
基于多维关联本体的学习资源推荐方法
2021-07-14 07:05李浩君吴嘉铭戴海容
浙江工业大学学报 2021年4期
李浩君,吴嘉铭,戴海容
(1.浙江工业大学 教育科学与技术学院,浙江 杭州 310023;2.浙江金融职业学院,浙江 杭州 310018)
随着移动通信技术的发展和我国“互联网+”教育应用的实施,互联网中学习资源数量激增,各式各样的学习平台也相继推出,海量的学习资源散布在各学习平台中,学习者需要访问多个学习平台才可能寻找到适合自己的学习资源。由于学习资源种类繁多以及来源广泛,学习者很难从海量信息中寻找到自己所需知识[1-2]。目前,大多数学习资源推荐方法难以解析异构数据,不能细粒度地描述情境特征、学习者特征以及资源特征,隐性知识因缺乏对特征间关系描述而难以挖掘,因而提供的学习资源与学习者需求匹配度较低,容易导致学习者产生知识迷航困扰。如何有效利用多源异构数据设计一套高效、精准的学习资源推荐方法已成为目前国内外研究热点。
为解决上述问题,首先,借助语义网本体技术构建多维关联本体模型(Multidimensional correlation ontology model, MCOM),该模型不仅能将分散的学习资源和移动终端获得的多源异构数据组织起来,而且充分利用语义关系解析学习者—情境—学习资源三元关系,实现细粒度的多维关联本体模型;其次,设计动态自均衡的二进制粒子群优化算法(Dynamic self-equilibrium binary particle swarm optimization, DSEBPSO)提高寻优计算的能力,通过动态策略更好地控制开发和探索过程,使这两个过程能动态自均衡,防止过早陷入局部最优,提高算法寻找最优资源的效率;最后,提出基于多维关联本体的学习资源推荐方法(Learning resource recommendation method based on multidimensional correlation ontology and dynamic self-equilibrium binary particle swarm optimization, MCOM-LROM),该方法通过语义推理将MCOM模型中的数据转化为DSEBPSO算法所需要的数据源,并且也将MCOM模型中学习资源本体中适合学习者的学习资源交给智能计算优化算法进行寻优计算,并将不适合的学习资源排除在智能计算服务对象外。所提出的学习资源推荐方法一方面能减少智能计算优化算法的计算量和运算时间;另一方面可充分利用语义网推理和智能算法的优势,一定程度上解决了智能计算优化算法面对多源异构数据冷启动问题。
1 问题描述和方法框架
为了解决学习资源与学习者需求特征匹配问题,研究者将学习资源推荐问题转化为离散型组合问题,通过智能算法进行求解[3-4]。粒子群算法具备参数少、易于理解特点,具有较好的搜索性能,已广泛应用于各领域的资源推荐研究。Chu等[5]建立了在线学习资源推荐模型,通过二进制粒子群算法求解与学习者特征差异最小的学习资源,为学习者提供个性化学习资源序列;刘丽珏等[6]提出了基于蚁群-粒子群混合算法的旅游路线推荐服务,解决了多目标旅游线路推荐的问题;李浩君等[7]构建了多维特征学习资源推荐模型,通过双映射二进制粒子群算法求解模型,满足了学习者在线学习的个性化学习资源需求。随着学习者对推荐质量要求的提高和学习资源数量的快速增长,研究者开始着力于构建新的方法解决大规模资源下学习资源推荐问题,Pukkhem[8]从语义网本体视角构建学习资源推荐系统,将学习者特征和学习资源特征映射到本体中进行匹配推荐,但考虑的学习者特征较少,推荐精度较低;吕刚等[9]提出用本体组织用户标签和学习资源标签,设计基于本体的资源推荐系统为用户提供学习资源推荐服务;Lü等[10]提出将学习资源关系特征用本体集成再通过遗传算法进行推荐计算。通过深入分析现有研究工作,发现目前学习资源推荐研究中还存在如下问题:1)在推荐过程中忽略了情境特征和学习资源间关联,导致服务精度低,学习者易产生知识迷航;2)多数方法不具备将学习过程各要素有机组织起来的能力,对数据利用效率较低;3)面对海量的学习资源,缺乏精确计算能力,服务响应时间长、准确度低。
1.1 问题描述
学习资源推荐本质是要满足用户个性化学习内容需求,帮助用户达成学习目标,过程中不仅要提供用户所需的学习资源,而且要能根据用户情境变化动态调整推荐资源。学习资源推荐问题受3 个维度因素影响:1)学习资源维度,学习资源的特征有很多,如承载媒介、适用的学习阶段、学习时长和资源难度等,学习资源和用户的匹配程度对学习结果有很大影响;2)情境维度,即学习过程中的情境因素,情境影响作用往往是对学习需求的求解过程优化;3)学习者维度,即推荐服务的对象因素,学习者的学习风格、学习偏好和能力水平等要素对推荐的准确性和高效性有着重要的影响。因此,基于多维关联本体的学习资源推荐方法是综合考虑用户需求、学习内容和服务环境等因素的资源优化与调度结果。
1.2 方法框架
基于多维关联本体的学习资源推荐方法可以分为两个过程,即多维关联本体模型构建和最优服务计算,两个过程的融合应用框架见图1。多维关联本体模型构建包括多源异构数据分析处理和多维关联本体设计等;最优服务计算依赖学习资源推荐模型进行,由推理计算和智能计算两个方法组成。笔者方法先将获取到的情境数据和分布在网络上的学习资源映射到设计的多维关联本体中,形成多层次、细粒度和有组织的数据结构;为了更深层次地挖掘用户的隐性知识需求,利用语义网推理技术进行推理计算,将低阶的数据转化成高阶的信息。在此基础上根据用户的知识需求,利用动态自均衡的二进制粒子群优化算法进行寻优计算,计算出当前情境下与用户需求最匹配的学习资源以及学习路径。

图1 基于多维关联本体的学习资源推荐方法框架
1.3 知识迷航值定义
知识迷航值(Knowledge disorientation)是学习资源推荐效果优劣的评价指标,表示学习者在接受学习资源推荐服务时产生对知识内容不理解的程度。知识迷航值越高,意味着学习者对知识内容不理解的程度越高,推荐的效果越差;反之,则说明当前推荐的学习资源能更好地满足学习者学习需求,推荐效果更好。知识迷航值由知识迷航值函数计算获得,用KD表示。
2 基于多维关联本体和改进粒子群算法的学习资源推荐模型
2.1 多维关联本体设计与实例填充
2.1.1 学习资源本体
学习资源本体包括学习资源各特征的详细信息,主要包含学习资源与知识点的对应关系、媒介类型、难度水平以及内容类型。
学习资源本体参数表示:
1)定义学习资源集合KU={KUm1,KUm2,…,KUmi},1≤m≤M,1≤i≤I,KUmi为第m个知识点的第i资源实例,M为目标知识点数量,I为每个知识点下的学习资源数量。设学习资源路径变量为xKUiKUj,使用二进制编码,当学习路径为资源i到资源j,则xKUiKUj=1,否则为0。
2)定义学习资源难度D={Dm1,Dm2,…,Dmi},Dmi为第m个知识点下的第i个资源的难度水平。
3)定义学习资源的媒介类型MT={MT1,MT2,…,MTn}={文本,图片,视频,互动游戏},n为媒介类型数量,设置n=4。
4)定义学习资源与知识点的关联度KR={KRm1,KRm2,…,KRmi},KRmi为第m个知识点与第i个学习资源的关联度,m为目标知识点数量,i为每个知识点下的资源数量。
5)定义学习资源的内容类型为KS={KS1,KS2,…,KSq}={课前预习,课中学习,课后复习,综合复习},q为内容类型数量,设置q=4。
2.1.2 学习者本体
学习者本体包括学习者的详细信息,包括学习目标、学习能力、学习风格、情感状态、媒介偏好和认知水平。用kolb风格类型对学习风格进行划分。
学习者本体参数表示:
1)定义学习者L={L1,L2,…,Lk},1≤k≤K,Lk为第k个学习者,K为学习者总数。定义学习者学习目标LC={LCk1,LCk2,…,LCkm},LCkm为第k个学习者目标学习m个知识点。定义学习者计划的学习时长LT={LT1t,LT2t,…,LTkt},LTkt为第k个学习者计划学习的时长。
2)定义学习者学习能力A={A1,A2,…,Ak},Ak为学习者Lk的学习能力,1≤k≤K。
3)定义学习者的学习风格为S={S1,S2,…,Sa}={聚合型,发散型,同化型,调节型},0≤a≤A,A为学习风格数量,设置A=4。
4)定义学习者的情感状态LE={LEk1,LEk2,…,LEke}={消极,较为消极,一般,较为积极,积极},1≤k≤K,0≤e≤E,K为学习者总数,E为情感状态种类,本文中设置E=5。LEke第k个学习者的情感状态,在学习过程中学习者有唯一情感状态。
5)定义学习者的媒介偏好LM={LMk1,LMk2,…,LMkn},k为学习者总数,n为媒介类型数量,LMkn为第k个学习者对第n种媒介的偏好值。
6)定义学习者的认知阶段O={O1,O2,…,Ob}={入门阶段、联系阶段、提高阶段},1≤b≤B,B为认知阶段种类,设置B=3。学习者有唯一认知阶段与之对应。
2.1.3 情境本体
情境本体包含学习环境的详细信息,包括时间、位置、网络环境和设备电量等。
情境本体参数表示:
1)定义学习者开始学习时间T={T1,T2,…,Tk},1≤k≤K,Tk表示第k个学习者开始学习的时间。
2)定义学习者的位置Si={Si1,Si2,…,Sik},Sik表示第k个学习者学习时的位置。
3)定义学习者学习时的网络环境Ne={Ne1,Ne2,…,Nek},Nek表示第k个学习者学习时的网络环境。
4)定义学习者学习使用的设备电量El={El1,El2,…,Elk},Elk表示第k个学习者的设备电量情况。
2.1.4 语义关系设计和实例填充
为将散布在各个学习平台中的学习资源组织起来,通过爬取各平台网络学习资源信息,利用中科大研发的ICTCLAS 2019自然语言处理系统对数据进行预处理,提取出学习资源中的关键信息和语义关系三元组,通过移动设备获取的学习者信息和情境信息也用同样的方向进行预处理。
一般情况下学习过程将使用多个学习资源,知识点有前导后继的关系,因此使用的学习资源也有先后顺序。不同的学习者在不同的情境下需求的学习资源也是不同的。因此学习资源本体、学习者本体和情境本体有多维语义关系。为构建上述的关系并嵌入实例,使用知识图谱中TransR[11]技术构建多维关联本体和实例填充。TransR将实体空间和关系空间相分离,充分考虑了实体存在多种语义关系的情况,将实体和关系分别映射到不同的语义空间中。对抽取的三元组(h,r,t),h,t属于空间Rk,r属于空间Rd,对每一个关系r,用映射矩阵Mr∈Rk×d把实体h,t从实体空间映射到关系空间,映射公式为
hr=hMr,tr=tMr
(1)
并满足如下约束条件,即
hr+r≈tr
(2)
实例映射进本体结构完成了部分自身逻辑构建,而自定义规则推理构建需教师或者专家进行语义手工补充,完善多维本体[12]。针对部分信息系统数据缺失导致推荐服务难以运行的问题,通过建立本体模型和本体逻辑属性分析,利用语义网逻辑标注就能推理出遗漏或缺失参数,完善和优化推荐服务初始化参数。而基于本体逻辑属性的推理计算往往不能识别出其隐性的知识,需要依靠建模人员和领域专家采取相应的处理方法才能将隐含在本体显示关系中的隐性知识提取出来[13]。因此,基于自定义规则的推理计算应用能极大降低事件处理复杂性,提高知识推荐服务工作的精准性。
笔者基于文献[14]和教学先验知识,充分利用情境信息和学习者信息构建了5 条自定义推理规则(表1)。通过Jena推理机进行本体的推理操作。

表1 自定义推理规则
2.2 学习资源推荐模型构建
移动学习资源推荐模型见图2。在图2的模型中将多源异构数据集A映射到多维关联本体M中,经推理计算得到子函数值集合B。即经过A→M→B两次映射,使得任意多源异构数据x∈A,有y∈B对应。为了提高推荐的精度,需要构造学习资源推荐目标函数进行寻优计算评价。构建多维关联本体可以实现3者间的关系解释和推理,进而得到子函数需要的数据。深入分析3 个维度因素之间关系,需要计算学习资源与用户特征匹配差值、学习资源间契合度差值,资源与知识点匹配差值以及情境特征匹配差值,需要构建多个子目标函数。

图2 移动学习资源推荐模型

(3)
式中:F(i)为4 个子映射函数;F(1)为学习资源难度与学习者能力差异信息;F(2)为学习资源之间的支出信息;sKUiKUj为学习的第i个学习资源和学习的第j个学习资源之间的支出;F(3)为学习资源与知识点匹配度;F(4)为学习者的学习风格与学习资源类型匹配度信息。参考文献[5,7]的目标函数权重值的设置,结合教学经验设置各子函数的权重ω1,ω2,ω3,ω4分别为0.3,0.2,0.3,0.2。
2.3 动态自均衡二进制粒子群算法设计

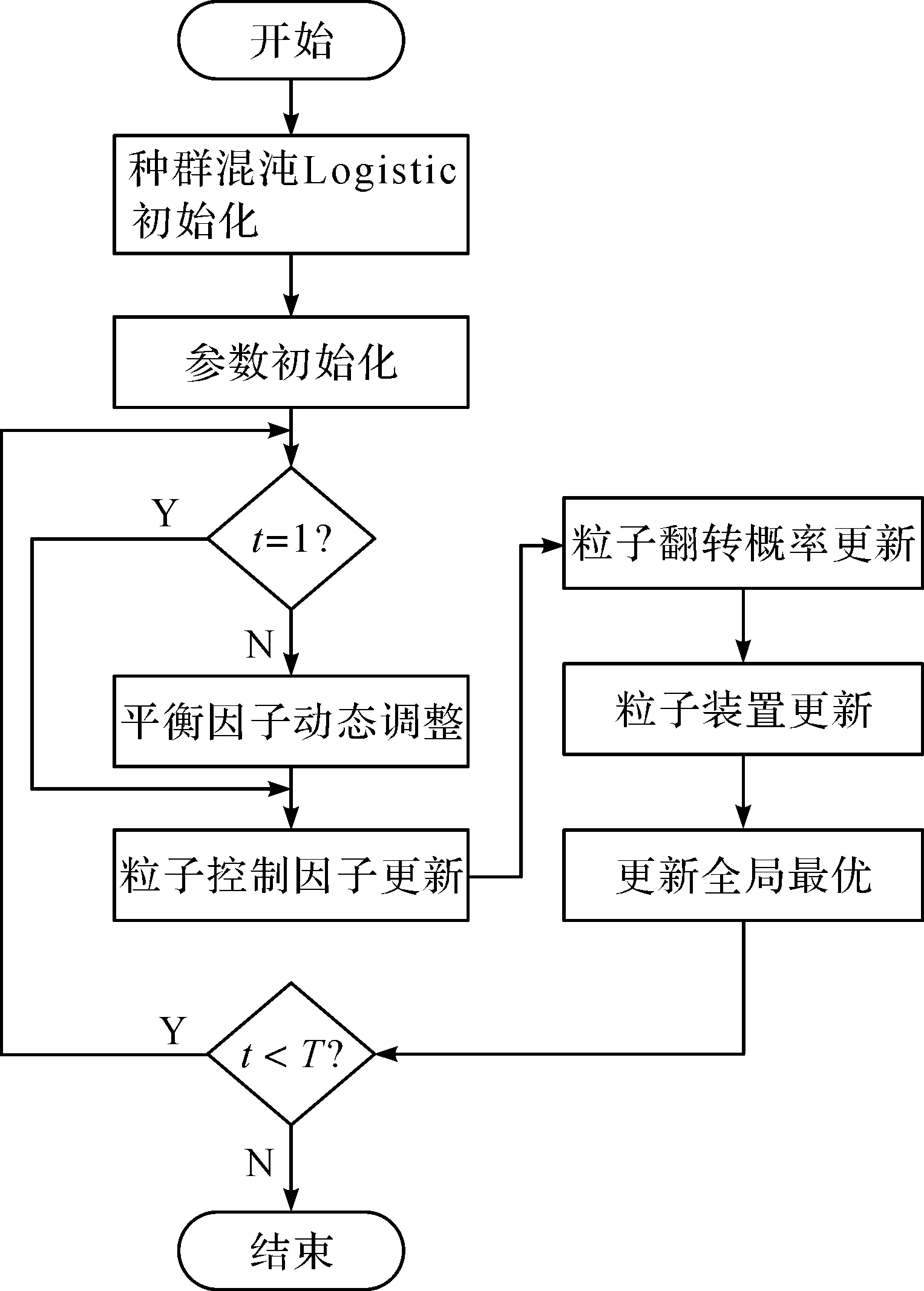
图3 DSEBPSO算法流程
2.3.1 平衡因子设计
DSEBPSO算法通过衡量粒子位置是否发生翻转取代BPSO中的速度,设计平衡因子(balance),控制粒子在0和1之间翻转,以达到控制开发和探索的目的。当粒子的平衡性高时,控制粒子位置在一段时间内保持不变,增强开发功能,但平衡因子的阈值设置过高会导致算法早熟,因此设计平衡因子,当粒子刚刚发生翻转时,让其保持一段时间平衡,但平衡因子阈值随时间降低,直至粒子再次发生翻转。平衡因子公式为
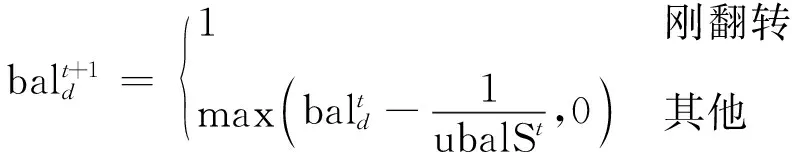
(4)
2.3.2 粒子翻转概率设计
在二进制空间中将BPSO中的速度视为粒子翻转的概率,由于学习因子和社会因子适用于连续域,对于二进制空间需要设置相同的因子去描述粒子运动状态。因此设计的粒子翻转概率保留了BPSO中的学习因子和社会因子,即
pd=ip×|pbd-xd|+ig×|gbd-xd|+
is×|1-bald|
(5)
式中:ip,ig为学习因子;is为社会因子;pbd,gbd分别为粒子的个体历史最优解和种群探索到的当前最优解。
当迭代开始时pbd=gbd可能性较大,当种群收敛时pbd≠gbd可能性较大,当迭代快结束时pbd=gbd的可能性较大,根据式(5)pd的最大值为ip+ig+is,因此设置ip+ig+is的和为1。在迭代过程中,粒子位置存在4 种可能,因此式(5)可以描述为
(6)
2.3.3 粒子位置更新策略
根据设计的粒子翻转概率式(5),粒子位置更新需考虑先前粒子位置,因此位置更新策略为
(7)
2.3.4 控制因子设计
设α为ip/ig,则ip,ig和is可表示为
(8)
(9)
将式(8,9)带入式(6),pd可以表示为
(10)
从式(10)可以发现粒子翻转概率与α,bald,is这3 个参数相关。文献[17]验证了α=0.5有更好的寻优结果,因此固定α=0.5。对于固定的α值,pd值由bald,is这两个参数决定。由式(10)可见:若is不变,bald减小,pd增大,探索能力增强,而bald增大则pd减小,将进行更多的开发。若bald固定,is减小pd也减小,开发能力增强,而is增大则pd增大,将进行更多的探索。在搜索迭代中,希望一开始能进行更多的探索,在后期能进行更多的开发,因此设计衰减因子ubalS和社会因子is,即

(11)
(12)
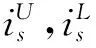
算法开发和探索的动态自均衡性由式(11,12)控制。由式(11,12)可知:设计衰减因子ubalS在迭代初期的初始值较小,平衡因子易达到阈值发生翻转,这样可以防止算法早熟,有利于探索。而ubalS随迭代过程线性增大,使得平衡因子阈值提高,不易发生翻转,算法随机性降低,开发能力增强,不易陷入局部最优。而is初始值较高,增强大粒子在迭代初期翻转的概率,增强算法的探索能力,设计is线性递减,逐步降低粒子翻转概率,增强算法开发能力,有利于跳出局部最优解。
2.3.5 性能测试


表2 基准函数及参数
图4为4种算法在4个基准函数上的收敛曲线,由图4可知:DSEBPSO算法无论是在单峰函数还是多峰函数上均有较好的收敛速度和跳出局部最优解的能力。

图4 4 种算法在基准函数收敛曲线
3 实验研究
3.1 实验方案及数据集
通过开展一系列实验验证基于多维关联本体的学习资源推荐方法与学习者学习需求的符合程度。实验数据集包含了学习资源数据、学习者数据和情境数据。参考Zhou等[18]的实验方案和集合现有教育数据集(如edX和World UC)中的特征信息,从浙江省某高校的学习平台数据中集中提取了部分移动学习数据信息。由于网络学习平台建设历史问题,该高校学习资源主要分布在3 个学习平台上,因此收集了3 个平台的数据,但平台间存在数据壁垒,收集的数据维度有差异,因此借鉴Zhou等[18]的实验方案并结合教学实际,按照相应规则补全了缺失数据形成本实验数据集。设计了基于数据集的仿真实验和随机选取30 名学习者对Java课程学习资源推荐的实证研究,从客观和主观指标探究MCOM-LROM方法的有效性。
3.2 仿真实验设置和结果分析
需要学习知识点数量的变化会影响学习资源供给内容准确度和匹配度,学习者LK数量多少同样也会对推荐的精度和效率产生影响(表3),通过设置不同知识点和学习者数量来观察不同情境下不同学习资源推荐方法的推荐质量。表3中设置的学习资源KUi个数是一个知识点相对应的学习资源个数。实验1~3是在学习者数量相同的情况下,设置不同的知识点数量进行对比的实验效果,在这3 组实验中,对应学习资源的数量分别为250,500,1 000;实验4~6是在知识点数量相同的条件下,设置不同的学习者数量进行对比的实验参数。

表3 仿真实验参数设置
表3中学习规模为学习者数量乘以学习资源数量。实验1~6的实验规模大小分别为250,500,1 000,5 000,10 000 维。
针对上述6 组实验参数设置,分别采用基于多维关联本体的学习资源推荐方法(MCOM-LROM)、基于本体推理的学习资源推荐方法(OBR)以及基于智能计算的学习资源推荐方法(IaBR)开展实验仿真研究,以探究不同学习资源推荐方法之间的差异,验证应用有效性。对于IaBR方法,选择两种智能算法进行实验仿真,分别为标准遗传算法实现方法(GA-IaBR)和二进制粒子群算法实现方法(BPSO-IaBR),而MCOM-LROM服务方法实现使用了DSEBPSO智能算法,目的是排除智能算法性能优劣对推荐性能的影响。各核心算法参数取值同2.3.5节。
学习资源推荐方法差异会影响学习者知识迷航值大小。学习资源推荐完成时间影响着学习资源推荐方法工作效率。学习资源、学习者和情境特征信息按表3参数定义从数据集预处理获得。通过Win 10操作系统、8 GB RAM、Pyhon 3.7、tensorflow1.6和MatlabR2018语言环境进行仿真实验。30 次独立运行实验后各学习资源推荐方法知识迷航值计算的均值和方差见表4。由于本体推理可能推理出不唯一学习资源,此情况下随机从备选库选择一个提供给用户。

表4 不同实验场景下各推荐方法最优解
知识迷航值越小说明为学习者提供的学习资源越符合学习者学习需求,且和当前情境契合度越高。由表4中的数据可知:不同实验场景下MCOM-LROM方法得出的知识迷航值的平均值和方差都是最小的,表示该方法能够更好地为学习者提供学习资源且具备更好的稳定性。
MCOM-LROM在本体推荐阶段时间复杂度为O(n),智能计算阶段时间复杂度为O(mn),因此MCOM-LROM时间复杂度为O(mn)。根据文献[19-20]BPSO-IaBR和GA-IaBR时间复杂度为O(mn)。OBR的时间复杂度为O(n)。
在BPSO-IaBR,GA-IaBR,OBR,MCOM-LROM4种方法下,针对相同学习规模的服务计算时间进行对比分析,结果如图5所示。由图5可知:本体推理OBR方法耗时远低于另外两种方法,但是本体推理OBR方法的知识迷航值均值和方差较大,学习者易产生知识迷航;而MCOM-LROM方法所需时间与BPSO-IaBR,GA-IaBR方法相比较少,且计算精度和稳定性更高,所以更加适用于学习资源推荐问题。

图5 BPSO-IaBR,GA-IaBR,OBR,MCOM-LROM服务计算时间
OBR方法推理计算可以找出适合学习者的学习资源,但无法找出最优解,OBR方法的知识迷航值高于MCOM-LROM方法,而且推荐精度低、稳定性差等。传统的智能计算推荐方法中信息利用率低,直接从整个学习资源库中寻找学习者所需资源,需要计算更多数量的学习资源,降低了推荐方法效率,且随着情境信息维度增加,也较容易陷入局部最优解,方法匹配效率差距和匹配精度差距增大。MCOM-LROM方法通过知识推理,将学习资源库中不适合学习者的资源剔除,从剩余的资源中寻找规划出最适合学习者的资源,提高推荐内容精度和运行效率,而且更能契合学习者的实际需求。
3.3 实证研究结果分析
为验证笔者提出的MCOM-LROM方法是否满足学习者的需求,随机抽取了30 名正在学习Java课程的学生进行学习资源推荐。研究者收集3 个学习平台的Java课程,通过提出的MCOM-LROM向学习者进行资源推荐。通过问卷的方式调查MCOM-LROM推荐结果满意度。实验共进行了5 d,向每位学习者提供了11 个学习资源,对每一个推荐的学习资源都进行满意度调查,共计330 个调查结果,结果见表5。

表5 满意度调查结果
由表5可知:330 个评价中有32.4%的推荐结果是非常满意,有39.4%的推荐结果是比较满意,这两者比例之和为71.8%,推荐结果总体满意度较高。因此,MCOM-LROM方法能够较好满足学习者的学习需求,学习体验较好。
4 结 论
针对目前学习资源推荐方法存在推荐质量不高、学习者易产生知识迷航的问题,提出了基于多维关联本体的学习资源推荐方法(MCOM-LROM)。通过重构学习资源推荐问题求解方法,设计了多维关联本体模型构建并融合语义计算与动态自均衡的二进制粒子群优化算法寻优计算两个核心模块,充分发挥本体技术和粒子群算法优势。实验结果表明:MCOM-LROM方法提供的学习资源更符合学习者的知识需求,有效减少了学习者知识迷航现象。随着5G时代的到来,情境信息和学习资源将更加丰富,未来研究将着力于构建更好、更快速的多维关联本体,设计基于多维关联本体的情境化学习资源推荐方法,帮助学习者摆脱知识迷航困扰。
猜你喜欢
昆明医科大学学报(2022年1期)2022-02-28
新世纪智能(数学备考)(2021年9期)2021-11-24
哈哈画报(2021年10期)2021-02-28
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
当代陕西(2019年15期)2019-09-02
小型微型计算机系统(2019年6期)2019-06-06
学苑创造·A版(2018年11期)2018-02-01
读者(2017年5期)2017-02-15
飞碟探索(2015年8期)2015-10-15
