
基于混合采样和集成学习的软件缺陷预测
2021-07-26 01:19杨昊天顾乾晖王嘉璐施恺杰徐力晨
网络安全技术与应用 2021年5期
◆杨昊天 顾乾晖 王嘉璐 施恺杰 徐力晨
(南昌工程学院信息工程学院 江西 330096)
软件缺陷检测是软件工程的重要课题[1]。一些常见的机器学习方法,如支持向量机、决策树、KNN、逻辑回归、朴素贝叶斯等都能够用来建立分类模型[2]。但是,对于软件缺陷检测问题,经典的学习方法效果并不理想。由于传统分类器的训练过程普遍遵循误差最小化原则,当训练数据不平衡时,分类面向多数类偏倚,因此最终的模型对少数类的分类性能较差,在严重情况下,模型甚至完全无效。类别不平衡指的是训练数据中不同类别样本的数量差异很大,其中某些类别的样本数目要远小于其他类别样本的数目[3]。这种情形广泛存在于现实应用中。不平衡的数据降低了少数类样本的分类正确性[4]。
不平衡学习算法目标可以简单描述为在不严重降低多数类准确性的情况下获得一个能够为少数类提供高准确率的分类器[5]。类别不平衡学习一直是机器学习与数据挖掘领域的研究热点与难点之一。目前,已有许多类别不平衡学习技术被提出,大致可以分为数据层处理技术、内置技术,混合技术。为了有效提升软件缺陷预测精度,本文提出了一种将SMOTE_Tomek 采样和集成学习算法XGBoost[3]相结合的分类预测模型。该模型先利用组合采样方法SMOTE_Tomek 使失衡的数据平衡,同时滤除噪音样本,然后再使用集成学习算法XGBoost 进行训练得到分类模型。为了评估提出的分类模型的有效性,我们利用十个NASA 软件缺陷数据集进行了广泛的比较实验。实验结果验证了本文提出的模型解决软件缺陷预测问题的优越性。
1 XGBoost 集成学习
XGBoost 是一种基于决策树并使用梯度提升框架的集成学习算法。
本文利用XGBoost 集成学习算法在平衡后的数据集上进行训练。设每个数据集中有n 个样本和m 个特征,记为:D={(xi,yi)}(|D|=n,xi∈Rm,yi∈R)。其中yi为实际缺陷标签。根据XGBoost 算法中决策树函数fk(x),预测缺陷标签,其中k 为迭代次数。由损失函数和惩罚项Ω(fk)建立目标函数。损失函数衡量目标值yi与预测值之间的误差,惩罚项用以避免过拟合,则目标函数可表示为
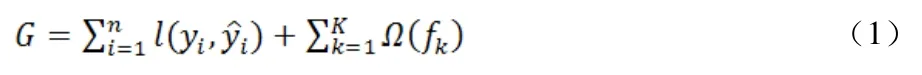

其中γ为决策树的复杂度,λ为惩罚因子,T 为决策树的叶子节点数目,ω为数据分到决策树中叶子节点的所在层数。将上式进行泰勒展开,则算法的第k 次的目标函数可近似表示为

在模型训练阶段,每次迭代选择最优的fk(x),使得式(3)最小化。
2 结合SMOTE_Tomek 的XGBoost 软件缺陷预测
采样技术主要包括欠采样和过采样。常见的欠采样方法主要有:随机欠采样、Tomek Links、NearMiss-1、NearMiss-2、NearMiss-3 等。下面以NASA 数据集中的PC3 样本为例。图1 展示了PC3 原始数据样本的分布情况。

图1 PC3 原始数据样本
SMOTE 采样方法在平衡数据的同时,造成了分类面的过度偏倚,因此提出了组合采样技术SMOTE_Tomek。该方法可以很好地改善SMOTE 过采样中的噪声和边界问题。该方法包含两步:首先利用SMOTE 采样对不平衡数据进行过采样处理,然后再通过Tomek Links采样对新生成的样本中存在的噪声进行删除。图2 展示了采用SMOTE_Tomek 采样方法后的新数据样本分布。

图2 SMOTE_Tomek 采样
3 实验结果与分析
3.1 数据集与评估指标
本文实验使用了十个美国国家航空航天局(NASA)的软件缺陷数据集。这些数据集是公开并被广泛使用于软件缺陷预测的数据集。每个数据集对应NASA 某个软件子系统,其特征包括代码行数、递归最大深度等。
软件缺陷预测是一个分类问题,分类问题中我们评估实验效果可以通过混淆矩阵来计算,由混淆矩阵计算出精确率、召回率、准确率和F1 值。其中,F1 值表示的是精确率和召回率的调和平均值,它的值越大,模型的分类性能越好。
3.2 分类性能比较与分析
本文实验的采样阶段分别比较了多种常用的欠采样和过采样。主要包括:随机过采样[6]、ADASYN、SMOTE,以及本文使用的SMOTE_Tomek 采样方法等。为了验证文中所提出的组合模型的性能,使用了不同的组合分类模型与之对比。表1 使用不同的采样模型和XGBoost 分类模型相结合,随机连续进行20 次实验,计算出各个组合预测模型在十个NASA 数据库中的准确率。

图3 八种采样方法分别与XGBoost 分类器相组合的F1 值比较

图4 九种分类器分别与SOMTE_Tomek 采样相组合的F1 值比较
在NASA 数据集上,使用过采样与XGBoost 的组合预测模型结果普遍优于欠采样与XGBoost 的组合模型。其中SMOTE_Tomek 与XGBoost 的组合模型有最优的准确率。但是,对于不平衡数据的分类,准确率往往不是理想的比较指标。因此,我们进一步对各个组合模型的F1 值进行比较。在十个NASA 数据集的预测结果中,过采样方法比欠采样方法有更好的F1 值。由各个采样方法在每个数据集的F1 值计算得到各个采样方法的F1 均值,如表1所示。表1 的实验结果表明,对于NASA 软件缺陷数据集,SMOTE_Tomek 采样方法与XGBoost 相组合的分类模型获得最优的F1 值,即有最好的分类性能。为了进一步验证SMOTE_Tomek 采样与XGBoost 组合的分类模型的优越性,我们进一步比较了SMOTE_Tomek 采样算法与其他主流分类器相组合的分类模型,实验结果如表2所示。

表1 10 个NASA 数据库上的F1 均值

表2 10 个NASA 数据库上的F1 均值
4 结束语
本文提出了一种SMOTE_Tomek 组合采样方法和XGBoost 集成学习相结合的分类模型。我们在十个NASA 数据集上的仿真实验结果表明:该组合模型在软件缺陷预测上有着非常出色的表现,获得了最好的平均准确率和平均F1 值。实验结果证明了本文提出的分类模型能够很好地处理软件缺陷预测问题。
猜你喜欢
数学小灵通(1-2年级)(2021年4期)2021-06-09
卷宗(2020年34期)2021-01-29
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
成都信息工程大学学报(2019年3期)2019-09-25
中学生数理化·七年级数学人教版(2019年4期)2019-05-20
电子制作(2018年16期)2018-09-26
中学生数理化·七年级数学人教版(2018年6期)2018-06-26
初中生世界·七年级(2017年9期)2017-10-13
中央民族大学学报(自然科学版)(2016年4期)2016-06-27
郑州大学学报(医学版)(2015年1期)2015-02-27
