
弱光条件下非规则曲面上浅刻蚀字符的识别研究
2021-08-23 03:17同军超施恢胜吴臻冕张卫超
数字制造科学 2021年2期
程 鑫,同军超,施恢胜,张 帆,吴臻冕,张卫超
(1.武汉理工大学 机电工程学院,湖北 武汉 430070;2.湖北省磁悬浮工程技术研究中心,湖北 武汉 430070)
光学字符识别(optical character recognition,OCR)技术的概念由德国科学家提出,接着美国科学家也提出了类似的想法,之后世界各国开始了对OCR技术的研究[1]。日本学者最先研究汉字识别。中国起步比较晚,但在后来取得了实质性的进展。目前,OCR技术应用的领域越来越多,包括列车号识别、车牌识别、手工填写表格识别、铁路集装箱号识别、港口集装箱号识别以及芯片批号识别等[2-6],市场上也有很多相关的产品。但在弱光条件下,这些产品对非规则曲面,浅刻蚀字符识别的适应性不理想,因此对弱光条件下非规则曲面和浅刻蚀字符识别的研究有重要意义。
弱光条件下会降低待识别字符与区域背景的对比度,降低获取图像的信噪比,给识别算法以及系统设计带来很多问题。非规则曲面和浅刻蚀条件会给补光带来光线覆盖范围和光线反射不规律问题,并且浅刻蚀的字符清晰度很差,不利于图像预处理和字符识别。
文献[7]研发了一套图像获取自适应系统,采用LED灯打光的方式解决了环境光线造成的字符成像不清晰的问题。针对不规则曲面字符以及图像显示微弱难以获取的情况,文献[8]利用照明的方式提高弱光情况下的图像亮度,并用偏振片来减少反射到摄像头的强光来提高成像清晰度。文献[9]通过研究各种单色光对图像清晰度的变化,利用单色光照射提高了显示微弱图像的清晰度。
针对上述弱光条件、非规则曲面及浅刻蚀问题,笔者提出了一种外部光线阻断,摄像头腔体内部单色补光的方法,实现了较高的字符识别精度。
1 字符识别系统的整体构成
字符识别系统的整体结构如图1所示,其主要实现思路为:①将被识别物体放置在黑箱中,采用内部光源补光,增强了需识别对象的光照条件,也避免了外部强光干扰,增强了弱光条件字符识别效果;②采用特定照射角度及光源选择来应对非规则曲面下的光线反射不均匀的问题。图像信息通过摄像头传输到上位计算机,通过区域定位、字符分割及识别获取字符编码。
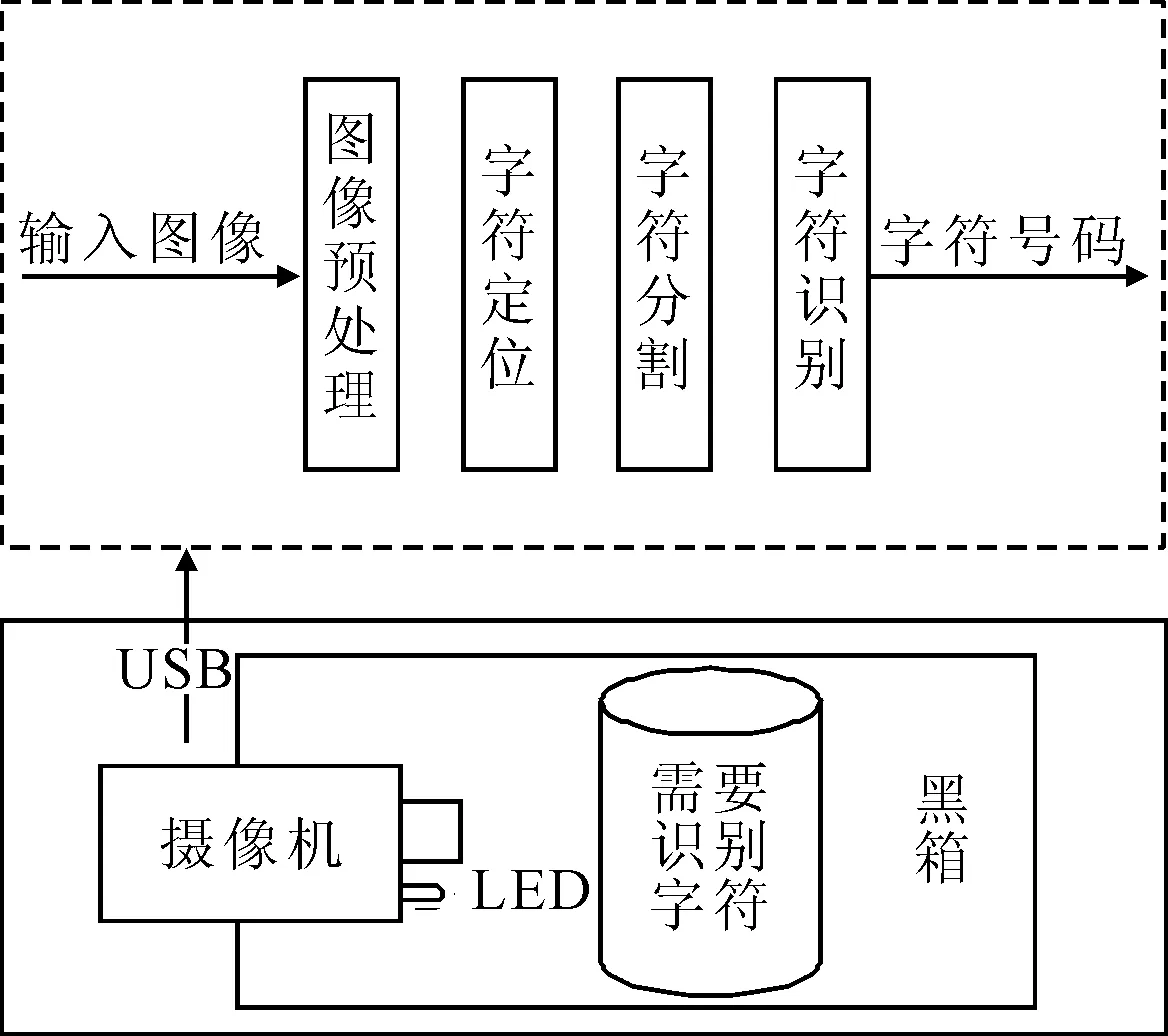
图1 字符视频识别系统的整体构成
2 图像预处理
通过摄像头获取图像之后,不能直接进行字符的定位分割识别。首先要对图像进行预处理,把图像中的干扰噪声,没有用的信息给滤除掉。通常采用的预处理有:图像灰度化、中值滤波、二值化处理和图像开操作。待识别字符如图2所示。
在黑箱中通过光照获取的图像如图2(b)所示。从图2(b)可知,通过调节设备的角度,获取的图像中只有编号和单一背景,没有其他信息,这为后面的工作提供了很大便利。
2.1 图像灰度化
图像灰度化就是把彩色图像变成没有彩色的图像。常用的处理方法,如分量法、最大值法、平均值法等,他们对于具有不平衡颜色值区域的彩色图像,仅仅通过处理三通道的亮度无法如实地表示原图的结构和对比度,因此采用加权平均法来进行灰度化,加权平均值法可以在一定程度上保留图像的这些信息[10]。处理结果如图3所示。
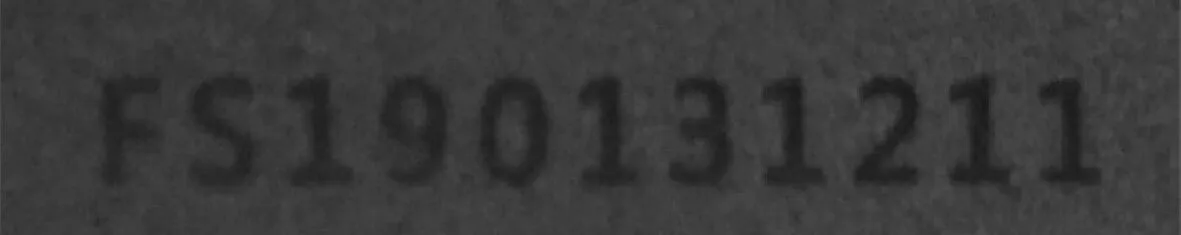
图3 灰度化处理后的图像
加权平均法对RGB三分量分配合适的权重进行均值运算,结果作为灰度值。因为人眼对绿色的敏感度高,蓝色低,所以权重分配如式(1)所示[2]。
Gray(i,j)=0.3×R(i,j)+
0.59×G(i,j)+0.11×B(i,j)
(1)
式中:Gray(i,j)为像素点(i,j)处的灰度值;R(i,j)、G(i,j)和B(i,j)分别为像素点(i,j)处的红色分量、绿色分量和蓝色分量。
2.2 中值滤波
从图3可知,在灰度化处理后有很多灰白点,这种噪声称为固定值噪声,中值滤波可以有效地处理这种噪声[11]。
中值滤波通过选择一个像素块,计算像素块的中值并把中值赋给像素块。太大的像素块会把图像必要的信息给滤除掉,而过小的像素块又会造成噪声滤除不完全。通过观察图3各个像素的灰度值以及经过多次的实验,发现块大小选择11×11能最好地对图像进行滤波,滤波效果如图4所示。

图4 中值滤波处理后的图像
2.3 二值化处理
中值滤波之后,需要对图像进行二值化操作。因为在黑箱中有灯光照射,所以采用全局阈值的方式来进行二值化。全局阈值在光照充足的情况下计算速度快,响应灵敏。全局滤波的数学表达式为:

(2)
其中f(i,j)为像素点(i,j)处的灰度值。要确定阈值的大小,首先来看一下图像的灰度直方图,如图5所示。

图5 滤波后图像灰度直方图
从图5中可以看出,字符和背景出现了两个驼峰。这样就为把字符和背景分离提供了一个方法。只要找到两个驼峰之间的最佳阈值,就可以实现字符和背景分离。而最大类间方差法是一个比较好的确定阈值的方法。

(3)
(4)
则阈值T为:
(5)
根据最大类间方差法得到的阈值为90。将其作为程序参数得到的二值化处理图像如图6所示。

图6 二值化处理后的图像
2.4 开操作
二值化后图像中只剩下黑白两种灰度值。而图像开操作可以把黑色字符连成一片。
开操作的原理就是对图像先进行腐蚀,然后进行膨胀。数学表达式为:
A∘B=(A⊖B)⊕B
(6)
式中:A为图像;B为需进行开操作的像素点矩阵。
从式(6)可知,B的大小对图像开操作的影响很大。过大的B会将不必要的信息带入要选择的区域中,过小的B会造成区域选择不完整,如图7所示。

图7 开操作错误图
为了选择合适的B大小,观察图像字符区域的像素关系,发现字符横向的像素间隔在20到25之间,竖向的像素间隔在12到18之间。经过多次试验,B的大小选择(21,15)能把字符连成一片。结果如图8所示。

图8 开操作处理后的图像
3 字符定位及识别
3.1 字符定位
字符定位采用的方法为基于边缘检测的定位方法,其目的是找到图像中的矩形区域,然后根据矩形区域的面积大小来筛选定位。这与前面的图像预处理刚好符合,并且定位精度较高。字符定位结果如图9所示。

图9 字符定位提取的图像
3.2 字符分割
字符区域提取出来后,接下来就是要把这些字符进行分割,才能进行一对一的识别。
常用的分割方法有两种:
(1)连通域分割。字符区域的每个字符笔画都是连续的。从左开始在垂直领域定位字符的开始位置和结束位置。然后计算它的外接矩形,可以分割出字符来。
(2)垂直投影分割。垂直投影分割是在垂直方向上进行灰度值投影,可以得到一个统计图。每一列表示灰度值的累加。通过扫描统计图,判断累加值就可以分割出字符来并且不会乱序。
上述两种方法理论上对字符分割都可以实现。但是经过试验后,发现连通域分割法对图像的角度很敏感,很小的角度就会造成分割出来的字符顺序混乱,没有具体的规律可循,很难进行排序。而垂直投影法则不会造成这样的结果,分割出来的字符顺序不会乱,对角度也不敏感。
因此采用垂直投影法来进行字符分割。在进行投影之前,首先要对图像进行反相操作,如图10所示。

图10 反相操作后的图像
垂直投影分割处理的结果如图11所示。

图11 垂直投影分割处理结果
从图11可以看出,垂直投影图中的黑色部分对应图10中的每一个字符。每个白色间隔与图10中的字符间黑色间隔对应。编写程序检测图11中黑色的起始位置和结束位置来分割出字符,结果如图12所示。

图12 分割出来字符图
3.3 字符识别
本文要识别的字符是汽车冷却水泵的泵体编号,字符字体一定,不会改变,并且是在黑箱中进行的图像采集。可运用模板匹配法进行字符识别。模板匹配法简单有效,只需要把分割出来的字符进行归一化,然后与准备好的字符进行对比即可得出结果。
采用的模板匹配策略为:(1)依次使用一个字符与模板的图像进行像素做差;(2)累加图像做差产生的像素值;(3)求出所有累加值中的最小值,最小值即为所求。

(7)
一个字符最终匹配得到的结果为:
min(ε1,ε2,…,ε36)
通过编写程序识别的结果如图13所示。从图13可知,识别的结果正确。

图13 字符识别结果
4 光照影响研究
在水泵的生产线中,泵体编号的采集是在黑箱状态下,用灯光照明采集得到的。图14为在亮光下采集的同一个泵体的编号。利用上述系统进行字符识别,得到结果如图15所示。

图14 亮光下采集的编号

图15 不同光照的识别结果
从图15可知,识别的结果是错误的,这表明光照强度对识别结果有很大的影响。
4.1 光照器件选择及性能
因为图像采集是在生产线上进行,所以不宜选择大的照明设备。通常用的补光光源有荧光灯、卤素灯和LED等,其主要性能如表1所示。
通过表1对比发现LED灯是一个很好的选择,并且其比普通光源单色性能好,成本低。选择5 mm的LED灯作为照明器件,灯光的颜色对于获取图像的清晰度有很大的影响。根据文献[9]的研究,红光对蓝色的太阳电池补光获取的图像清晰度最好,另外根据光色散以及吸收理论,使用与字符颜色相同或相近的单色光照射物体,会对该光的反射率很大,获得的图像很亮;使用与字符颜色互补的光或者与互补光相近的光照射,会使字符很暗[12]。颜色间的互补关系如图16所示。

表1 常见光源性能

图16 颜色互补关系图
因为需要识别字符区域是很深的黄色并且趋于黑色,背景区域为银白色且有点发蓝,所以选用白发黄的LED灯进行补光实验。白发黄LED灯发光强度和电流的关系曲线如图17所示,曲线以25 mA额定电流为基准。

图17 白发黄LED发光强度和电流关系曲线
4.2 光照实验设计
4.2.1 不同光照强度下的图像获取
此次实验通过控制同一角度下不同电流大小对光照强度进行控制。控制的电流大小分别为10 mA、15 mA、20 mA、25 mA、30 mA。不同电流下采集的图像如图18所示。

图18 不同电流强度下采集的图像
4.2.2 实验分析
这些图像肉眼看起来没多大的区别,但是用计算机来识别会有很大的差距。为了更好地对这些图像进行区别,采用图像熵来对这些图像进行评价。
图像熵[13]表达的是图像特征的一种统计形式,可以很好反映图像中平均信息量的多少,它不仅表达了图像灰度的聚集特征,还反映了图像灰度分布的空间特征,他是一个表示图像信息量很好的方法。
数学表达式为:
(8)
式中:i为像素的灰度值;j为邻域灰度均值;f(i,j)为特征二元组(i,j)出现的频数;N为图像的深度。
定义图像的二维熵为:
(9)
利用式(8)和式(9)计算图18的图像熵,结果如图19所示。

图19 图像熵与LED电流强度曲线
利用图像熵给采集的图像进行了定量的评价,对图像进行识别,识别结果如图20所示。

图20 不同电流强度下采集图像的识别结果
从图20可知,在电流10 mA和15 mA的光照强度下识别正确。其他光照强度下识别结果都不正确。再根据图像熵分析,可以得到在电流10 mA和15 mA的光照强度下,图像熵的值都在6.9以上,其他的都在6.9以下。因此可以得到结论,光照强度不是越大越好,在适当的光照强度和匹配识别程序的参数设置下,图像熵在大于6.9是能正确识别的条件。
5 结论
笔者实现了针对弱光条件下非规则曲面上的浅刻蚀字符的字符识别工作,并在不同的光照条件下,对识别效果进行了实验研究,结论如下:
(1)实现了弱光条件下非规则曲面上的浅刻蚀字符的模板匹配,通过编码模板库,可准确识别上述不理想条件下的浅刻蚀字符。
(2)隔离外部光源具备较好的外部干扰屏蔽效果,但内部光源的强度、颜色和照射角度对识别效果有较大影响。在实验中,常规白发黄LED灯在10~15 mA工作电流下能实现图像熵6.9以上,具备较好的照射条件,能保证浅刻蚀字符的准确识别。
猜你喜欢
江西通信科技(2022年2期)2022-08-08
福建农林大学学报(自然科学版)(2021年5期)2021-10-08
汉字汉语研究(2020年2期)2020-08-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
电脑爱好者(2019年8期)2019-10-30
现代电子技术(2016年22期)2016-12-26
软件导刊(2016年11期)2016-12-22
科学与财富(2016年28期)2016-10-14
福建农业科技(2016年10期)2016-03-07
