
基于多条件对抗和梯度优化的生成对抗网络
2021-10-13 04:51李响严毅刘明辉刘明
电子科技大学学报 2021年5期
李响,严毅,刘明辉,刘明
(电子科技大学计算机科学与工程学院 成都 610054)
生成对抗网络(generative adversarial nets,GAN)[1]是受零和博弈的思想启发而提出的一种新颖的生成模型框。它由一个生成网络与一个判别网络组成,通过让两个神经网络相互博弈、相互对抗的方式进行学习,最终达到纳什均衡。GAN 通常用于生成以假乱真的图片[2]、影片、音频[3]、3D 模型、文本[4]等等,在诸多领域都取得了显著的成效。
尽管如此,GAN 还有一些突出的问题有待研究,比如模式崩溃问题。普遍的看法是因为数据的支持和生成的分布是不相交的或位于低维流形中[5]。根据Monge-Ampere 方程的正则性理论,如果目标度量的支持是断开的或只是非凸的,则最优转换映射是不连续的。而通用DNN只能近似连续映射,这种内在冲突导致了模式崩溃[6]。对于这个问题,前期也有很多研究,如通过优化使得网络具有更加优异的学习能力,从而能够学习具有一般性的特征,而不是集中于某种特异性特征;或是通过控制损失函数,逼迫模型学习更多类型的特征。本文从多生成器博弈的角度出发,通过对现有的多生成器模型的一系列改进来促使不同的生成器生成不同的模式数据,达到有效解决模式崩溃问题的目的。现有的多生成器模型的基本思路都是使用多个生成器的联合分布去模拟样本的真实分布,多个生成器网络参数共享或者不进行共享,通过引入分类器来最大化各个生成器生成数据的JS 散度,强制不同生成器去捕获不同的模式,取得了较好的效果。Multi-generator GAN(MGAN)是其中效果较好的网络,但也存在一些问题。因为MGAN 的损失函数是在原GAN 的损失函数基础上添加一个最大化生成器样本差异的正则项,该正则项主要是对多个生成器系统整体进行约束,而从单个生成器的角度出发,模式崩溃问题还是存在的。并且,由于GAN的损失函数的缺陷[7]也会造成生成样本的质量在达到一定水平后,继续训练生成质量反而会下降的不稳定现象。
针对MGAN 上述的问题,本文主要优化思路如下:
1)使用Wasserstein 距离作为多个生成器与判别器间的博弈损失函数,改善训练过程中的梯度消失、训练不稳定等问题。
2)引入一个正则惩罚项使得损失函数可以更好地满足Lipschitz 连续,从而使得梯度可以向着更快和更好的角度前进,同时也在一定程度上避免了梯度消失和过拟合带来的影响。
3)引入一个超参数来平衡多角度损失函数带来的差异性,避免过度偏向其中某一种梯度方向。
4)提出了一种多生成器参数共享策略,减少训练代价的情况下同时提高了网络的性能,方便各个生成器独立处理图像的高维特征。
1 相关工作
为了解决原始GAN 模式崩溃的问题,各类研究提出了非常多的思路和方法。AdaGAN[8]利用一个二分类器的置信度来计算样本在下一轮迭代中的权重。GAM[9]在测试阶段将要比较的一对GAN 的判别器进行交换后再比较。GAP[10]提出同时对多对生成器和判别器进行训练,并将GAM 中GAN比较阶段交换判别器的操作引入训练阶段。MADGAN[11]训练多个生成器来模拟整个样本集上的分布,使不同的生成器尽量去生成不同模式的样本。WGAN[12]用严谨的数学推证了原始GAN 梯度消失和模式崩溃的两大问题,并提出了引入Wasserstein距离对原始损失函数进行替换的解决方案。WGAN-GP[13]在判别函数中添加了一个梯度惩罚项,以解决WGAN 中参数集中化的问题。MGAN[14]采用多生成器的方案尝试解决原始GAN 的模式崩溃问题,使用多个生成器来模拟真实样本分布,并通过最大化各个生成器之间的差异以鼓励不同的生成器生成不同模式的样本。
现有的多生成器模型的基本思路都是使用多个生成器的联合分布去模拟样本的真实分布,多个生成器网络参数共享或者不进行共享,通过引入分类器来最大化各个生成器生成数据的JS 散度,强制不同生成器去捕获不同的模式,取得了比较好的效果。
2 基于多生成器的生成对抗网络
2.1 整体架构
本文提出了一种采用多生成器架构的生成对抗网络模型(improved-MGAN,IMGAN),网络结构如图1 所示。图中z表示随机噪声,Gk为k个生成器。
2.1.1 模型参数共享
本文的参数共享策略是在保持前置卷积神经网络参数共享的基础上,对网络的最后一层卷积和全连接层进行了独立训练,即除了网络的全连接层和最后一层卷积输出参数外,网络的其他层参数都共享,在减少训练代价的情况下同时提高了网络的性能。
2.1.2 模型的模块组成
在这种网络架构下,多个生成器将输入的随机噪声转化为图片;判别器对接收到的图片进行区分,判断是生成器生成的图片还是样本集中的图片;分类器对多个生成器生成的样本进行区分,判断是由哪个生成器生成,评估不同生成器生成样本的相似性。经过多个生成器、判别器、分类器之间的多方博弈,最终达到纳什均衡。
2.2 损失函数
为了优化典型的多生成器网络如MGAN 易出现的梯度消失、训练不易收敛等问题[15],引入WGAN-GP 的Wasserstein 距离的损失函数作为IMGAN 模型中多个生成器与判别器间的博弈的损失函数。
引入WGAN-GP 的损失函数后,此时判别器的输出结果是样本图片分布与生成的图片分布间的Wasserstein 距离的近似,较之原模型的判别器的输出结果在度量上发生了变化,因此引入一个参数项 λC来平衡判别器与分类器对网络公共部分的影响:
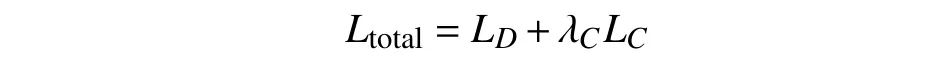
式中,LD为判别器的损失;LC为分类器的损失;Ltotal为判别/分类网络的损失函数。
由于本文是对每个样本独立地施加梯度惩罚,为防止引入同一批次样本间的相互依赖关系,本文也按照WGAN-GP 的思路对判别网络的结构进行了调整,去掉了判别器/分类器网络的批量归一化以及判别器最后一层的激活函数Sigmoid。
2.2.1 分类器的损失函数
为了避免模式崩溃,希望不同的生成器生成的样本之间有明显的差异,所以分类器的损失函数需要引导不同的生成器生成差异较大的样本,采用交叉熵来衡量不同生成器生成样本的差异,分类器损失函数为:

式中,πk为第k个生成器生成的分布在多个生成器形成的联合分布中的权重;PGk为第k个生成器生成的分布;Ck(x)为样本来自第k个生成器的概率。由式(1)可知,当各生成器生成的样本差异较大,分类器易于区分时,损失较小;当各生成器生成的样本较为接近,分类器难以区分时,损失较大,由此可以促使不同的生成器生成不同的样本。
2.2.2 生成器的损失函数
为了使模型训练过程更加稳定,生成器的损失函数采用WGAN 生成器的损失函数:

式中,Pmodel代表多个生成器生成的联合分布;D(x)为判别器的判别结果,在WGAN 的损失函数中不需要取对数。生成器损失函数由两部分组成,前一项为GAN 的经典损失,用于促使生成器生成的图片与真实样本更接近,后一项是前面提到的分类器损失函数,用于使生成器生成尽可能差异化的样本,两部分通过参数 β进行调节,通过该损失函数来提升生成器生成结果的质量和多样性。
2.2.3 判别器损失函数
为了应对训练过程中出现的梯度消失的问题,本文模型的判别网络部分的损失函数采用了WGANGP 中的判别器损失函数:

式中,Pmodel是多个生成器生成的联合分布;λgp是梯度惩罚项的参数。最后一项梯度惩罚项使判别器满足Lipschitz 约束,能够平滑判别器的参数,有效缓解WGAN 收敛困难的问题。
2.3 网络结构
本文通过引入残差块[16]将构成MGAN 网络的基本单元进行替换,解决原网络中存在的随着训练轮数的增加活性神经元的比例会逐渐下降的问题。在同等网络深度下,残差网络不仅具有更小的参数量,还能够进一步提高模型生成图像的质量。
2.3.1 生成网络结构
生成网络的结构包含输入、反卷积、激励、输出几层。网络结构中都采用了批量归一化操作来代替池化层以避免一些有用的特征丢失和整体与部分关联关系被忽略的问题。卷积神经网络中的反卷积操作由残差块通过上采样完成。
多个生成器采用了参数共享机制,输入层到第一层全连接层以及最后一层反卷积层参数不共享,其余层参数都共享。各个生成器的数据批量归一化分开进行[17],网络结构如图2 所示。

图2 生成器网络结构
2.3.2 判别/分类网络结构
判别卷积神经网络/分类卷积神经网络同样采用参数共享,最后一层参数不共享,网络的其余层参数都进行共享。两个网络由卷积、池化、激励和输出几层构成。由于采用了WGAN-GP 的损失函数,所以不需要对判别器的数据进行批量归一化,去掉了判别器的最后一层Sigmoid 激活函数。判别/分类网络中的卷积操作通过下采样残差块完成,其结构如图3 所示。

图3 判别/分类网络结构
3 实验结果与分析
3.1 实验数据集
本文实验选取了Cifar10 和CelebA 两个数据集对本文的模型进行验证。Cifar10 数据集提供了60000张大小为32*32 像素的彩色图片,分为10 类,每类包含6000 张图片,是开放的物体识别数据集。CelebA 包含了10177 个名人的共202599 张做了特征标记和属性标记的人脸图片。
3.2 实验设置
实验需要对本文提出的IMGAN 与典型的多生成器模型MGAN 进行对比,首先要排除超参数对实验的影响,受限于实验条件,未寻找模型在某一数据集上的最优值,而是采用了相关文献给出的较优值。相关参数的取值如表1 所示。

表1 实验参数设置
由于在生成对抗网络中,损失函数输出的损失值并不能直接代表生成图片的质量,即使通过训练,损失值已经很小了,但实际生成的图片仍然和真实图片相去甚远,所以本文引入了GAN 生成质量的常用评价标准(Frchet inception distance,FID)来对IMGAN 模型的生成效果进行评价。FID 使用均值和协方差矩阵来计算两个分布之间的距离:
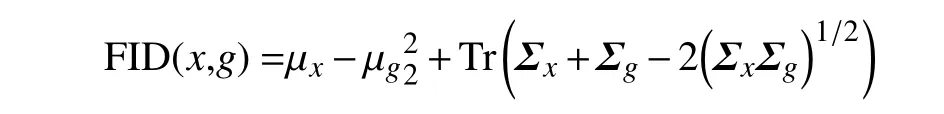
式中,x为真实图片分布;g为生成图片分布;µ为均值;Σ 为协方差;Tr 为矩阵的迹,即矩阵对角线上元素的总和。FID 值越低,两个分布越接近,说明生成图片的质量较高、多样性较好。
3.3 Cifar10 实验
在Cifar10 数据集上,分别测试了:1)单独更改参数共享方案,解绑模型的最后一层参数;2)单独更改损失函数,使用Wasserstein 距离;3)在引入1)、2)优化的基础上再更改网络结构,引入残差块这3 种场景来验证本文优化方法的效果,计算这3 种场景的FID 值来进行评估。采用Adam 优化器,设置初始学习率为0.02,随训练轮数的增加递减,设置Adam 优化器的衰减参数β1=0.5,β2=0.90,设置多样性调节参数β=0.05。
引入残差块后网络中多个生成器的结构如表2所示,判别/分类网络结构如表3 所示。

表2 Cifar10 上多个生成器网络配置

表3 Cifar10 上判别/分类器网络配置
实验结果FID 值如表4 所示。从实验结果可以看出,本文策略确实能够有效降低FID 值,性能较MGAN 有了明显的提升。

表4 Cifar10 上IMGAN 不同优化策略效果
从图4 的两种模型生成的图片对比来看,IMGAN较之MGAN 生成的图片直观上体现了较大的差异性,也没有出现单个生成器的模式崩溃问题,体现出了更好的生成效果。

图4 两个模型在cifar10 上的效果图
3.4 CelebA 实验
在CelebA 数据集上的实验中,采用FID 值来对模型的表现进行评价。网络优化同样采用Adam优化器;设置初始学习率为0.02,随训练轮数增加递减,设置Adam 优化器的衰减参数β1=0.00,β2=0.90,设置超参数λC=0.90。由于CelebA 的属性标记比Cifar10 更加复杂,将调节模型生成样本多样性的超参数进一步增大,设置β=0.10。
网络中多个生成器的结构如表5 所示,判别/分类网络结构如表6 所示。

表5 CelebA 上多个生成器网络配置
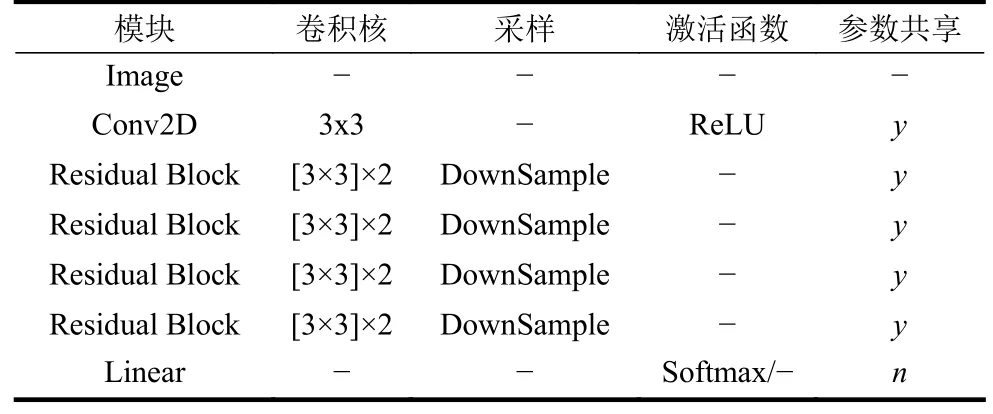
表6 CelebA 上判别/分类器网络配置
同在Cifar10 数据集上的实验一样,分别测试:1)单独更改参数共享方案,解绑模型的最后一层参数;2)单独更改损失函数,使用Wasserstein 距离;3)在引入1)、2)优化的基础上再更改网络结构,引入残差块这3 种场景来验证本文优化方法的效果。模型收敛时,FID 指标对比如表7 所示。

表7 两模型在CelebA 上的对比实验评估指标
模型迭代100000 轮后,得到的生成样本对比如图5 所示。直观上来观察模型的生成效果,IMGAN生成的人脸更加清晰和真实,FID 值也比原模型下降了0.679,这说明本文的模型在CelebA 数据集上能够进一步提高生成图片的质量。

图5 CelebA 上两个模型生成样本对比
4 结束语
本文针对生成对抗网络训练中模式崩溃的问题,从多生成器博弈的角度出发,通过对现有的多生成器模型的一系列改进来促使不同的生成器生成不同的模式数据,有效解决模式崩溃问题,使用Wasserstein 距离作为多个生成器与判别器间的博弈损失函数,改善训练过程中的梯度消失、训练不稳定等问题;提出了一种多生成器参数共享策略,减少了训练代价的同时提高了网络的性能;引入一个超参数来平衡多角度损失函数带来的差异性;引入一个正则惩罚项使得损失函数可以更好地满足Lipschitz 连续等。通过一系列的实验,验证了本文方案的有效性,能够提升生成器生成图片的质量,并且保证其生成的多样性,有效缓解了模式崩溃的问题。
猜你喜欢
数学小灵通·3-4年级(2021年5期)2021-07-16
今日农业(2019年15期)2019-01-03
计算机应用(2017年4期)2017-06-27
光学精密工程(2016年4期)2016-11-07
光学精密工程(2016年3期)2016-11-07
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
管理现代化(2016年3期)2016-02-06
管理现代化(2016年3期)2016-02-06
智能系统学报(2015年4期)2015-12-27
广西民族大学学报(自然科学版)(2015年3期)2015-12-07
