像采集过程中,存在传感器排列密度受限,光学畸变,景物与采集设备之间存在相对位移等诸多降质因素,建立摄像机阵列的退化模型:
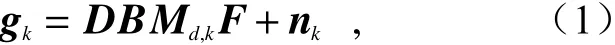
其中,gk表示第k个相机捕获的视点图像,F表示高分辨率图像,nk表示空间域附加噪声,D、B和Md,k分别表示下采样、光学模糊和位移(取决于深度d和视点k)。超分辨率重建的主要任务就是估计F以适应退化模型,求解以下方程:

其中,第一项为对观测到的低分辨率图像与理想高分辨率图像的一致性度量, ωb是基于深度和空间变化的权重向量,⊙代表哈达玛乘积(Hadamard product),也称逐元素乘积,Jb(F)为bokeh正则化项,JBTV(F)为 双边总变异BTV正则化项[23],λb和 λBTV为正则化系数,Jb(F)可以表示为:

其中,Fb为由bokeh渲染生成的图像。采用梯度下降法逼近公式(2)的最优解,步长和迭代次数均可设置。
生成bokeh图像的过程为:利用基于深度的各向异性滤波器对中心视点图像进行渲染,通过调节其参数可实现对场景中某一深度层的聚焦,而对其他深度层产生不同程度的模糊。下面对具体过程进行解释:假设图像中的某点p没有被聚焦,其在图像中对应的混叠圆[24]半径为:

其中,lf和lp分别表示焦距深度和p点深度,f为焦距,F为透镜F数,深度l可表示为l=fb/d,其中b为基线长度,d为视差。那么公式(4)可表示为:

在bokeh渲染过程中,f,F,b和df是固定不变的,那么p点对应的混叠圆半径与p点和焦点之间的绝对视差成正比。K=f/2F(b−df)表示整体的模糊程度,同时反映场景深度,K越大表示模糊程度越强,景深越小。
假设q点周围存在多个以pi为中心的混叠圆,由于混叠圆中强度是均匀分布的,计算pi对q的贡献可 通 过Ipiq=Ipi/πr2pi,rpiq≤rpi表 示,其中Ipi为pi点渲染前的强度,rpi为 以pi为中心的混叠圆的半径,rpiq为pi与q之间的距离。那么q点强度可表示为:

其中,Sq={pi|rpiq≤rmax}表 示q点周围点的集合,rmax是图像中混叠圆半径的最大值。由于Sq中的某些点可能对q点没有作用,所以将权重λpi定义为:

各向异性滤波器基于公式(6)和公式(7),采用双三次插值渲染中心视点图像生成Fb。
另外还需要对公式(2)和公式(3)中的 ωb进行计算, ωb是基于深度和空间变化的权重向量,未聚焦的区域应具有较大的权重。一幅图像的模糊程度由混叠圆半径决定,通过γp=(rp−rmin)/(rmax−rmin)将 半径归一化至[0, 1],rmin为图像中混叠圆半径的最小值。使用sigmoid函数将 γp转化为ωp,ωp=1/{1+exp[−α(γp−β)]}, 其中 α为衰减因子,β为阈值。遍历所有像素点,得到权值向量ωb。
2.2 通过基于图的显著性检测生成显著图
上述步骤中通过设置参数能够对场景中某一深度层进行聚焦,而对其他部分产生不同程度的模糊,在此基础上进行如下基于图的显著性检测。首先,对重聚焦后的图像进行超像素处理,采用SLIC (Simple Linear Iterative Clustering)算法[25]将图像分割为n个超像素,该算法计算速度快,能生成紧凑且近似均匀的超像素。然后,构建图结构G=(V,E), 其 中V={v1,···,vn}为 超 像 素 点 集,E为边集,E=E1∪E2∪E3∪E4由V中任意两节点之间通过边权值矩阵W=[wij]n×n量化的连接构成。通过以下4条规则对其进行定义:


接着分两个阶段生成并细化显著图,第一阶段采用结合全局和局部平滑度约束的传播模型进行标签传播,计算一个关于表示向量y=[y1,···,yn]T的排序向量。 表示向量y定义为:如果vi是 种子节 点,则yi=1, 否则yi=0。排序向 量f用以表示节点与背景种子节点的相关性,可通过求解下式获得排序向量f:


其中, λ1=1/(1+µ1), λ2=µ2/(1+µ1)。分别将上、下、左、右4个边界所含超像素节点作为种子,得到排序向量,分别归一化后计算其互补值得到前景目标相关性,然后将对应元素相乘生成显著性粗图

在显著性区域与背景具有明显对比度的情况下,Mc会是良好的显著性检测结果,但是通过背景查询并不能表示全部的显著性目标信息,特别是对于显著性目标具有复杂结构或与背景相似的情况,结果受背景噪声影响较大。第二阶段,对上一阶段得到的显著性粗图进行细化。首先,采用边界盒[27]生成包含目标区域、排除背景区域的目标图

其中,Aj为 边界框 Ωj的 分数,δ为指示函数,表示节点vi是 否在边框内,L用于对要检测的边界盒生成的边框数量进行限制。结合Mc和Mo细化模型,细化结果f∗计算公式如下:


式(14)中,第一项仍为平滑约束,用以保证显著性值连续,第二项为标签适应度约束,用以保证细化的结果与粗图Mc相差不大,第三项是通过Mo构建的正则化约束,抑制不属于目标的背景区域,增强可能属于目标的区域。令式(14)导数为0得最优解

3 实 验
3.1 参数设置
在4D光场数据集[28]上进行实验,该数据集对于每个场景提供9×9×512×512×3光场。选择每个场景3×3的子视点图像序列作为输入,输出对该场景进行显著性检测的显著图。另外,实验对数据集中每一场景都进行了人为的显著性标注,使每一场景都带有显著性检测的真值图,用于对检测结果进行定量分析。算法中的参数设置如下:重聚焦过程中,两项正则化系数分别设为λb=5, λBTV=0.2;bokeh渲染过程中,衰减因子α=15; 阈值 β=0.3;bokeh强度K= 3(可根据对模糊程度及景深的需要进行调节);显著性检测过程中,每个超像素包含的像素数量设置为600;控制约束 σ2=0.1; λ1=0.99; λ2=0.5;要检测的边框数量L=104。
3.2 重聚焦结果
实验中,将场景深度量化为30个层次,通过设置索引i指定要聚焦的深度层,生成在该深度层聚焦,其他深度层散焦的重聚焦图像,如图2所示。图2(a)为场景Herbs的中心视点图像;图2(b)为聚焦于第29个深度层的重聚焦图像,图中场景最前侧花盆得以清晰显示;图2(c)为聚焦于第19个深度层的重聚焦图像,场景较前侧花盆得以清晰显示;图2(d)为聚焦于第9个深度层的重聚焦图像,图中场景较后侧花盆得以清晰显示;图2(e)为聚焦于第2个深度层的重聚焦图像,图中场景最后侧花盆得以清晰显示。实验结果表明,对于输入的多幅视点图像,通过选择对场景的某一深度层进行重聚焦,能够使位于该深度层上的物体清晰显示,对位于其他深度层上的物体产生不同程度的模糊。实验中将中心视点图像作为真值图,使用PSNR定量评估聚焦区域(方框框出)的清晰度。

图 2 聚焦于场景不同深度层上的重聚焦结果Fig. 2 Refocusing results focusing on different depth layers of the scene
3.3 显著性检测结果
将本文方法所得的最终检测结果与4种不同类型的显著性检测算法以及1种最新的基于深度学习的显著性目标检测算法进行了比较,如图3(彩图见期刊电子版)所示。其中文献[19]、文献[18]为基于图的显著性检测方法,文献[9]为综合自底向上和自顶向下两种机制的显著目标检测方法,文献[13]为上下文感知的显著性检测方法。由图3可知,本文方法显著性检测的结果最为完整、细致,图中对用红色和蓝色方框标注出的部分细节进行放大展示以做视觉对比。对于第一行所展示的包含多个显著性目标的场景Table,本文方法能检测出更多的显著性目标,例如,左侧的盆栽、笔筒、前方的台灯等,另外本文方法得到的显著图中主要显著性目标也更为细致,例如,收纳盒和打开的书。对于第二行所展示的显著性区域与背景对比度不大的场景Boxes,本文方法检测出的显著性目标最为精细,例如,收纳箱的右上边缘和收纳袋。

图 3 5种算法对场景Table和Boxes进行显著性检测所得结果比较Fig. 3 Comparison of the saliency detection results obtained by five algorithms for the scene Table and Boxes
采用平均绝对值误差(Mean Absolute Error,MAE)来评价检测出的显著图与人工标注的真值图之间的差异,由下面的公式进行计算:
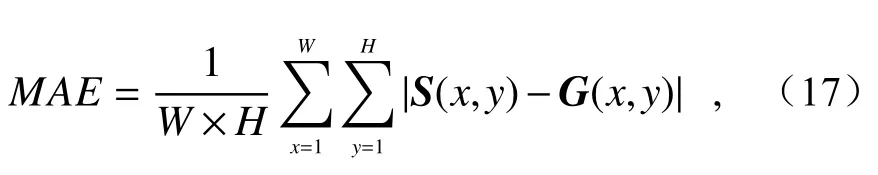
其中,W和H分别代表图像的宽度和高度,S为显著图,G为真值图,MAE越小说明检测结果与真值图之间的差异越小,算法的性能越好。针对Table和Boxes这两种特殊场景,本文提出算法的MAE值均小于其他4种算法,检测结果能体现出更丰富的显著性目标信息。对整个数据集中的全部场景进行显著性检测,计算MAE值,见表1。结果表明本文算法较其他4种算法,平均MAE值均有所降低,所得显著图与真值图之间的差距有所缩小,检测结果更为精细。

表1 5种算法的平均MAE值Tab. 1 Average MAE values of 5 different kinds of algorithms
对本文算法所得显著性检测结果进行阈值处理,用二值化的结果与文献[10]中提出的基于深度学习的显著性目标检测算法所得结果进行比较,如图4所示。可以看出虽然对于包含多个显著性目标的复杂场景,本文结果也存在部分显著性目标丢失的不足,但是所包含的显著性目标的信息更多,对细节处理得更好,与真值图之间的差异更小,且无需预先通过大量数据来训练网络,也无需在测试时下载预训练模型。故与基于深度学习的显著性目标检测算法相比,本文方法更简单、有效。

图 4 本文算法所得结果与最新的基于深度学习的显著性目标检测算法所得结果的比较Fig. 4 The comparison between the results of our algorithm and the latest salient object detection algorithm based on deep learning
另外,由于本文方法结合了光场重聚焦,可通过选择聚焦于不同的深度层,将该深度层上的显著性目标更精确、细致地检出。图5展示的是聚焦于场景两个不同深度层(索引i分别设置为29和9)所得显著图。第一行从左至右分别为中心视点图像、聚焦到果盘所在深度层后所得的显著图以及聚焦到较后侧花盆所在深度层后所得的显著图;第二行将两幅显著图中果盘部分进行放大展示。可以看出,当设置聚焦于果盘所在深度层(i= 29)时,场景中前侧的果盘能够被更精细的检测出;当设置聚焦于场景较后侧花盆所在深度层(i= 9)时,后侧花盆能够被更精细地检测出,一定程度上实现了可选择的显著性检测。

图 5 聚焦于场景不同深度层所得显著图比较Fig. 5 Comparison of saliency maps obtained by focusing on different depth layers of the scene
4 结 论
本文提出了一种结合相机阵列选择性光场重聚焦的显著性检测方法。通过同一场景的多幅视点图像,结合场景的深度、聚焦等信息,利用基于图的显著性检测方法,提出结合全局和局部平滑度约束的传播模型来防止错误标签传播,得到的显著性粗图经过目标图的细化最终输出精细的结果图。此外,通过参数设置对场景的某一深度层进行重聚焦,而对其他深度层产生不同程度的模糊,使得对包含多个显著目标的场景中位于该深度层的显著目标得以更精确、细致地被检测出,一定程度上实现了可选择的显著性检测。在4D光场数据集上进行的实验表明本文所提出的算法效果良好,所得的显著图与人为标注的真值图之间的平均绝对误差的均值为0.2128,较其他方法有所降低,检测出的显著图最为精细,改善了现有显著性检测方法针对包含多个显著目标以及显著目标的某些区域与背景区域对比不明显的场景所得的显著图不够精细,甚至会丢失某些显著性区域的不足。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
电子制作(2019年24期)2019-02-23
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
西南交通大学学报(2018年5期)2018-11-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
苏州科技大学学报(自然科学版)(2017年1期)2017-03-20
知识产权(2016年8期)2016-12-01
河南电力(2016年5期)2016-02-06
新闻前哨(2015年2期)2015-03-11
