
内核网络堆栈的Go 语言实现与分析
2021-07-11 08:16柴艳娜
电子设计工程 2021年13期
柴艳娜
(长安大学信息与网络管理处,陕西西安 710064)
计算机是现代日常生活的一种必需品,其高效可靠的运行需要依赖于一套稳健无缺陷(Bug-free)的操作系统。现代操作系统都会使用内核(Kernel)来对硬件进行管理,因此,可以说内核的安全稳定决定了人们与计算机相处的体验。内核中的缺陷(Bug)将可能使用户的应用程序甚至操作系统本身变得不可靠[1]。
大多数成熟的操作系统内核都是用C 语言实现的,C 语言因其允许高度自由控制内存使用等诸多低级程序操作特性,从而成为最受欢迎的的内核开发语言[2]。这种高度的自由也会带来一些代价,比如内存释放两遍的错误、数组越界的错误以及死锁[3]。同时它也不能防止数据类型的错误解析,保证不了类型的安全性。C 语言也无法方便高效地使用现代多核处理器的全部性能。
如果用Go 等高级语言来开发内核,则可能规避掉很多上述问题。为此,该文用Go 语言实现了内核网络堆栈子系统,进行了可行性研究,并设计实验进行验证。
1 Linux系统网络堆栈
Linux 的网络堆栈(Network Stack)是其内核的一个子模块,如果在源代码基础上从零开始编译Linux内核,可以通过menuconfig 对该模块进行选择和修改配置。位于Linux/net 目录的源代码是Linux 官方自带的默认网络堆栈实现[4]。
Linux 网络堆栈模型如图1 所示。

图1 Linux网络堆栈
网络堆栈共分为6 层,每一层都分别执行不同的处理任务,对于流入、流出数据都会进行处理。最顶层的应用层是操作系统用户空间(User Space)的一部分,用户常驻使用的应用程序如浏览器、IM 软件等便工作在这一层。
中间4 层是内核空间(Kernel Space),以内核模块(Module)形式工作,最底层则是物理层,处理真实的物理媒介数据传送和接收的真实物理设备,如网卡、交换机及路由器等。
Socket 接口层是创建Socket 以及提供API 接口给应用层进行调用的地方,也叫系统调用接口(System Call Interface)[3]。
协议层则实现各种网络协议的解析,是数据正确发送与接收的核心。
网络设备驱动接口及驱动层,则是提供了操作实际物理设备的手段,同时也提供了相应的监控和调优手段,方便调整实际物理设备的工作状态和性能。
完整地实现一个操作系统内核是一项工作量巨大的工程,得益于Linux内核的良好分层模型,替换某些模块便可进行研究和对比,因此,该文代之以实现一个内核子系统,即网络堆栈,从而方便下一步的研究工作。
该文用Go 语言实现一个Linux 内核网络堆栈,用于演示用高级语言开发内核的相对优势。之所以选择Go 是因为语言本身自带优秀的CSP 并发模型(Concurrent Sequential Processes)[5-6]。CSP 模型将 复杂任务解构成更小的、更加可管理的子任务。这些子任务都能被单个进程所处理,进程之间彼此保持通信,共同完成原始的复杂任务。
CSP 模型的目标是帮助程序员设计、实现和验证复杂的计算机系统,十分重要,特别是要设计一个如内核般复杂的软件。Go 提供了线程安全(Thread-safe)方式的CSP 模型,Go 语言的线程即协程(Goroutines),同步的通信构造即通道(Channel)[7]。Go 语言运行时自动根据计算机的物理内核数量来管理调度协程。CSP 模型能让人很容易地使用计算机的所有内核,同时改善代码的可读性,进行更简单的调试和减少产生缺陷。网络堆栈很自然地可以被划分成多个子任务去运行,可以充分利用Go 协程去动态调度,高效利用所有可用物理内核[8]。
CSP 模型只在垃圾回收语言里有可行性,Go 提供了必要的垃圾回收。Go 是一门强类型语言,能减少一大类错误,包括错误类型转换,内存释放两遍,对象释放后再使用等。Go的延迟声明(Defer Statement)允许在函数结束时更方便地清理,减少那些疏于管理的资源导致死锁的可能性。
2 实 现
文中实现的独立网络堆栈(下文以项目代号NStack 称呼之)是建立在Tap 虚拟网卡基础上,所有基础网络协议,包括以太网(Ethernet)、ARP、IPv4、ICMP、UDP 和TCP,都能被实现。为确保性能不受影响,延迟(Latency)和吞吐量(Through-out)会被测试,并与C 语言实现的网络堆栈Tapip 进行比较。
2.1 Tap接口
Tap 接口即一种虚拟网络接口(虚拟网卡),它用软件来模仿实际硬件。NStack 会将Tap 接口当作正常物理接口一样读写[9]。Tap 接口会关联一桥接接口,就好像一个路由器作为主机的一个子网接入其中,这样可以允许NStack 能使用它自己的MAC 地址和IP 地址,连接到外部网络。
2.2 协议实现
NStack 会实现数据链路层、网络层和传输层的协议,每一层独立运行自己的协议,如图2 所示。分层模型可以增加并行,在高负载下提供高效服务[10]。

图2 分层协议栈
每一个协议的实现都使用了类似结构的包处理器(Packet Dealer)。IP 包处理器如图3 所示。包处理器从低层级读取数据包,并通过通道传输。通道以箭头表示在图2、3中。IP包处理器将数据包发给不同的IP Reader 协程,如图3 所示,IP Reader 处理完接收到的数据包后,将处理结果转发给下一层的包处理器。

图3 IPv4包处理器
2.3 性能测试
NStack会与Tapip进行性能比较。Tapip是一个C语言开发的多线程网络堆栈。这个比较允许评估用高级语言开发网络堆栈的优点和缺点。两个网络堆栈都实现了相似的协议,都在用户空间(User Space)操作,都使用Tap 虚拟接口。测试机器是Ubuntu 14.04/Linux 3.13.0,16 GB 内存,Intel Xeon Quad Core Dual Socket 处理器。
2.3.1 延 迟
为测试延迟,将取50 次ping 响应时间的平均值作比较。测试环境的一台Linux 虚拟机将运行两个网络堆栈,ping 请求从该虚拟机发出。为判断堆栈在负载增加情况下的性能,多个ping 会被同时并发发送。从1 个增加到1 000 个并发ping“连接”来模拟网络堆栈可能接受的负载。为保证对两个网络堆栈公平,其他的变量都将保持不变,包括每个ping“连接”发送的ping 请求数,ICMP 接受缓冲区大小以及ping请求数据包大小。
2.3.2 吞吐量
第二个将要评估的性能指标便是吞吐量。一个堆栈的吞吐量是在给定时间内,它能发送或接收的数据量大小[11]。以下步骤将用来测量两个堆栈的吞吐量:
1)初始化一个TCP 服务端。
2)初始化一个TCP 客户端,连接会在local 网络(localhost)中建立,以排除Tap虚拟网卡导致的开销。
3)客户端发送4 kB 数据给服务端。
4)计算堆栈完成上述过程的总时间,该时间和发送的数据量将用来计算吞吐量。
为测量堆栈的相对扩展能力,将会逐步增加客户端数来测量性能[12],最大测试到100个并发客户端。
有许多预防措施将用于保证吞吐量的准确测量,比如所有可比较的缓冲区大小都一致[13]。在Tapip 中,每个客户端和服务端连接都运行在各自的线程里,NStack 类似,但是用的是Go 的协程而不是线程。另外,也会确保所有连接完成且连接的负载被完整传输之后再停止运行网络堆栈[14-15]。
3 结果分析
NStack 的代码与Tapip 比较类似,但是从结果来看,性能上包括延迟和吞吐量,相比之下NStack 出色得多。
3.1 准确性
NStack 和Tapip 都能准确地运行协议,这可以通过分别测试两个协议栈与一台Linux 终端的连接来进行判断[16-18]。测试中发现Tapip 有内存泄漏的情况。这是因为Tapip 会开辟缓存区存储数据包,在某些情况下这些缓存区不会被释放或者重复释放。当缓存区被重复释放时,Tapip 会奔溃或者导致异常行为。当缓存区不会被释放时,Tapip 会不断侵占内存,直至系统奔溃。Go 则由于有内置的垃圾回收,可以很好地避免这种情况的发生。
3.2 代码比较
虽然很难量化地评估编写Go 语言相比较C 语言的优点,但是一些代码片段的比较还是可以看出高级语言的某些优势。以下以IP 报文分片重组的处理代码举例说明。
当添加分片到重组队列时,Tapip 的C 语言代码如下:

Go 可以用协程处理IP 报文分片,因此它可以简单的将分片转发给对应的协程处理,同时可以紧接着处理后续数据包。
在清理分片时,C 语言的Tapip 需要显性地释放每一个内存缓存区,代码如下:

而Go 语言只需跟踪通道即可:
delete(ipr.fragBuf,bufID)
Go 语言的简洁、友好、可读,由此可见一斑。
3.3 延迟测试结果
延迟测试结果如图4 所示。1 个ping 请求时,Tapip 的延迟为0.074 ms,优于NStack 的0.234 ms,但是随着并发请求的增加,当1 000 个ping 请求时,NStack的延迟为0.717 ms,差不多比Tapip的3.279 ms高4 倍。NStack 在连接数为600 时,开始领先于Tapip。NStack 延迟的增加是线性的,而Tapip 是指数型的。NStack 的延迟趋势是优于Tapip 的,因为在请求数很少时,两者之间延迟的差距很小,但是在大量并发ping 时,差异就明显变大。

图4 延迟测试结果
3.4 吞吐量测试结果
吞吐量测试结果如图5 所示。1 个并发连接时,NStack的吞吐量达到7.3 Mbit/s,对比Tapip的4.6 Mbit/s。当100 个并发连接时,NStack 达到了284.9 Mbit/s,而Tapip 则只有195 Mbit/s。并且,NStack 的吞吐量增加速度比Tapip 快得多。这表明NStack 可以继续在更大量的并发情况下扩展吞吐量,而Tapip 则很可能处理不了这种负载。
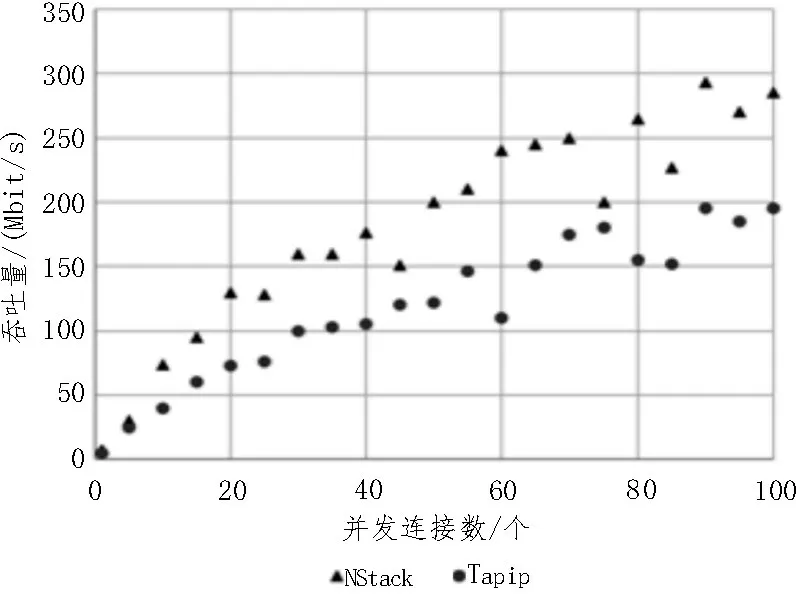
图5 吞吐量测试结果
4 结束语
由该实验可以得出,用Go 开发内核子系统可以改善代码的可读性和可靠性,结构模块清晰,具有良好的并发能力和稳定性,同时又对性能没有重大不良影响。结果表明,对于内核开发来说,Go 语言可以是一个重要的C 语言替代者。
猜你喜欢
计算机工程与科学(2022年11期)2022-11-17
今日农业(2021年9期)2021-07-28
成都信息工程大学学报(2018年4期)2019-01-23
信息安全研究(2018年12期)2018-12-29
军事运筹与系统工程(2017年1期)2017-07-31
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
新农业(2016年23期)2016-08-16
集装箱化(2014年2期)2014-03-15
