
一种基于SMOTE的不平衡数据集重采样方法
2021-09-15 11:47张天翼丁立新
计算机应用与软件 2021年9期
张天翼 丁立新
(武汉大学计算机学院 湖北 武汉 430072)
0 引 言
现实中的数据集通常是不平衡的,不平衡数据集中的实例分布十分不均衡。当基于不平衡数据集构造分类器时,分类器的预测结果可能会偏向多数类,这些分类器很容易将少数样本误分类为多数类。但是有时少数类样本才是问题的主要研究对象,在这种情况下,少数类样本的错误分类可能会带来严重的问题和风险。例如,在医学数据集中,健康人的样本通常远远多于患者样本,如果基于此数据集构建分类器,那么输入一个测试样本,分类器大概率会将输入样本预测为健康人,但是将患者误分类为健康人的风险远高于将健康人误分类为患者的风险。数据失衡不仅出现在医学检测中,而且也出现在许多其他实际应用中,例如海上雷达图像中油污泄露区域检测[1]、电信欺诈检测[2]等。
研究者们已经开发出了许多方法来消除数据不平衡所带来的影响,这些方法大都在算法层面或数据层面来解决不平衡问题。算法层面的方法主要包括集成学习法和成本敏感型学习法。传统分类算法的目标是平衡的数据集,因此数据集中的所有样本都具有相同的重要性,并且将A误分类为B和将B误分类为A的代价是相同的。但是在不平衡的数据集中,对于少数类而言,拥有与多数类样本相等的误分类成本并不公平。因为在一些问题中,少数类相比于其他类具有更大的研究价值。成本敏感型学习方法则修改了各类错误的惩罚因子,分类器将少数类样本误分类为多数类样本会受到更大的惩罚,在迭代过程中会逐渐减少这类错误,因此可以弱化或消除分类器的错误偏差。AdaCost[3]是一种典型的成本敏感型学习方法。AdaCost在迭代学习过程中为少数样本的错误分类提供了更大的惩罚因素,这使得少数样本在总体成本函数中占主导地位。
集成学习方法从数据集中生成多个独立的预测模型作为弱分类器,然后将这些模型组合为强分类器。当每个弱分类器具有相对较低的错误率时,组合的强分类器将具有比任何弱分类器低得多的错误率。研究人员已经开发了基于提升算法的改进方法来解决数据不平衡问题,例如文献[4]提出少数类合成提升算法(SMOTEBoost)、文献[5]提出随机欠采样提升算法(RUSBoost)、文献[6]提出干扰修正提升算法(PCBoost)、文献[7]提出基于模型的样本合成提升算法(MBSBoost)、文献[8]提出基于过采样的不平衡数据集成分类算法(SDPDBoost)。SMOTEBoost使用SMOTE进行样本合成,并且把新样本加入到数据集中。这些新样本可以给弱分类器带来更多有关少数群体分类的信息,经过多次迭代,最终的强分类器可以得到针对少数类样本分类的提升。RUSBoost则采用欠采样方法,随机删除一些多数类样本,然后使用处理后的数据构造弱分类器。PCBoost算法首先对少数类进行随机过采样,然后使用信息增益率构造弱分类器。错误分类的过采样样本在最后阶段会被删除。除了基于提升算法的方法,还有其他的方法,如文献[9]提出的概率阈值袋装法,利用袋装法首先获得校准良好的后验估计,然后根据性能指标选取适当的阈值,以使其最大化。
数据层面的方法采用的主要策略是合成新样本和重采样。这些方法会重塑数据集,因此可以通过重塑每个类别中的样本数来消除数据不平衡。主要有三种重采样方式:多数类样本欠采样、少数类样本过采样和混合方法。欠采样方法会丢弃多数类中的某些内部样本,或将某些样本替换为合成样本,然后通过某种标准选择丢弃的样本或替换后的样本,以便剩余的多数样本可以保留尽可能多的原始数据信息。欠采样后,两种类型的采样数近似相等,数据集达到平衡。过采样方法通过生成新的少数类样本来消除偏斜分布的危害,生成的新样本加入数据集后,应使数据集达到平衡,并且基于这些数据集训练的分类器可以是无偏的。混合方法是上述方法的混合,它同时使用欠采样和过采样来使数据集平衡,经由数据层面的方法处理后的数据集是平衡的,因此基本分类器可以发挥其原始作用。
在以上不同类型的方法中,过采样是研究人员在解决数据不平衡问题中的一种流行策略[10],而使用较多的方法之一是少数类样本合成过采样技术(SMOTE)算法[11]。该方法根据少数样本的k个最近邻样本生成新的合成样本,合成样本是端点为两个最近邻少数类样本对应的线段上的随机点。由于缺乏多样性,已经有许多其他改进的算法被提出,例如文献[12]提出的边界线少数类样本合成技术(Borderline SMOTE)、文献[13]提出的自适应综合过采样(ADASYN)、文献[14]提出的基于类聚集程度的少数类样本合成(DB-SMOTE)、文献[15]提出的基于周围邻域的SMOTE和文献[16]提出的随机游走过采样(RWO)。针对多分类不平衡问题,文献[17]提出了基于马氏距离的适应性过采样方法(AMDO)。为了使合成的样本更具多样性,本文提出了一种改进的合成技术。与其选择两个点来构建一条线,不如在合成过程中涉及更多样本来构建平面或空间。除了过采样策略,还有许多欠采样的方法被用来解决不平衡问题,如文献[18]提出的去噪欠采样(Noise-filtered Under-sampling Scheme)。
1 背景知识
1.1 少数类样本合成过采样技术
解决数据不平衡问题的一种典型的过采样方法是SMOTE算法,该方法旨在弥补少数类随机过采样的缺陷。对少数类样本进行随机过采样不会使得少数类样本更具识别性,因为过采样过程其实是对样本进行复制,这种复制会使样本的决策判定越来越严格,越来越具体,导致分类过拟合。例如,如果原始决策为[0,10],则在随机过采样后,由于复制了多个少数样本,这使分类器确信少数类在较窄的范围内,分类器将给出更具体的决策区域,例如[3,6]。SMOTE算法则采用了合成新样本的方法来增加少数类样本的数量,其基本步骤如下:
Step1从少数类样本A的K最近邻少数类中随机选取一个B,A和B的样本特征的差向量为(B-A)。
Step2从区间(0,1)中随机选取一个实数i作为权值。将权值i与差向量相乘得到i(B-A)。
Step3把Step 2的结果与样本A的特征向量相加得到合成样本A+i(B-A)。
该技术通过生成人工样本来拓宽决策区域,因为添加到数据集中的样本位于原始样本的附近的合成样本,而不是样本本身。与带有替换的随机过采样相比,决策区域更为通用。实验表明,SMOTE算法可以提高少数类的分类器准确性,并且SMOTE算法和欠采样的组合比单纯使用欠采样效果更好。SMOTE算法在低维不平衡数据集中运行良好,但在一些实验中能观察到,SMOTE在高维上的性能不如在低维上的性能[19]。SMOTE包含一个参数k,代表了取最近邻的个数,文献[20]介绍了如何选取合适的k值。
1.2 已有的SMOTE算法改进
尽管SMOTE算法是解决数据不平衡问题的有效工具,但它仍有一些局限性。其没有考虑多数类别即可生成合成样本,由于新样本的生成过程是随机的,因此新生成的样本可能会出现在多数类的决策区域中。随机生成的结果是两种类别的决策区域的重叠的概率会增加,这使得两个类别更难以区分[11]。前人已经提出了SMOTE算法的一些改进版本,大多数的改进算法都在寻找一个合适的生成区域生成新样本并尽量避免重叠的增大。文献[12]提出的Borderline SMOTE将少数样本划分为噪声点、危险点和安全点,首先删除噪声点,仅使用危险点进行样本合成。Borderline SMOTE在生成过程中不仅使用少数样本,还使用多数样本,通过此方法可以加强类之间的边界。自适应SMOTE考虑了最近邻居和被选取的少数样本的距离[13],设置了最近邻距离的阈值,避免了样本到合成样本之间的距离过长,并根据不同样本集的内部分布特征调整阈值。基于周围邻域的SMOTE算法使用了最近邻的不同定义[14],该方法使用了最近的质心邻域和Graph邻域,以确保最近的邻域距离不太远。基于局部线性嵌入的SMOTE算法将局部线性嵌入算法部署到少数样本[15]。随机游走过采样(RWO)引入了基于中心极限定理的过采样方法[16],它以新生成的少数样本均值遵循原始分布的方式创建样本。当使用带有SVM的SMOTE算法作为分类器时,合成采样方法会影响SVM的内核归纳特征空间的性能,基于内核的SMOTE算法直接在SVM的特征空间中生成合成样本[23]。文献[24]结合了K-means聚类和SMOTE算法来创建新样本,避免了噪声的产生,有效地克服了类之间和类内部的不平衡。
2 改进算法
2.1 SMOTE算法的局限性
SMOTE算法首先找出每个少数类的k个最近邻样本,然后随机选择一个最近邻样本和一个实数来合成新样本。根据算法的描述,对于单个合成样本,只有两个真实的少数样本参与合成,并且合成样本选自两个真实样本所对应的线段上。换言之,合成样本的特征向量是两个真实样本特征向量的线性组合。整个少数类中新样本的潜在出现范围是每个少数类样本对之间的一组线段上。在低维特征空间中,这种方法足以描述潜在的少数类样本分布特点。但当特征空间维度较高时,线性关系太单调以致不足以描述潜在的少数样本的分布。因为在低维度空间中可能的真实样本落在一条线段上的概率较高,但是随着维度的增大,潜在的真实样本落入在两个样本之间线段上的可能性则会越来越小。
另外,原有的合成策略不足以改变某些分类器的偏差。例如,支持向量机分类器使用支持向量来找出分隔不同类的边界,支持向量是靠近边界的样本向量,是分类算法的核心,如果将SVM应用于通过SMOTE算法进行过采样的数据集,参与单个样本合成的真实样本存在三种可能性,即两个都是支持向量、两个都不是支持向量、一个是支持向量且一个是非支持向量,后两种可能性的合成样本几乎不能成为支持向量,因此新样本对边界的计算没有帮助。对于第一种情况,新样本不会显著改变原始边界,因为它们位于支持向量的直线上,并且这些直线与边界线段趋近平行。总体而言,SMOTE算法在高维度上缺乏多样性,并且可能不会大大改变某些分类器的偏差。
2.2 改进SMOTE算法设计
基于以上分析,SMOTE算法的缺点实际上有着相同的原因,即合成方法太单调,并且线段关系太简单以致无法适应潜在的少数类特征。为合成样本添加一些垂直偏移可以增加多样性,一种有效的方法是在生成过程中涉及更多的少数类样本。
因此,本文提出了一种改进的SMOTE算法,与原始的SMOTE算法相比,本文使用D个少数类样本创建了人工样本,这里D是特征空间的维数。首先,对于所有少数样本,计算它们的k个相同类别的最近邻样本集,然后对于每个少数样本,选择D个邻居和0到1/D的实数以创建新样本。该方法将合成样本空间从一维空间扩展到D维空间,从而使新样本更加多样化。改进的SMOTE算法描述如算法1所示。
算法1改进的SMOTE算法
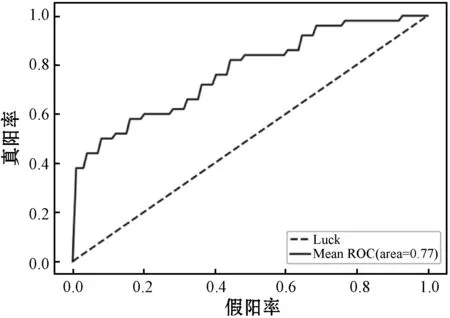
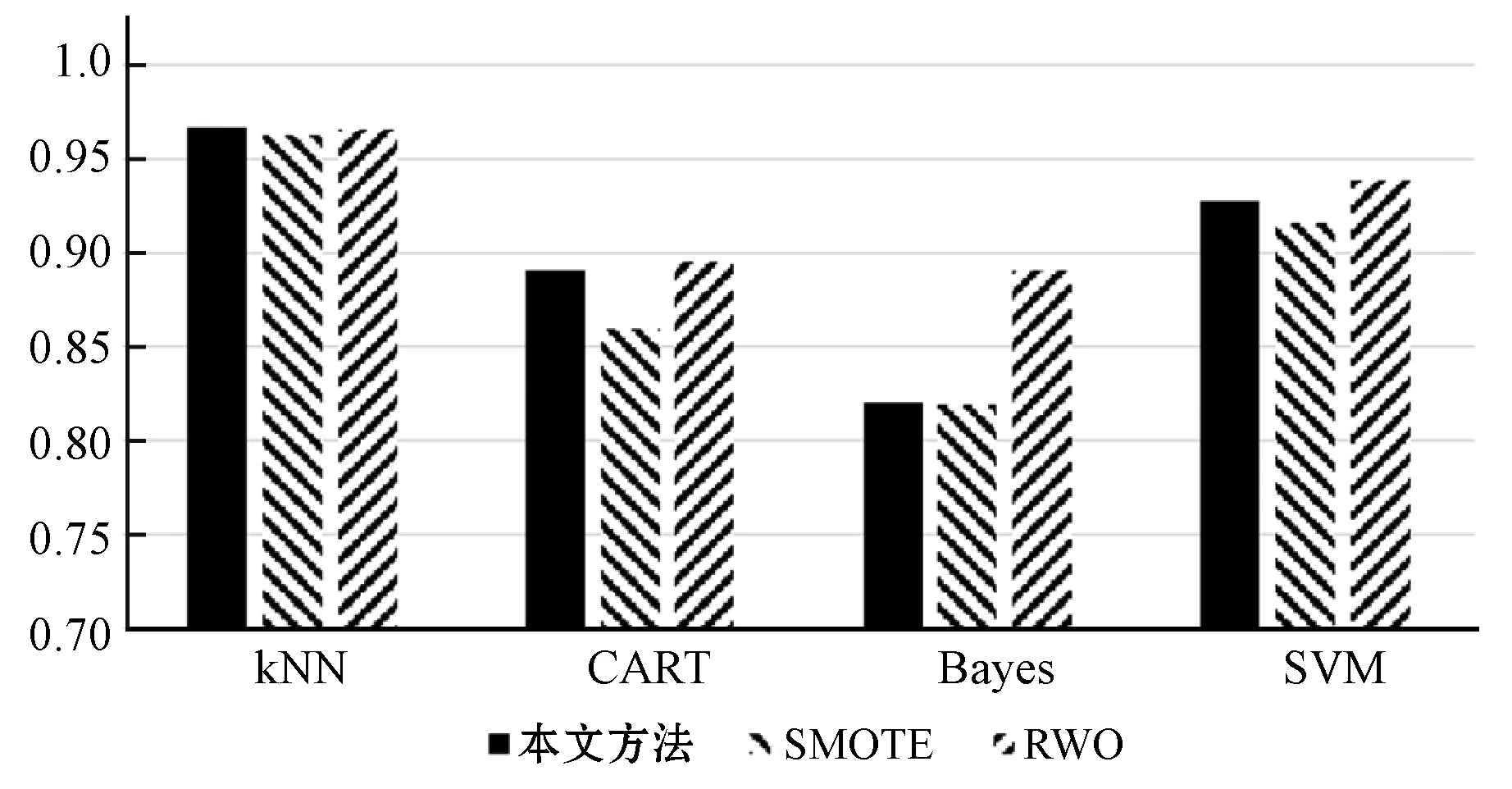
输入:训练集中的正类样本集合(少数类集合)P={P1,P2,…,Pmin};正类样本的个数min;每一个正类需合成样本的数量N;近邻个数k;参与合成的近邻个数D(D 输出:一个合成样本集合Syntheticsamples。 使用少数类集合P构建Kd树; fori=1 tomindo 找出Pi的k近邻集合: knni={knni1,knni2,…,knnik}; fora=1 toNdo 从knni中随机选择D个紧邻样本: da={da1,da2,…,daD}; 计算被选取的近邻与样本Pa的向量差: 计算合成样本的向量: 将生成的新样本计入集合; Endfor Endfor 这里,失衡率是多数类样本个数与少数类样本个数的比值,N=INT(maj/min-1),maj是多数样本的数量。 上述的改进算法中有两个参数k和D,其中k表示最近邻样本的数量,D表示生成新样本过程中涉及的样本数量。原始SMOTE算法始终将参数D设置为1,这使得样本出现的范围在真实的少数类样本的线段上。如果将D设置为2,则合成样本将在平面上而不是在线段上。如果将D设置为特征向量的大小,则合成样本的可能范围将扩展到整个特征空间。在一些特殊情况下,合成样本的可能范围会小于预期,如选取的最近邻中存在某个样本是其他样本的线性组合,此时依然能够生成足够多样的合成样本。 新算法会输出min×D个合成样本,这些样本分布在整个特征空间而不是线段中。因此,本文改进的SMOTE算法的结果会更加多样化,并且能够表示潜在分布特征。与RWO算法相比,本文改进的SMOTE算法生成的人工样本具有更多的局部分布特征。 准确率是衡量分类器性能的通用指标,但是当数据集不平衡时,准确率并不能很好地体现分类器对于少数类样本的分类性能。由于数据集中包含大量多数类样本,因此多数类的准确率主导了整体准确率。为了评估分类器的整体性能,研究者们使用了许多其他指标,例如AUC和F-measure。AUC是ROC(接收器工作特性曲线)曲线下的面积,ROC曲线是表示在不同分类标准下真阳率和假阳率变化的曲线。根据不同的分类器,标准也有所不同。由于ROC曲线下的面积是不同标准的积分结果,针对分类器的整体度量,因此该度量仅与分类器和数据集有关。ROC曲线如图1所示,其中:曲线最左边点的坐标为(0,0),最右边点的坐标为(1,1)。AUC则是ROC曲线下的的面积,即ROC在[0,1]区间的定积分。 图1 ROC曲线示例 F-measure是精度和召回率的加权谐波平均值。由于多数类的权重更多地取决于准确性,因此手动为少数类设置适当的权重可以对分类器进行公平的评估。F测度的公式为: (1) 式中:recall为召回率,recall=TP/(TP+FN);precision为准确率,precision=TP/(TP+FP);β为谐波系数,设置β=1;F-measure为F1-measure,本文实验中也使用了F1-measure作为衡量指标之一。实验中选择AUC、少数类召回率、少数类准确率及F1量度作为度量标准,因为这些衡量指标更多地集中于分类器的整体表现。 本文使用的数据集来自UCI机器学习数据库。数据集包括Adults、Forest、Phoneme和Pima。在这些数据集中Adults、Phoneme和Pima是二分类集,Forest是多分类集。由于Forest数据集具有两个以上的类别,所以手动选择一个类作为少数类,并将其余的类合并为一个类作为多数类。某些数据集包含名义属性,SMOTE算法是为数字属性设计的,不能用于名词性属性。为了方便起见,将这些名词性属性删除。改进算法中的参数D则会根据数据集的属性数有所改变。Adult、Forest、Phoneme和Pima的参数D分别为14、12、5和8。表1展示了每个数据集的详细信息。 表1 数据集信息 实验中应用了不同的机器学习算法作为过采样数据集的分类器,包括KNN、CART、朴素贝叶斯分类器(Bayes)和支持向量机(SVM)。这些分类器是基于scikit-learn(https://scikit-learn.org/)构建。 实验测试了三种过采样方法,分别为SMOTE算法、本文改进的SMOTE算法和RWO算法。SMOTE算法是本文中改进算法的原算法。RWO算法是一种基于中心极限定理的过采样算法,在合成新样本的过程中首先会计算出所有少数类样本的正态分布,再根据这个分布产生新样本。所以新样本是根据所有少数类样本产生的,并且在所有属性上都具有多样性。本文算法是针对原算法在合成样本多样性上的改进,因此选用SMOTE算法和RWO算法作为对照比较。由于所有这些方法均包含随机因素,因此单次实验无法有效反映算法的性能。针对每种过采样方法和分类器进行了30次重复实验,最终结果是所有结果的平均值。每种过采样算法和分类算法的实验结果如表3-表5所示。4个指标通过十折交叉验证进行评估,每个指标的评估将产生10个实验结果,并且表中显示的结果是所有验证结果的均值。 表2 Adult数据集实验结果 表3 Forest数据集实验结果 表4 Phoneme数据集实验结果 表5 Pima数据集实验结果 续表5 为了更加直观地比较三种方法的综合性能,本文特别比较了三种方法在不同数据集和分类算法下的ROC-AUC指数,如图2-图5所示。 图2 Adult数据集ROC-AUC比较 图3 Forest数据集ROC-AUC比较 图4 Phoneme数据集ROC-AUC比较 图5 Pima数据集ROC-AUC比较 根据Adult数据集的实验结果,本文方法具有比原始SMOTE算法更好的总体性能,尤其是在使用SVM分类器的Forest和Pima数据集的结果上,本文方法在这些数据集上实现了更高的ROC-AUC。至于其他指标和测试,结果提升了1%~2%。当使用CART分类器对过采样的数据集进行分类时,SMOTE算法的性能要优于本文方法,SMOTE算法在召回率、F1和ROC-AUC方面表现更好。在高失衡率数据集中,本文方法的性能不如RWO算法。但是在低失衡率数据集(如Pima)中,本文方法具有与RWO算法类似的结果。综合结果表明本文方法优于其他两种方法,特别是在使用SVM时,而RWO算法在使用朴素贝叶斯分类器时具有更好表现。 数据不平衡会影响基本分类器的分类结果,使它们很难对少数类进行公平的分类。为了解决这个问题,SMOTE算法被提出以通过生成少数样本的合成来达到平衡。本文提出了一种SMOTE方法的改进,使算法产生的合成样本更具多样性。实验表明,该方法在召回率、F1和ROC-AUC方面比原始SMOTE算法具有更好的性能,并且在使用SVM分类器的低失衡率数据集上特别有效。本文算法比原始SMOTE算法在综合性能上也有一定的提升,在使用不同的分类算法时,本文方法和RWO算法也会有不同的表现。在使用朴素贝叶斯分类器时,RWO算法优于本文方法;使用支持向量机时,本文方法则会有更好的综合性能。尽管在整体实验结果上,本文方法优于SMOTE算法,但是当数据集的不平衡率较高时,RWO算法会比本文方法更好。因此,当数据集高度不平衡时,还需要探索更有效的改进策略。 本文方法比原始SMOTE算法多一个设定参数。对于不同的数据集,最佳参数是不同的,如何设置适当的参数是有待解决的问题。未来可尝试将其他的一些改进版本的SMOTE上使用的策略移植到本文方法上,多种策略融合或许是处理非平衡数据集分类问题的可选途径。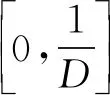
3 实 验









4 结 语
猜你喜欢
现代电子技术(2022年15期)2022-07-28
新高考·高一数学(2022年3期)2022-04-28
电子产品世界(2022年4期)2022-04-21
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
计算机系统应用(2021年2期)2021-02-23
计算机测量与控制(2019年4期)2019-05-08
领导决策信息(2018年16期)2018-09-27
人大建设(2017年10期)2018-01-23
数学学习与研究(2017年3期)2017-03-09
高中生学习·高三版(2016年9期)2016-05-14
