
基于NoSQL的分布式R*树索引构建与应用研究
2021-10-18 00:36孙乐乐,金宝轩
地理与地理信息科学 2021年5期
孙 乐 乐,金 宝 轩
(1.云南师范大学地理学部,云南 昆明 650500;2.云南省自然资源厅,云南 昆明 650224)
0 引言
随着信息采集/传输技术的发展,空间数据精度与体量不断提高,空间数据在物联网[1]、位置服务(LBS)等领域广泛应用[2,3],传统关系型数据库在异构数据存储、扩展性、高并发响应等方面的劣势不断凸显[4,5],以NoSQL存储、管理空间数据并支撑空间查询、应用成为研究热点[6-8]。然而,由于存储模型的差异,NoSQL的空间索引机制与传统RDB空间索引不同,设计与构建高效的NoSQL空间索引是扩展NoSQL空间数据的关键。
NoSQL数据模型主要包括key-value、column-oriented、document、graph等,基于这些模型构建的空间索引有MD-HBase[9]、GeoMesa[10]、JUST[3]、GS-Phenix[8]、MongoDB 2d与2dsphere、Neo4j Spatial 等。索引机制上,SFC(Space-Filling Curve)类索引是应用最广泛的NoSQL空间索引,其以Hilbert、Z-Curve等曲线将多维空间对象映射、编码到一维空间,实现NoSQL索引存储[3,9,10],其中,GeoMesa[10]以显著的查询性能和丰富的支持功能被广泛应用在京东物流[3]、阿里云(Ganos)、滴滴出行[2]等平台,支撑上亿量级的空间大数据查询、分析服务。但SFC属于space-specific索引[10],组织的是空间区域而非数据,适用于点数据,对线、多边形等复杂几何的索引性能有限,且易产生跨区域对象分配问题[3,11],往往通过重复存储或扩张区域缓解[11],影响索引性能;另一方面,NoSQL SFC类索引本质上是一种Geohash编码,多被存储于磁盘,查询时需进行数据表范围扫描,查询范围较大时,计算查询对应的字典序范围(lexicographic range)成本较高[10],制约其扩展性。
R*树[12]根据实际的空间分布层级划分、组织空间区域,是一种内存式、data-specific索引,也是R树家族中最具查询性能的索引之一[13,14]。R*树基本元素为MBR(Minimum Bounding Rectangle),理论上能索引一切以MBR表示的复杂几何(如线、多线、多边形等),克服了SFC类索引的上述不足。树结构型空间索引会占据数据体量的15%或更高比例[15],分布式R*树结构能控制索引体积,避免内存溢出,可通过分区策略在并行环境中集成使用,分布式R*树类索引被广泛用于提高批处理空间运算作业性能[16],如SpatialHadoop[17]、GeoSpark[18]等空间处理框架的索引被保存在文件系统中,使用时通过并行计算框架加载、查询。有研究提出混合模式的NoSQL空间索引方案,以存储在HDFS或RDB中的外部R树索引扩展NoSQL支持空间操作[18,19]。然而,不同存储介质在安全、备份与并发访问等策略上的差异[11]会导致索引查询、数据访问等操作复杂化,降低效率,同时会增加索引、数据一致性维护的成本。因此,要实现低延迟、高扩展性的查询性能,关键在于设计一个具有优良查询性能的索引机制以及与其相对应的高性能查询、应用处理机制。
针对上述问题,本文提出一种基于NoSQL的分布式R*树内存式空间索引。首先给出基于Apache Spark的索引并行构建算法,以及基于NoSQL SSPT(Server-Side Scripts)计算框架的查询/计算并行处理机制;然后以HBase为例,通过构建性能、空间查询性能、应用性能三方面实验比较本文索引的优越性;最后以自然资源开发项目合规性审查为应用场景,验证索引的应用表现,以期支撑常见的“查询+统计”模式应用。
1 理论基础
1.1 R*树索引
R*树通过引入一系列针对区域、边界形状、节点间重叠等方面的措施,优化数据插入、节点分裂逻辑,提出强制重插机制,使树结构更合理、效率更高[12]。R*树的内存持久化特性使其在检索时无需访问实际数据对象,直接给出符合空间关系的对象列表,使响应延迟更低。由于索引元素的形式固定,R*树的体积与索引对象数量成正比,面对大体量数据,构建单一集中式R*树往往导致较大的树深度与索引体积,索引加载、遍历的内存成本与时间成本较高。因此,本文采取数据划分策略构建分布式R*树,同时控制索引体量。
1.2 NoSQL数据库
NoSQL广为认可的定义是“Not Only SQL”,多为schema-less[4]或schema-free[5]模式,主要特性包括高读/写性能、大体量数据存储、结构松散、高扩展性与低成本等[5],与传统RDB在ACID、事务、SQL支持等方面存在较大差异。由于存储容量较大,为弥补客户端API在结果解析、统计计算方面的性能劣势,许多NoSQL数据库提供了SSPT,如Apache Accumulo的Iterators、Apache HBase的Coprocessor、Aerospike的User-Defined Functions、CouchDB的View等。SSPT通过在数据端执行计算以避免IO成本,并提供以分区为单位的并行计算模式,具有低延迟与性能扩展优势。因此,本文基于SSPT设计分布式R*树加载、查询处理并行机制,提高索引性能。
1.3 空间索引耗时模型
一般应用场景下,空间索引耗时T计算公式为:
(1)
式中:p为并行度,值为1时对应集中式单机索引,值大于1时对应分布式索引;i为任务编号,取值范围为[0,p];Li为索引载入和准备耗时;Qi为索引检索耗时;Ri为后续处理(结果传输、加工等)耗时。
索引体量决定加载、检索成本。集中式索引结构需单机集中存储、加载使用[16],在有限的内存、计算资源下,当索引对象数增加,L0、Q0、R0均增大,且存在查询失败、资源移出风险,同时,大数据体量会使索引结构更复杂[15]。以R树为例,树的深度为logmN,m为节点元素数,N为数据量,N越大树结构越深,产生的遍历计算越多。整体上,单机索引扩展性低,更适用于传统集中式分析模式。分布式索引多采用分区策略,将数据划分为中小体量、均匀的区块序列[15,17],各区块存储相邻的空间对象集合并构建本地索引,执行时仅加载、查询符合空间关系的区块索引数据,若符合空间关系的区块数大于1,则并行执行。因此,在同种索引下,理论上分布式结构索引的Li、Qi、Ri为集中式索引耗时L0、Q0、R0的1/p,实际应用场景中,集群节点间性能不一致,或查询结果不均匀,使耗时遵循“木桶效应”,即整体耗时取决于最慢子任务耗时。因此,提高区块间均衡性对于减少索引耗时及提高整体性能同样重要。
2 分布式R*树索引机制
分布式R*树索引(图1)包括两层结构:1)分区格网索引记录各分区所含数据的空间范围、数量等元数据,用于过滤分区;2)以分区为单位构建、使用R*树,用于检索、过滤所在分区数据。每个分区配有一个基于Region Server提供的JVM (Java Virtual Machine)与线程池,用于索引实例化、查询与应用处理。查询时,分区格网索引首先过滤掉不符合空间关系的分区,而后以分区为单位并行执行查询及应用处理,返回结果,分区内也支持多线程加速,以进一步提高效率。

图1 分布式R*树索引结构与核心组件Fig.1 Architecture and core components of the proposed distributed R*-tree index
2.1 分布式R*树构建
2.1.1 空间数据划分 为控制R*树深度,提高并行加载、查询的均衡性,采用改进后的STR(Sort Tile Recursive)[20]进行划分。STR是一种简单的空间数据打包算法,划分原理见图2a,其递归性地按各坐标轴对空间对象重心进行排序、均等划分,能同时保证区块间条目数平衡与较小的空间重叠。然而,当数据整体MBR的长宽比α较大时,STR划分后的区块数据更易呈长条形而非正方形,违反了R*树的边界周长最小化原则[12]。同时,STR固定的空间编码方向会导致类似morton曲线的区域跳跃问题,使顺序编码的分区在空间位置上不邻近,如图2a中的Part 2到Part 3;还会增大过滤数据体量,如图2a中灰色矩形仅与Part 2、Part 4相交,进行范围扫描时,需过滤并不相交的Part 3。因此,本研究对STR的切分与编码策略进行优化。假设要为N个二维空间对象构建p(式(2))个容量为C的R*树,X、Y轴上的切分数分别为Sx、Sy(式(3)),划分数据时,优先按照空间跨度更大的方向划分,即Sx、Sy较大值对应的坐标轴,以S形曲线对各分区进行编码。以图2b为例,先按Y轴划分,yi切片内分区编号Hcodei(式(4))范围为(1+(yi-1)Sx,yiSx),编码方向根据yi的奇偶性确定。

图2 STR数据均衡划分策略Fig.2 Data balancing and partitioning strategy of STR
(2)
(3)
(4)
2.1.2 索引并行构建 划分后得到p个编码为Hcodei的区块,每个区块包括空间矢量数据集Fi。借助并行计算,在每个分区内实例化R*树对象ri,遍历分区元素,插入构建R*树,并获取R*树的根节点mi。将这些数据对象转换为字节形式,以便后续导入NoSQL,得到划分后的空间数据集M(式(5))。从M中抽取出Hcodei、mi(即分区格网索引),Hcodei记录各分区数据的rowkey前缀与范围,mi记录各分区数据空间范围,用于过滤分区。
(5)
2.1.3 存储模式设计 1)存储模型上,由于列(column)配置可变,HBase表仅需配置geo、prop两个列族(column family)即可(表1)。rowkey为Hcodei_Ocodei,j形式,长度固定,Hcodei长度为3,Ocodei,j是指存储对象在当前i分区的编码,数值形式为字符串,长度为全局ri的最大深度,不足则头部补0。rowkey根据存储内容分为元数据row(Hcodei、Ocodei,j均为0)、分区元数据row(Ocodei,j为0)、数据row(Hcodei、Ocodei,j均大于0)。由于rowkey根据ASCII字典顺序排序,配置数据表在Hcodei_0000处切分区块,i∈[1,p-1],保证相同Hcodei前缀的row分配到同一区块内。如表1的分片方案可配置为[001_0000,002_0000,…,Hcodep-1_0000],因此,每个分区startkey的Ocodei,j数值固定为0。2)编码存储上,元数据row存储分区格网索引与全局元数据,如表1中row 000_0000 以geo:Hcodei_0000列记录各分区的空间范围mi,以prop:size、prop:wkid列存储数据整体条目数、坐标系信息;分区元数据row存储各分区的索引ri、空间范围mi,保证索引本地化,如表1中row 001_0000以geo:rtree列存储ri,以prop:extent列存储当前分区数据的空间范围mi;数据row存储空间数据集Fi,Fi中每个元素存储为一个row,为提高相邻rowkey的空间邻近性,本研究将空间对象从R*树根节点到叶节点的编码拼接为一维序列,构成rowkey中Ocodei,j编码部分,对应其在ri中的索引路径,如图3中9号元素的Ocodei,j为021。

表1 HBase分布式R*树与空间数据存储模型示例Table 1 Instances of distributed R*-tree and spatial data storage model of HBase

图3 对象的R*树路径映射为一维rowkey空间编码示意Fig.3 Mapping spatial object′s route path in R*-tree to one-dimensional spatial encoded rowkey
2.2 查询并行处理
空间查询可描述为从原始空间数据集中获取符合给定空间关系要素的过程。分布式R*树、数据编码存储模式已实现索引和数据的本地化,因此,可结合HBase的SSPT机制EndPoint Coprocessor开发并行运行于服务端的查询处理服务接口,处理空间查询。本文空间查询处理(算法1)首先通过全局分区格网索引获取符合空间关系的Hcodei集合:S={Hcodei,…,Hcodet}(i∈[1,p]),然后将查询请求q广播到S对应的区块内并进行R*树查询,获取索引对象的ID集合D,若D容量较大,则采用多线程进行后续运算,线程数为round(D.size()/l),l为给定的单线程处理数阈值。由于D是查询R*树的结果,若要获取经过实际数据几何空间关系检验的结果,还需执行算法2,遍历D获取实际数据,执行几何空间关系检验,对过滤后的结果进行加工、输出。
算法1 空间查询处理
输入:空间查询请求q
输出:查询结果R
S=queryRegionRowkeyList(q);
foreachregion inSdo
load R*-tree instance
D=queryRegionR*-tree(q);
if(D.size()>l){
threadPool = init(D.size(),l);
threadPool.run(geoCheckandProcess(D,q,R));
}else{
geoCheckandProcess (D,q,R);
}
算法2 查询处理函数geoCheckandProcess
输入:空间查询请求q,ID集合D
输出:查询结果R
foreachID in Ddo
if(isIntersecting(getGeo(ID),q.geo())){
r=formatResult(getData(ID));
appendResults(R,r)
}
returnR;
2.3 应用并行处理
应用并行处理与查询并行处理机制相似,理论上无需区块间通信的计算都可通过SSPT实现。HBase官方指出,Coprocessor能执行不复杂的映射、统计、聚合等计算,因此,可通过扩展服务接口实现基于数据端的应用并行处理。以自然资源开发项目合规性审查为例,只需在原有EndPoint类中新定义一个服务接口,处理逻辑与算法1整体一致,不同之处在于将算法2替换为合规性处理函数(算法3)。算法3可计算输入图斑与审查图层几何的相交情况,以及相交部分的椭球、平面面积并输出。
算法3 合规性处理函数spCompProcess
输入:空间查询请求q,ID集合D
输出:查询结果R
foreachID inDdo
if(isIntersecting(getGeo(ID),q.geo())){
geo=getIntersection(q.geo(),getGeo(ID));
compute geodesic/planar area;
transform CRS and get the other area;
r=formatResult(getData(ID).prop,geo,area_geodesic,area_planar);
appendResults(R,r)
}
returnR;
3 实验与结果分析
3.1 实验设计与数据
利用具有代表性的NoSQL/SQL空间查询和GeoMesa、ArcGIS分析工具,选取自然资源管理部门真实数据(表2),通过构建性能、空间查询性能与应用性能三方面实验,对比验证本文索引的性能。

表2 实验数据集信息Table 2 Information of experimental datasets
实验的单机配置为Intel Xeon E3-1230 v5处理器,16 G内存,Windows 10专业版操作系统;HBase集群包括3个HMaster、4个RegionServer,RegionServer有24个Vcores、80 G内存,HBase版本为cdh5.13.3-1.2.0,GeoMesa版本为1.3.5;ArcSDE数据库服务器为Oracle 12c,128 G内存。集群内节点间通过万兆交换机连接,客户端与集群环境间的网络传输速率为100 Mbps。
3.2 构建性能分析
在D4数据集中随机抽取1万~500万条数据构建索引,记录本文方法与GeoMesa的执行耗时(图4)。由图4可知,本文索引构建的平均耗时仅为GeoMesa的30.0%,当数据集较小时(1万、10万),GeoMesa构建耗时表现略优,但当数据量达50万后,本文方法更具优势,如500万量级下耗时仅为GeoMesa的18.6%。这说明GeoMesa采用基于协处理器的索引构建方法[10],扩展性低于本文的批处理并行构建模式,同时,本文的数据划分策略优化了分布式R*树间体积的均衡性,缓解了数据倾斜问题,进一步提高了R*树的并行构建效率。本文索引机制下,执行500万条多边形空间数据索引构建、NoSQL导入的总耗时在2 min内,能满足一般应用场景的需求。
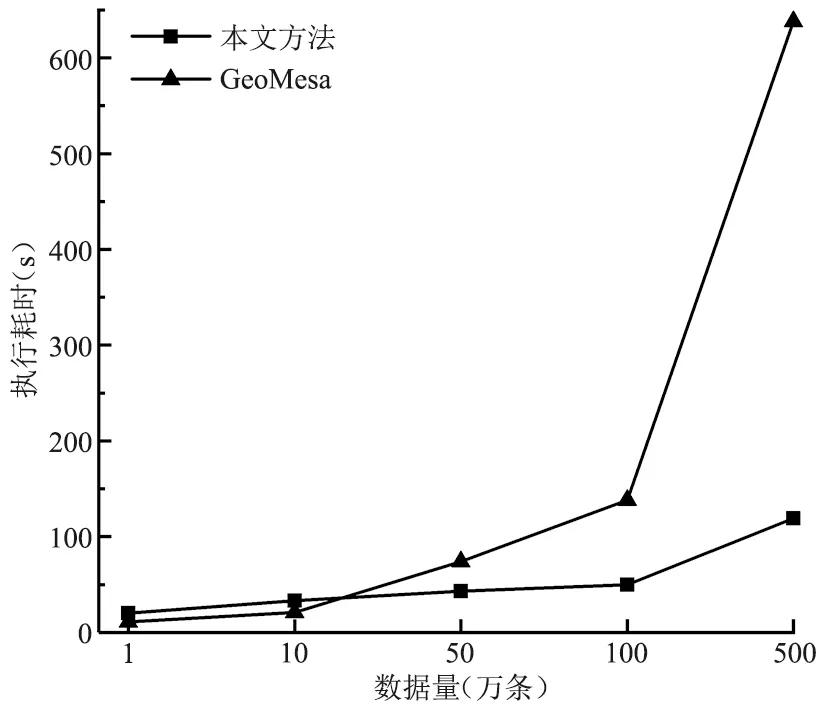
图4 索引构建执行耗时对比Fig.4 Comparison of execution time for constructing index
3.3 空间查询性能分析
3.3.1 范围查询性能分析 范围查询包括MBR查询与多边形几何查询:前者以MBR为输入,仅以MBR间的空间关系过滤数据;后者以不规则多边形为输入,进行几何间空间关系检查。实验以D3、D4为目标数据,查询输入MBR、多边形几何信息见表3、表4,查询仅返回ID序列,以不同输入信息下两种方法的平均查询响应时间T作为性能评价指标。

表3 查询输入的MBR信息Table 3 Information of input MBRs
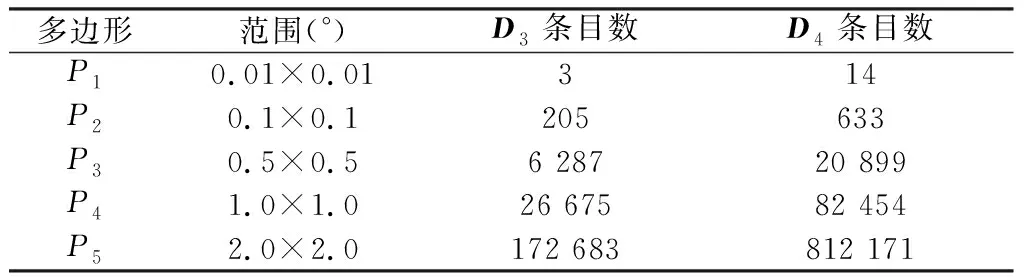
表4 查询输入的多边形信息Table 4 Information of input polygons
(1)MBR查询。如图5所示,本文索引的MBR查询性能显著优于GeoMesa,平均T值为后者的26.5%,说明SFC类索引固定的空间划分、组织模式,面对复杂多边形时,负担的遍历、检索成本更高。本文索引充分利用R*树的查询优势,更多考虑空间对象的分布特征,检索时能快速定位目标要素,查询效率更高;其次,R*树的内存化特性使其在执行MBR查询时无需扫描数据row,进一步控制了时间成本。性能扩展方面,随着查询范围扩大,两种方法的T值均有所增大,这是由于更多查询结果增加了客户端与服务器端的传输耗时,以M5查询D4为例,返回结果的数据量约为23.32 MB,百兆网络下传回客户端耗时接近2 s。由图5可知,数据表范围扫描的检索方式使GeoMesa面对更大查询范围时,T值增幅更大;XZ-Ordering的区域扩展策略产生了重叠、相交区域,增加了遍历计算量。本文方法充分利用STR能兼顾数目均衡性与空间分布特征的优势,很好地控制了R*树的深度与体积,减少了索引加载、查询耗时,同时,R*树间重叠面积较小,有效控制了查询分区的数量。
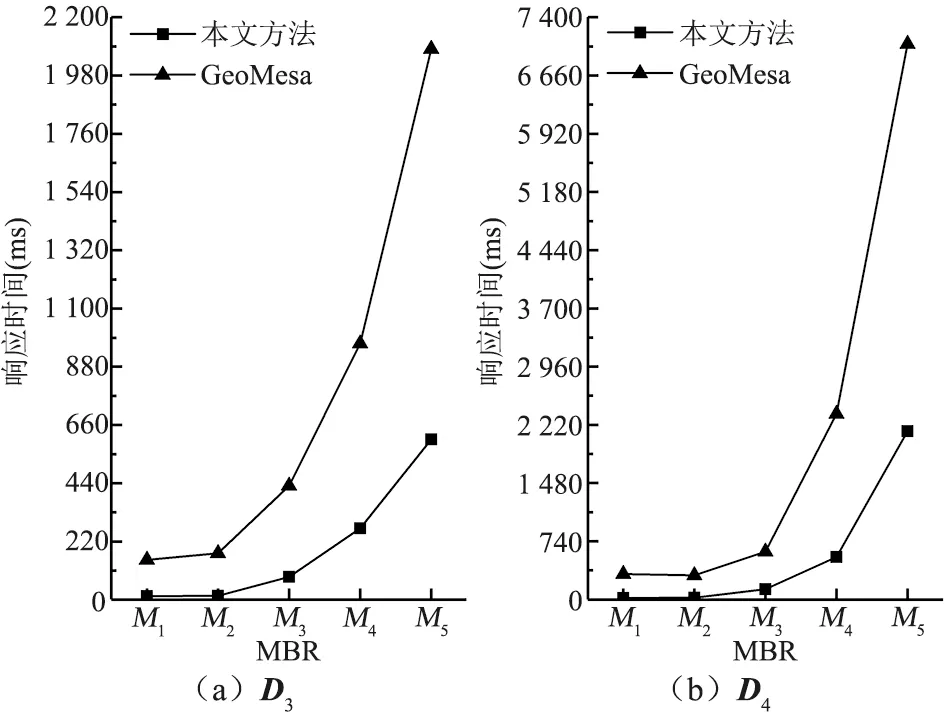
图5 MBR查询平均响应时间对比Fig.5 Comparison of average response time of MBR query
(2)多边形几何查询。由于SFC类索引执行两种查询时操作内容相似,由图6可知,相比MBR查询,GeoMesa多边形几何查询的T值增幅较小。本文方法则增加了数据获取与几何关系判断计算,多边形几何查询的T值增加了1.69~2 753.30 ms;同时,得益于R*树索引的查询性能优势,本文方法执行81万量级查询的T值仍控制在5 s内,平均T值是GeoMesa的53.4%,性能优势依然突出。
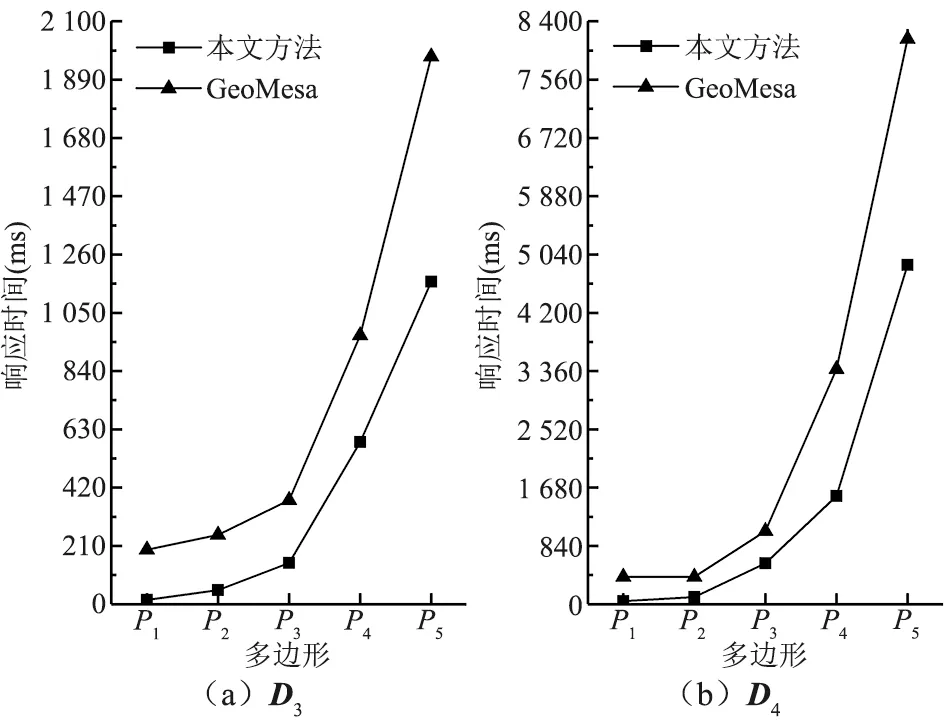
图6 多边形几何查询平均响应时间对比Fig.6 Comparison of average response time of polygon query
3.3.2 最邻近查询性能分析 用D3、D4数据集进行最邻近查询实验,以101.419725°E,25.623202°N为中心点,选取不同的距离半径(表5),测试本文方法与GeoMesa进行10次查询的T均值(图7)。由图7可知,本文方法的T均值为GeoMesa的52.3%,减少了96.89~8 795.13 ms,执行7 700量级、77万量级最邻近查询的T值分别为0.25 s、4.44 s,能保证大范围最邻近查询的低延迟响应,可较好地支撑应用。

表5 最邻近查询输入的半径信息Table 5 Information of input query radii for nearest neighbor query
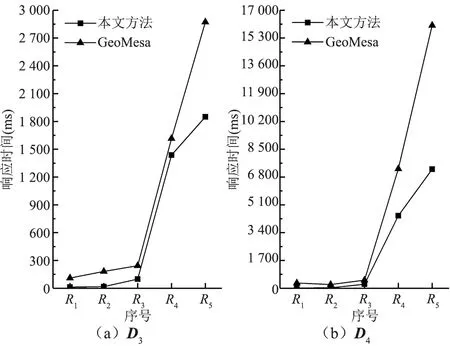
图7 最邻近查询平均响应时间对比Fig.7 Comparison of average response time of nearest neighbor query
3.4 应用性能分析
合规性分析是指在土地、矿产建设开发等审批阶段分析自然资源开发、建设项目在空间上的规划合理性,避免破坏耕地、自然保护区等限制及禁止开发规划区域,通常包括空间查询、叠加运算、结果加工等步骤。本研究以自然资源开发项目合规性分析为应用场景,通过查询、叠加计算获取审查项目(表6)与各类审查数据的压占关系,进行结果加工及压占面积、数量指标计算,生成审查结论,并将本文方法与ArcGIS、GeoMesa进行对比。如图8所示,基于NoSQL较好的扩展性及SSPT并行计算的优势,本文方法和GeoMesa的效率显著高于基于Oracle的ArcGIS,平均耗时分别为ArcGIS的10.6%与14.53%。本文方法综合应用表现最优,最大耗时不超36.2 s,低于GeoMesa的47.97 s,平均耗时为GeoMesa的72.7%,证明了分布式R*树与应用并行处理的优越性,能支撑常见的“查询+统计”类应用。
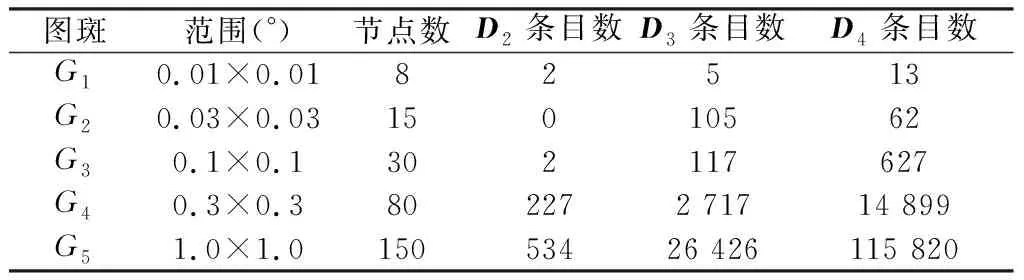
表6 合规性审查输入的图斑信息Table 6 Information of input review polygons for the compliance review

图8 各方法审查执行耗时对比Fig.8 Comparison of execution time for compliance review using various methods
4 结语
空间索引是支撑空间查询、分析应用的基础。本文提出一种基于NoSQL的分布式R*树索引机制,该索引基于NoSQL的分区机制与优化后的STR均衡策略,实现分布式索引结构,以控制树的深度、体积,凭借R*树更优良的空间组织结构与内存化特性,以及基于NoSQL的SSPT机制设计的查询、应用并行处理机制,实现查询、应用计算的高响应与高性能扩展。实验证明:本文索引在构建性能、空间查询性能、应用性能方面优越性显著,能为基于NoSQL的大体量空间数据管理、分析应用提供一种优良解决方案。但本文索引的更新成本偏高,后续将研究提升索引更新性能与数据可视化。
猜你喜欢
中学生数理化·七年级数学人教版(2022年9期)2022-10-24
环球时报(2022-03-29)2022-03-29
少年漫画(艺术创想)(2020年2期)2020-06-15
中学生数理化·七年级数学人教版(2019年9期)2019-11-16
趣味(数学)(2019年11期)2019-04-13
知识经济·中国直销(2018年7期)2018-07-27
测绘科学与工程(2016年4期)2016-04-17
电测与仪表(2015年8期)2015-04-09
电测与仪表(2015年7期)2015-04-09
测绘科学与工程(2014年2期)2014-02-27
