
长记忆时间序列均值多变点的ANOVA型检验
2021-07-12 08:03赵文芝
西安工程大学学报 2021年3期
刘 豆,赵文芝
(西安工程大学 理学院,陕西 西安 710048)
0 引 言
变点问题是统计学研究热点问题之一。变点指在某一时刻前后观测值存在明显的差异,遵循2种不同的模型,即前后2个子序列可以由2种不同的数学模型呈现,反映了观测值本身发生了某种机制的转变。1954年PAGE[1]发表的一篇质量检验的文章提出了变点问题,该问题提出之后即被人们广泛关注,现在变点问题已被大量应用于经济金融等领域。
通常均值变点检验的方法有最小二乘检验、CUSUM检验、比率检验、贝叶斯检验、似然比检验等。HORVTH和KOKOSZKA等用CUSUM估计量估计均值变点,并给出极限分布[2-3]。但是,CUSUM方法的缺点之一是需要估计长期方差,在应用中非常不方便。由于长期方差不易准确估计,一旦估计结果较差,会使检验方法出现第一类错误的概率难以控制。HIDALAGO等用Wald法[4],KUAN等用最小二乘方法[5]检验均值变点;SHAO和赵文芝等采用比率统计量研究了均值变点检验问题[6-7]。然而,以上文献只研究了均值单变点检验情况。
在实际的统计检验中,所选数据不一定只有一个变点,因此多变点检验问题的研究具有重要意义。BAI等研究了线性模型多变点的估计及其检验问题[8-11]。他们放宽了现有的限制性假设条件,提出了Sup-Wald型检验并讨论多变点估计的序贯估计方法,为研究多变点问题提供了一种新的思路。此外,BARDET等采用拟似然比的方法得到一般因果参数模型多变点的一致估计[12];KEJRIWAL等用Wald法检验持久性多变点问题[13];夏志明等提出基于局部比较法研究多变点个数及其位置的估计[14];文献[15-18]研究线性多变点模型并且应用到实际数据中进行变点检测;NORIAH等提出了用ANOVA统计量研究独立同分布序列的均值多变点检验[19];吕会琴等在厚尾相依序列下研究了均值多变点的ANOVA型检验[20]。以上文献都是采用不同方法研究短记忆序列多变点问题。然而,在气温、水文以及地质等领域会出现长记忆序列。由于受各种因素的干扰,长记忆序列也有可能存在均值多变点。在上述研究的基础上,付国龙用滑动比法检验长记忆均值多变点[21];徐琼瑶等提出似然比扫描法研究长记忆均值多变点检验[22]。对于长记忆序列均值多变点检验的文献并不多,仍然有许多问题值得讨论。本文采用ANOVA型统计量研究长记忆序列的均值多变点检验,将文献[19]的研究方法推广到长记忆序列上,考虑长记忆序列均值多变点检验。
1 长记忆模型及统计量的极限分布
假设n个观测值X1,X2,…,Xn是由式(1)给出:
(1)
式中:μ1,μ2,…,μk+1为常数,n为样本容量;

考虑假设检验问题H0:μ1=μ2=…=μk+1; H1:μ1≠μ2≠…≠μk+1。
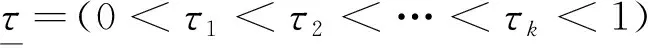
di,n=[nτi]-[nτi-1],i=1,2,…,k+1

文献[23]提出了分数布朗运动过程Bd,表达式为
其中B0是标准布朗运动。这里的Bd具有高斯性,均值为零,协方差函数S为
|t-s|1+2d+|s|1+2d)·

其中0≤t≤1,n→∞。
定义ANOVA型检验统计量
(2)
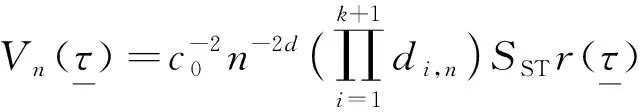
定理1假设X1,X2,…,Xn是长记忆序列且满足式(1),则在原假设H0成立的条件下,当n→∞时,有
(3)
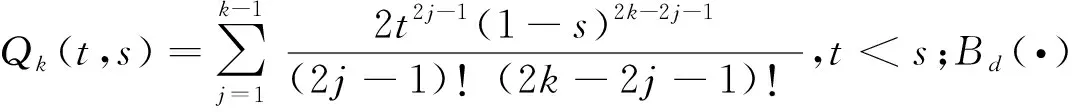

(4)
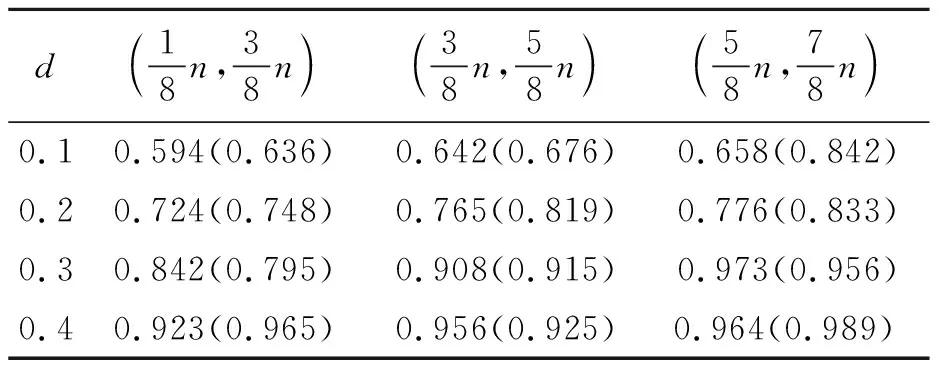
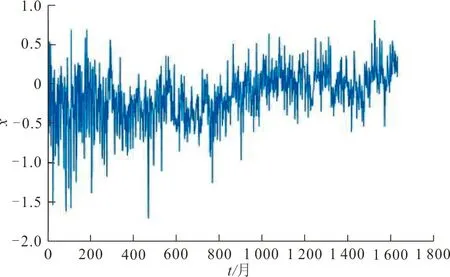
假设{(et}是一个0 其中0≤t≤1,c>0,n→∞。可得 从而,基于式(4)可以证明,在原假设H0成立时,当n→∞,有下式成立: (5) 根据式(2),对式(5)不断积分可以得到式(3)。 成立。 由于 且 考虑如下数据生成过程 Xt=μ(t)+et,t=1,2,…,n 其中{et,t=1,2,…,n}为FARIMA(0,d,0)过程。 首先通过Monte Carlo方法对变点个数k=2,长记忆参数d分别为0.1、0.2、0.3、0.4进行数值模拟。对每一个d都会分别产生一个FARIMA(0,d,0)序列,重复进行5 000次,将得到的5 000个样本按从小到大的顺序排列。选取在经验水平α=0.05下检验统计量Tn(k)极限分布的分位数,结果见表1。 表 1 检验统计量极限分布的α分位数Tab.1 The α quantile of limit distributionof the test statistic 从表1可以看出,在检验水平α=0.05下,长记忆参数d对检验统计量极限分布的α分位数的值有同向影响,即长记忆参数d越大,检验统计量极限分布α分位数的值就越大。 分别取样本容量n=200和n=400,变点位置(k1,k2)分为 等3种情况,分别代表变点发生时刻的早期、中期和晚期。在均值(μ1,μ2,μ3)=(0,1,2)的条件下,对模型在α=0.05的检验水平下模拟500次,模拟结果见表2~4。表3中括号外的数据表示样本容量n=200时的经验势函数值,括号里的数据表示样本容量n=400时的经验势函数值。 表 2 样本容量n=200,400的Tn(k)的经验水平Tab.2 The empirical size of Tn(k) withthe sample size n=200,400 观察表2可以发现,当样本容量n增加以及长记忆参数d的变化呈持续增加时,Tn(k)的经验水平明显增加,表明样本容量对Tn(k)的经验水平有很大的同向影响,说明检验水平失真较小,该检验是有效的。 表 3 样本容量n=200,400的Tn(k)的经验势Tab.3 The empirical power of Tn(k) with thesample size n=200,400 观察表3可以发现,当样本容量n增加时,Tn(k)的经验势明显增加,显示样本容量n对统计量Tn(k)的经验势有明显的同向影响,而且样本容量n越大,效果越明显。另外,当长记忆序列参数d的变化呈持续增加时,经验势函数值会越接近于1,即表明该方法具有有效性。 表 4 变点个数对检验统计量临界值的影响Tab.4 Effect of the change point number on the critical value of the test statistic 从表4可以看出,在检验水平α=0.05,不同的长记忆参数下,随着变点个数的增多,检验统计量对应的临界值越来越小。 进一步用Matlab软件拟合得出,在α=0.05,长记忆参数d(0 当k=1 时, C1(d)=121.9d2+137.7d+200.3 (6) 当k=2时, C2(d)=0.169d2+0.527 8d+0.524 6 (7) 当k=3时, C3(d)=5.155×10-4d2+9.025×10-4d+ 2.198×10-3 (8) 对于不同的长记忆参数d(0 用2组统计学中比较经典的实际数据进一步验证该方法的有效性。2组数据分别为北半球的月平均气温数据(1854—1989年)以及尼罗河年最低水位(622—1281年)。以上数据来自于文献[24]。 Beran对北半球月平均气温数据(1854—1989年)的拟合模型为d=0.37的长记忆序列[24]。对这组数据进行变点检测,将数据代入Tn(k)中可计算其临界值为tn(k)=398.447。该值大于k=1,d=0.37的临界值267.937 2。应该拒绝原假设,即该组数据存在变点。从图1可以看出,该组数据存在明显变化,即存在变点,但是变点的位置有待进一步的估计。 图 1 北半球月平均气温数据(1854—1989年)Fig.1 Monthly mean temperature data of the northern hemisphere from 1854 to 1989 Beran对尼罗河年最低水位数据(622—1281年)的拟合模型为d=0.33的长记忆序列[24]。对这组数据进行变点检测,将数据代入Tn(k)中可计算其临界值为tn(k)=5.245。该值小于k=1,d=0.33的临界值259.015 9且大于k=2,d=0.33的临界值0.717 2。应该拒绝原假设,即该组数据存在变点。从图2可以看出,该组数据存在明显变化,即存在变点,但是变点的位置仍有待进一步的估计。 图 2 尼罗河年最低水位(622—1281年)Fig.2 Yearly minimum water levels of the Nile river from 622 to 1281 利用ANOVA统计量研究关于线性长记忆均值多变点检验问题。当变点个数已知时,原假设下证明了极限分布,备则假设下得到了一致性检验。根据数值实验以及实例分析验证了所提方法的有效性。但是,对于变点具体位置的估计以及变点个数等还有待进一步的研究。


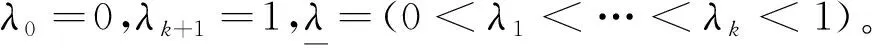


2 数值模拟



3 实例验证

4 结 语
猜你喜欢
中原商报·科教研究(2022年1期)2022-05-13中国新闻周刊(2021年24期)2021-07-19智富时代(2019年4期)2019-06-01智富时代(2019年4期)2019-06-01数学大世界(2018年35期)2018-02-22发明与创新·中学生(2017年5期)2017-05-12试题与研究·中考化学(2016年1期)2016-09-30新湘评论·下半月(2016年4期)2016-05-05新湘评论·下半月(2016年4期)2016-05-05海外文摘(2016年4期)2016-04-15
