
基于改进的多模态神经网络图像描述方法
2021-09-15 11:20李柯徵王海涌
计算机应用与软件 2021年9期
李柯徵 王海涌
(兰州交通大学电子与信息工程学院 甘肃 兰州 730070)
(兰州交通大学甘肃省人工智能与图形图像处理工程研究中心 甘肃 兰州 730070)
0 引 言
硬件的发展推动了人工智能的发展,作为人工智能分支的自然语言处理(Natural Language Processing, NLP)和计算机视觉(Computer Vision, CV)逐渐成为近几年广大研究者们研究的热点。NLP主要研究的是理解自然语言,常用于实现命名实体识别、文本分析、机器翻译、语音识别等。CV则主要研究的是图像分类、对图像中的目标进行检测、图像的语义分割、图像修复等。
互联网技术的飞速发展以及数码设备的快速普及,带来了图像数据的迅速增长,使用纯人工来鉴别图像内容变得十分困难。同时,随着深度神经网络的兴起,处理日渐繁多的图像数据成为一种可能,因此,如何通过计算机自动提取图像所表达的信息成为了研究人员所关注的热点。图像描述是指机器自动生成描述图像的自然语言,它能够实现图像到文本信息的多模态转换,是一项融合了NLP和CV的综合任务。最早的图像描述模型是由Farhadi等[1]提出的,该模型给定二元组(I,S),其中:I表示图像;S表示摘要句子。能够完成从图像I到摘要句子S的多模态映射I→S。图像描述的研究虽然仍处于初级阶段,但是它在图像检索、机器人问答、辅助盲人等方面有着很好的应用前景,具有重要的现实意义。
Socher等[2]用深度神经网络分别学习图像和文本模态表示,然后映射到多模态联合空间;Kulkarni等[3]将图像中的对象、属性和介词等相关信息表示成三元组,然后使用预先训练好的N-gram语言模型生成流畅的文本描述句子;Mao等[4]提出的多模态循环神经网络(Multimodal Recurrent Neural Network,M-RNN)使用CNN对图像建模、RNN对句子建模,并利用多模态空间为图像和文本建立关联;Vinyals等[5]提出了谷歌NIC模型,该模型将图像和单词投影到多模态空间,并使用长短时记忆网络生成摘要;Zhou等[6]提出一种基于text-conditional注意力机制的方法,该方法强调关注描述句子中的某个单词,使用文本信息改善局部注意力;Zhang等[7]将强化学习应用在图像的文本描述生成中。然而,现有方法依然存在梯度消失导致的模型描述性能不佳、缺失语义信息,以及模型结构无法关注图像中的重点而导致模型与图像特征之间语义信息关联性不足等问题。
为了改善目前图像描述方法所存在的问题,本文以多模态循环神经网络M-RNN为基线模型,提出在图像处理部分加入卷积注意力模块(Convolutional Block Attention Module,CBAM)[8]使模型更关注图像中的重点,并使用门控循环单元(Gated Recurrent Unit,GRU)来优化M-RNN的语言处理部分。改进后的模型在描述性能上得到了有效的提升,并且改善了模型与图像特征之间语义信息关联性不足的问题。
1 相关工作
1.1 多模态循环神经网络M-RNN
M-RNN可以为输入的图像生成描述句子来解释图像的内容,是一种基于概率的神经网络模型。该模型将图像描述生成分为两个分支任务,使用CNN提取图像特征,使用RNN建立语言模型。M-RNN中的图像部分采用AlexNet[9]结构提取图像特征(在Mao等[10]后续的研究中,模型里的CNN采用了VGGNet[11]结构,实验证明在M-RNN模型中VGGNet的效果要好于AlexNet),语言部分使用RNN处理词向量,之后在多模态层将图像特征与语言特征相结合,最后经过Softmax层预测产生描述单词。
M-RNN模型的每个时间步包含了5层:两个词嵌入层,循环层,多模态层,Softmax层。在图像描述任务中,它们发挥了至关重要的作用:词嵌入层可以将输入的one-hot编码的词向量转化为稠密词向量,之后循环层对稠密词向量进行序列化处理,在多模态层会融合语言模型和图像处理得到的特征向量,最后经过Softmax层生成预测单词的概率分布。
1.2 VGG-16网络
VGG-16网络是常用的VGGNet模型,由13个卷积层和3个全连接层叠加而成,主要用来提取图像特征。将VGG-16网络中的Softmax层移除,并把第15层与M-RNN中的多模态层进行连接,即可把抽取的图像特征在多模态层和语言特征进行融合。VGG-16网络如图1所示,其中FC表示全连接层。
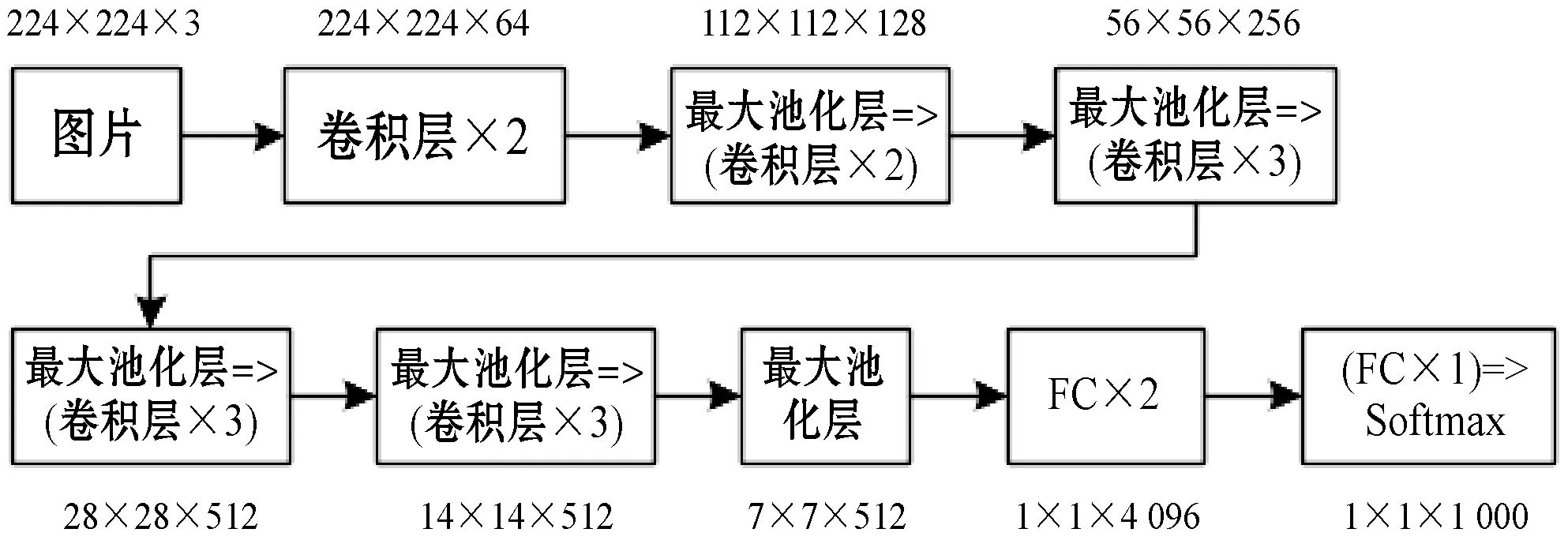
图1 VGG-16网络图
1.3 注意力机制
人类的视觉注意力是一种特有的大脑信号处理机制,可以帮助人类获得需要重点关注的目标区域,以获取更多目标区域的细节信息,注意力机制则是对人类视觉注意力的模拟。已经有很多研究表明将注意力机制应用到图像描述任务当中,可以显著提高语义表示的准确性。
Anderson等[12]使用了自下而上和自上而下的组合注意力机制,让每个图像区域关联相应的特征向量并确定相应的特征权重,从而计算目标对象与其他显著图像区域之间的注意力权重;Aneja等[13]提出一种用于图像描述的使用注意力机制的卷积模型;Wang等[14]使用了一种视觉CNN和语言CNN相结合的方法(CNN+CNN),并利用分层的注意力机制连接了两个CNN;靳华中等[15]提出了一种结合局部和全局特征的带有注意力机制的图像描述生成模型。
2 本文方法
本文方法是一种基于M-RNN改进的图像描述方法,为了改善模型的描述性能和模型与图像之间关联性不足的问题,针对M-RNN的语言模型和图像特征提取两方面进行了改进。由于M-RNN中的语言模型部分使用了RNN,在训练的过程中,RNN的神经元更新容易出现梯度消失的问题,从而使模型不擅长处理较长的上下文文本,所以本文提出在M-RNN中使用GRU门控循环单元来优化文本序列的生成。而对于图像特征提取部分,M-RNN仅仅使用了VGG-16网络来提取图像特征,无法对图像中的关键部分进行重点关注,会导致生成的图像描述文本与图像表达的重点出现偏差,所以提出在VGG-16网络中引入CBAM卷积注意力模块来解决这一问题。
2.1 使用GRU优化序列生成
GRU是由Cho等[16]提出的一种RNN模型,该模型在RNN的基础上使用更新门和重置门来处理信息流,其中更新门用来决定要忘记哪些信息以及哪些新信息需要被添加,重置门用来决定有多少信息需要被遗忘。其结构如图2所示。

图2 GRU内部结构
GRU不仅可以解决普通RNN梯度消失而导致的缺乏长期记忆的问题,而且其构造较之于常用的长短时记忆网络LSTM更加简单且参数更少,所以在进行训练数据量大的任务时,速度更快,因此本文引入了GRU来优化文本序列的生成。将经过词嵌入层处理的词向量wt和上一隐层的激活值ht-1作为GRU的输入,得到时间步t的激活值ht,随后将ht在多模态层与词向量wt和图像特征I融合,最后通过Softmax层预测文本,在经过n个时间步后,得到文本序列。以下是GRU单元的内部更新公式:
(1)
zt=σ(Wzwt+Uzht-1)
(2)
(3)
rt=σ(Wrwt+Urht-1)
(4)
式中:σ表示Sigmoid函数;W和U表示要学习的权重。
分析以上公式:


4) 式(4)中重置门信号rt会判定ht-1对结果ht的重要性,如果ht-1和新的记忆计算不相关,那么重置门就可以完全地消除过去隐藏状态的信息。
在每一个时间步t的处理过程中,经过GRU处理得到的激活值ht会输入到多模态层与稠密词向量wt、图像特征I进行加融合[17],公式如下:
mt=g2(Vw·wt+Vr·ht+VI·I)
(5)
式中:m代表各个特征在多模态层融合后得到的特征向量;V代表要学习的权重;g2(·)为双曲正切函数[18]。
(6)
2.2 卷积注意力模块CBAM的使用
2.2.1卷积注意力模块
注意力机制本质上是模仿人类观察物品的方式。通常来说,当人在看一幅图片时,除了从整体把握一幅图片之外,也会更加关注图片的某个局部信息,例如局部桌子的位置、商品的种类等。人类正是利用了一系列局部瞥见并选择性地聚焦于显著部分,所以能够更好地捕捉视觉信息。注意力机制其实包含两方面内容:(1) 决定整段输入的哪个部分需要更加关注;(2) 从关键的部分进行特征提取,得到重要的信息,因此它的核心目标就是从众多信息中选择出对当前任务目标更关键的信息。
CBAM是一种用于前馈卷积神经网络的简单而有效的注意力模块,该模块包含了通道注意力模块和空间注意力模块两个子模块,当给定一个中间特征图时,特征图会分别沿着CBAM中的通道和空间两个维度依次推断出注意力权重,然后与原特征图相乘来对特征进行自适应调整。其中通道注意力模块用来关注什么样的特征是有意义的,可以对一些无意义的通道进行过滤得到优化的特征,而空间注意力模块则用来关注哪里的特征是有意义的。通过两个子模块的协调作用,特征F转化为更具表现力的特征F*。作为一种轻量级的通用模块,CBAM可以无缝地集成到任何 CNN 结构中,开销可以忽略不计,并且可以与CNN一起进行端到端的训练。
2.2.2在VGG-16中引入CBAM
本文方法中的提取图像特征部分将CBAM模块加入到了VGG-16结构中,在VGG-16的3个14×14×512的卷积层之间分别引入了一次CBAM模块,结构如图3所示。
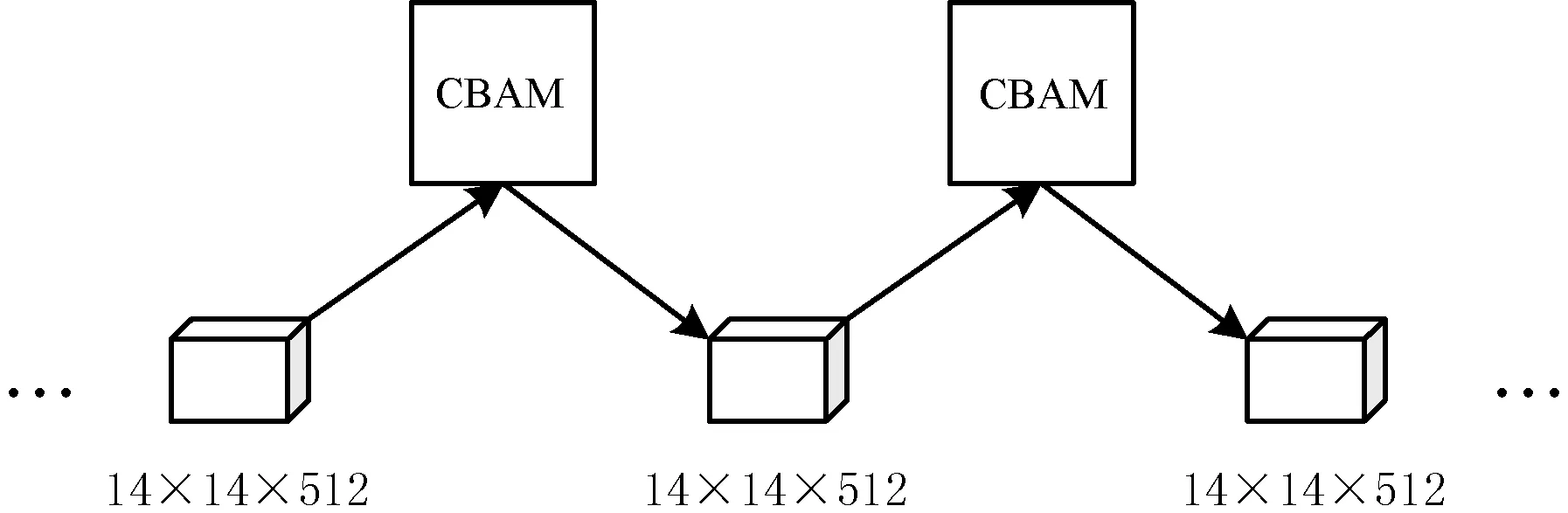
图3 在VGG-16中引入CBAM
本文方法中引入CBAM模块的VGG-16使用了两次CBAM注意力模块来对图像进行自适应调整。每一次自适应调整,CBAM依据给定的中间特征映射F∈RC×H×W作为输入,其中:C表示图像特征的通道数;H和W分别表示图像特征的高和宽。依照式(7)推断出一个一维通道注意力图谱Mc∈RC×1×1,然后按照式(8)对原特征F与Mc进行张量乘积得到通道注意力特征F′,紧接着根据式(9)获得一个二维的空间注意力图谱Ms∈R1×H×W,最后根据式(10)将空间注意力映射图谱Ms乘以特征F′得到原特征F的最终自适应特征F″。该过程如图4所示。

图4 VGG-16中的CBAM
Mc(F)=σ(MLP(AvgPool(F))+MLP(MaxPool(F)))=
(7)

F′=Mc(F)⊗F
(8)
Ms(F′)=σ(f7×7([AvgPool(F′);MaxPool(F′)]))=
(9)
式中:f7×7表示表示卷积核大小为7×7的卷积运算。
F″=Ms(F′)⊗F′
(10)
2.3 模型训练
图像提取部分使用预训练过的包含了CBAM的VGG-16网络,利用对数似然成本函数来训练本文模型,对数似然成本函数与训练集中相应图片的参考句的困惑度有关,困惑度则是评价语言模型的一个标准尺度,一条句子w1:L的困惑度计算公式如下:
(11)
式中:L代表句子的长度;log2PPL(w1:L|I)表示图片I对应的句子w1:n-1的困惑度;P(wn|w1:n-1,I)表示给定图片I和单词序列w1:n-1时生成单词wn的概率。训练模型选取的成本函数是由训练集给定上下文和相应图片得到的预测词的平均对数似然函数加上正则化项得到的,公式如下:
(12)
式中:Ns表示训练集中句子的数目;N表示训练集中所有单词的数目;Li表示第i个句子的长度;λθ表示要学习的权重;θ代表模型的参数。使用反向传播算法训练模型,训练目标是最小化该成本函数,即在训练集上使用该模型最大化生成句子的概率。
基于改进的多模态神经网络图像描述方法如算法1所示。
算法1基于改进的多模态神经网络图像描述方法
输入:MSCOCO图像数据集,文本数据集。
输出:图像描述文本。
对于数据集中的图像及其对应的参考句采取如下步骤:
Step1使用引入了CBAM注意力模块的VGG-16网络提取图像特征I。
Step2经过两层词嵌入对单词编码得到稠密词向量wt。
Step3将词向量wt,前一层GRU隐含层ht-1,输入下一层GRU,计算ht。
Step4对wt、ht、I进行加融合。
Step5通过损失函数计算损失,反馈调整参数。
Step6返回Step2,直到输出为
Step7返回图像描述文本。
3 实 验
3.1 实验环境和数据
实验使用的硬件设施为一台具有型号为i7-7800X的主频为3.5 GHz、睿频为4 GHz的六核十二线程Intel CPU,以及一块CUDA核心数为3 584、显存容量为11 GB的NVIDIA GTX 1080TI的GPU的电脑。软件方面使用64位的Linux操作系统,采用了GPU 版本的TensorFlow深度学习框架,安装了NVIDIA CUDA8.0工具包以及cuDNN-v5.1深度学习库,并基于Python2.7版本的PyCharm开发环境进行实验。
本文采用的数据集为MSCOCO2014[19]数据集。MSCOCO数据集是由微软团队提出的用于图像识别、图像语义分割和图像描述的大规模数据集,该数据集的目标是通过将对象识别问题放在更广泛的场景理解问题的背景下,提高对象识别的技术水平,同时对于提到图像描述的准确性也具有深刻意义。为了能够与原算法形成鲜明对比,突出本文改进后算法的优越性,文中使用的数据集采用了与文献[4]中一样的MSCOCO数据集,并将该数据集划分为包含82 783幅图像的训练集和包含40 504幅图像的验证集。对于每一幅图像,都有对应的5个参考描述句子。进行实验时,从验证集中分别随机选取4 000幅图像进行验证,以及1 000幅图像进行测试。
进行实验前,对数据集进行进一步的了解,通过对数据集进行分析可知,数据集中图像参考句的单词数目大多集中在9个单词到16个单词之间,分析结果如图5所示。所以在实验中使用句子长度小于等于16个单词的参考句来构建单词表,这样可以使模型生成的句子更具代表性。
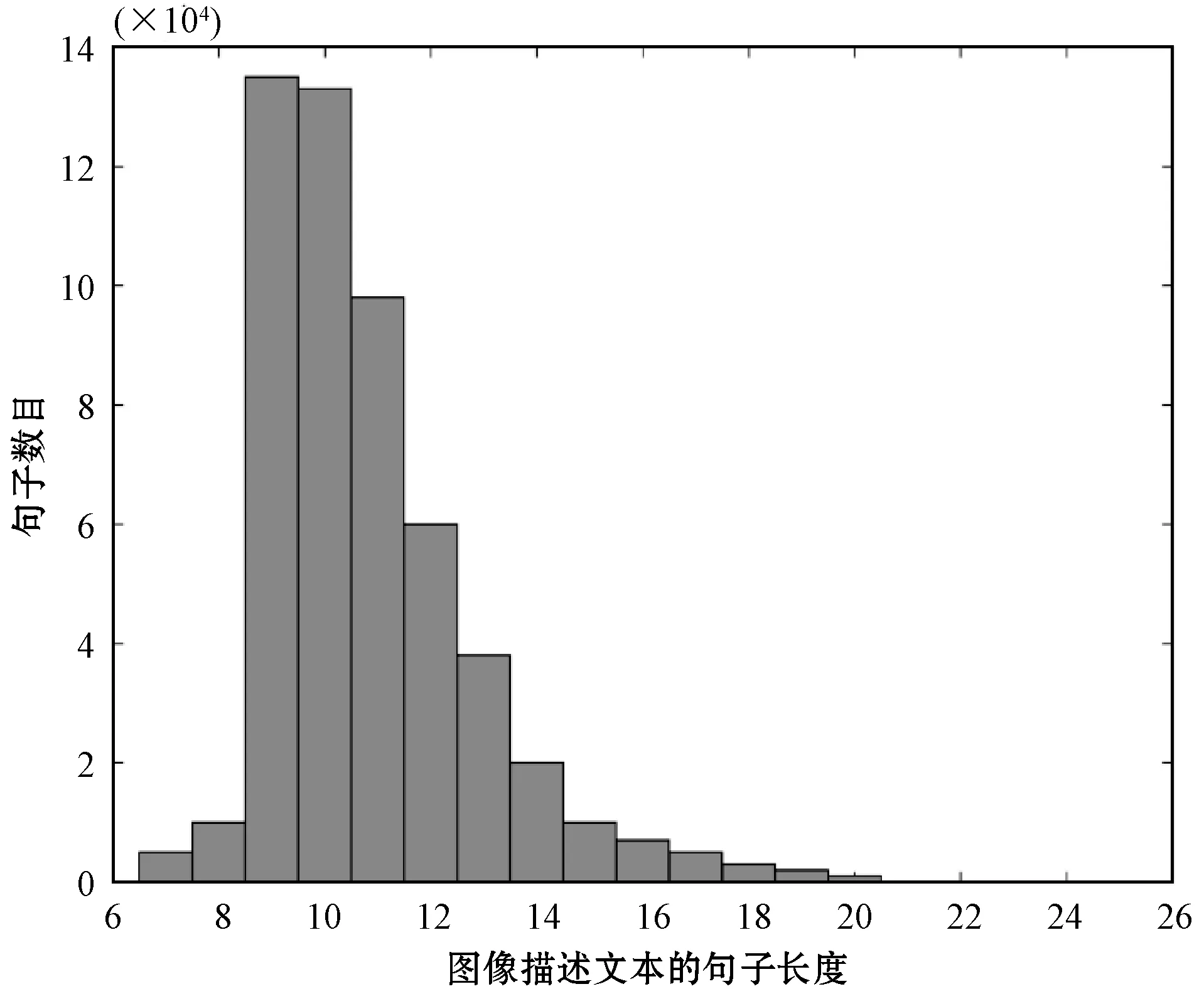
图5 数据集中参考句的长度分布
3.2 实验方法及参数设置
为了验证本文方法的有效性,实验中对本文方法和M-RNN、谷歌的NIC、DeepVS[20]、文献[13]提出的卷积模型,以及CNN+CNN等模型进行了实验对比,使用BLEU[21]、METEOR[22]和CIDEr[23]三种指标来衡量图像描述文本的质量。并且采用了人工主观抽检的方式对改进方法和原方法生成的图像描述文本进行评价分析。同时为了证明CBAM注意力机制对图像特征产生了积极影响,使用梯度加权的类激活映射(Gradient-weighted Class Activation Mapping ,Grad-CAM)[24]算法对图像特征进行了可视化对比。
在训练之前,使用MSCOCO数据集中的参考句构建单词表,本文选取句子长度小于等于16个单词的参考句来构建单词表,最终确定的单词表大小为13 691。实验中采用反向传播算法对模型进行训练,将初始学习率设置为1.0,学习衰减率设置为0.85,批大小设置为100,在训练集上总共迭代50次。并且在训练时,采用dropout正则化方法,按一定概率使词嵌入层、循环神经网络层和多模态层中的某些神经网络单元随机失活来预防过拟合的发生,本文实验中dropout值设为0.5。
3.3 实验结果及分析
图6对比了本文方法、M-RNN、NIC在MSCOCO2014数据集上的困惑度曲线,展示了三种方法复杂度随迭代次数的变化,在第50个迭代时,M-RNN的复杂度达到最小12.38,本文方法的复杂度达到最小12.17,NIC的复杂度达到最小12.08。
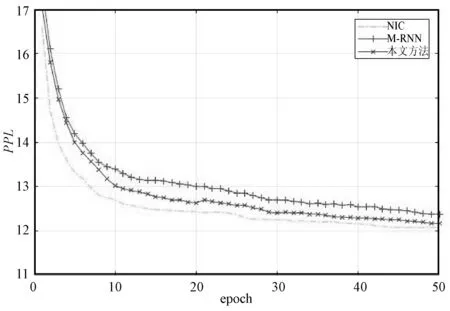
图6 MSCOCO2014数据集上训练结果对比
表1使用BLEU-1、BLEU-4、METEOR、CIDEr等评价标准,给出了不同图像描述模型在MSCOCO验证集上的得分情况,其中B@1和B@4为BLEU-1得分和BLEU-4得分。可以看出,本文方法的各项得分均高于其他方法,反映出本文方法具有一定的优越性。

表1 不同图像描述生成模型得分对比结果
图7为从MSCOCO测试集中选取的几种不同类型的图片,使用这些图片对比了本文改进方法和原方法M-RNN生成的图像描述句子。图7(a)M-RNN生成的描述为an elephant is standing in a field,本文方法生成的描述为an elephant is standing in a grassy area;图7(b)M-RNN生成的描述为a stop sign on the side of the road,本文方法生成的描述为a stop sign on the corner of a street;图7(c)M-RNN生成的描述为a yellow bus driving down a street,本文方法生成的描述为a yellow bus driving down a street next to a building;图7(d)M-RNN生成的描述为a group of people in a kitchen,本文方法生成的描述为a group of people standing around a kitchen preparing food;图7(e)M-RNN生成的描述为a display case with lots of food,本文方法生成的描述为a display case filled with lots of different donuts;图7(f)M-RNN生成的描述为a baseball player holding a bat,本文方法生成的描述为a baseball player holding a bat at a ball on a field。可以看出虽然两种方法描述结果相近,但是本文方法描述更加准确,且可以描述出图像中更加细微的部分。比如,对于图7(e),M-RNN只是描述了图中有很多食物“lots of food”,而本文方法生成的句子中“lots of different donuts”不仅描述出食物是甜甜圈,还描述出甜甜圈种类多样。

(a) 动物类图像 (b) 环境类图像
图8是使用Grad-CAM可视化图像特征的实验对比,对比了VGG-16和VGG-16+CBAM的特征区域以及真实类别的Softmax得分P,可视化结果能够反映特征对结果的贡献程度。通过Grad-CAM算法的覆盖图层可以看出VGG-16+CBAM覆盖的目标对象区域优于VGG-16网络,这说明CBAM注意力机制能够使VGG-16更好地利用目标区域信息并从中聚合特征,同时,也相应提高了目标的分类分数。

P=0.787 32 P=0.898 387
4 结 语
针对当前图像描述方法描述性能不佳、缺失语义信息,以及模型结构与图像特征之间语义信息关联性不足的问题,提出基于改进的多模态神经网络图像描述方法。该方法利用GRU型循环神经网络中的“门”操作在一定程度上解决了普通RNN在复杂模型下由于梯度消失而导致的缺少长期记忆的问题,引入CBAM注意力机制使得模型在提取图像特征时关注图像的关键部分,从而得到内容更加详实、信息关联度更高的图像描述句子。通过在MSCOCO数据集上进行的实验验证本文方法具有良好的性能。随着自然语言处理与图像处理理论的日趋完善,在未来工作中,将纳入新的方法、技术来探索它们对图像描述任务的影响。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21
汽车实用技术(2022年10期)2022-06-09
中学生数理化(高中版.高考理化)(2022年5期)2022-06-01
昆明医科大学学报(2022年3期)2022-04-19
小雪花·成长指南(2022年1期)2022-04-09
中国传媒大学学报(自然科学版)(2021年1期)2021-06-09
第二课堂(课外活动版)(2016年2期)2016-10-21
中学生数理化·高一版(2016年6期)2016-05-14
电影新作(2014年1期)2014-02-27
中学英语之友·高一版(2008年10期)2008-12-11
