
集成机器学习模型在不平衡样本财务预警中的应用*
2021-08-29 07:00刘家鹏江敏祺
电子技术应用 2021年8期
张 露 ,刘家鹏 ,江敏祺
(1.中国计量大学 经济与管理学院,浙江 杭州 310018;2.上海财经大学 信息管理与工程学院,上海 200000)
0 引言
进入大数据时代以来,对信息的敏感程度和预测能力变得尤为重要,而对企业而言,无论是在经营活动还是投资活动中,财务危机预警一直是个问题和难题。机器学习的兴起为大数据的处理和应用提供了新的方式。
目前,许多学者将机器学习与金融危机预警相结合,取得了重大突破。OHLSON J A[1]建议将逻辑回归应用于分类的后概率,来估计公司的破产概率。Zou Hui 和HASTIE T[2]提出了弹性网络,克服了岭回归和Lasso的缺点[3]。决策树学习是一种强大的分类器[4],在树分类器的基础上,有学者提出了随机森林[5]和XGBoost[6],在计算机[7]、图像分类[8]等领域被证明有效。
但在过去的研究中,大多采用人工设定样本量,而忽视了实际上财务预警企业与正常企业的数量对比的悬殊[9]。数据不平衡的问题是财务预警研究领域的难题[10]。VEGANZONES D 和SEVERIN E[11]提出采样技术可用于提高不平衡样本预测的分类器性能,随机上采样技术[12]、随机下采样技术[13]和人工合成少数抽样技术(SMOTE)[14]的应用解决了集成复杂分类器在不平衡的财务预警研究数据中失效的问题。而集成学习机制可以通过集成不同的模型来整合多种算法的优点[15],目前在个人信贷领域已经有了一定的应用[16]。
本文研究的目的包括三个部分:一是测试集成机器学习模型的预测性能,寻找最适合财务预警的分类器;二是将不平衡学习理念运用到中国上市公司的全样本中,避免人工筛选样本的巧合性,利用抽样技术和袋装(Bagging)方法提高企业在T-3 期间内财务风险的概率;三是保持财务预警企业预测准确率的同时,提高健康企业分类的准确性,为企业的日常经营和投资者的投资决策提供一定的参考。
1 实证研究方法设计
1.1 研究模型设计
本文的研究模型设计过程如图1 所示。

图1 不平衡财务预警模型设计过程
首先,本文用装袋法和采样技术对不平衡数据进行处理。随机上采样技术(RUT)通过随机抽取重复的小样本来平衡不平衡样本;随机下采样技术(RDT)随机筛选出大样本,使其处于平衡状态;合成少数过采样技术(SMOTE)通过KNN 生成新的小样本来生成平衡数据,分别得到3 个数据集。
其次,对于在上一步骤得到的数据集,分别采用模型池中的Logistic 回归(LR)、弹性网(EN)、决策树(DT)、随机森林(RF)和XGBoost 5 种分类器进行预测。前4 种财务方法在财务预警领域已经有了较为成熟的应用。XGBoost 于2016 年提出,是对GBDT的进一步提升,其损失函数为:

其中,第一部分表示n 个样本的损失函数值,在这里通过样本预测值y^i和真实值yi的比较,来计算出对样本i的模型损失值;第二部分是正则项,用来控制模型的复杂度,模型越复杂,则惩罚力度越大,从而提升模型的泛化能力,Ω(fk)代表第k 棵树的复杂度。XGBoost 是一种改进的GBDT算法,GBDT在优化时只用到一阶导数,而XGBoost 则对损失函数进行了二阶泰勒展开,利用二阶导加快了模型训练时的收敛速度,使得模型求解更加高效。XGBoost 算法中加入了正则项,可以有效减少过拟合,即:

其中,Τ 为叶节点的个数。第二部分为节点权重的L2 范式,叶子节点值wj用来评估第k 棵树的复杂性程度。γ、λ 分别为对应的惩罚参数,越大的γ 和λ 对应越简单的模型。对式(1)泰勒展开,可得:
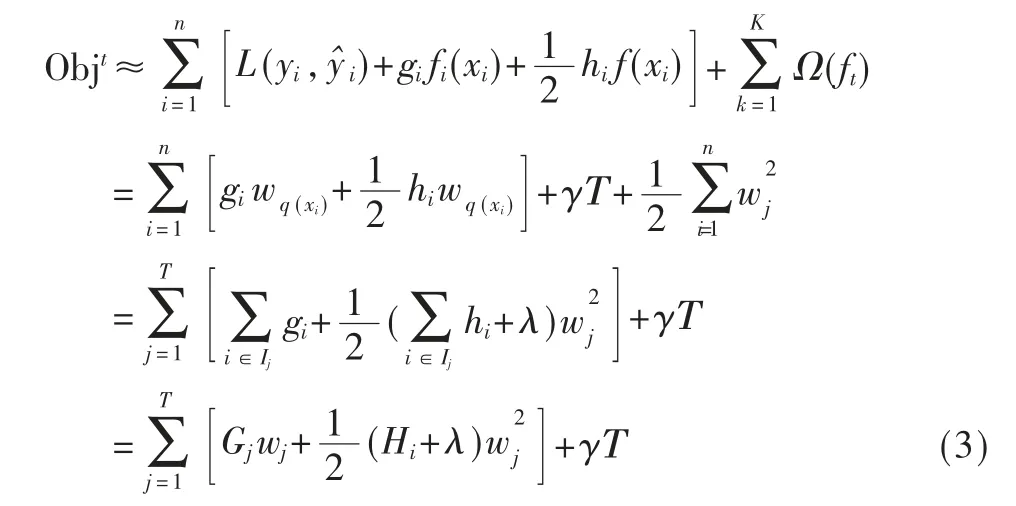
式(3)中涉及的参数有:

其中,hi和gi为第t 步的损失函数,由于hi和gi可以并行计算,极大地提高了XGBoost的建模效率;I 代表了每个叶子节点上的训练集样本。此外,XGBoost 算法还在目标函数中加入了正则项,用以权衡目标函数的下降和模型的复杂程度,一定程度上避免了过拟合。
最后,集成学习机制通过整合不同的学习模型,综合多种算法的优点。本文分别通过稳健和谨慎的算法来整合单个分类器。稳健集成算法是指只要其中一个模型预测到企业的财务风险,集成模型就预测出企业存在财务风险,并记为ME-R;谨慎集成算法是只有所有模型都预测到企业的财务风险时,该集成模型才能预测到企业存在财务风险两个分类器同时预测企业将面临风险,记为ME-C。
1.2 数据来源及指标选取
本文选取的是上交所主板市场非金融行业A 股企业的财务指标数据,数据来自锐思金融数据库。考虑到ST 或*ST的标志是连续两年或三年净利润为负,因此选取了t-3 年的财务指标数据来预测第t 年的结果。
本文从锐思金融数据库的财务比率数据中选取了107 个原始变量,并参考了数据库的分类方法,将107 个变量分成了9 组指标,分别是每股指标、盈利能力、偿债能力、成长能力、营运能力、现金流量、分红能力、资本结构和杜邦分析指标。由于这些指标未经过初始分类,存在一定的相关性,为了防止信息冗余和过度拟合,本文采用相关系数矩阵计算,筛选掉相关系数大于0.5的指标,然后剩下的57 个变量指标如图2 所示,Xi代表财务预警指标。

图2 财务预警指标构建
1.3 数据来源及指标选取
本文设定的分类结果矩阵表示如表1 所示,TP 和TN 代表预测和真实值一致的情况,FP 和FN 代表预测值和真实值不一致的情况。本次研究中感兴趣的是发生财务预警的企业,因此将其设定为Positive的类别。

表1 分类矩阵
表1 中,TN 代表正确的分类为不感兴趣的类别,TP代表正确的分类为感兴趣的类别,FN 代表错误的分类为不感兴趣的类别,FP 代表错误的分类为感兴趣的类别。本文使用的3 个指标公式如下所示:

其中,灵敏度(Sensitivity)是本文感兴趣的类别正确分类的概率,即正确挑选出有财务风险企业的概率;特异性(Specificity)度量了挑选出正常企业的概率;准确度(Accuracy)则是所有企业被正确分类的概率。
此外,还将用AUC(Area Under Curve)值来度量模型的精确度以衡量模型的性能。AUC 值越大,代表该模型的性能越好。
2 实际测试及结果分析
首先使用Bagging的思想加强学习感兴趣样本的信息,然后在Bagging的基础上,又分别尝试使用了随机过采样、随机欠采样和SMOTE 采样技术。对上述优化是否能提升模型性能用AUC 值来表示,如表2 所示,即模型经过优化前后的AUC 值的对比。

表2 模型优化前后的AUC 值
从表2 中可以看出,经过采样技术和Bagging 对机器学习模型的优化,AUC 值得到了明显的提高,分类器在优化前的均衡样本中的表现要明显差于优化后的不均衡样本。数据的增加使得分类器能学习到更多的信息,对样本进行不平衡采样的处理,使得模型不会忽略小样本中的信息,甚至通过权重影响,更重视小样本中的信息,从而减小巧合,发挥分类器预测的性能。
接下来分别对经过不平衡采样处理后的分类器进行财务预警预测,结果如表3 所示。
基于误判的代价,本文优先考虑模型的灵敏度,即正确挑选出财务预警企业的概率。其中,在Bagging RDT的算法下,对财务预警的预测准确率是最高的,且随机森林和XGBoost的Sensitivity 值是相同的。对此,推测将这两个分类器进一步集成可能会提高整体样本的准确率。因此,本文尝试用稳健和谨慎的算法将随机森林和XGBoost 相结合。
从表3 中的ME-R 和ME-C 可以看出,两种集成算法都能保持金融危机企业选择的准确性,但谨慎的集成算法可以降低对健康企业的误判率。在Bagging RDT 模型上,总精度提高了5%~9%。因此,推荐谨慎算法(ME-C)下的集成模型。

表3 优化模型的分类预测概率
此外,通过随机森林和XGBoost 对研究指标进行重要性分析,分别排名前5 个的变量如图3 所示挑选出重要指标,为利益相关者提供一定的参考,如图3 所示。
在图3 中有一个变量发生重叠,因此,一共有9 个较为重要的变量,分别是每股收益、每股营业总收入、每股营业利润、每股未分配利润、每股留存收益、归属母公司的净利润增长率、每股现金及现金等价物余额、流动负债/负债合计、扣除非经常性损益后的净利润。筛选出的衡量企业财务风险的关键性指标,能为企业的投资决策和经营管理提供一定的借鉴。

图3 随机森林的指标重要性程度
3 结论
本文将集成机器学习模型应用到不均衡样本的企业财务预警中,并通过一系列的优化解决了样本不均衡的问题,提高了预测的准确性。
本文的实证研究使用了t-3 期的上交所主板市场非金融行业A 股企业的财务指标数据来预测t 期的企业财务状况,即预测该企业在t 期是否会被ST。本文证明了不同的采样比例会影响预测的准确率,随着样本规模的增大,在一定程度上会提高预测准确率,但随着正常上市企业样本的扩增,而存在财务风险的企业的数量远远小于正常上市企业,使得分类器“偷懒”,盲目将企业预测为正常,出现了样本的不均衡现象,使得模型失去挑选出财务危机企业的能力。但是由于人为设定样本使得样本量数量受限,使得机器学习的分类器无法完全发挥其优势,因此本文应用了Bagging 思想和采样技术——随机过采样、随机欠采样和SMOTE 采样来优化模型,从而提升预测的准确性。
实证研究表明,采样技术的使用提高了模型的性能,提升了正确挑选出财务预警企业的概率,这正是本文所感兴趣的分类。其中,单独的分类器中,表现最佳的是XGBoost 与随机欠采样的结合,它在提升了挑选出财务危机企业的概率的同时,对正常企业预测概率的兼顾性要优于随机森林。为了减少正常企业被误判的概率,本文对随机森林和XGBoost 进行了简单的集成,使得在t 期正确预测财务预警企业的概率维持在92.86%的同时,相比于基分类器,集成模型将正常企业的误判率降低了约6%,整体预测准确率提高了5.4%。
集成机器学习的应用能帮助企业较好地完成前瞻性的财务预警,与传统方法相比,会具有更好的普适性,能结合大数据时代的背景,提高预测的准确率,对管理者有更低的财会专业性要求,有利于企业的多元化发展,为企业挑选投资对象以及日常的生产经营活动提供了新的借鉴意义。
猜你喜欢
中学生数理化·中考版(2022年6期)2022-06-05
中学生数理化·中考版(2021年6期)2021-11-22
新世纪智能(数学备考)(2021年4期)2021-08-06
新世纪智能(数学备考)(2021年4期)2021-08-06
今日农业(2019年12期)2019-08-13
现代园艺(2017年22期)2018-01-19
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
火控雷达技术(2016年3期)2016-02-06
小说月刊(2014年11期)2014-04-18
