
基于最小均方误差的两步信号幅度估计算法
2021-07-20 05:41杜立婵黄绎珲
探测与控制学报 2021年3期
杜立婵,黄绎珲
(1.南宁职业技术学院人工智能学院,广西 南宁 530008;2. 广西大学计算机与电子信息学院,广西 南宁 530004)
0 引言
快速发展的无线通信技术实现了更高效的信息传递,但也使通信环境变得更加复杂,接收机同时接收到多个信号的情况难以避免,如微小卫星平台的PCMA信号侦收[1-3]、星载AIS信号探测[4]等。因此,研究单通道接收数字调制混合信号有重要的应用价值[5-6]。而如何快速准确地获知混合信号的参数,特别是幅度参数,是后续信号处理不可缺少的一环,直接影响着信号处理的速度和精度。因此研究单通道混合信号幅度估计问题具有重要的实用意义。
通信信号在传输过程中,信号幅度受信道衰落和噪声等因素的影响发生改变,幅度估计的精度直接影响到后续解调算法性能的优劣,因此幅度估计是信号盲分离的重要环节。对于单个信号的幅度估计,主要有极大似然估计方法、傅里叶谱分析法[7]和高阶差分法[8]等。文献[9]提出了一种适合于PCMA系统中幅度估计的基于判决反馈的迭代算法,算法性能在较高信噪比下接近克拉美罗不等式;文献[10]提出基于MAX-MIN思想的幅度盲估计算法,该算法在两路信号幅度差异较大条件下有着较好的估计性能,但算法性能受频率估计精度影响较大,且不适用于两路信号幅度相当的情况;针对于此情况,文献[11]提出了一种独立于载频估计的算法,算法的适应性和稳健性较好;文献[12]通过搜索零频率处循环频率轴上的大强度谱线进行混合信号的幅度估计,算法无需任何先验信息,对功率差异不大的混合信号幅度具有较高的估计精度,但不适用于两路信号幅度相差较大的情况;文献[13]通过高次方法对混合信号的幅度进行估计,该方法适用于两路信号幅度值相当的情况,而当幅度差距较大时,忽略算法的交叉项带来较大的误差,方法不再适用。
综上所述,目前已有的方法在幅度估计精度上受较多因素影响且精度不足,应用范围受限。混合信号的幅度估计,特别是高精度的幅度估计,对信号盲分离有重要意义,一些现有的单通道盲分离算法需要幅度的估值作为设置初始值的依据,但没有给出幅度估计的方法[14-15]。本文针对单通道数字混合信号幅度估计精度不足的问题,提出了基于最小均方误差的两步信号幅度估计方法。
1 混合信号幅度粗估计
接收端接收到两个信号,复基带模型可以写成:
(1)
式(1)中,Ak(t)表示两路信号的传输衰落,fk表示两路信号的载波频率偏差,θk表示两路信号的载波初相,v(t)为信道引入均值为零的复加性高斯白噪声(additive white gauss noise,AWGN),单边功率谱密度为N0/2,x1(t)和x2(t)为接收到的两路独立的同数字调制方式复基带信号,可以表示为:
(2)
(3)
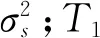
y(t)=A1ej(2πf1t+θ1)x1(t)+A2ej(2πf2t+θ2)x2(t)+v(t)
(4)
1.1 四次方法
为了方便分析,对式(4)的接收信号模型进行频率变换y(t)=y(t)e-j2πf1t,得:
y(t)=A1ejθ1x1(t)+A2ej(2π(f2-f1)t+θ2)x2(t)+v(t)
(5)
接下来y(t)对信号做四次方运算,然后对运算后的信号按采样点求平均,即:
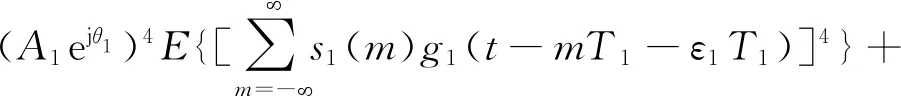
(6)
式(6)中,E{·}表示求平均运算。由于两路信号是独立调制且高斯白噪声是零均值的,利用分量信号内各符号独立性与数字调制信号的恒模特性,可得:

(7)
可将升余弦脉冲分量与调制信号分量分离开来,将上式定义为常数G。残余频偏导致式(6)第二项趋于零,由四次方平均值的模值与常数G即可估计出第1 路信号幅度值:
(8)
同理,可用类似的方法得到第2路信号的幅度估值。
该方法适用于两路信号幅值相当的情况,而当两路信号幅值差异较大时,式(6)第二项不再趋于零,按照此方法进行幅度估计将会带来较大的误差,方法将不再适用。
1.2 MAX-MIN法
当两路信号幅值差距较大时,假设A1>A2,即第一路信号的幅值强于第二路信号。同样对接收信号模型进行频率变换y(t)=y(t)e-j2πf1t。此时,y(t)的离散采样值y(k)=y(kT)将聚合在第一路信号的星座点周围。此时,将2π相平面分为D个相同大小的区间,依次记做Ω0,Ω1,Ω2,…,ΩN-1(N足够大),则可以得到两个分量信号的幅度估值:

(9)
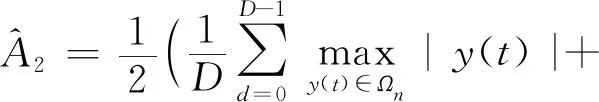
(10)
至此,得到了两种不同情况下信号的幅度估值,可设置为下一步精估计算法的初值。
2 混合信号幅度高精度估计
对接收到的信号按P/T速率进行采样,可以得到离散基带信号:
(11)
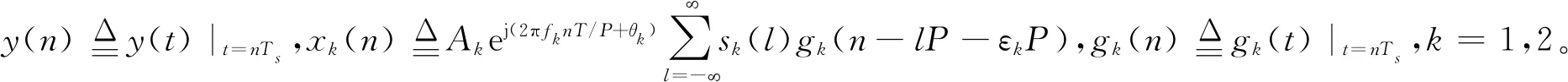
对于式(11)表示的信号模型,假设已经由以上方法估计出信号幅值,因为本文只研究信号幅值的高精度估计问题,则设其他参数已知(包括相位、时延和频偏),模型可以进一步写成:
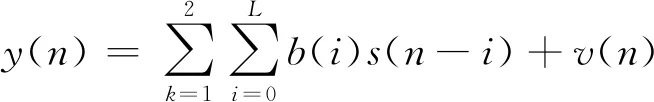
(12)
(13)
根据四阶累计量的性质,可得:
Lys(l,m,n)=γxLb(l,m,n)
(14)
Ly(l,m,n)=Lys(l,m,n)+Ln(l,m,n)
(15)
其中,E{x(k)4}-[3·E{x(k)2}]2=γx≠0,接收信号y(k)、滤波器输出ys(n)的四阶累计量定义如下:
Ly(l,m,n)=My,4(l,m,n)-My,2(l)·
My,2(n-m)-My,2(m)·My,2(n-l)-
My,2(n)·My,2(m-l)
(16)
Lys(l,m,n)=Mys,4(l,m,n)-Mys,2(l)·
Mys,2(n-m)-Mys,2(m)·Mys,2(n-l)-
Mys,2(n)·Mys,2(m-l)
(17)
式中,二阶矩My,2(j),Mys,2(j)和四阶矩My,4(l,m,n),Mys,4(l,m,n)定义如下:
Ln(l,m,n)=0
(18)
Ly(l,m,n)=Lys(l,m,n)
(19)
由于s(n)是独立产生序列,可得:

(20)
高精度估计就是使整个接收序列y(k)的四阶累计量的均方误差J1最小:
(21)
式(21)中,

(22)
用最优梯度法对J1求导,可得:
(23)
F(l,m,n,h)=b(h+l)b(h+m)b(h+n)u-1(L-h-n)+
b(h-l)b(h+m-l)b(h+n-l)u-1(h-l)u-1×
(L-h-n+l)+b(h-m)b(h+l-m)×
b(h+n-m)u-1(h-m)u-1×
(L-h-n+m)+b(h-n)×
b(h+l-n)b(h+m-n)u-1×
(h-n)u-1(L-h-m+n)
0≤h≤L
(24)
式(24)中,
(25)
通过迭代更新b(h):
(26)
正数μ称为步长参数(step size parameter)或者步长因子,它将控制算法的迭代速度,可得:
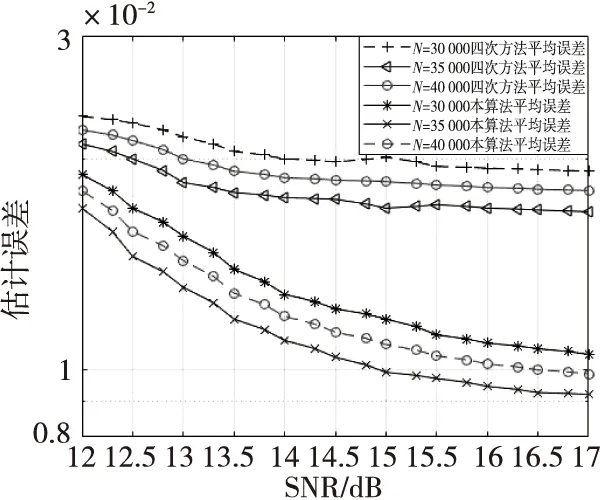
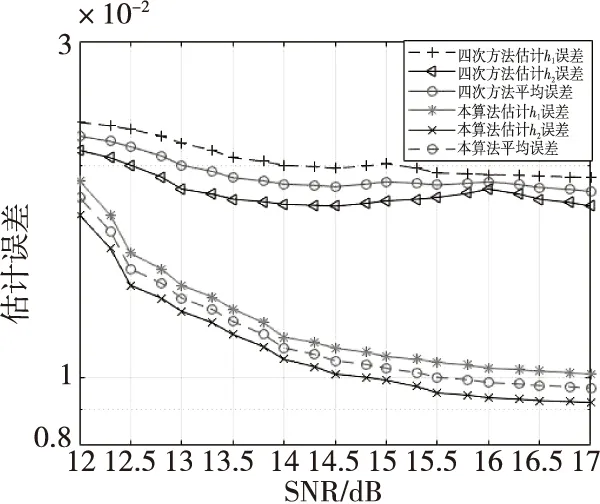
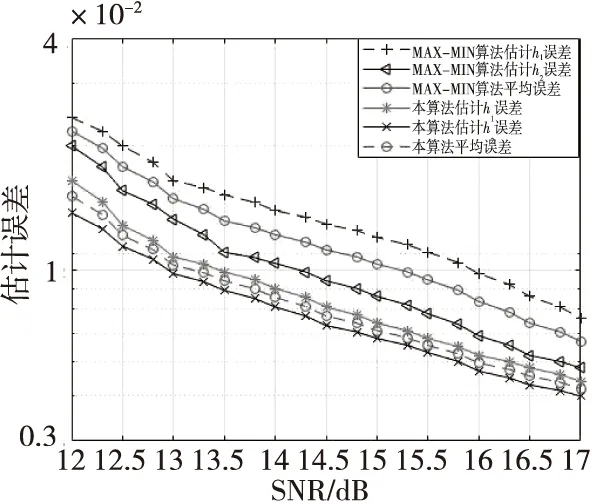
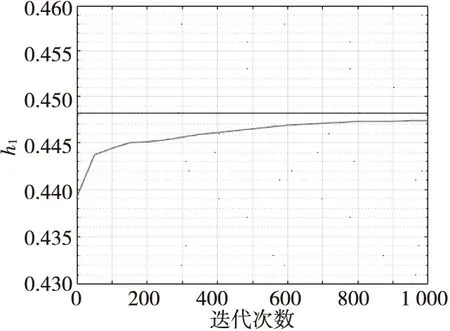
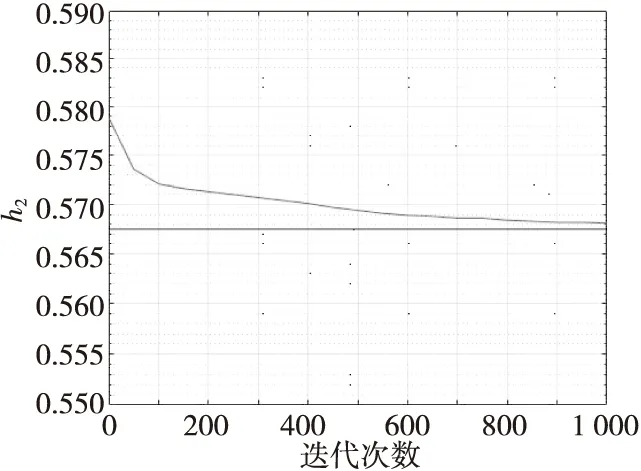
0 (27) bk(h)→b(h) (28) 信道参数的组合中,使用了时延、频偏以及初相的准确值,由式(19)可知,信道参数的误差与两路信号的幅值误差成线性关系,所以由此得出两路信号的高精度估计幅值。 仿真实验采用两路QPSK信号的混合,采样率、频偏等参数都是相对于符号率的归一化参数,码元随机均匀产生且独立同分布,假设已知两个信号的频偏f1=1×10-2,f2=1.001×10-2,符号速率分别为80和100 kHz,过采样倍数P=4,成型滤波器滚降系数β=0.35,等效滤波器长度L=17,迭代步长μ=0.01,其余参数设置为:θ1=π/4,θ2=π/8,ε1=0.8,ε2=0.65,信噪比定义为SNR=10·lg[((|A1|2+|A2|2)Es)/2N0],单路信号的幅度估计误差定义为: (29) 平均误差定义为: MSE(A)={MSE(A1)+MSE(A2)}/2 (30) 本实验考察不同符号数目对算法精度的影响。采用符号数目分别为30 000,35 000和40 000,两信号幅度比A1/A2=0.9,幅度粗估计采用四次方法进行,得到的幅度估计误差曲线如图1所示。 图1 不同符号数下算法性能的对比Fig.1 Comparison of algorithm performance under different symbol numbers 从图1中可以看出,两种算法的幅度估计误差随数据长度的增加而减小,在符号数为35 000,信噪比为12.5 dB时,两种算法的幅度估计误差均在2×10-2以内。分析算法原理可知,四次方算法涉及四阶统计量、本算法涉及四阶累计量,需要较长的数据才能提升估计精度,所以两者适合数据量较大的参数估计场合。为了满足后续处理需求,一般采用符号数30 000以上,例如,本文其他仿真实验参数估计采用符号数为35 000。 当两信号幅度比大于0.6且小于1时[16],即0.6 图2 四次方法与本算法性能对比Fig.2 Comparison of the performance of the quadratic method and this algorithm 从图2中可以看出,四次方法估计精度基本不受信噪比增加的影响,分析算法原理可知,四次方法利用了信号内各个符号间的独立性、数字信号的恒模特性及噪声方差可忽略性原理,避免了噪声对信号幅度估计的影响;而本文算法的估计精度则随信噪比的增加而提高,尽管本文算法是基于累积量的原理构造代价函数,但是本文算法有自适应迭代提升精度的过程,所以算法性能曲线有一定的提升。在信噪比较低的情况下,两种算法的估计误差均比较大,主要是因为信道环境恶劣,四次方法赋给本文算法的初值误差较大;随着信噪比的升高,本文算法幅度估计精度有所提升,在信噪比为15 dB时,精度达到了10-2量级,证明了算法的有效性。 在实验条件A1/A2=0.2的条件下,图3给出了MAX-MIN方法和本文算法在不同信噪比下幅度估计误差曲线。由图3可知,当两信号幅度比为0.2且信噪比大于13 dB时,MAX-MIN方法的平均误差在2%左右,所以MAX-MIN方法适用于两路幅度差异较大的混合信号幅度估计。对于不存在近似运算的MAX-MIN方法,无论是大信号还是小信号,在幅度比较小时都能提供较为准确的估计,在信噪比为15 dB时,精度可达到10-3量级。本文算法在信噪比为13 dB时,精度达到了10-3量级。 图3 MAX-MIN方法与本算法性能对比Fig.3 Comparison of the perfor-mance of MAX-MIN method and this algorithm 需要说明的是,本实验算法对比中,信号2的幅度估计误差要低于信号1:一是因为信号2的幅度值更大,代表信号能量越大,估计误差更小;二是因为信号2的符号速率大于信号1,对于同样的采样点来说,信号2参与估计算法的符号数要多于信号1,符号数越多则统计量的估计值也就越准确。 本节考察以四次方法为粗估计算法的条件下,本文算法随迭代次数的收敛速度情况。实验条件设定为:信噪比15 dB,h1、h2的准确值h1=0.448 2,h2=0.567 5,迭代步长μ=0.01,符号数目N=35 000。从图4、图5中可以看出,在经过四次方法估计之后,两信号幅值估计较为准确,均在2%左右,本算法经过50次的迭代后,误差减少一半以上,经过大约1 000次的迭代,误差可以达到10-5量级,精度提升作用明显。在实验中取迭代次数为50次,精度已经能满足后续处理的要求。 图4 本算法h1收敛曲线Fig.4 h1 convergence curve in this algorithm 图5 本算法h2收敛曲线Fig.5 h2 convergence curve in this algorithm 本文提出了基于最小均方误差的两步信号幅度估计方法,该方法采用高次方法或最大最小法进行幅度的粗估计,然后利用接收序列累积量的最小均方误差准则,通过自适应迭代更新参数,提升了分量信号的幅度估计精度。仿真实验表明了本算法的有效性,算法经过50次迭代后,幅度估计误差减少一半以上,参数估计精度提升明显。算法收敛速度快,应用范围广,做到了性能和复杂度的较好折中,具有实用价值。3 仿真结果与分析
3.1 不同符号数下算法性能的对比
3.2 幅度估计算法对比
3.3 算法的收敛速度
4 结论
猜你喜欢
装备维修技术(2022年7期)2022-07-01现代仪器与医疗(2022年1期)2022-04-19北京理工大学学报(2021年12期)2022-01-13股市动态分析(2021年25期)2021-12-30北京理工大学学报(2021年8期)2021-09-14汽车与安全(2019年11期)2019-06-01中国新技术新产品(2018年22期)2018-01-05筑路机械与施工机械化(2016年12期)2017-01-13股市动态分析(2014年27期)2014-07-29
