
基于BP神经网络的大豆种子外观品质质量检测技术研究
2021-09-09 06:45魏剑
黑龙江科学 2021年16期
魏 剑
(黑龙江省科学院,哈尔滨 150001)
大豆是主要的农作物及经济作物之一。我国大豆种植面积和总产量都位居世界第四。大豆的生产形式通常为混合种植、混合收购,这种传统的生产方式不能使优质大豆产品得到更好的经济收益。高蛋白、高品质大豆的专门性种植、筛选是提高经济效益的有效途径,这需要对大豆种子的质量严格把关。20世纪80 年代,人工神经网络在人工智能领域成为研究热点。神经网络是通过对人脑的模拟和抽象[1],从信息处理角度建立一种简单模型,由不同的连接方式形成不同类型的网络,是人工智能的高科技产物。由大量节点构成网络,节点是一种函数,称为激励函数。节点之间的连接是权重,激励函数和权重的不同,影响网络的输出结果。
1 Matlab中神经网络的构建
1.1 Matlab中典型的n维神经元模型
Matlab中典型的n维神经元模型如图1。

图1 典型n维网络神经元模型
其中,p1,p2,…,pn为神经网络的n个输入,用n维向量表示为:
p=[p1,p2,…,pn]T
(1)
w1,w2,…,wn表示网络权值,是输入和神经元之间的关联度,设b代表神经元阈值,则输出表示为:
a=f(wp+b)
(2)
常见的传递函数f有线性函数、S函数、硬现幅(包括符号函数)函数。在Matlab中,以上的传递函数—线性函数、S函数、硬限幅函数分别是purelin函数、logsig函数、hardlim函数。
1.2 神经网络的学习和训练
神经网络的学习和训练目的是调整合适的神经元模型中的权值w和阈值b[2]。
学习是通过输入层输入信息,传递给中间层神经元,最终到达输出层。学习过程分为监督学习和无监督学习,通过反复对比实际输出和目标输出,调整权值和阈值,使实际输出不断接近目标输出。
训练分为批量式和渐进式训练。其分别将目标矢量和输入矢量做统一一次性处理和调试或渐进式调试。
2 BP神经网络的模式识别
BP神经网络是神经网络中最为广泛使用的算法,产生于20世纪80年代,是对输入、输出对组训练的模型,是一种非循环的多级反复训练,具有广泛的适应性[3-4]。BP神经网络的基本结构如图2所示。
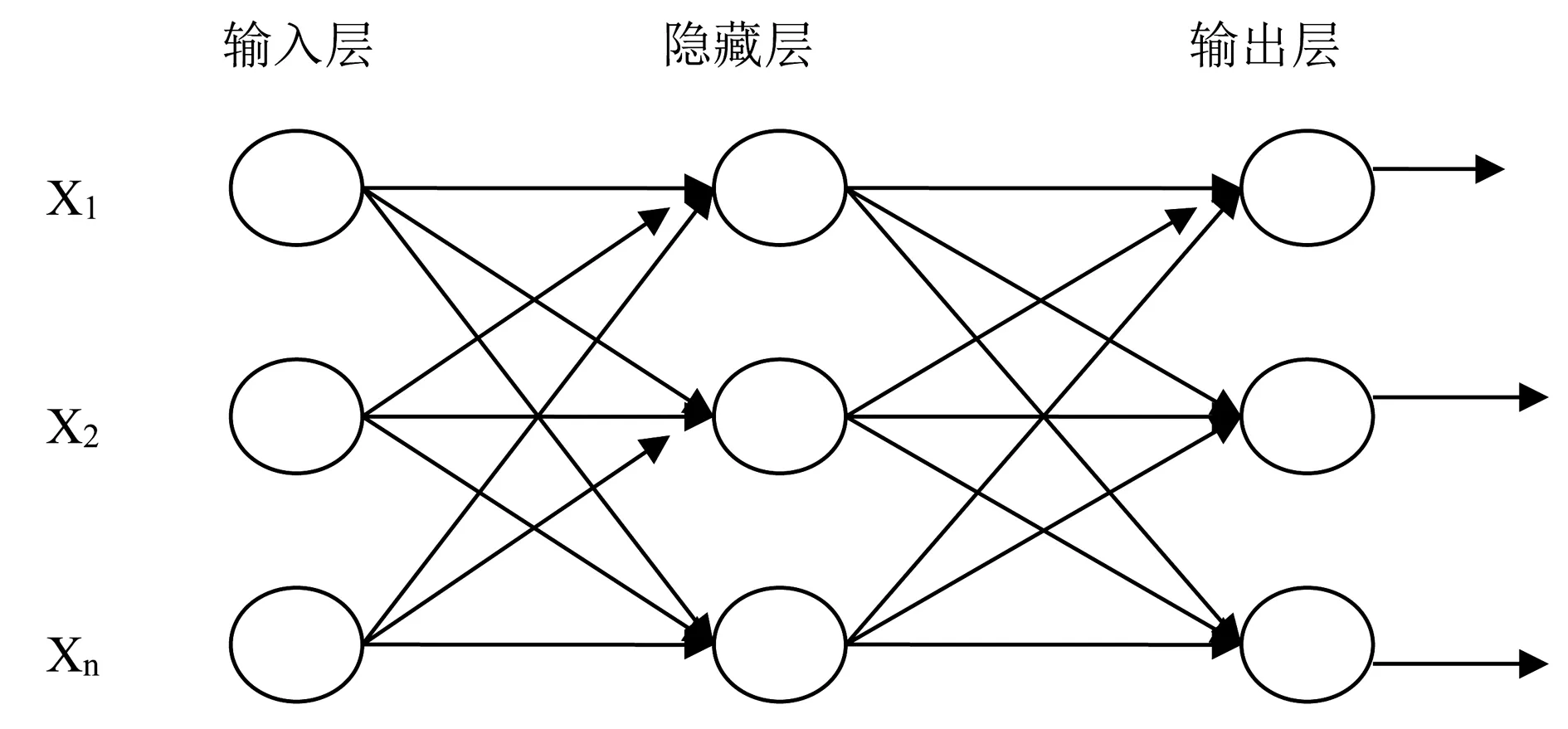
图2 BP神经网络拓扑结构
BP神经网络分为输入层、隐藏层、输出层,通过反向学习,调整权值和阈值,传递函数为S型函数,训练中进行归一化,实现输出量连续地分布在0~1,其基本思想为信号向前传播和误差向后传播。Matlab中,BP神经网络的训练函数为train函数。训练前设置训练参数,函数包括net.trainparam.epochs函数:设置训练步数;net.trainparam.show函数:显示训练结果间隔步数;net.trainparam.time函数:训练时间的设置;net.trainparam.goal函数:训练的目标精度;net.trainparam.min_grad函数:训练允许的最小梯度值。
实现训练的基本函数为:[net,tr]=train(net,p,t),其中,p是输入样本矢量集,t是目标样本矢量集。
3 基于BP神经网络的大豆种子外观品质检测
3.1 特征参数的降维处理
在特征提取环节中,提取了图像颜色特征27个,形状特征8个,纹理特征4个,共39个特征参数作为反映的外观特点的基本特征参数,这些工作的完成,为种子质量的检测奠定了基础。若将这些特征参数都作为BP神经网络的训练,则训练极易出现训练速度慢、网络瘫痪的问题。去除特征参数中一些次要项是必要手段,通过主成分析法(PCA)实现主要特征参数的选择,使特征不仅数量减少,还具有独立性和可靠性。
在Matlab中进行主成分析的函数选用Princomp函数,通过函数消除特征参数中的一些相关项,分析步骤如下:计算相关系数矩阵;计算特征值和特征向量;计算主成贡献率和累积贡献率;计算主成分载荷。
Princomp函数实现如下:
PC=princomp(X)
[PC,SCORE,latent,tsquare]=princomp(X)
[PC,SCORE,latent,tsquare]=princomp(X)对数据矩阵X进行主成分分析,给出各主成分PC、输出得分SCORE、X的方差矩阵的特征值latent和每个数据点的统计量tsquare。根据主成分析得出的数据相关性表明,特征参数中不同颜色系统下的特征的独立性不强,经过分析最终得到29个特征为主要参数,保证了特征参数的独立性和可靠性。
3.2 构建BP神经网络
确定BP神经网络的网络层和每层中神经元的数目以及选择初始权值和学习速率,激活函数选用S函数,具体步骤如下:
采用主成分析法进行特征参数的降维处理(上一节已做处理),将互相独立的29个特征参数作为神经元的输入。
建立输入矩阵,该矩阵的训练样本数量为800,即800粒不同品种的大豆种子,200粒样本作为测试集。
为了提高训练的速度,采用归一化矩阵作为输入矩阵,归一化之后数据分布区间为[-1,1],通过函数premnmx实现,Matlab程序语言为:[Pn,minp,maxp,Tn,mint,maxt]=premnmx(P,T),其中,minp,maxp代表原始输入P中的最小和最大值;mint,maxt代表原始输出T中的最小和最大值。
建立神经元网络,调用 newff 函数,网络的输入层为29 个神经元,输出层个数为 1 个节点;Matlab程序语言为net=newff(MaxMinp,[s1,s2],{‘tansig’,‘logsig’},‘trainlm’),对应层之间的映射关系和优化函数实现网络的训练。
网络训练测试。
网络的主要训练程序如下:
clear all;
p= xlsread(‘biao2.xls’);
p=p’;
t= xlsread(‘biao7.xls’);
t=t’;
[pn,minp,maxp,tn,mint,maxt]=premnmx(p,t);
xlswrite(‘maxp.xls’,maxp);
xlswrite(‘minp.xls’,minp);
xlswrite(‘maxt.xls’,maxt);
xlswrite(‘mint.xls’,mint);
[R,Q]=size(pn)
net=newff(minmax(pn),[s1,s2],{‘tansig’,‘purelin’},‘trainlm’);
%
net.trainParam.show=100;
net.trainParam.lr=0.2;
net.trainParam.mc=0.9
net.trainParam.epochs=2 000;
net.trainParam.goal=1e-6;
[net,tr]=train(net,pn,tn);
Y=sim(net,pn);
iw1=net.IW{1};
b1=net.b{1};
lw2=net.LW{2};
b2=net.b{2};
save netkohler net ;
由此建立了识别大豆种子质量的输入层神经元个数为29的BP神经网络。
3.3 大豆种子四类病害识别研究
3.3.1 虫蚀病害的识别研究
如图3为虫蚀大豆种子图像,大豆种子虫蚀颗粒表面粗糙,形状不规则,呈现锯齿状态,颗粒颜色呈现深褐色。在虫蚀病害的识别中,选择大豆种子图像的颜色特征和形状特征进行识别。

图3 虫蚀颗粒图像
程序语言如下:
clear all
load(‘D:work netkohler.mat’);
test=xlsread(‘biao.xls’);
test=test’;
maxp=xlsread(‘maxp.xls’);
minp=xlsread(‘minp.xls’);
maxt=xlsread(‘maxt.xls’);
mint=xlsread(‘mint.xls’);
testn=tramnmx(test,minp,maxp);
S=sim(net,testn);
S = postmnmx(S,mint,maxt);
S=S’;
xlswrite(‘biao5’,[S]);
训练结果保存,选取200粒大豆种子,包括100粒虫蚀颗粒种子,100粒饱满大豆种子作为测试集,测试训练网络的识别率,测试部分结果如表1所示。

表1 大豆种子虫蚀颗粒识别结果
3.3.2 破碎颗粒的识别研究
在大豆的采摘、装车、卸载等过程中,避免不了大豆种子因碰撞而破损,如图4所示,破碎大豆种子与饱满颗粒的大豆种子在颜色上不存在差异,差异主要体现在形状上,因此图像中特征选择主要选取形状特征进行破碎颗粒的识别研究。

图4 破碎颗粒图像
将训练好的网络进行保存,同样选用饱满和破碎颗粒各100粒进行测试,测试结果如表2所示。

表2 大豆种子破碎颗粒识别结果
破碎颗粒的训练结果为误差达到-0.000 276 167。
3.3.3 霉变病害的识别研究
大豆种子发生霉变呈现种子胀大、豆子软化、颜色加深的状态,如图5为霉变大豆种子图像。

图5 霉变颗粒图像
网络的训练目标为1e-006,即10的-6次方,最终训练误差达到了8.53245e-007,测试结果如表3所示。

表3 大豆种子霉变颗粒识别结果
3.3.4 灰斑病害的识别研究
灰斑病的图像进行特征提取和选择后,选用颜色特征,选取均方差最小的网络测试,灰斑病的图像如图6所示。

图6 灰斑颗粒图像
训练目标是1e-006,即10的-6次方,最终训练误差达到了6.3295e-007。
同样选用豆粒进行测试,结果如表4所示。

表4 大豆种子灰斑颗粒识别结果
对大豆种子常见的四种病害的识别表明:构建的BP神经网络能够识别单类大豆种子病害,并且识别率较高;除了对破碎颗粒的识别率较低为83%外,其他单类缺陷的识别效果均良好。破碎粒识别率较差的原因可能是特征选择造成。
大豆种子多项病害的检测。针对单类大豆种子病害识别的训练网络识别率较高,但在实际生产应用中往往存在多种病害,因此建立能够准确识别多种病害并存的网络是必要的,从而识别出优质大豆种子。
试验研究应用 MATLAB 提取的大豆的 29个特征值构建神经网络。构建步骤如下:建立输入矩阵,该矩阵的训练样本数量为2 000粒,500粒样本作为测试集。为了提高训练的速度,采用归一化矩阵作为输入矩阵,归一化之后数据分布区间为[-1,1]。建立神经元网络,调用 newff 函数[5],网络的输入层为29 个神经元,输出层个数为 5 个节点。Matlab程序语言为net=newff(MaxMinp,[s1,s2],{‘tansig’,‘logsig’},‘trainlm’),对应层之间的映射关系和优化函数实现网络的训练。网络训练测试。
参数的设置为:迭代步数为100,最大训练次数为1 000,学习速率为0.2,训练精度为1e-3。样本数量较大,为了实现快速识别,选用合适的算法是关键,将常用的两种算法进行比较,选用Levenberg-Marquardt算法更为合适。
Fletcher-Reeves 共轭梯度算法。Fletcher-Reeves 共轭梯度算法简称为FR法,根据已知点梯度形成共轭方向,并沿着此方向搜索到极小值点。对于初始点X,计算目标函数f(x)的梯度。试验中设置迭代步数为100,最大训练次数为1 000,学习速率为0.2,训练精度为1e-3,训练结果如图7所示。

图7 Fletcher-Reeves 共轭梯度算法
训练结果为0.104 621,训练目标是0.001。
Levenberg-Marquardt 算。Levenberg-Marquardt 算法是一种最优化的算法[6],通过寻找一个使得函数值最小的参数向量实现训练,使用非线性的最小二乘算法,通过迭代寻优。训练结果如图8所示。

图8 Levenberg-Marquardt算法
试验中设置迭代步数为100,最大训练次数为1 000,学习速率为0.2,训练精度为1e-3,训练结果为0.032 469 3。
试验结果表明,Levenberg-Marquardt算法的训练误差更小,训练更精准。利用Levenberg-Marquardt算法进行网络的训练,并将刚训练网络保存,用饱满大豆种子、虫蚀颗粒、破碎颗粒、霉变颗粒、灰斑颗粒、不同大豆混杂颗粒各100作为测试集,测试结果如表5所示。
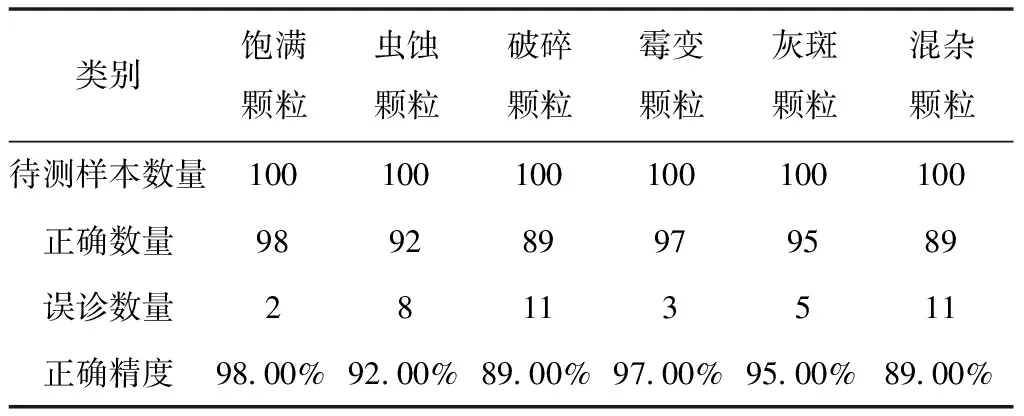
表5 大豆种子灰斑颗粒识别结果
4 小结
以上试验分析了神经网络及BP神经网络的结构和学习训练过程,对特征参数进行了主成分析法降维处理,降低了训练难度,提高了训练精度。采用BP神经网络的训练和测试,对单类大豆种子识别率很高。针对实际生产,通过比较不同共轭梯度算法,采用Levenberg-Marquardt算法训练网络,误差更小,达到了大豆种子多种缺陷的识别。
猜你喜欢
今日农业(2022年16期)2022-11-09
中国化肥信息(2022年5期)2022-08-30
今日农业(2021年20期)2021-11-26
今日农业(2021年14期)2021-10-14
电子产品世界(2021年8期)2021-01-16
空间科学学报(2020年1期)2021-01-14
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
中国交通信息化(2019年12期)2019-08-13
中国疼痛医学杂志(2017年8期)2017-01-11
创新时代(2016年8期)2016-10-21
