
基于NLP和深度学习方法的英文情感分析方法研究
2021-07-11 08:16薛雨
电子设计工程 2021年13期
薛雨
(商洛学院人文学院,陕西商洛 726000)
随着互联网的普及与发展,文化、购物、社交等信息平台产生了大量的文本资源,这些资源大多由用户自主上传,其形式多样、结构复杂。在这些文本信息中蕴含着丰富的数据价值,是描绘用户画像的直接资料[1-4]。例如,从文化信息数据库中分析文本信息,可以辅助调查社会关系网络和文化发展倾向;从购物网站中爬取用户对于某件商品的评论信息,可以辅助商家更准确地获得用户对该商品的印象,为商家与平台的营销策略提供直接支持。在这些需求下,要求计算机通过智能数据处理算法准确地理解文本信息所蕴含的情感倾向,以处理海量大数据并提取特征数据,即文本情感分析,是自然语言处理领域中研究的重要课题之一[5-9]。文中通过将文本片段化,识别出给定文本中所表达的情感倾向及强度。英语是世界通用语言,对于英文情感分析的研究具有更广阔的应用前景。在情感分析时,按照分析对象的不同,可以分为词、句、篇不同的级别,不同级别的文本分析粒度不同。文中为了提升英文情感分析方法的实用价值,以英文语句为单位进行情感分析研究。
1 理论基础
1.1 自然语言处理
自然语言处理(NLP)是一项研究人与机器间使用自然语言进行信息交互的技术理论和方法,是一项融合计算机、语言学、数学等各个学科的智能方法。不论自然语言处理的目的如何,均要将文本信息转化为词向量作为模型的输入,并进行模型的训练。
经典的词向量训练有两种方式:一种是基于语言模型的框架;另一种是基于主题的模型。第一种方法由于得到的词向量信息中包含语义信息,更适合情感分析的研究[10]。
语言模型可以描述确定文本序列下每个词序列的出现概率,即对于T长度的字符串向量s为:

P(⋅)是一个概率模型,将字符串序列中的第j个词表示为wj。通过模型训练,输出式(1)中的条件概率。但在词训练的过程中,模型参数会随着次数的增多而增长;词向量的表述也会随着向量维度的增长而趋向于稀疏。因此,文中引入了神经网络进行训练,即使用Word2vec 框架。
在文档D中,对于当前词wij,其上下文Ci以最大后验概率为目标函数:

式(2)中,将D中的第j个句子标记为Tj。为了计算条件概率p(wij|Cij;θ),需要进行词汇的映射。然后,使用层次Softmax 网络,进行条件概率的最大化。过程如图1 所示[11-16]。

图1 层次Softmax结构示意图
层次Sotfmax 结构与一般的神经网络结构类似,包含输入层、隐藏层与输出层。
1)输入层
在输入层中,使用词向量矩阵M记录当前词在上下文中的2h个词向量作为模型的输入,即:
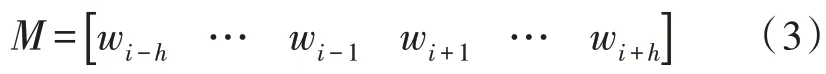
2)隐藏层
隐藏层用于输入层各个向量的累加,由节点wneu1完成汇聚。
3)输出层
层次型Softmax结构与传统神经网络的最大区别在于输出层,其输出层由二叉树构成。每一个二叉树的叶子节点均对应一个词向量w,wneu1与二叉树中的所有非叶节点连接,非叶子节点对应一个非词向量q。对于当前词向量,其条件概率可以表示为:

在训练二叉树时,使用了最小负对数似然函数。在误差反向传播的过程中,根据随机梯度下降的原则进行参数更新。
此时,词向量与非词向量的更新方法如下:

其中,η是模型的学习率,η决定了参数在梯度下降过程中参数变化的快慢。
1.2 基于负抽样的模型优化
在分层Softmax 中,为了节省训练二叉树时的计算资源,可以引入负抽样方法。负抽样前,需要定义模型中的正样本与负样本。文中将wij作为正样本,将wij替换上下文后的词作为负样本。此时,目标函数可以简化为:

此时,根据梯度下降原则:

其中,label用于区分正负样本。当样本是正样本时,lable=1;当样本是负样本时,lable=0。此时梯度为:

同时在引入负抽样后,文本内所有的词向量可以划分为上下文词、中心词两类。参数更新时,对上下文词更新,中心词保留在邻接矩阵Rw内,此时的更新方法如下:

1.3 情感相关词嵌入
上述模型可以进行词向量的抽取,但直接抽取的词向量仅包含少量的情感信息。通过向基础语言模型内嵌入与情感相关的词目,可以实现文本的情感分析。此时,损失函数的形式如下:

其中,正常的词序列被标记为t,替换后的词序列为tr。
在该模型中,需要在原有模型的基础上再增加一个Softmax 层,该层专门用于情感信息的提取。在模型的输入层,以n-gram作为输入。此时,式(13)可以写成:

2 方法实现
文中对自然语言处理的词向量提取方法结合情感分析的文本分析模型进行了介绍,接下来文中将结合具体的语料对上述模型进行仿真。
2.1 实验设计
英文情感分析的实现,最重要的是完成基于英文语料的模型训练[17],然后通过测试数据集进行测试。流程如图2 所示。

图2 情感分析方法流程
为了更优地发挥模型的性能,需要合理选择情感分析时使用的语料资源。文中使用的语料资源为SemEval2013,这是学术界认可度极高的国际语义测评竞赛提供的官方语料。其具体的组成包括训练集、开发集与测试集,每个集合由包含肯定、中性和否定的3 种情感倾向组成。情感分析语料参数如表1 所示。

表1 情感分析语料参数
在语料的预处理中,需要根据算法需实现的目的对文本信息进行分词,标注词条的属性以及对于英文中常用的停用词进行过滤。
文中在进行分词与词性标注时,使用中科院发布的ICTCLAS 分词标注辅助系统作为依据。
在进行模型性能评价时,文中使用的指标包括两类,一类是机器学习算法常用的指标:准确度Accuracy、F1,其定义如下:

其中,f(x)是模型的预测值,y(x)是模型的真实值,|X|为当前数据集的输入值。P、R分别为模型的准确率与召回率:

另一类是与文本分析情感强度相关的肯德尔等级系数t,其定义形式如下:

2.2 仿真结果
在进行算法的仿真时,为了提升算法在英文情感分析时的精度,文中使用深度学习中的卷积神经网络替代分层Softmax 中的二叉树。根据卷积神经网络的结构需要,确定使用卷积窗口的大小。为了简化模型,文中在不同的卷积层使用长度相同的卷积核。表2 给出了模型的性能指标随卷积核大小的变化情况。

表2 模型指标随卷积核大小的变化
图3(a)给出了模型Accuracy 与模型F1 的指标随着卷积核增加的变化情况,图3(b)给出了模型的训练时间随着卷积核增加的变化情况。可以看出,模型的精度和F1 值在卷积核小于或等于100 时,随着卷积核的增长线性提升,当卷积核大于100 后,这两个指标不再有所改善;此时,观察模型训练时间曲线可以看出,模型在卷积核大于100 后,急剧增加。综上所述,文中在模型训练时选取的卷积核大小为100。最终确定的模型参数如表3 所示。
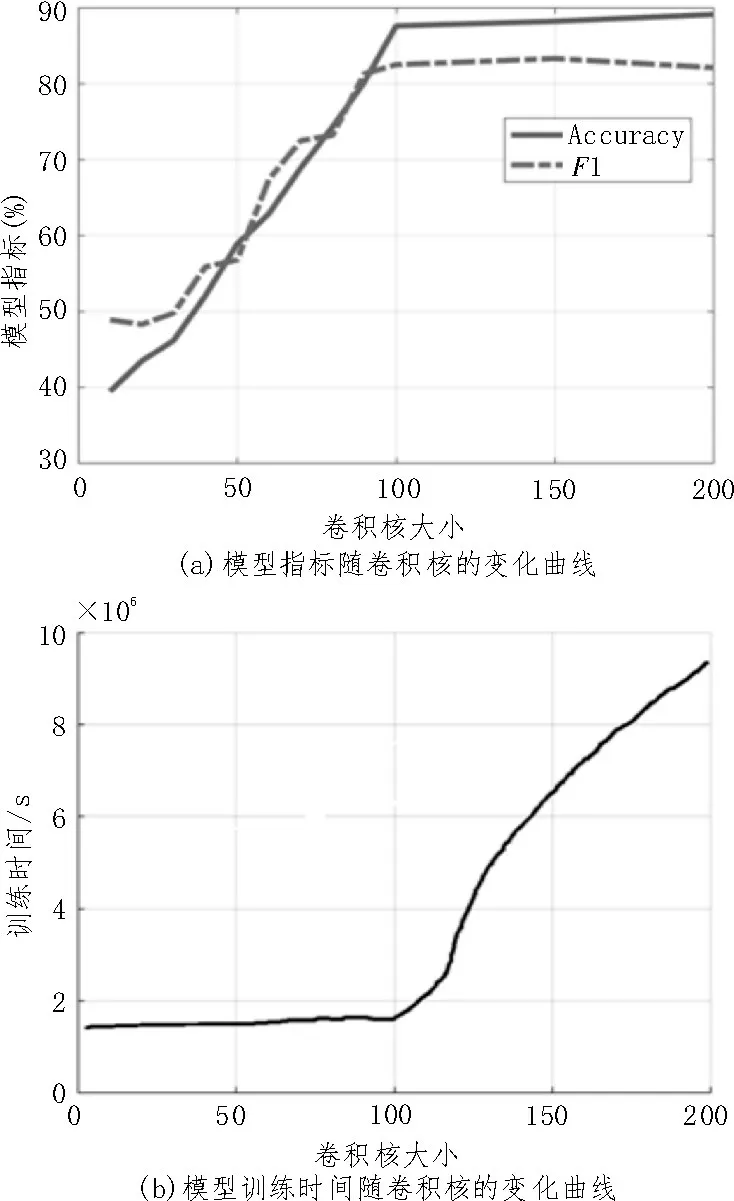
图3 卷积核大小与模型参数的关系

表3 模型参数设置
模型训练完成后,将测试集输入到模型中,测试数据经模型运算输出3 个不同类别的情感预测值。通过与数据集的标记进行比对,获得测试结果。具体的测试结果如表4 所示。此外,为了评估模型的性能,文中采用基于二叉树的分层次Softmax 模型,其结果如表4 所示。

表4 测试结果对比
从测试结果可知,在进行英文文本的情感分析时,对于表示否定的文本,两个模型均有较优的识别精度。对于中性的文本,识别精度较差;从模型的整体性能来看,文中提出的CNN-Softmax 模型由于引入更深层次的卷积结构,在模型的性能上有大幅度提升。Accuracy 与F1 分别达到了84.3%和82.3%,相较于传统的基于二叉树的模型有约5%的提升。
3 结束语
文本情感分析是自然语言处理领域研究的热点之一,文中对词向量模型的提取和基于深度卷积神经网络的文本情感分析方法进行了研究[18]。对于词向量提取的框架、文中建模方法与情感分析的流程进行了深入的介绍。其在开放的语料集上进行情感分析实验,仿真结果证明了文中方法的优越性。传统基于二叉树Softmax 模型的改造对于英文文本的情感分析,具有较强的实用价值。
猜你喜欢
电脑报(2022年37期)2022-09-28
北京航空航天大学学报(2021年9期)2021-11-02
现代计算机(2021年14期)2021-07-09
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
海外华文教育(2016年1期)2017-01-20
武汉轻工大学学报(2016年4期)2017-01-16
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
