
基于改进的Flume的实时数据采集系统
2021-08-09 00:35朱涛孙知信宫婧
科技资讯 2021年11期
朱涛 孙知信 宫婧
摘 要:任意一个分布式系统都必须满足CAP理论,在数据分析分析系统中,最为重要的是效率以及可靠性,而数据采集时整个分析系统的基石,构建基于改进的Flume的实时数据采集系统,通过flume采集数据,采用复合型Channel与flume相结合,在保证数据源的丰富性和可靠性的前提下,提高采集的效率。实验结果表明,该系统的各项功能符合预期结果,Flume使用复合型Channel可以提高采集效率。
关键词:Flume CAP 实时性 分布式
中图分类号:TP273.5 文獻标识码:A文章编号:1672-3791(2021)04(b)-0073-04
Real Time Data Acquisition System Based on Improved Flume
ZHU Tao SUN Zhixin* GONG Jing
(Nanjing University of Posts and Telecommunications, Nanjing, Jiangsu Province, 210023 China)
Abstract: Any distributed system must meet the CAP theory. In a data analysis system, the most important thing is efficiency and reliability. The cornerstone of the entire analysis system for data collection is to build a real-time data collection system based on improved Flume. Collect data through flume, and use the combination of composite channel and flume to improve the efficiency of collection while ensuring the richness and reliability of the data source. The experimental results show that the functions of the system meet the expected results. Flume uses the composite channel can improve the collection efficiency.
Key Words: Flume; CAP; Real-time; Distributed
随着互联网技术飞速发展,各种网络应用呈现爆发式增长,同时用户使用量也急剧增加,这也意味着各种智能终端产生的日志数据与日俱增,如何更好地管理以及更快地采集日志数据,成了一个亟待解决的问题,而数据是实现大数据研究的基础,传统的数据采集技术方案己经难以满足快速采集高质量的数据集的需求。
1 相关技术研
hossam hakeem[1]在基于对当前的国内外的大数据环境进行的深度剖析的基础之上,提出基于大数据的数据分析的软件架构,并针对于自己需要处理的数据类型提出一种基于分层的数据分析的模型。尚凯[2]基于对国内运营商数据的复杂性以及数据采集时的困难的研究,提出一种新的方案,其规定数据采集的来源均来源于企业B域、O域、M域以及企业外部,采用高可用、高可靠、分布式的数据采集方法,并对这些数据进行清洗、处理后,将数据存储于运营商的数据库当中,此方案在对于海量的结构化以及非结构化的数据进行采集时可以提供很好的实时性。
于秦[3]通过开源软件Flume设计实现一款分布式多平台多系统收集多种日志的系统,此系统具有高吞吐量、可扩展性强、高聚合等特征。在提供高速数据采集解决方案方面, 李祥等[4]研究者中同时使用这两个组件,系统的整体架构分为数据采集层、数据分析层、Web界面展示组成,而数据分析采用了Hadoop和Strom分别实现数据的离线和实时计算,数据采集层采用Flume来实时地采集数据。陈飞等[5]研究者采用Flume的数据采集框架和ElasticSearch组合来对Nginx的日志进行数据采集,并对这些数据进行分析,从而完成对整个系统的实现。Hadoop是一般是用作离线处理的,而Strom则是一个很好的实时计算框架。
通过上述分析,该文将构建基于改进的Flume的实时数据采集系统,在提高数据的采集效率同时采用分布式系统满足高可用性,提高了分析系统的分析效率。
2 基于改进的Flume的实时数据采集系统
现如今的研究更多地关注动态实时数据,而不是静态数据,这提出了更高的技术要求。要处理流数据,第一步是收集大规模实时流数据[6]。由于实时数据传输的不稳定性,流数据的收集与传统方法大不相同。随着数据种类变得复杂且框架自带的Memory Channel和File Channel都会有各种各样的问题,无法提高更好地实时数据采集[7]。下面提出对Flume框架的改进。
Flume自身提供了Memory Channel和File Channel。当相关人员使用Memory Channel,它会将events存放于内存的队列中保证它的效率,它的优点就是高效、高吞吐量,但是缺点也很明显,当机器宕机或者服务死掉的时候,内存中的数据都会丢失,从而导致分析得不到准确的数据。而File Channel却相反,它是将所有的events被保存在本地的磁盘文件中,优点是容量较大且发生故障时数据可恢复,缺点就是速度较慢。
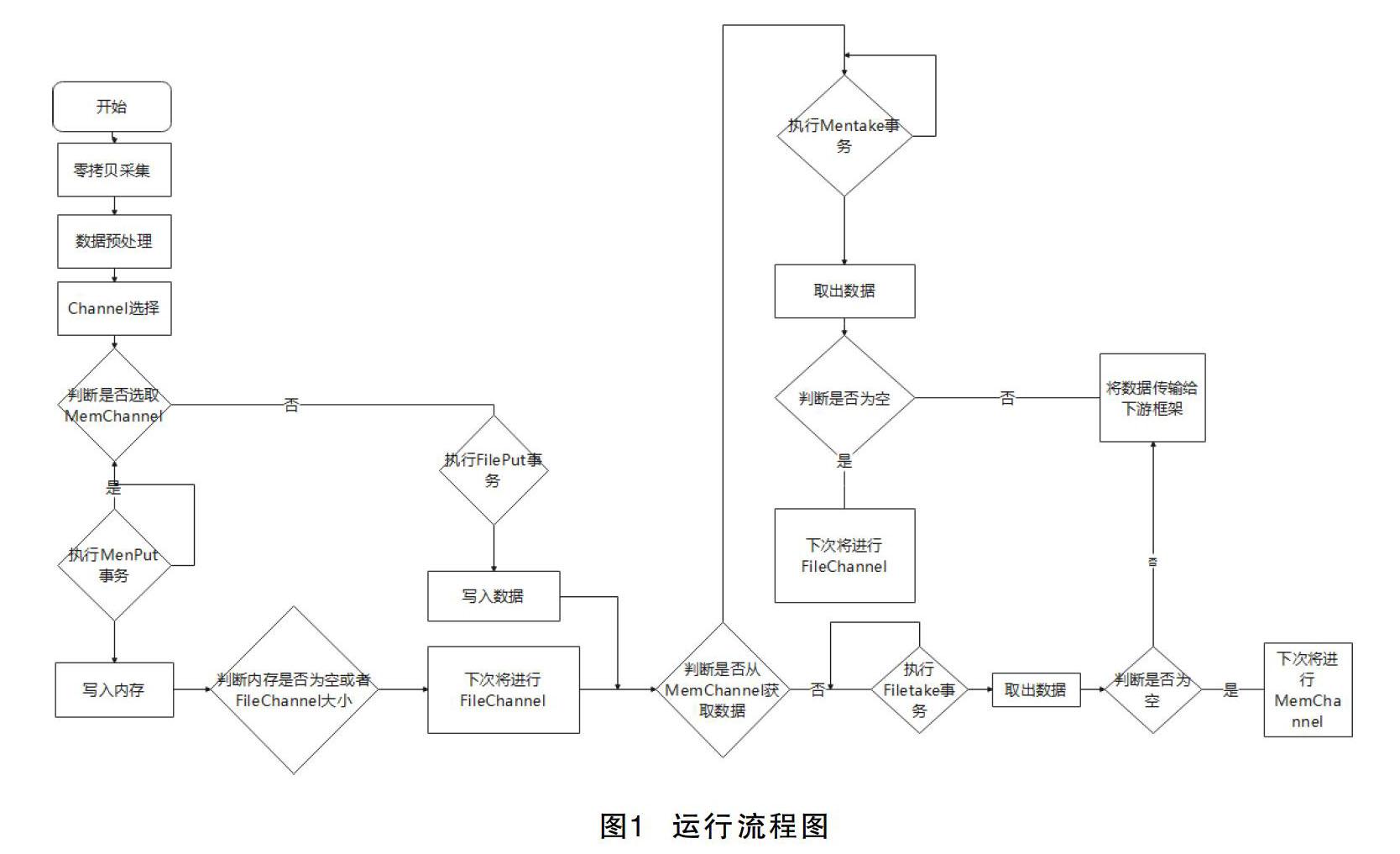
为了充分利用这两种channel的优势,该文引入复合型channel,复合型channel根据其内在的每个channel的使用情况以及下游Sink的处理情况,来自主地选择下次使用哪种channel来进行数据的存储。Sink的接收速度很快,当Sink接收器处理速度够快,并且Channel没有存放过多数据的时候,相关人员可以采用Memory Channel,从而使得整个的系统的传输效率最大化;反之,当Sink接收器处理速度跟不上,同时希望Channel可以暂时存储采集到的数据时,相关人员可以采用File Channel来减少下游数据处理的压力。因此,需要实现complex Channel,即就能智能地在两个Channel之间切换。复合channel的运行流程图见图1。
步骤1:flume从磁盘实时采集数据,经过拦截器对数据进行一些预处理。
步骤2:经过预处理的数据通过选择器,选择复合型的channel。
步骤3:定义两个原子布尔型变量(putToMemCh-
annel、takeFromMemChannel)作为标志位,分别表示是否写入MemChannel和是否从MemChannel中取出。
步骤4:执行put方法,判断是否可以往内存MemChannel写入数据,如果可以,则转到步骤5,否则,转到步骤7。
步骤5:对数据的put事务性的判断,是否满足要求,如果满足,则转至步骤6,否则,转至步骤5。
步骤6:将数据写入内存,并且为下次的写入做准备,判断MemChannel是否为空或者FileChannel现在大小是否超过100,二者只要满足其一,就将putToMemChannel置为false。
步骤7:对数据进行put进行事务性的判断,是否满足要求,如果满足,则将数据通过写入FileChannel,如果不满,则转至步骤7。
步骤8:执行take方法,判断是从哪个类型的channel获取数据,如果是MemChannel,则转至步骤9,否则转至步骤11。
步骤9:对数据的take事务性进行判断,判断是否满足要求,如果满足,则转至步骤10,否则,转至步骤9。
步骤10:对数据进行事务性的取出,并判断数据是否为空,如果为空,代表内存中无数据,将takeFromMemChannel设为false,意味着下次将从FileChannel中获取数据。
步骤11:对数据进行事务性的取出,并判断数据是否为空,如果为空,代表文件系统中没有数据,则将takeFromMemChannel和putToMemChannel设为true,意味着下次将从内存中读取和写入数据。
3 系统实现与测试
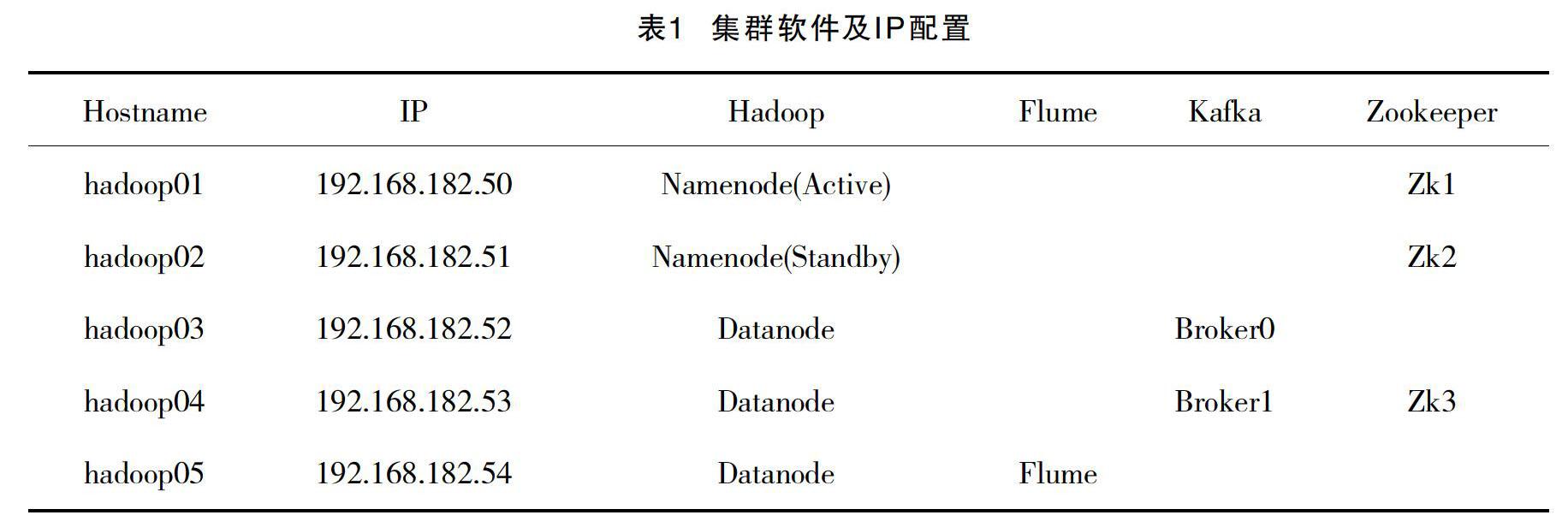
在构建该系统中,该文基于E5-2667CPU(20處理器)、128内存和25T硬盘的服务器上利用VM-ware 虚拟化5台服务器,利用这5台服务器进行综合评测。集群安装组件配置如表1所示。
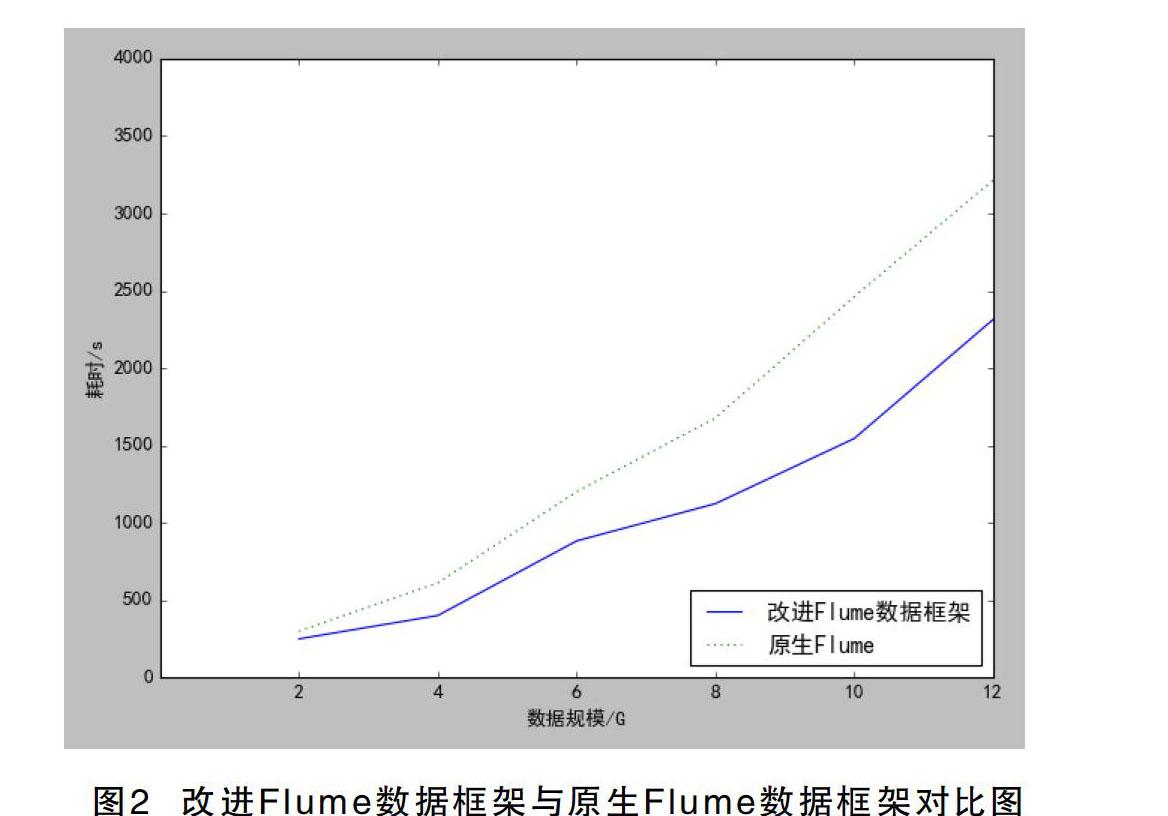
该文设计的系统模型与传统的Flume-HDFS模型在同一大小数据的分析耗时对比见图2,该系统的传输效率以及在数据的分析实时性要高于原系统。
4 结语
该文构建了基于改进的Flume的实时数据采集系统,通过实现数据采集框架与复合Channel选择技术相结合,对数据采集环节做出了改进。实验测试了数据采集的效率。由实验结果表明,相比于传统的数据
分析系统,该系统在数据采集效率和时性方面有明显的提升。综合分析可得,该文平台可以更加高效地、稳定地完成数据的实时采集。
参考文献
[1] Hossam Hakeem.Layered Software Partterns for Data Analysis in Big Data Environment[J].International Journal of Automation and Computing,2017,14(6):650-660.
[2] 尚凯.企业数据中心数据采集与建模[D].山东大学,2017.
[3] 于秦.基于Apache Flume的大数据日志收集系统[J].中国新通信,2016,18(18):41.
[4] 李洋,吕家恪.基于Hadoop与Storm的日志实时处理系统研究[J].西南师范大学学报:自然科学版,2017,42(4):119-126.
[5] 陈飞,艾中良.基于Flume的分布式日志采集分析系统设计与实现[J].软件,2016,37(12):82-88.
[6] M.Rashid,A.Hamid,N.Ahmad,et al. Novel Machine Learning Approach for Sentiment Analysis of Real Time Twitter Data with Apache Flume[C]//2020 Sixth International Conference on Parallel,Distributed and Grid Computing (PDGC).2020:336-340.
[7] A.Kanavos,G.Vonitsanos,A.Mohasseb,et al. An Entropy-based Evaluation for Sentiment Analysis of Stock Market Prices using Twitter Data[C]//2020 15th International Workshop on Semantic and Social Media Adaptation and Personalizatio.2020:1-7.
猜你喜欢
科学与财富(2021年35期)2021-05-10
华东师范大学学报(自然科学版)(2019年5期)2019-11-11
电子技术与软件工程(2016年22期)2016-12-26
电脑知识与技术(2016年24期)2016-11-14
物联网技术(2015年10期)2015-11-10
物联网技术(2015年5期)2015-07-18
无线互联科技(2015年3期)2015-04-13
